

Rolf Kalbermatter
-
Posts
3,909 -
Joined
-
Last visited
-
Days Won
270
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Rolf Kalbermatter
-
-
On 3/25/2021 at 2:45 PM, Fábio Nicolas Schmidt said:
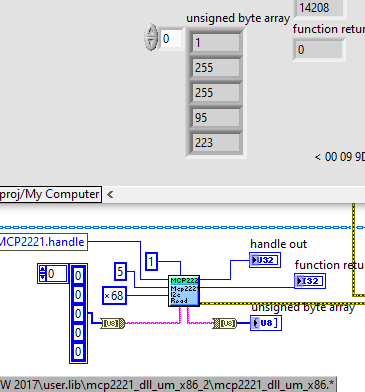
I am using the MCP2221 to read analog values from an ADC MCP3424, and noticed a bug when reading bytes from the analog data register.

Do you have any workaround for this issue? I tried to download latest driver and DLL, but still no luck solving this.
This library has a bug. The underlying Read VI should use byte arrays as input and output data and the Call Library Node should be configured accordingly for this parameter to be Array, 8 bit unsigned Integer, Pass as C array pointer.
With the current C String configuration in the Call Library Node, LabVIEW will scan the string after the Call Library Node has finished, and terminate it after the first 0 byte (since that is how in C strings are terminated).
-
 1
1
-
-
16 minutes ago, viSci said:
Later this afternoon I plan on remoting into the server. Could you suggest a specific MSC runtime to try?
No, Microsoft Visual C 6.0 still used the standard Windows C Runtime MSVCRT.DLL which should be available in every Windows version since 3.0. Or maybe it is not anymore in Windows Server 2019??
Try to see if you can find MSVCRT.DLL in SysWow64.
-
Well so long ago. I would have to look into the code to see if it could actually even cause this error from not being able to locate the Python kernel. I kind of doubt it.
What might be more likely the problem is the lack of the correct MSC C Runtime library. Although a quick check seems to indicate that it was compiled with MSVC 6.0 which did not have this cumbersome C compiler version specific runtime support library issues. Not having a Windows Server 2019 installation available it is also a bit of a trouble to try to debug this.
-
2 hours ago, ShaunR said:
So I guess you have a Ham Radio licence? It's exactly what my Ham Radio buddy said.
No, I didn't go through the whole procedure to obtain a license. But I did in a long ago past, during my education in electronics, experiment with building the hardware for a radio transceiver to do that. And also another one to receive the satellite radio signal from weather satellites (all at that time in analogue hardware, when 137MHz was considered still really HF and its signal propagation in a circuit sometimes more magic than anything else, not one of those easy SDR dongles 😁)
At some point I decided that HF was simply too hard to really work with and concentrated on mostly digital electronics and some audio electronics for PA.
-
On 5/19/2023 at 9:58 AM, ShaunR said:
While I was faffing around with callbacks. I also implemented PSK.
I'm an "Urgestein". For me PSK still mean Phase Shift Keying.
-
2 hours ago, dipanwita said:
I have a H&H PLI Series Electrical Load in my laboratory. I am targeting to control this device by giving instruction using LABVIEW. Currently, as a interface medium I am using ethernet (LAN) for communication. I have downloaded specific driver (H&H PLI series) required for this device to use in LabVIEW. I am facing some difficulties in it such as providing SCPI commands which is in manual to this device but not receiving response from it. I need some help to resolve this matter. I am not able to understand the issue. I need some help.
So you say you downloaded a driver but program the entire communication in plain calls anyhow. Why that?
First thing would be that commands need to be terminated. Try to add a \n or maybe \r\n to the *IDN? command too.
Also, while the case of the commands usually shouldn't matter for SCPI command, you do not need to write the syntax from the programming manual literally. The convention is, that the uppercase letters are required (short form), while the lowercase letters are optional (long form). Some instruments allow partial optional characters and other only understand either the exact short form or the full long form command parts in a single command.
One potential problem is that the native TCP nodes only have 4 messages modes for TCP Read. And neither is usually perfect for normal instruments. You would want to use the termination character mode, but there is only the option to use CR AND LF. Many instruments send either one of them but not necessarily all of them. Standard mode kind of still works but the Read will timeout as it can't read the actually asked amount of characters. This will slow down your communication a lot. Better is usually to go and use VISA instead for these cases.
-
20 hours ago, ShaunR said:
So I can retire in October?
If you happen to own a substantial amount of NI shares, that is certainly possible. 😁
Otherwise you have to consult with your pension provider first. 😎
-
Why do you think your path hierarchy in the RTE needs to be different than on your development system? You should be able to arrange that in a way that there is (almost) no difference!
If you make sure to not enable the LabVIEW 8.0 hierarchy layout in your application build settings, the relative paths inside the executable remain automatically the same. Of course you will need to add all those classes explicitly to the build now, as LabVIEW can't track them as dependency now anymore, since you have no static reference to them.
-
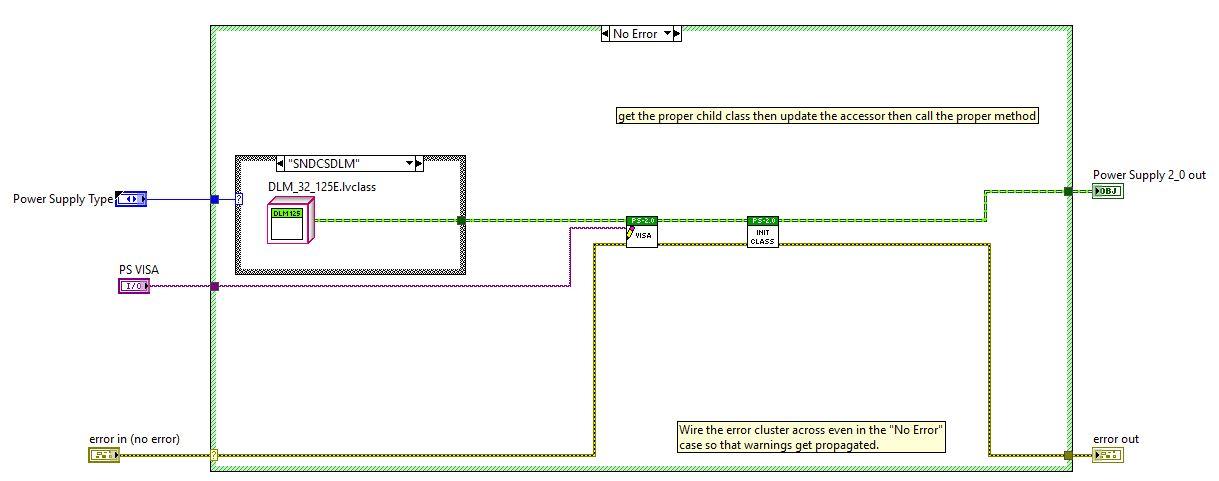
16 minutes ago, Matt_AM said:
Question about OO, because I think I am doing it wrong. In my parent PS 2-0 class' Create VISA based Class, I am using an enum to grab the proper child at run time by dropping the child into a case based off of the enum. Is this the proper method (image below). I think I remember reading something somewhere that you should use the "get default class" vi when doing this architecture. Again, I'm new to OO so if my design is wrong, please let me know so I can make it better.
This absolutely will pull every class in that case structure into your VI hierarchy. And if any of them is not executable (for instance because it calls a DLL whose dependencies is not satisfied) your VI here (and the whole class it is a member of) will have a broken executable status.
The idea with using the Get Default Value for a class is exactly to avoid that. If you resolve the class at runtime with the Get Default Value function it does not matter if any of the classes that you may eventually call is present or not on disk, or broken or whatever, when trying to load your "Generic" PS2 OO class. It will load and as long as you do not try to instantiate one of the not present or broken classes at runtime, nothing bad will happen.
Only when you indicate to this function to load SNDCSDLM, will it cause a runtime error to the fact that something is wrong with that class when it was trying to load it. If you however only indicate to load and use AG6038A (just to name something) and that class has no problems, you can execute everything and it does not matter that the SNDCSDLM class is not executable for some reason.
But with your current implementation it does matter. The Class constant makes the whole class a static dependency of your VI (and of your entire Power Supply 2.0 class) and if any of the class members of SNDCSDLM is broken your entire Power Supply 2.0 class is also broken, even if you never even intend to run the SNDCSDLM class in it.
-
1
-
-
3 hours ago, Lipko said:
The parrot is improving with every quiestion. I can only guess how many millions of questions it gets every day. So 1-2 months can mean eons.
Or maybe I just fell for all those alarmists...Supposedly it is not using user input to add to the internal knowledge pool beyond a single session. Of course it's tempting to do that anyhow. It uses a lot of energy to run and somehow some bean counters want to see some form of ROI here, so "free" learning input would seem interesting. But without a very rigorous vetting of such input, the whole knowledge pool could easily be tainted with lots and lots of untruthiness. Not that even the selection of the actual training corpus for each new training round is guaranteed or even likely to be not biased in some ways either.
-
15 minutes ago, Lipko said:
Eons have passed since the last reply. Any new experiences?
Your time scale definitely seems skewed in terms of the grand scheme of the universe and all that. 😁
Or did you mean to write Atoms instead of Eons? 😎
I consider ChatGPT and friends still mainly a fairly advanced parrot.
-
21 hours ago, ShaunR said:
SNDCSDLM.dll depends on cvirte.dll. You can check it's deployed on the target machine with Dependency Walker. It's always deployed on development machines so maybe that's the issue. Something easy to check and eliminate.
Shaun already pointed you at the culprit. There is one potential pitfall however. CVIRTE.dll is the same for LabWindows/CVI as is LVRT.dll for LabVIEW. It is the Runtime Engine that contains the entire business and support logic for executing LabWindows/CVI compiled DLLs and executables. And it has similar versions as LabVIEW too. So depending on in which CVI version the DLL was created, you may need to make sure you install the correct CVI Runtime version on that PC. Similar to LabVIEW, CVI also started to use an upwards compatible Runtime library somewhere around 2015 or 2016 I think. But if your DLL was compiled in an earlier version of LabWindows/CVI, things are listening a lot more narrow.
CVIRTE is used by several tools in the NI software stall (Not everything is developed in LabVIEW and not even everything in LabWindows/CVI, some tools are directly developed and compiled in MSVC). But some of the plugins in NI Max such as the instrument control wizard and similar are developed in LabWindows/CVI. So if you install a typical NI Development machine, that runtime library is absolutely sure to be present, but on a minimal LabVIEW runtime only installed machine, it is not automatically there. And none of the typical LabVIEW Additional Installer containers includes it.
The real problem is likely the developer of your SNDCSDLM.dll. S/he would know that they used LabWindows/CVI to compile that DLL and they should have provided a proper installer for this component that also takes care of installing the right version of the CVI Runtime to the target machine. Simply adding such components as a dependency in your LabVIEW project makes you automatically responsible to care about this yourself! And yes it is cumbersome, but there is no easy solution to this, other than the fact that the original developer of a component SHOULD provide a proper installer (and any user of such a component SHOULD include that installer as part of their own application installer rather than just copy the DLL alone into their project).
-
1
-
-
40 minutes ago, Harris Hu said:
As far as I know, if LABIEW and Siemens PLC transmit data through OPC, the structure can also be read. Maybe I need to understand how OPC does it.
That's simple. OPC is a completely different protocol layer. You need an OPC capable server (which last time I checked was an additional licensed component) in your PLC to do that. Part of the OPC UA protocol is to enumerate all the available resources on a system. That includes data items and their data type. And the NI OPC library has an extensive part that converts between the OPC wire data and the actual LabVIEW data in a seemingly transparent way.
Snap7 (and all the other S7 Toolkits out there) communicate through the Siemens S7 protocol, which is based on ISO on TCP as basis protocol, and while the ISO protocol is an officially documented protocol, it is only the container frame in which Siemens then packs its own S7 protocol elements. And those S7 protocol features were never officially documented by Siemens, but the original protocol that only addresses fixed DB, EB, AB, MK elements was reverse engineered by projects like libnodave and then Snap7. No such reverse engineering has happened for the extended protocol elements present in the 1200 and 1500 series that support accessing "compressed" elements.
-
On 5/13/2023 at 5:39 PM, Neon_Light said:
I am afraid you are correct, the C I did was low level ANSI... I bought a book to learn C++, but I am afraid to have landed in a chicken egg situation: I really want to finish this project so I can start with the book but I am losing a lot of time finishing this project because the lack of knowledge. I can copy and understand parts from the internet, but without the overview which a book can give ... ow well I think you get the point. Anyway your answer helps me a lot I hope I can start reading the book soon.
Is my assumption correct that:
I only need a handle if the size of the data is unknown e.g. the struct with a unknown string size?
But when I do something like this:
typedef struct { int firstInt; int secondInt; int thirdInt // The string is gone !! Now I know it is 3 x int = 12 bytes }structSample; ..
Then I do not need a handle?
Thanx again Rolf!! Your help is great!
Handles are only used for arrays (and a LabVIEW string is also an array of ASCII bytes).
Now, when you start to do arrays of structures, things get really fun, but yes it is an array so it is a handle too.
-
On 5/13/2023 at 4:07 PM, ShaunR said:
Me neither so I'm stealing that snippet.
While it's not a problem for this specific datatype, you should do something extra for any struct definition, which I forgot in my example above!
#include "extcode.h" // This is logical to get the definitions for the LabVIEW manager functions #include "hosttype.h" // Helpful if you also intend to include OS system API headers ...... // Anything else you may need to include #include "lv_prolog.h" // This is important to get correct alignment definition for any structured datatype // that is meant to interface directly to LabVIEW native diagram clusters typedef struct // This datatypes elements are now properly aligned to LabVIEW rules { int32_t firstInt; int32_t secondInt; int32_t thirdInt; LStrHandle lvString; } MyStruct, *MyStructPtr; #include "lv_epilog.h" // Reset the alignment to what it was before the "lv_prolog.h" include ..........................
As mentioned for this particular cluster no special alignment rules apply for 32-bit as all 4 elements are 32-bit entities. In LabVIEW 64-bit the LStrHandle (which is a pointer really) is aligned to 64-bit, so there are 4 extra bytes added between thirdInt and lvString, but LabVIEW also uses the default alignment of 8 byte (64-bit) so the alignment is again the same independent if you use those lv_prolog.h and lv_epilog.h includes or not. But in LabVIEW 32-bit full byte packing is used (for traditional reason), while most compilers there also use 64-bit alignment rules. Therefore if the natural alignment of elements does cause extra filler bytes, it will not match with what LabVIEW 32-bit for Windows expects for its clusters.
-
2 hours ago, Neon_Light said:
Hello to you all,
Sending a cluster with int's
I did manage to send an array with clusters from a dll to Labview. Thank you all for the help. You can find the link here:
It works fine I am very pleased with it. 😃
Sending a text string
I did got a example here:
Tested it and it works fine. Again I am happy 😃
Sending a cluster with int's AND a string
Now I want to send a cluster / struct with a couple of int's AND a string of text. I Got a example of how to send text from a C / C++ wrapper to Labview, can someone please help me out? The thing I do not get is, how to combine the both examples. Is "sizeof(structSample)" valid with a LStrHandle in it? How do I copy the data from the string to the struct, etc. Can someone change the code example or help me with the example so it works? I did add some text to the example code to make it more clear I added +++ signs in my comment in the code.
Hope someone can help me. Thanx !
// LVUserEvent.cpp : Defines the entry point for the DLL application. // #include "stdafx.h" #include <stdio.h> #include "LVUserEvent.h" #define STRING_LENGHT 256 //Can be any size // ++++ I want to send this Cluster/Struct to Labview typedef struct { int firstInt; int secondInt; int thirdInt // +++++ I try to add this, Gues this will not work .. see extcode.h LStrHandle textString[TEXT_STRING_SIZE]; }structSample; typedef struct{ int32_t size; structSample elm[1]; }totalstructSample, **structHdl LVUSEREVENT_API void SendEvent(LVUserEventRef *rwer) { LStrHandle newStringHandle; //Allocate memory for a LabVIEW string handle using LabVIEW's //memory manager functions. newStringHandle=(LStrHandle)DSNewHandle(sizeof(int32)+STRING_LENGHT*sizeof(uChar)); // +++++ OW no another one ... structHdl = (eventHdl)DSNewHandle(sizeof(totalstructSample)); Sleep(2000); PopulateStringHandle(newStringHandle,"+++ Dear int I don't want you in my PostLVUserEvent"); //Post event to Event structure. Refer to "Using External Code //with LabVIEW manual for information about this function. PostLVUserEvent(*rwer,(void *)&newStringHandle); return; } void PopulateStringHandle(LStrHandle lvStringHandle,char* stringData) { //Empties the buffer memset(LStrBuf(*lvStringHandle),'\0',STRING_LENGHT); //Fills the string buffer with stringData sprintf((char*)LStrBuf(*lvStringHandle),"%s",stringData); //Informs the LabVIEW string handle about the size of the size LStrLen(*lvStringHandle)=strlen(stringData); return; }
You clearly have not much C programming experience. Which of course is a very bad starting point to try to write C code that should then interoperate with LabVIEW.
First this:
// +++++ I try to add this, Gues this will not work .. see extcode.h LStrHandle textString[TEXT_STRING_SIZE]; }structSample;You are basically defining a fixed size array of TEXT_STRING_SIZE LabVIEW string handles, not a LabVIEW string handle of TEXT_STRING_SIZE length. LabVIEW string handles are never fixed size but instead dynamically allocated memory blocks with an extra pointer reference to it. And that dynamic allocation (and deallocation) ABSOLUTELY and SURELY must be done by using the LabVIEW memory manager functions. Anything else is nothing more than a crash site.
What you have built there as datatype would look like an array of structs and each of these structs would contain three integers followed by 256 LabVIEW string handles, which is not only pretty weird but absolutely NOT compatible with any possible LabVIEW structure.
And after allocating all these things you eventually only send the actual string handle to the event and leak everything else and the handle itself too!
typedef struct { int32_t firstInt; int32_t secondInt; int32_t thirdInt; LStrHandle lvString; } MyStruct, *MyStructPtr; MgErr CreateStringHandle(LStrHandle *lvStringHandle, char* stringData) { MgErr err; size_t len = strlen(stringData); if (*lvStringHandle) { err = DSSetHandleSize(*lvStringHandle, sizeof(int32_t) + len); } else { *lvStringHandle = DSNewHandle(sizeof(int32_t) + len); if (!*lvStringHandle) err = mFullErr; } if (!err) { MoveBlock(stringData, LStrBuf(**lvStringHandle), len); LStrLen(**lvStringHandle) = (int32_t)len; } return err; } MgErr SendStringInSructToLV(LVUserEventRef *userEvent) { MyStruct structure = {1, 2, 3, NULL); MgErr err = CreateStringHandle(&structure.lvString, "Some C String!"); if (!err) { err = PostLVUserEvent(*userEvent, &structure); DSDisposeHandle(structure.lvString); } return err; }
-
2
-
-
No that should not happen. When the Write loop wants to access the DVR it is either locked or not. When it is not there is no problem. When it is, the IPE in the Write loop is put on a wait queue (with other stuff in the diagram still able to execute and as soon as the DVR is unlocked this wait queue is queried and the according IPE woken up and passed control with the newly locked DVR. If the Read loop now wants to access the DVR, its IPE is put on that same wait queue as a Read access is not allowed as long as the DVR is locked for ReadModifyWrite access.
Two Read accesses on the other side could execute in parallel as there is no chance for a race condition here.
-
7 hours ago, Bobillier said:
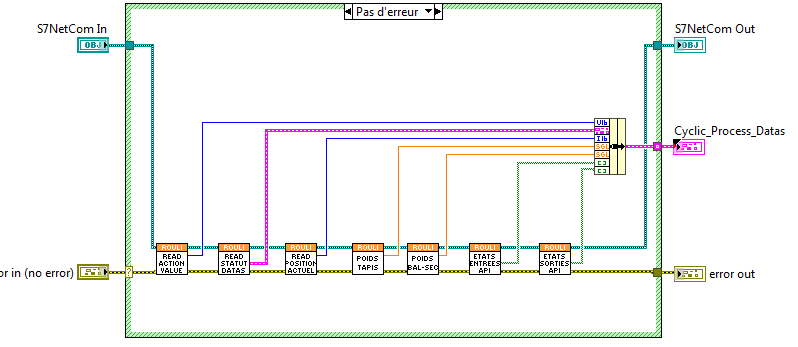
Like I said before, it's not possible because In TIA struct (Like array) is a decorative declaration. It's just to facilitate the visualisation of a group of few data types in a same entity in TIA. But there is no sens of that in PLC, where struct datas are stored sequentially without adding information about the struct itself.
And like with S7 communication you can only accedd to memory, you can only acceed to few bytes list and define from this adress to this adress it's one int or one real. no information about struct it's self in memory. You need to collect each data type and recreate struct after like in my image.
It's not impossible but it is also not something the typical toolkits support. The low level functions used underneath are based on requesting a number of bytes from a certain address in a certain DB element, then convert this as binary data to the actual LabVIEW datatype. For the standard scalar data types, all the S7 toolkits out there provide ready made functions that convert the actual bytes to and from floating point data, integers, timestamps, and even strings but so called complex data types are not something they can support out of the box without a lot of extra work.
But it is your responsibility to make sure that the DB address you specify for an actual read or write access is actually the datatype you used according to the VI. If you use a Read Float64 function for a specific address but the PLC has a boolean or something stored there, you simply read crap.
To support structured data we can not have ready made VIs that would provide an out of the box functionality. For one there are really an indefinite amount of possible combinations of data types when you add complex (struct type) data types to the recipe. And it is obvious that nobody can create a library with an indefinite amount of premade VIs.
So we would have to do some dynamic data parsing but that is not trivial. It could be done with Variant parsing code in LabVIEW where we try to map a specific LabVIEW cluster to a structured data type in the PLC memory. But this is quite involved and still leaves the problem of the user needing to be able to actually determine the correct cluster elements and order to map nicely to the PLC memory structure. A can of worms and a complete support nightmare as there will be lots and lots of support requests in the form of "It doesn't work!!!!!"
The static S7 protocol as "documented" by the various libraries out there does not support datatype discovery from the PLC from a remote site. Siemens introduced a new memory model with TIA 13 or so that supports so called compressed DB elements with symbolic naming. Here the various data elements do not have a fixed address anymore but are aligned in memory to be optimally filling things. To be able to still read and write such elements, Siemens added a new protocol layer that allows to enumerate the actual elements in the DBs, retrieve their current dynamic address (a variable can end up at a different address every time you make any changes to the PLC program and deploy it) and then access it. This protocol extension, as the entire S7 protocol actually, has not been officially documented by Siemens for external users. Some commercial libraries have tried to support it, such as Accon AG-Link but I'm not sure if they did reverse engineering or if they have an NDA with Siemens to get that information. I'm not aware of any other 3rd party library that would support this and definitely none of the Open Source ones have ever tried to go there.
-
4 hours ago, David Boyd said:
When I came across Darin's QR library, it did inspire me to offer up a solution for Data Matrix. As I noted in my readme/release notes, I thought "how tough could it be?". After reading the ISO 16022 standard I think I nearly had a brain hemorrhage!
I'm not entirely sure if that applies to every ISO standard, but that reaction is usually mine too. They tend to be complicated, involved, lengthy and almost incomprehensible. RFC's also have a tendency to contain a lot of verbiage and not really come to the actual meat of it very soon, but they at least have usually some actual description and even occasional examples. ISO often just seems like a lot of bla bla and it is rather difficult to distill the actual useful information out of it.
-
Yes it of course depends on the target you are compiling for. The actual application target, not the underlying OS. It's the same for pointers and size_t datatypes (at least in any system I know of. There is of course theoretically a chance that some very obscure compiler chooses a different type system. But for the systems that are even an option for a LabVIEW program, this is all the same).
-
1
-
-
On 5/3/2023 at 2:01 PM, dadreamer said:
First, C unions are special data type that allows for multiple data types to be stored in the same location. Therefore you don't need to bundle each and every field defined in your header for that union. The union length is set by the longest field. So you should pass 4 bytes in both of your cases. It's up to the code on how to interpret that union onwards: either as uint32_t "value" or as four uint8_t fields struct.
Second, you have two pointers in your main struct (pImagePtr and pUserPtr). You should pass them as 32-bit fields in 32-bit LabVIEW or 64-bit fields in 64-bit LabVIEW. To satisfy both cases, use Conditional Disable Structure with two cases for 32- and 64-bits accordingly. Now you're passing U8 fields, that will likely lead to writing to the neighboring fields inside the shared library. The same applies to size_t parameters (read here for details).
Maybe it would even be easier to make two different structs for 32- and 64-bits in Conditional Disable Structure instead of defining each parameter separately.
Totally correct so far but you forgot that size_t is also depending on the bitness, not just the pointers itself. So these values also either need to be a 32-bit of 64-bit integer value.
-
1
-
-
On 4/19/2023 at 3:55 PM, bna08 said:
This is what I am actually doing already. The question is if IMAQ Image pixels pointed to by the pointer obtained from IMAQ GetImagePixelPtr can be cast to a LabVIEW array.
Daddreamer is correct. An IMAQ image is NOT a LabVIEW array, not even by a very very long stretch. There is simply no way to treat it as such without copying the data around anyhow!
-
On 3/1/2023 at 12:06 PM, Mattia Fontana said:
Thank you very much, I already had the correct version of the library and the second option (manually copying the file to the /usr/local/lib/ sbRIO folder) worked.
It is still impossible to do it with MAX since after installing a base Linux RT image to the sbRIO, it is then impossible to add custom software without reformatting the device memory, while it was possible in previous LabVIEW/MAX versions.
Thanks again!
Yes since LabVIEW 2020 or 2021 one would need an .ipk to be able to install software on an RT system. I haven't yet come to create such a beast but am working on a general update to the library currently. It's just that there are so many other things to tackle too. 😎
-
2 hours ago, ShaunR said:
Having played a bit, it doesn't look that straightforward.
The main idea, it seems, is that you create callbacks that allocate and free the
CRYPTO_EX_DATA(which is required for the get and set) but if they are all set to NULL in CRYPTO_get_ex_new_index then you must use CRYPTO_EX_new which would have to be a global and there is no way to associate it with the SSL session.This seems a lot harder than it should be so maybe I'm not seeing something.
It depends what you consider a lot harder. The basic function gets you a pointer sized slot to store whatever you want. If you manage allocation/deallocation of that data structure yourself you can get away with NULL callback parameters and only need the set and get functions to store the pointer and get it out back.


Close TCP
in Remote Control, Monitoring and the Internet
Posted · Edited by Rolf Kalbermatter
It depends what was the reason of the loss. If the connection got lost because the remote side disconnected, then yes you absolutely SHOULD close your side of the connection too. Otherwise that refnum will reserve resources, for one for itself, as well as the underlying socket which also needs to be explicitly closed.
So when in doubt ALWAYS close LabVIEW refnums explicitly through the proper close node even if the underlying resource has been somehow invalidated. The only time you do not need to do that is if the refnum got autoclosed because the top level VI in whose hierarchy the refnum was created got idle.