

Rolf Kalbermatter
-
Posts
3,909 -
Joined
-
Last visited
-
Days Won
270
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Rolf Kalbermatter
-
-
47 minutes ago, ShaunR said:
Termination characters, for a start.
")
I would echo what Rolf is saying. With SCPI you can get some of the way there as it standardises instrument behaviours - but even then it' has limitations.
IMO, the most expedient way to develop when you don't have the hardware is to use stubs rather than simulators. Design top-down and use stubs where you would have a driver to give you a value and an error that you can can use to develop and test the rest of the software. When you get the hardware, you can use the stubs as an interface to a driver to massage whatever it gives into a form your software is expecting. You will, to all intents and purposes, be designing a proprietary interface for your particular software that you glue drivers underneath as and when you get your hands on them.
That's usually the way I work too. And since there are classes I usually create a base class that is a simulation, dummy or whatever you want to call it version and then a derived one that is the actual implementation, possibly with another one that is for a different similar device or over another bus interface.
My experience about trying to create a universal, generic class hierarchy for one or more device types is that it is a never ending story that will make you go back and forth over and over again as you try to shoehorn one specific instrument feature into the existing class interface to eventually notice that it breaks another feature for a different interface in the same place. Basically it is a noble pursuit to try to do that, but one that fails sooner or later in the reality.
-
54 minutes ago, CT2DAC said:
Why not bring some of that knowledge to help poor old engineers having to do with low-tech serial devices (while awaiting delivery)?
Most likely because everybody says that same sentence, waits for our savior to bring the holy grail and then forgets about it after said savior hasn't arrived within a month or two. Some creating their own limited version of it but never bothering to go the extra mile to post it somewhere for others to not have to wait for that savior anymore. 😁
-
3 hours ago, X___ said:
Some of the earlier patents (still listed in Help>>Patents...) have long expired. The latest is dated 2014.
Sure you could nowadays create almost a clone without fearing an NI letter to arrive. But who wants to do that?
-
1 hour ago, CT2DAC said:
Hello All.
I have the need for instrument simulators, that I can use while developing and the instruments are not physically available.
Think of any RS232, or ETH instrument: dmm, motion controller, hardware interface, sensor, whatever.
I would like to have a piece of software that I would "connect" to and send commands. This sw would basically do syntax checking and reply with error codes in case of invalid syntax or with some 'valid' reply - a 'simulated' dmm would reply with a random value (maybe within a range). [I know of IVI instrument simulator, but this offers a limited number and, most often, my instruments are not IVI/SCPI compatible].
Now, the main issue is that I would like to avoid writing a specific simulator for every instrument I come across with; it would be time consuming and error prone, defeating the whole purpose of working with simulators (which is mainly getting ahead and saving time, while waiting for instruments to become available).
I would like to have the syntax specified in a text file (I know the commands syntax from the instrument manual, much like: CMD param1 -OPT1=param2... etc.). It resembles what command line interpreters, language compiler preprocessors do, based on a syntax/grammar description (abstract syntax tree?).
Searching on the net gives out a lot of stuff; however everything is specifically targeted for for windows, linux and other programming languages.
I could not find anything "programmable" or general purpose.
I came across a couple of posts - Exterface by Daklu and Gold Parser Engine by Taylorh140 - which seem to point in the 'right' direction but I can't seem to find any code to work on.
Is there anyone out there that can point me towards any kind of resource - not necessarily LabView - that can perform as I "dream of" and from I can learn/use?
This kind of idea comes up frequently and various people have tried to solve it. In the end almost everybody ends up writing a simulator for his specific device and then moves on, since there are other projects to be done that deliver income. Writing a generic simulator sounds like a good idea, until you start to work on one. First problem, lots of instruments have very different ideas of how they want to behave on invalid input, wrong sequences and conflicting settings. Some simply go into a lock mode that you have to take them out of, sometimes with a literal kick in the ass by pushing the power button. Others will refuse wrong settings and some ignore it and act like there has nothing been sent. A few try to be smart and will change anything needed to make the new settings work, even though you told them in the previous command to go into this or that mode.
The next problem is often that writing the specific command instruction file for your generic simulator is almost as trouble some as implementing it from scratch. Either simulator only supports the most trivial command response pattern and the command instruction file is trivial but the behavior of your simulation is far from close to your actual device, or it supports many modes and features and your command instruction file is getting complicated too. And almost with every new device you want to simulate you are pretty sure to need to go into your simulator to add an additional feature to support some quirk of your new device.
The end result is that there are many people with good intentions to write such a beast and none who goes beyond a simply device specific simulator, and even that one is seldom really simulating the real thing close enough to be able to test more than that your program works if everything is going right, which in reality it often doesn't.
-
On 1/31/2023 at 7:42 PM, bjustice said:
I really wish LabVIEW had a more full-featured custom control editor.
That custom control editor is one of the more arcane parts of LabVIEW. It exists since at least LabVIEW 2 and has seen only small improvements since. And according to its original creator back at that time it is a pretty nasty piece of software code that would need a complete rewrite to be able to make more elaborate modifications to it. Chances for that to happen are about 0.0something % nowadays. Unless someone somewhere is willing to pour a few millions into this. 😎
-
 1
1
-
 1
1
-
-
2 hours ago, ShaunR said:
Me neither. What exactly are "the LabVIEW suite of offerings"? (Please don't tell me BridgeVIEW or whatever they are calling it now
)
My snarky response would be LabVIEW NXG. 😀
More realistically you could consider the LabVIEW realtime and LabVIEW FPGA as parts of a bigger suite.
BridgeVIEW morphed into the LabVIEW DSC (Data Logging and Supervisory Control) Module long ago (LabVIEW 7 or so), which is an addon, similar to Vision Control and such. But it is legacy: 32-bit only, not really improved for a long time, it is still using SQL Server Express 2012, which is not compatible to the latest Windows versions.
-
1 hour ago, Reds said:
We have been particularly impressed with NI’s portfolio including modular intelligent devices and the LabVIEW suite of offerings, as well as NI’s industry stewardship over many decades in this space. Combining NI with Emerson would lead to significant opportunities for both of our teams and further develop our position as a premier global automation company.
I'm not convinced. They either have no idea about how complicated LabVIEW is or just hoped they could put some sand in the NI managers eyes by teasing them with what they thought is still NI's pet child.
-
On 1/29/2023 at 6:06 PM, X___ said:
As far as I am concerned, the writing has been on the wall a long time ago as far as LabVIEW was concerned. What saddens me the most is that its graphical paradigm hasn't percolated (much) in other languages (Node-Red and some other experiments being rare and not-so-impressive exceptions).
That is partly NI's work. They were pretty aggressive about defending their idea by applying for quite a few patents and defending them too. Of course if you go to the trouble to apply for a patent you have to be willing to defend it, otherwise you eventually loose the right to a patent anyways.
And they did buy up some companies that had something similar to LabVIEW, such as DasyLab for instance, although in my opinion DasyLab didn't quite go beyond the standard "wire some icons together" similar to what HPVee did, and what Node-Red is doing too. But they tried to use some structures that were darn close to LabVIEW loops and that was a prominent NI patent. So NI eventually approached them and made them the offer to either buy them or meet them in front of a judge. The rest is history.
-
 1
1
-
-
46 minutes ago, ShaunR said:
But I was thinking more of VI server being the interface for LabVIEW as a back-end, function server so that in addition to the above, it could also act as binding for other languages (RPC). They did something similar with their webserver where you could call functions but it was a hideous solution requiring deployment of the NI Webserver and Silverlight etc. You could map a web page address to a VI to call. VI server has much finer granularity than just user VI's and, IMO, should have been the starting point.
Well, I do have a VI library that can talk VI Server, at around LabVIEW 6 to 7. The principle seems still pretty much the same, but there were a few zillion new attributes and methods added to the VI Server since, and classes, and what else.
-
1 hour ago, ShaunR said:
IMO, LabVIEW's biggest weakness is the UI. Python isn't a good improvement on that and vice-versa. LabVIEW would also be a very expensive and cumbersome development tool just for planning and maintining python applications. Perhaps a more realistic solution would be to improve the LabVIEW VI server so that it could interface with other languages directly using TCP - make it more like an RPC interface. That may scratch your Python fetish itch.
Actually, as far as the UI goes it depends quite a bit what you want to do. For fairly simple UIs that "just work" it's still an amazing easy system. If you want to support the latest craze in terms of UX design, then yes it is simply stuck in how things were 20 years ago. Basically if you need a functional UI it works fairly easy and simple, if you need a shiny UI then LabVIEW is going to be a pain in the ass to use.
Nowadays Beckhoff and Siemens and others have their own UI solutions too, but in comparison to them LabVIEW is still shiny and easy. Beckhoff does have the advantage that their UI is HTML5 based so easy to remote but it looks like a stick figure compared to a Van Gogh painting when you compare it to a LabVIEW front panel.
My dream was that they can develop something that allows the LabVIEW front panel to be remoted as HTML5, but seeing the Beckhoff solution I start to think that this project failed because they did not want to settle with simple vector graphic front panels but wanted to have a more native looking impression in the web browser.
And yes documenting the VI Server binary TCP/IP protocol and/or adding a REST or similar protocol interface to the VI server would be an interesting improvement.
-
18 minutes ago, ShaunR said:
I think the C compiler was (or was based on) on the Watcom compiler.
No, Watcom C was used to compile LabVIEW and LabWindows CVI for Windows 3,1 because it was pretty much the only available compiler that could create flat 32-bit code at that point and absolutely the only one that supported this on the 16-bit Windows platform.
They did not have a license to use the compiler in there and it was several years before Watcom faltered and a few more years before its sanitized source code was open sourced. It still exists as open source but activity on that project is very dead.
-
29 minutes ago, ShaunR said:
I always felt they could have had a tighter integration between LabVIEW and CVI. It could have solved our lack of being able to use C callbacks for a start. A CVI node like the Formula node could have been quite useful.
LabWindows CVI did use a lot of LabVIEW technology originally. Pretty much the entire UI manager and other manager layers such as File IO etc were taken from the initial LabVIEW 2.5 version developed for Windows. On top of that they developed the LabWindows/CVI specific things such as function panels, project management and text editor etc. The C compiler was their own invention I believe. Later, around 2010 or so they used replaced the proprietary compiler in LabVIEW with LLVM as compiler backend and after that they used that knowledge to replace the LabWindows/CVI compiler with the same LLVM backend.
Callback support in LabVIEW, while not impossible to do (ctypes in Python can do it too). always was considered an esoteric thing. And IMHO not entirely incorrectly. The problem isn’t so much the callback mechanisms itself. Libffi is a reasonable example how it can be done although I’m sure if you dig in there it takes you a few days to understand what is needed just in a Windows application alone. The much more difficult thing is to allow a configuration in the Call Library Node that doesn’t require a PHD in C programming to configure it correctly to match the callback function correctly and the mapping from the callback function parameters to the callback VI inputs and outputs.
ctypes in Python is much more straightforward because Python is a procedural language like C and even there you have only very few people who can handle normal function calls and virtually nobody who gets the callback functions right!
-
6 hours ago, X___ said:
Who probably wouldn't mind a few extra 100 million dollars for... what about spinning off G and funding an open source project making a graphical Python-based LabVIEW?
Sorry but you are talking nonsense here. I don’t mean the part about Jeff spinning off a new company with that money although I think that’s not very likely, but a Python based LabVIEW is just utter nonsense.
LabVIEW is written for maybe 95% in C/C++ with a little Objective C and C# thrown in, and reimplementing it in another language would take only 10 to 20 years if you are lucky. If you want to make it reasonably compatible you can add another 10 years at least. And that is not even considering the abominable performance such a beast would have if you choose Python as basis.
Reimplementing LabVIEW from ground up would cost likely 500 million to 1 billion dollar nowadays. Even NXG was not a full redesign. They tried to replace the UI layer, project management and OS interface with C# and .Net based frameworks but a lot of the underlaying core was simply reused and invoked with an Interop layer.
And a pure LabVIEW based company would be difficult. The current subscription debacle was an attempt to make the software department inside NI self sustaining by implementing a serious price hike. At the same time they stopped LabWindows/CVI completely which always had been a step child in the NI offerings together with most other software platforms like Measurement Studio. They earned very little with them and did not invest much in them because of that, which made them of course a self fulfilling failure.
There is only a relatively small development team left for LabVIEW, apparently mostly located in Penang, Malaysia, if I interpret the job offers on the NI site correctly and they are probably scared to death about the huge and involved legacy code base that LabVIEW is and don’t dare to touch anything more substantial out of well founded fear to break a lot of things with more involved changes.
I think what LabVIEW needs is a two version approach. One development branch that releases regular new builds where developers are allowed to make changes that can and very likely will break things and to work on them and improve them gradually and once a year or even once every two years all the things that have proven to be working and stable are taken over into the LTS branch that professionals who pay a premium to use this version, can use with a 99% assurance that nothing important breaks.
You want to play with cutting edge features and don't mind to receive regular access violation dialogs and other such features? You can use our development release which costs a modest license fee and if you promise to not use it for anything that earns you money you can even use the community license with it.
You expect rock solid performance and no crashes and bugs that are not caused by other things such as third party additions or your hardware/OS?
Here we have an LTS version! It does not contain the latest gadgets and features and toys but we can assure you that everything that is in it is absolutely rock solid. And yes this has its price but if you use this you can be sure to focus on solving your problems and not worrying about quirks and irks in our software!
-
9 hours ago, Reds said:
I didn't quote the part where he explicitly states his disappointment with NI's "execution" and how it has lost focus on it's "stakeholders" including customers and partners. Check out the article and decide for yourself. I mean, he's not wrong if you ask me.
Well I can assure you that he was not the person who would blindly follow shareholder value and forget everything else. I have talked with him personally on several occasions and he was as approachable as you can get. When you talked with him it was not as a number in the employee list or as an expendable necessity to run his company but as a human and he felt honestly interested in talking with you, not just as a social nicety.
He was the old style boss who cared more about his company and the people who worked there than sales and profit, which were a mere means to make his company and the people working there to succeed and prosper, not a means in itself.
Could he have decided to stop LabVIEW? Probably if he had seen that it gets a sinkhole for his company. Would he have stopped it because it cost a bit more than the company can earn from direct license sales? Certainly not, since he did clearly see the internal synergies.
So yes I’m sure he isn’t happy about what the current management has done. He likely stood behind the idea to diversify the old NI away from a mostly DAQ centered company that had pretty much reached the ceiling of that market and couldn’t grow much more But I doubt very much that he approved to start throwing away the very roots of his company in favor of new and bolder frontiers.
-
17 hours ago, CIPLEO said:
Thank you Rolf and ShaunR for your answers.
I tested the function "GetValueByPointer.xnode" which works well but as you said when you create an executable it does not work anymore. So I looked at the thread you linked me and I found a second solution which you are also the author working in both cases.
So I have the impression that the second solution is the best in my case.
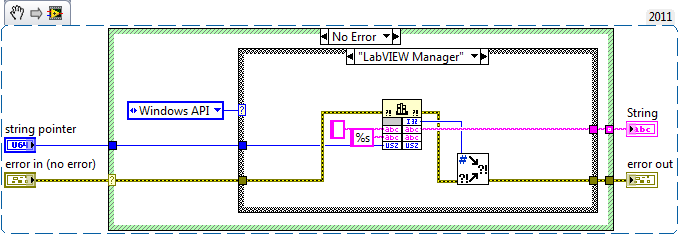
Are there any weak points that I did not see or understand?Are you seriously asking me if my solutions have weak points? 😁 I'm outraged! 😜
Seriously though, the LabVIEW manager function variant and the Windows API variant have a very, and I mean really very very small chance that that function will be broken, removed, changed or otherwise made unusable in a future version of LabVIEW or Windows. The chance for that is however in the same order of magnitude as that you will experience the demise of the universe. 😁
The chance that LabVIEW eventually will cease to exist is definitely greater and in that case you won't have to bother about this anyways.
-
The problem is your configuration of the last parameter of the HFAread function. This function returns the "value". For a string this seems to be the pointer to the internally allocated string as can be seen from your C code:
const char *my_string; H5Aread(attr_id, type_id, &my_string);
What you have programmed in LabVIEW corresponds to this:
/* const */ char my_string[100]; H5Aread(attr_id, type_id, my_string);
That's absolutely not the same!
You want to configure this last parameter as a pointer sized integer, passed as pointer to value, and then use the <LabVIEW>\vi.lib\Utility\importsl\GetValueByPointer\GetValueByPointer.xnode.
But! This function uses a special shared library as helper library that is located in <LabVIEW>\resources\lvimptls.dll. And the LabVIEW application builder keeps forgetting to add this shared library to an application build, assuming that it is part of the LabVIEW runtime engine, but the LabVIEW runtime engine somewhere along the way lost this DLL.
See this thread for a discussion of getting the GetValueByPointer to work in a build application or alternatingly replace it with another function that does not need this DLL.
And it depends also if the variable for the returned value is variable sized or fixed sized. There should be a function that can tell you if this is the case.
For variable sized values, the library allocates the string buffer and you have then to deallocate it with H5free_memory(). For fixed size values you have to preallocate the buffer before calling the read function to size+1 bytes and even make sure to fill in the last byte with 0 and afterwards deallocate it with whatever corresponding function to your allocation.
If you think this is complicated then you are right, if you blame LabVIEW for not doing all this for you, then you blame the wrong one. LabVIEW can't do this for you, it is dictated by the programmers of the H5F library and there is no way in the whole universe that LabVIEW could know about this.
-
2 hours ago, hooovahh said:
I agree, and it does at times sound desperate. But also is this just how things are in the corporate world? Like do they really care how they are perceived if in the end they get what they want? They could offer more money, or they could just first do a marketing campaign. Relatively low risk, maybe it doesn't work out but I'm sure people who are in charge of these kinds of acquisitions have a playbook, that I'm unfamiliar with.
It sorta feels like we are the kids in a divorce proceedings. Just going along with little or no influence on what happens to us. I hope weekday dad buys us a new DVD player.
Well in a world where many consider bad publicity many times better than no publicity, you could be very right.
For now the market thinks for several days already that NI is more worth than what Emerson offered. So their whole attempt of appealing to the shareholders to let them have their way does seem to have backfired.
-
10 minutes ago, Neon_Light said:
Thank you Rolf !!
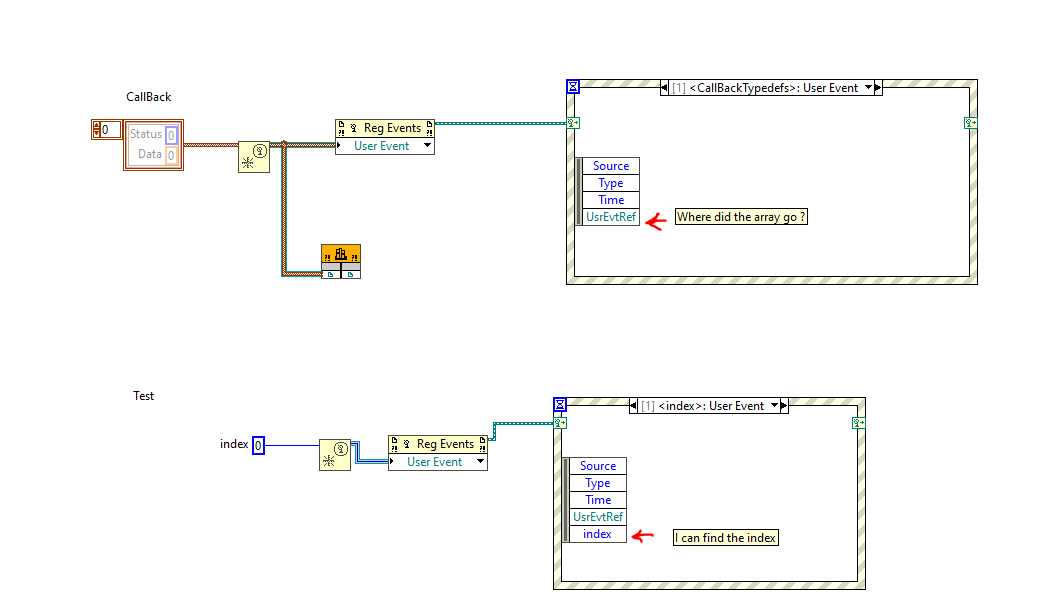
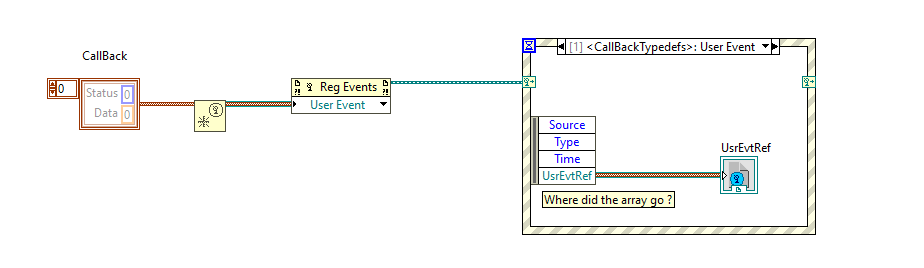
but the thing I can still not find is how do I get acces to the array in the event structure. If I wire a number for example index to the create user event it ends up in the event structure. Wile the callback array does not appear. I added a screenshot, hope that helps.
It's unclear since you still don't want to post VIs but only images so we have to guess. But I would say the array simply has no label. The node inside the event structure only lets you select named elements. The "CallBack" word looks like it may be a label, but it is probably just a free label like the "Test" in the image below.
-
1 hour ago, Neon_Light said:
Hello I did give it a try I am able to compile some C code send some data to the created DLL and receive data from the DLL. So that is great 🙂 thanks !
The original DLL however will return a array with structs to my C DLL I will try to implement thePostLVUserEvent part there . When I try to make an even structure as an experiment I am not able to get the array out again. This makes me think I am not using the event method in the correct way. what will be the best way to get an array from the DLL back to the Labview event? Do I need to send every array element back with a PostLVUserEvent?
There is no real problem to create such an array directly in the callback function, to be sent through the user event. But you must understand that the actual array must be a LabVIEW managed array handle.
Basically something like this will be needed (and you will need to adjust the typedef of the cluster to match what you used in your LabVIEW code, since you "forgot" to attach your code):
#include "lv_prolog.h" typedef struct { int32_t status; double value; } DataRecord; typedef struct int32_t size; DataRecord elm[1]; } DataArrayRec, *DataArrayPtr, **DataArrayHdl; #include "lv_epilog.h" /* if the callback can be reentrant, meaning it can be called while another callback is already executing, use of a global variable for the data array is NOT safe and needs to be handled differently!!!! */ static DataArrayHdl handle = NULL; void yourCallback(.......) { int32_t i, size = somewhereFromTheParameters; MgErr err; if (!handle) { handle = DSNewHandle(sizeof(DataArrayRec) * (size - 1)); if (!handle) err = mFullErr; } else { err = DSSetHandleSize(handle, sizeof(DataArrayRec) * (size - 1)); } if (!err) { (*handle)->size = size; for (i = 0; i < size; i++) { (*handle)->elm[i].status = status[i]; (*handle)->elm[i].value = values[i]; } err = PostLVUserEvent(lvEventRefnum, &handle); } }
The easiest way to actually get the datatype declaration for the array that you need to pass to PostLVUserEvent() would be to create a dummy Call Library Node with a parameter configured as Adapt to Type, and then right click on the node and select "Create C Souce code". After choosing where to write the file it will create a C source file that contains the necessary data type declarations.
-
8 minutes ago, drjdpowell said:
The market presumable thinks the offer will be accepted, possibly at a higher price.
Or that there will be someone else who will offer more. There are several companies that could benefit from an NI integration at least as much and some of them could benefit NI a lot more than Emerson.
-
3 hours ago, SebastienM said:
Anybody knows about this AspenTech software ? :
Immediate, Compelling And Certain Value For NI Shareholders (webflow.com)
They did manage to spell LabVIEW correctly in their letter to the NI board of directors, but that definitely doesn't mean that they are after LabVIEW. Emerson is a company that declared shareholder value as the holy grail of their philosophy. In order to make that holy grail true they need to grow and grow fast and that can not be done through internal grow. So they need to acquire others.
They changed their strategy recently and divested themselves of several large divisions that they consider not being able to add the necessary grow to make their bold targets possible. They even gave up their headquarter for that. They looked around for potential candidates and NI was a very attractive target. They have a considerable internal value and potential grow but did underperform for several years on the stock market. So a relatively cheap buy for a lot of potential. The perfect target to take over to help realize external grow to satisfy the shareholder value promise. And being so keen on shareholder value they figured the best bet is to appeal to the NI shareholders to make them force the board of directors to sell to them. Except that going public with this puts them now in the seat of the hostile raider. And that is what they really are. They don't want NI to integrate all the services and products into their own corporate structure. If they get their mind, they will pick the cherries from the pie and throw the rest in the trash. And no, LabVIEW is not the cherry they are after. That's in their view more an old and withered rose that needs to get chopped off than anything else. It's also not the DAQ boards. What they are after is the test system division, a relatively young part of NI but with a lot of grow potential for quite some time to come. TestStand makes a good chance to be reused, LabVIEW is in that picture at best another test adapter provider inside TestStand besides Python and .Net.
55 minutes ago, ShaunR said:They sound kinda desperate.
Their whole behavior sounds like the little child that sits in a corner and starts mocking because the world doesn't want to give him what it feels is his natural right to have. Somehow it would seem to me that if their target doesn't feel like wanting to sell their company for the price they offer, they have exactly two options: make a better offer that they can't refuse or walk away. But they choose to instead stamp with their feet on the ground and be very upset that their "generous" offer wasn't welcome.
-
Basically the same as Jacobson said. The DMA FIFOs internally are 64-bit aligned. If you try to push data through it that doesn't fit into the 64 bits (8 * 8 bit, 4 * 16 bit, 2 * 32 bit or 1 * 64 bit) then the FPGA will actually force alignment by stuffing extra filler bytes into the DMA channel. In that case you would loose some of the throughput as there is extra data transferred that simply is discarded on the other side. That loss is however typically very low. The worst case would be if you try to push 5 byte data elements (clusters of 5 bytes for instance) through the channel. Then you would waste 3/8 of the DMA bandwidth.
The performance on the FPGA side should not change at all purely from different data sizes. What could somewhat change is the usage of FPGA resources as binary bit data is stuffed, shifted, packed/unpacked and otherwise manipulated to push into or pull from the DMA interface logic.
The performance on the realtime side could change however as more complex packing/unpacking will incur some extra CPU consumption.
-
1
-
-
9 hours ago, X___ said:
I see...nothing.
I had the same reaction.
8 hours ago, ShaunR said:NI's system division is quite weak.
Not the System Engineering Group that tried to make DCAF and similar. They have a different division that you and I haven't seen much of yet but that makes complete test systems for EV, semiconductor and other high value potential industries. I have no idea if they use LabVIEW in them. I'm sure they do use TestStand and probably some LabVIEW adapters to interface to hardware components, but it's definitely NOT a LabVIEW solution.
7 hours ago, Michael Aivaliotis said:Looking for a new profession?
That's very ambiguous, depending on who you directed this message to. 😁
-
13 minutes ago, ShaunR said:
It looks like they are only really interested in the hardware side of the NI business as they are a bit thin on the ground there. For software they seem to be geared towards cloud analytics and control. I don't see much of a place for LabVIEW in their software catalog except for transitioning LabVIEW customers to their platforms.
Possibly, but I think it is not even CompactRIO or any of the DAQ boards. Maybe PXI, but most likely neither. What they want is the test system division which makes complete test systems for the EV, energy and space markets. This are high value systems with an interesting cash flow and a significant grow potential. They want that type of business to make their share holder expectations true. Selling DAQ boards or even LabVIEW license subscriptions doesn't earn enough for that.
Most likely the NI board are already in communication with companies like Danaher, Roper, Agilent, Keysight and others about their potential interest to save them from the Emerson hostile takeover bid. Not sure that either would be better for us users but it has definitely the potential to get a significantly higher share price for the share holders and that is/has to be the main concern of managers in a public traded company, as otherwise they might face accusations of mismanagement and legal actions by the share holders.
")
")
 )
)
MQTT [Decision to make.]
in LabVIEW General
Posted
It's most likely organically grown. Guaranteed green and maybe even vegan. 😁
And grown and groomed by many different "developers".