Rolf Kalbermatter
-
Posts
3,968 -
Joined
-
Last visited
-
Days Won
281
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Rolf Kalbermatter
-

LabView2013 DCOM Problem
Rolf Kalbermatter replied to BadLuckMan's topic in Remote Control, Monitoring and the Internet
You are logged in on that remote computer with an unlocked user session? And connecting to the LabVIEW instance over DCOM under this account? Maybe DCOM executes the LabVIEW process under a different account that has no desktop session available! -
That's a dead end, unless you have VERY good dissassembly knowledge and endless time to tinker with. This DLL control is a real DLL. It is a C++ compiled plugin module that extends the internal object hierarchy by one additional class, each class being a specific LabVIEW control. The virtual table interface of such classes is VERY cumbersome to reverse engineer. Not impossible but REALLY VERY cumbersome. It's much easier to get an elephant to go through a needle hole than doing that! But it doesn't end there. You have to reverse engineer also the interface this class has to use to interact with the LabVIEW internal object model. This object model is loosely coupled with the object model as exposed by the LabVIEW VI Server interface but really only loosely. VI Server exposes some of the methods and properties of it, but by far not all, and is in fact a wrapper around the internal object model that translates between the C++ interface and the more strict LabVIEW VI Server interface. And my investigations into this make me conclude that it is not even fully extensible. The idea probably was to have a fully extensible interface but the controls who make use of this seem to rely on specific functions inside the LabVIEW kernel for itself, so unless one would only want to create slightly different type of existing controls by subclassing them it's probably not even going to work. This seems a very complicated business as there used to be another similar interface way back in LabVIEW 3. At that time the LabVIEW code was fully standard C only, but LabVIEW did anyhow use an internal object oriented UI control object hierarchy with messaging system and assembly written dynamic dispatch. A variant of a CIN code object file was used to add a new control into this control object hierarchy and the Picture Control was an addon package that seemed to use this interface, but in LabVIEW 4 the Picture control C code was fully integrated into LabVIEW itself and this object control interface was left in limbo only to be almost completely removed in LabVIEW 5, when a more extensive new object hierarchy was developed which went beyond just the UI elements and eventually used true C++ dynamic dispatch. The problem with this solution was that while LabVIEW evolved and had to add new object methods to its internal objects to implement new features such as Undo, the external code object created in an earlier version of LabVIEW and being embedded in the user LabVIEW VI, would still implement the older virtual dispatch table that did not have this method, so upgrading such LabVIEW code by the user to a new version would have been a rather problematic thing. Making this interface fully forward and backward compatible is an almost impossible task, but disallowing extension of the method table not an option either.
-
Problem when try to read Interbase Data on Windows 7
Rolf Kalbermatter replied to Fedly Chan's topic in Database and File IO
If you buy LabVIEW now you will get LabVIEW 2014. LabVIEW 2014 can't directly read LabVIEW 4 VIs. Almost 20 years is a long period and they had to do some cut at some point. Here you can see the compatibility table between LabVIEW versions. You will need an intermediate conversion package, which you should be able to discuss with your NI sales representative. It's basically an Evaluation version of LabVIEW 8.2 or 8.5 that can load and recompile older VIs to a format that the most recent LabVIEW version can read. -
Problem when try to read Interbase Data on Windows 7
Rolf Kalbermatter replied to Fedly Chan's topic in Database and File IO
You seem to be using the VERY SUPER old original Database Toolkit with LabVIEW 4!!! You do realize that this software was released about 15 years before anyone even knew that Windows 7 might be released anytime soon???? Are you trying to load LabVIEW 4 on your Windows 7 machine? LabVIEW 4 was originally a Windows 3.1 application that used a special memory manager to support 32 bit operation. There was only a prelimenary version of it that was compiled for and working on Windows NT. While LabVIEW for Windows 3.1 could run in compatibility mode in Windows NT and even 2000, this compatibility mode was just a cludge and would badly fail as soon as you started to acceess hardware interfaces. That is not supported and will almost certainly fail in many different ways! I'm surprised that it even worked on XP even without hardware access but it's a safe bet that Windows 7 has probably broken something that would be necessary to run the Windows 3.1 version of LabVIEW on it. The way in LabVIEW 4 to interface to external code was through so called CINs. LabVIEW has changed a lot since those days and has subsequently removed the ability to create CINs in all versions of LabVIEW and eventually scraped support for loading CINs from all new platforms. This includes any new 64 Bit version of LabVIEW. Or are you using Windows 7 64 Bit and have installed a recent version of LabVIEW 64 Bit for Windows 64 Bit? As explained this version doesn't support CINs. The LabVIEW CINs are compiled binary resources similar to DLLs they have to match exactly the memory model of the LabVIEW application that you use. So there needed to be seperate CINs for LabVIEW for Windows 3.1, LabVIEW for Windows 32 bit, and about three versions of LabVIEW for Mac (Mac OS 9, Mac OS X PPC, Mac OS X x86) but there are none for LabVIEW for Windows 64 bit nor LabVIEW for Mac OS X 64 Bit and never will be. You may find the price of the toolkits expensive but unless you want to work with Windows XP or 2000 you really won't get around upgrading to newer versions. Besides working in LabVIEW 4 is a major pain in the a** in comparison with newer versions of LabVIEW. If you decide to upgrade at least LabVIEW, you can also look in alternative Database Toolkits on the net. There is one called LabXML and another one called ADO-Toolkit. There are others too but no matter which you choose none of them will support LabVIEW 4.0 so an upgrade of at least LabVIEW is unavoidable. Just FYI we are currently at LabVIEW 2014 which is about equivalent to LabVIEW version 14.0 in the old numbering scheme. -
Calling .net and thread starvation
Rolf Kalbermatter replied to John Lokanis's topic in Calling External Code
That sounds like a bad memory! There is a threadconfig.vi in vi.lib\Utility\sysinfo.llb that will configure LabVIEW and write the necessary settings into the LabVIEW.ini file. You can then copy them into your application ini file. That should be managed by Windows. -
Calling .net and thread starvation
Rolf Kalbermatter replied to John Lokanis's topic in Calling External Code
The first approach would certainly be to put your .Net code in a different execution system. That should give your timer code (it is all LabVIEW isn't it?) enough room to do its work. As LabVIEW executes a .Net call the calling thread is basically locked. If you happen to have 8 parallel .Net calls your execution system is blocked. Increasing the number of threads per execution systems is only a bandaid at best. Sooner or later you will manage to use them too and run into problems again. However do you really have that many parallel code execution paths going on that call into .Net? You only have .Net and no ActiveX and Call Library Node calls? -
Silently close a scripted VI with unsaved changes
Rolf Kalbermatter replied to Thoric's topic in VI Scripting
And they may not just change to the better but introduce bugs in never versions, since they are not tested in the normal daily build tests and the internal tool that used them may have been removed or changed to use other functions. They also suddenly can be unimplemented, since as far as NI is concerned they never were documented so removing them is not something they would avoid at big costs when they clean up unused code. As said by AQ and others on various occasions a large internal project is currently to rewrite substantial parts of LabVIEW to get rid of old legacy code that doesn't match the current coding standards anymore and in the process of this it is likely that a lot of old undocumented features will get axed while they are at cleaning up the code, if they are found to be either incompatible with the new architecture or unused by any of the current internal LabVIEW tools. -
Load hex file into avr controller using LabVIEW
Rolf Kalbermatter replied to piZviZ's topic in LabVIEW General
Yes it is, but as pointed out the protocol to download a hex file to the AVR controller seems to be quite involved. If it is fully documented by AVR you can of course try to implement it in LabVIEW but I would expect this to be non-trivial. -
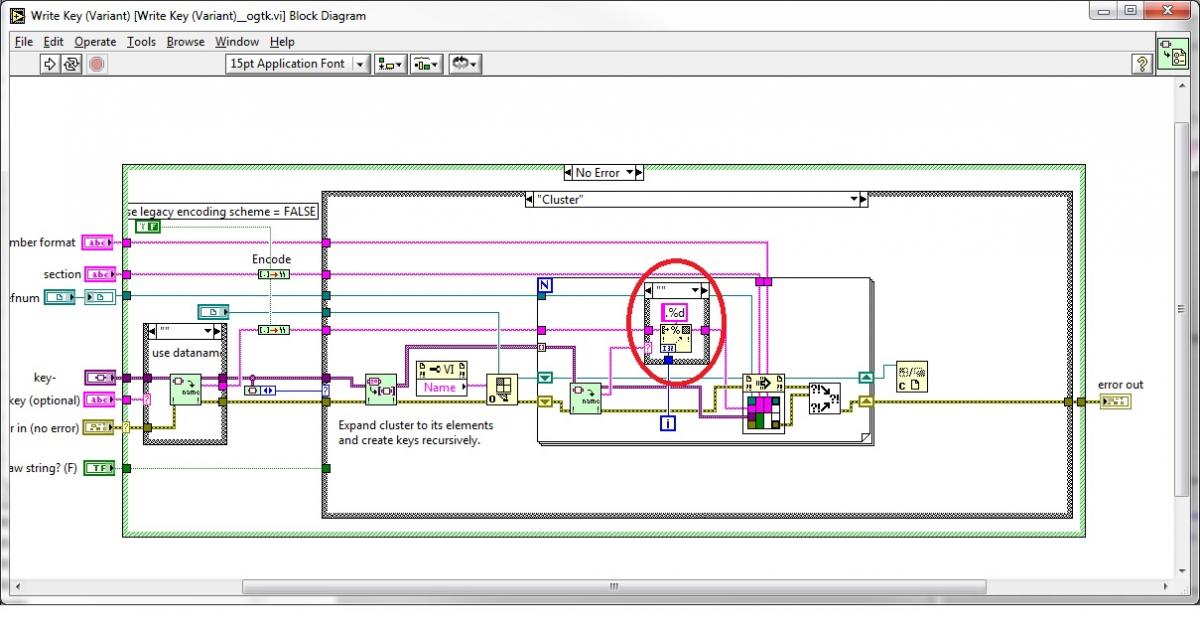
It's discutable if this should work. But the quickest solution for this would be to allow for a small change in the "Write Key (Variant).vi" and "Read Key (Variant).vi" in the Cluster case similar to this:

-
sbrio-9606 Poor performance for sbRIO-9606 USB
Rolf Kalbermatter replied to codcoder's topic in Embedded
Unless you use a truely speced high speed flash pen drive you are likely to keep seeing poor performance. Especially those cheapo give away flash drives (I'm looking at you NI ) have abominable performance, especially for writing. I've found that almost all flash drives that are handed out for marketing purposes seem to be of that super el cheapo quality, and similarly most noname flash drives that you can find in the super market stores. Cost maybe half of a high quality brand drive but perform much less than half that good. -
GOOP Development Suite v4.5 is released
Rolf Kalbermatter replied to spdavids's topic in Object-Oriented Programming
You might be right there. I guess I was assuming that there must be a difference between an initialized object and one that hasn't been initialize yet since there is this Get LV Class Default Value.vi. But I guess any class has as soon as it gets placed on a diagram a cluster and the To More Specific Class simply compares that the underlaying object has a matching method AND cluster definition and in that case copies the class data into the existing cluster. Makes sense from a by val architectural point of view. As such there is indeed no Not an Object but only a Default Data state, which is the equivalent of the Class data cluster having all default data elements. -
GOOP Development Suite v4.5 is released
Rolf Kalbermatter replied to spdavids's topic in Object-Oriented Programming
I didn't mean to indicate that an object reference is a by-ref implementation. But I have a hunch that an object wire on the LabVIEW diagram is similar to other refnums. The use of a refnum doesn't have to mean that the object is by-ref. It's only a matter of how LabVIEW implements the rules to access the underlaying object that defines by-ref or by-value implementation. As such implementation of a "Not an Object" primitive would be not that difficult. But maybe they didn't do that so far as they might want to solve a few more issues with Not a Number/Path/Refnum to allow some distinction between the canonical invalid underlying object type for Refnums and Objects and the once allocated but later destroyed object type. -
Passing array of string to C dll
Rolf Kalbermatter replied to Reikira's topic in Calling External Code
It sure is known when the function returns. So you would need to determine its length after the function returned the array of strings. There is a C runtime function strlen() which does exactly that, and a LabVIEW Manager Function StrLen() which does the same. So calling StrLen() with the CLN just like you did with MoveBlock() on the string pointer will return you the number of characters in the string and then you can do an Initialize Array with that length and then a MoveBlock() to copy the string from the string pointer into the LabVIEW byte array and then convert it with Bytes to String into a String. There is another LabVIEW Manager function LStrPrintf() which combines those two into one convinient function call. The definition is: MgErr LStrPrintf(LStrHandle handle, CStr format, .....); You would configure the first parameter of the CLN as LabVIEW String handle passed by value, the second as C String pointer, and the third as Pointer sized integer. To the first you wire an empty LabVIEW string constant, to the second a string constant containing "%s" (without quotes) and the third is your C string pointer from your array. The output of the first parameter then contains the properly sized string. The return value of the function is an int32 and if not equal to zero indicates a LabVIEW error code. -
How to manage RT code with FPGA refs that runs on Win/Linux/Mac
Rolf Kalbermatter replied to Stobber's topic in Real-Time
This is one topic, but there are more and I've seen some weird errors too especially with the conditional disable structure in the General Error Handler. -
GOOP Development Suite v4.5 is released
Rolf Kalbermatter replied to spdavids's topic in Object-Oriented Programming
That is only half the truth. For an unitialized object reference you are right but for an object reference that has been created and then destroyed the actual refnum value is not null but still not valid anymore! There should be something akin to "Not a Number/Path/Refnum" for object wires. In fact I was at first assuming that LabVIEW objects are inherently also refnums but that seems not really the case. And extending "Not a Number/Path/Refnum" to "Not a Number/Path/Refnum/Object" would seem logical but the resulting long name sounds like a bad idea. -
How to manage RT code with FPGA refs that runs on Win/Linux/Mac
Rolf Kalbermatter replied to Stobber's topic in Real-Time
Conditional disable while allowing a VI to run despite unrunable code in disabled frames can have some strange effects. For one, LabVIEW normally tries to load the VIs anyhow which can result in dialogs during loading for missing subVIs and such. Also there have been strange and hard to reproduce problems with the error list showing errors that only go away after removing and recreating the code in conditional disable frames. -
How to manage RT code with FPGA refs that runs on Win/Linux/Mac
Rolf Kalbermatter replied to Stobber's topic in Real-Time
You create VIs that contain those refnums but you load and call them dynamically through Open VI Reference and (Asynchronous) Call by Reference (CBR)! Usually I create the VI that does the work and a wrapper VI that does the Open VI Reference and (A)CBR and Close Reference. You can make the wrapper as smart as you like adding the logic to decide if it should attempt to load the VI or just bail out without doing anything (or creating a warning or something) in there. Also I usually do some smart caching for the refnum using an uninitialized shift register to prevent opening and closing the refnum over and over again. Last but not least although not very nice from a design point of view I tried in the past to combine multiple operations in one wrapper/dynamic subVI combination since maintaining lots of these in parallel is quite a work load. Another better approach I have considered but which failed in the past with older LabVIEW versions because of some LVOOP limitations is to use the dynamic dispatch feature of LVOOP. You would then create two (or more) classes for the different platforms and a dummy base class and load the appropriate child class dynamically (with Get LV Class Default Value.vi) at start and then call it through the interface provided by the base class. This is IMHO the most clean design for such things. It basically uses the Factory Pattern here. While I'm not yet converted to LVOOP for everything, I find the Factory Pattern a very elegant design method to solve problems where you have dynamic components that you need to access depending on some condition that has to be determined at runtime. Doing it through VI server with (A)CBR is certainly an option but LVOOP dynamic dispatch makes it that more elegant. -
Passing array of string to C dll
Rolf Kalbermatter replied to Reikira's topic in Calling External Code
There is nothing new there as far as iterating the array of strings goes. Instead of a double array you basically have a string. This is a C string in the DLL and you need to MoveBlock() into a LabVIEW handle that you have allocated before with a long enough size. Using Initialize Array with a type of U8 and passing it as C array pointer into the dst parameter of MoveBlock() will do, and after the MoveBlock() call you can convert it to a string with Bytes To String. -
Well, maybe we are not talking about the same. I had a hell of a time (admittedly in earlier versions than 2014) when developing a plugin interface using CBR. Every time I updated the connector pane of the plugin VI in any way (just fixing a typo in an enum is enough) I had to go into every location where I had loaded the plugin through Open VI Reference and relink the strict VI refnum with the new connector pane or the CBR would return an error because the actual connector pane was not matching the expected one. Making the Strict VI Reference a strict typedef didn't seem to help. Since some time I use LVOOP with the factory pattern to implement plugins so have not tried the CBR approach anymore. Some posts on other fora made me believe that it is still a problem even in recent LabVIEW versions. Plugin devolopment is generally a pain in just about any programming environment I have tried. You either have problems at edit time to make sure the interface stays fully consistent or at runtime when trying to load the plugins and often both. The next problem is to make sure the plugins are where your software expects them to be, independent of running in debug mode in your IDE or in the final application. Nothing that specifically more difficult in LabVIEW.
-
But beware. Even if you create a strict typedef of this "Strict VI refnum" control, it will not update its instances if you chance the connector pane of the VI and also change the strict typedef to link to this new connector pane. You have to go into every place where you used this control even if you used the strict typedef, and update it to use the new connector pane. Quite painfull if you try to built a plugin interface. And it's not really unintuitive. It was the only way to open a VI Reference for use with the Call By Reference node, before the static VI refnum was introduced.
-
Passing array of string to C dll
Rolf Kalbermatter replied to Reikira's topic in Calling External Code
I was wondering about that when I wrote the VI, but I just didn't feel like creating a real DLL and trying it out in the debugger. Figured you could solve that problem yourself if it turned out to be necessary. To append something to a reply post you have to click the "More Options" button to the right of the "Post" buttion. This will give you the choice to switch into the full editor which allows to attach files (and insert images that you have uploaded as attachement). Had to search myself for that. It seems these forum board softwares like to hide that option under strange buttons names. Also if you chose to edit your previous post you get into an editor with a somewhat more meaningfull button besides the "Save Changes" button called "Use Full Editor" which goes into the same editor as the other option in reply mode. -
Passing array of string to C dll
Rolf Kalbermatter replied to Reikira's topic in Calling External Code
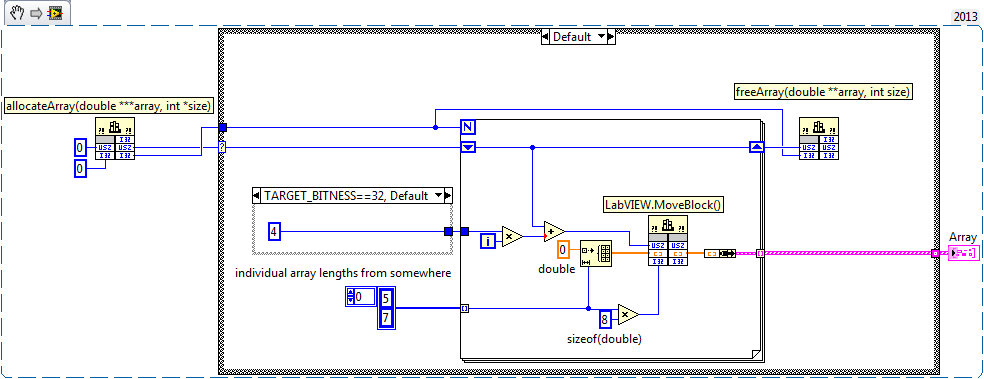
Something like this should probably work. But beware it's not tested in any way. Test Array Pointers.vi
-
Passing array of string to C dll
Rolf Kalbermatter replied to Reikira's topic in Calling External Code
And where in this is your: void myfunction(double ***arrayptrs, int *size) If this would be your allocateArrays() then what you would do is make sure to export free_arrayptrs() too and call that from LabVIEW at the end. Also *arrayptrs_out = (double**)malloc(*arraycnt_out*sizeof(double*)); should probably be instead: *arrayptrs_out = (double**)malloc(*size * sizeof(double*)); Then in LabVIEW you configure the parameter as pointer sized integer passed by reference, then in a loop do what ned has suggested before. But your proposed interface is pretty weak. While you return the number of array pointers in the returned data in *size, the caller has absolutely no way to know how many elements of data each array contains. This would be just by convention (caller and callee both have to know magically) and that is always a very bad API design. And you forgot to deallocate the array of array pointers in your free_arrayptrs()!!!! -
Control LabView 2013 with DCOM
Rolf Kalbermatter replied to BadLuckMan's topic in Remote Control, Monitoring and the Internet
The TLB file is now embedded in the LabVIEW executable. Everything else works the same. -
Passing array of string to C dll
Rolf Kalbermatter replied to Reikira's topic in Calling External Code
It could be that the function allocates the array of arrays itself and returns it and for that the pointer of pointer needs to be passed by reference. But there is absolutely no way to tell from the C prototype. The C syntax alone is notoriously inadequate to describe such details. The only way to know is to read the function documentation, consult any possible C sample that comes with the library and usually do lots of trial and error anyways since even the documentation and samples are usually to poorly made than that they would explain everything. Basically the solution to free() the array in the calling program is not safe because of the possible mismatch of the C runtime library between what the DLL uses and what the caller uses. The library exposing functions that return allocated memory MUST always export a function to deallocate that memory properly.