ned
-
Posts
571 -
Joined
-
Last visited
-
Days Won
14
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by ned
-
Do you actually need to assemble a recursive data structure in LabVIEW, or you just need to generate the JSON from some source data (a directory structure or similar)? If you just need the JSON, here's what I think I'd do, although I haven't tried coding it (and am on LabVIEW 2012 right now so no access to Flatten to JSON). If this isn't clear I can try coding it although might be easier if you post your code as a starting point to show the source of your data. Instead of attempting to do something recursive, use a queue (this could just be an array in a shift register around a while loop). The datatype of the queue will be a cluster of at least two elements: the data source, and the current position within the accumulate JSON string at which to insert a new child. Build up a cluster matching your datatype, but leave children as some simple scalar. Put the top-level data source into your queue. Also put a string in a shift register. Now, in a while loop, continue until the array is empty: - take the first item off the queue, and fill into the cluster. Flatten to JSON. - insert the JSON into the accumulator string at the current index. - find the new index at which to insert any children of the current node - enqueue, at the front, any children of that node, along with the string index I'm probably oversimplifying since tracking where to insert children in the string may be a challenge, but I suspect it can be made to work. If you care about the ordering of the children then enqueue them in reverse order, since you'll always be inserting new children at the same string index (pushing any existing children further into the string). Make sure you do this depth-first, by putting new children at the front of the queue, not the back.
-
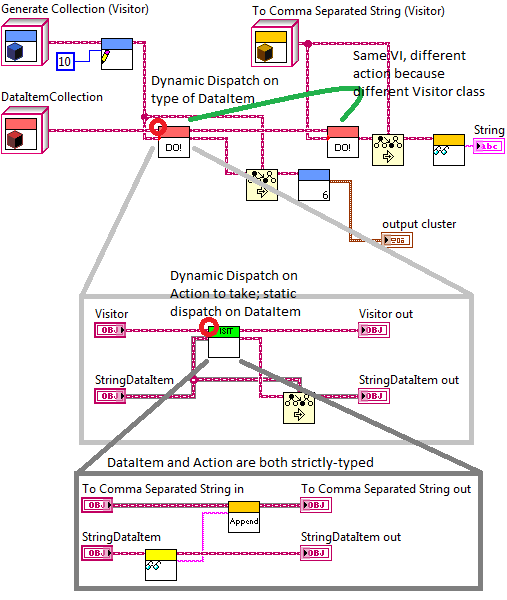
My general experience with Preserve Run-Time Class is that you'll know when you need it, because you'll code something that should work and realize that the class types don't match. As an example, I posted an image in this thread (http://lavag.org/topic/18377-decoupling-message-based-systems-that-communicate-across-a-network/#entry110228) showing the need for Preserve Run-Time Class, and the code for it is here: http://lavag.org/topic/16696-ah-yes-another-oo-architecture-question/#entry102428. I have a Datatype class, and an Action class. I want to perform Action on some Datatype. We can't do dynamic dispatch on two terminals at once, so there are two levels of dynamic dispatch - one on the Datatype, and inside that, a second one on Action. At the top level, we can see that we pass a specific action into the Do VI, but the Action (or Visitor) input to Do is necessarily static dispatch on the parent type, so the output wire is also of the parent type. Preserve Run-Time Class lets us tell the compiler that the output really is the same as the input.
-
Unfortunately those functions aren't available on an sbRIO-9606, unless that's a new addition in 2014.
-
AOP architecture issues and options
ned replied to John Lokanis's topic in Application Design & Architecture
I haven't built any systems with the goal of comparing the two architectures, and certainly not at that level of complexity you're talking about. I'm sorry for pulling just a few sentences out of a much longer post, but a couple comments about performance and other possible disadvantages. I don't think you'll get a run-time boost; you might even get worse run-time performance. A case structure with many cases and a string as a selector will most likely be slower than dynamic dispatch, and may get slower as you add more cases (somewhat dependent on the algorithm used to find the right case). Dynamic dispatch is constant time regardless of how many methods override the base call. There's almost no overhead in conversion to a variant. There's probably a small amount of overhead in conversion from a variant because it requires checking that the types match, but it may be insignificant. Don't underestimate the value of type safety, though - it shifts potential errors from run-time, where they're problematic, to edit-time, where they can be easily corrected. I'm not sure that having a case structure will be easier to read; might depend on how many cases are in it. One thing you will lose is the ability to call the parent. That makes it more difficult to share code across multiple similar cases - you'll either need to duplicate the contents of some cases, or make some cases that match multiple selections and then have special cases inside that for each slight difference. Is your goal simply to improve editor performance? It seems like your architecture works well in an application, so if the issues are purely in the development environment, maybe this is a good opportunity to bang on NI and see if they can find ways to improve the IDE (admittedly this isn't a short-term solution). -
If you can share the C code, it will be easier to provide a direct translation into LabVIEW. It would also help to share your LabVIEW code. From your description, it seems you'll want to pass a pointer-sized integer by pointer as the arrayptrs parameter. You'll get back a memory address. I assume that you either know, or can determine from the size parameter, the number of arrays pointed to by that address, so you use MoveBlock to copy that block of addresses into an array of pointer-sized integers. Then you repeat the MoveBlock process again, using the addresses you just copied, to get the actual data.
-
Ah! So in this case, it's the calling code (LabVIEW) that needs to do both the allocation and deallocation. Are you doing anything to allocate the memory? If you do not first allocate the memory, the code will probably crash when it calls your function. You should do something similar to my first post in this thread, but swap the order of the calls to MoveBlock and to the DLL function, so that you are copying data out of the array after calling the function rather than copying data into the array before the DLL call. I notice that your function prototype has 3 *s (double ***arrayptrs) - is this correct, or an accidental typo? If that's correct, then you need yet another layer of indirection, meaning another call to DSNewPtr and another call to MoveBlock (to move the addresses returned by DSNewPtr into an array). Is the int *size parameter an input, an output, or both? Is it an array of ints of the sizes of each double array, or a pointer to a scalar size? Do you have documentation on exactly what this function expects in the arrayptrs parameter?
-
Yes, it's possible, although a bit complicated. Use moveblock to copy the array of addresses into a LabVIEW array, then iterate through those and use moveblock to copy the actual data into an array. Or, use the technique explained here: https://decibel.ni.com/content/docs/DOC-9091. You'll need to account for your arrays having different lengths, which you could do simply by bundling each one to generate an array of clusters where each cluster contains an array.
-
This isn't a forum for learning C. Anything I would write here to explain how C strings and pointers work, someone has already written (in a book and elsewhere on the internet). Briefly, in your struct, when you declare "char *serialnr_A" in your struct, you are allocating space only for a memory address. Sometime later you need to allocate the actual space for the serial number, and then assign the address of that space to the value serialnr_A. When you assign "pubtable.serialnr_A = interntable.serialnr_A;" you are copying the address stored in the internal table to the address stored in the public table. You aren't copying the serial number at all. In your LabVIEW code, you are passing the serialnr parameter as a 32-bit integer, and this happens not to crash because on a 32-bit operating system, a memory address is stored as a 32-bit value. Probably what you want to do instead is copy the data stored at that address, to the serial number parameter. However that has a second problem: If the serial number is stored as a string, then it is stored as a series of ASCII characters, and NOT as a number. If the serial number happens to be 4 bytes long then you can store it in a 32-bit (4-byte) integer, but when you display it as an integer (as you're doing in your cluster) you won't see the serial number, because then you're looking at the bits as one number rather than as 4 individual bytes. When you store "2" as a character, you're actually storing the decimal value 50 in a byte. Does that distinction make sense to you? So even once you get past the pointer/value problem, you still won't see the correct serial number in your cluster. You have a couple of options and you need to figure out which one is best for you. For all of these, in order to display the serial number as a string in LabVIEW, you'll need to do some conversion in LabVIEW. Unless you want to rewrite your DLL to understand LabVIEW data types (you don't), you cannot pass a cluster that contains an embedded string to a DLL as a struct. - If you know that the serial number is always 4 bytes, you simply store those 4 bytes in the serialNr value. When you want to display it on the screen as a string, you'll need to convert it to a 4-byte array of U8, then convert that to a string. - Continue instead to store a pointer to the serial number in the struct, and then you'll need to use a call to MoveBlock to retrieve the actual string and copy it into a LabVIEW string. Also, this will break if you move to a 64-bit operating system. - Define the serialNr parameter as a cluster of U8, instead of as a single I32, and copy the actual serial number values into it. To display as a string, you'll need to convert the U8 cluster to an array, and then convert the array of bytes to a string.
-
There's some ambiguity in what you're passing there. Are you passing an array of pointers to arrays of the same length, or several different lengths (as is the case for an array of strings)? Either way you should be able to do it similar to the string array case. You will need to adjust the math for the difference in size between a char (1 byte) and a double (8 bytes), and remove the extra byte allocated for the null that terminates the string because arrays aren't terminated.
-
Your screenshot shows that your cluster contains only 32-bit integer values. Why do you think you can put a string into one of them and get the right result? You cannot copy strings in C using assignment. You must use strcpy() or another similar function. But before you do that you need to understand strings in C. Find a good C reference - I highly recommend the original K&R reference "The C Programming Language" but there are many others available.
-
Maybe you assigned a pointer (a memory address) to a value, so you're seeing the memory address rather than the number you expected to see?
-
KingCluster - how are you opening the FPGA VI reference? If you're referring to the VI, then yes, it probably will show up as not compiled because the VI or its subVIs were last saved for a different target. Loading a bitfile or build specification instead should solve the problem. If that's not it, can you be more specific than "breaks"? What error do you get, and where does it occur?
-
I don't have a brilliant way to simplify. If you wanted to get into scripting, you could try scripting the addition of a new message, so you would just need to write the logic for the message itself (unavoidable) and the logic for how to handle that message (also unavoidable). The script would automate adding the abstract and specific calls to the parent and child of the network message execution class. I still have an issue with using a variable inside the Execute method to get the correct network message execution class. There's no problem storing the class in a variable, but to follow the Visitor pattern, you should move the variable outside the entire message structure, and pass the class into the Execute method on a wire. This way you eliminate all the calls to the variable inside the various Execute methods. Maybe this is what you're doing already, and I've misunderstood - it would help to see code. I put together the diagram below, taking pieces from my Visitor example project, that I hope helps to show how this works: There are two "Visitors" (which are like your Network Message Execution classes). They each perform an action on a DataItem (analogous to your Message). DataItem has a Do method with two parameters: dynamic dispatch on the type of DataItem, and static dispatch on the Visitor (the action). Inside the Do method is the reverse - dynamic dispatch on the Visitor, static dispatch on the DataItem since it's type is already known due to the previous dynamic dispatch. The message class only has a dependency on the parent Visitor class, not on any of the child implementations. EDIT: and also note, there's no casting of the Visitor at all, whereas in your description you say you need to cast it to the parent type, which I don't understand.

-
I'm guessing this is somewhat a continuation of http://lavag.org/topic/16714-class-dependency-linking/? What's the reason for storing the "network message execution class" in a variable (a functional global or some such, I assume) rather than wiring it in as a terminal? It might be easier to switch between implementations if it was a wire. Can the messages be grouped together, such that there's a set that covers core functionality, then add additional groups? If so, you could inherit from the "network message execution class" with each successive child adding an additional set of handled messages.
-
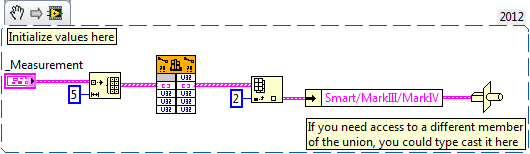
You can pass clusters to a DLL, with the parameter configured as Adapt to Type. The cluster will be passed by pointer, like a struct. I recommend that you try this for your Show Probe Dialog VI, since it will eliminate splitting and joining numbers. LabVIEW will handle all that for you automatically. You can likewise pass an array of clusters to the DLL using Adapt to Type. Set "Data Format" to "Array Data Pointer." You'll need to create a cluster that matches the format of the Measurement struct. This is easy if you're only using one of the members of the union. If you are using more than one member of the union, then you can either pass the data in a more generic format (for example an array of the correct number of bytes) and parse the data out later, or you can create a struct that matches one member of the union, and then reinterpret that portion of the data when dealing with other Measurement types. See snippet below.
-
When you say "local path" - local to which machine? You can only run a VI on the machine on which that VI is located. When you open a connection to remote machine, you can then load a VI that's on the remote disk, not your local disk. When you run that VI, it runs on the remote computer. VI Server doesn't transfer VIs over the network; it only sets up the inputs, starts execution, and retrieves the outputs. Try including the VI in the compiled application. A static VI reference is a good way to do this. It will cause the VI to load in memory along with the application. You can then refer to that VI by name, rather than through a path. Wire a string (NOT a path) containing the VI name in place of the path to the VI. If you have a firewall on the server side, it will block connections to VI Server unless you specifically allow them. It might help to upload your application's INI file, along with your code.
-
How is the Measurement data type defined? If the Measurement struct is fairly simple, you can create a matching cluster in LabVIEW, fill in the values, and pass it to the DLL function. The corresponding output from the Call Library Node will have the modified values after the call to the DLL. Can you share your LabVIEW code, showing what you tried?
-
Yes, you can use VI Server to get call a DLL running on a remote target. In a Windows environment, you need to have a LabVIEW application (either the development environment or a compiled application) running in order to have VI Server available. You also need to enable VI Server allow access to the VIs you need (you can set this in Options, or in the INI file). The Run-Time Engine loads when a LabVIEW-compiled application starts, NOT at system startup (except in a LabVIEW Real-Time environment, not your situation). However, if you don't have your LabVIEW application run at startup, then you'll need some way to start it remotely in order to get access to VI Server when you need it. The "web" version of the run-time engine is fairly small (under 30mb download) and might provide everything you need - many of my applications run just fine with it. You can find the version that matches your development environment by searching the NI site for "web run-time" and finding the right one. If you're using a version of LabVIEW older than 2012, look for the "Minimum Run-Time" instead.
-
The "shared library file is not on the local machine" option allows you to import a shared library using only the header, without access to the DLL. This has nothing to do with remote access to the DLL, it just tells the import wizard to rely on the header file and not look for the DLL. There is no way to call a function inside a DLL remotely. A DLL isn't even loaded into memory until an application needs it. You'll need to write an application - it doesn't need to be in LabVIEW, and you don't need VI server although it is an option - that accepts network connections, parses the received data, calls the correct function in the DLL with the appropriate parameters, and returns the result (if needed) over the network. That could be a lot of work. Why are you trying to do this?
-
This might be a difference with TFS. Perforce won't complain when you attempt to move files on disk that are in source control, so the method I explained works. If the source control system won't let you move a file on disk that isn't checked out then I don't have a good solution.
-
I've also combined the two approaches - it's cumbersome but gets everything right. Move the files in the LabVIEW project. Close the project and save everything. Manually, on disk, move the files back to their original locations, then use the source control system to do the move. Maybe Mercurial is smarter than Perforce about file moves, or I missed something in Perforce, because I haven't found a way to have it do the right thing with moved files.
-
Opening file in read-only in Excel causes LV write permission error
ned replied to eberaud's topic in Database and File IO
Can you share your code, or better, a minimal VI that demonstrates the problem? In a similar situation, I wrote code that closed the file after every write and immediately set the Read-Only flag on the file, so that Excel would always open it Read-Only. When I needed to append to the file, it cleared the Read-Only flag and immediately opened it with write access. Kind of inelegant, but it worked. The user could open the file in Excel at (almost) any time and see the most recent results, without interfering with the ability of my code to update the file. -
I haven't used TFS and LabVIEW together, but I have used TFS, and I've used Perforce with LabVIEW, so I'm pretty sure these comments are correct. I've never found a satisfactory way to move files. My recommendation is don't do it in LabVIEW. Close the project in LabVIEW, use TFS to move the files, then re-open the project and find the "missing" files. Unfortunately as far as I know there is no way to move a file both in source control and within the LabVIEW project simultaneously, although I would love to hear otherwise. You can do your check-out/check-in operations either in LabVIEW or in TFS. If the status doesn't match, LabVIEW has a menu command to refresh source control status. I often find it convenient to check in individual files within the LabVIEW environment (for a small bug-fix), but if I'm making related changes to multiple files then after I'm done working, I close the entire project within LabVIEW (to confirm everything is saved) and then submit all the modified files at once within Perforce (or TFS in your case). I leave "Include callers when checking out files" unchecked. It's whatever you prefer. I personally prefer to separate automatic changes (such as when a callee changes) from changes I made explicitly, and it doesn't bother me that much that I get a bunch of unsaved VIs when I close a project. I just don't save the automatic changes until I'm ready. You may prefer to do it the other way. I haven't seen any interference between auto-populating folders and source control.
-
I think the older cRIOs ran PharLap ETS, and it's the newer ones that run VxWorks? But maybe I have it backwards. A bit off-topic, but I had a possibly-related issue with code on a newer sbRIO (running VxWorks, if I remember correctly) where it crashed or wouldn't run an executable that used more than one execution subsystem. I was in a rush to get it working and so didn't have time to investigate or report the problem, I just set everything to the same execution subsystem and it ran fine.
-
Can the VI Recovery Dialog Be Suppressed?
ned replied to hfettig's topic in Development Environment (IDE)
Haven't tried this, just a guess. Recovery files are stored at DocumentsLabVIEW DataLVAutoSave (by default). I believe if there are no files there, you won't see a recovery dialog, so you could add a batch file that clears that directory before launching LabVIEW, and run that batch file instead of running LabVIEW directly in the automated build.