Gary Rubin
-
Posts
633 -
Joined
-
Last visited
-
Days Won
4
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Gary Rubin
-
I must be missing something. Isn't 8bits at 100MHz = 100MB/s? Generally, the MB is megabytes, while Mb is megabits.
-

Another Lego Mindstorms NXT Rube Goldberg Machine
Gary Rubin replied to crelf's topic in LAVA Lounge
I wish I had that kind of free time. -
Can something really be considered "high-visibility" if you can't talk about it?
-
Inlining a subVI that uses the In Place Memory Structure
Gary Rubin replied to Onno's topic in LabVIEW General
Oops.... You guys are right... I wonder why I thought it worked... -
Inlining a subVI that uses the In Place Memory Structure
Gary Rubin replied to Onno's topic in LabVIEW General
Mine works. Were the I32s <5? -
Inlining a subVI that uses the In Place Memory Structure
Gary Rubin replied to Onno's topic in LabVIEW General
What are your input and output numbers? I'm guessing your x-values are integers and your y-value is 1? -
Inlining a subVI that uses the In Place Memory Structure
Gary Rubin replied to Onno's topic in LabVIEW General
Chris is right - I'm still on 8.6. And this is why I generally stop posting on LAVA once I'm a version or two behind -- most of my issues/questions have become deprecated. -
Inlining a subVI that uses the In Place Memory Structure
Gary Rubin replied to Onno's topic in LabVIEW General
Sorry, not 7us for the formula node -- 7us to call the subvi. The actual formula node calculation is much, much faster than that. The calculation time is what it is. It's the overhead of the subvi call that I was hoping to be able to do something about. -
Inlining a subVI that uses the In Place Memory Structure
Gary Rubin replied to Onno's topic in LabVIEW General
1) 20k. 2) Win7-64, although the code will eventually be deployed on Windows Embedded. -
Inlining a subVI that uses the In Place Memory Structure
Gary Rubin replied to Onno's topic in LabVIEW General
It looks like I'm getting about 7us per call. Still not sure if that's to slow or not. -
Inlining a subVI that uses the In Place Memory Structure
Gary Rubin replied to Onno's topic in LabVIEW General
Right, but I still have the same basic problem. I have a small, but not insignificant block of code that will be used in several places. To me, that sounds like a textbook reason for making a subVI, but what I'm finding is that the actual calculations take about 0.03% of the time, and overhead associated with calling the subvi seems to take the other 99.97% of the time. I was wondering about any tricks to trim that 99.97% overhead load. I'll see what I can do with the inline subvi switch, but I was wondering what other methods might exist. Gary -
Inlining a subVI that uses the In Place Memory Structure
Gary Rubin replied to Onno's topic in LabVIEW General
Not for negative numbers. Try putting a negative number in your array... You'll get a different answer. mod and rem aren't the same for negative numbers, although they vary from language to language (AARGH!). The LabVIEW formula node has both versions, but the native function only supports the approach that gives positive remainders. -
Inlining a subVI that uses the In Place Memory Structure
Gary Rubin replied to Onno's topic in LabVIEW General
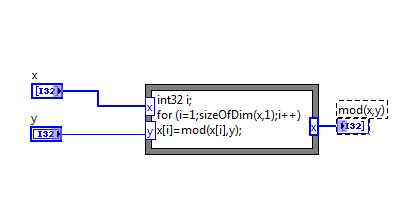
I have somewhat related question, I think. I was disappointed to find that Labview 8.6 does not have a native "mod" function, but I found that I could create my own using a formula node: This runs the at same speed as the native rem/IQ function, but treats negative numbers the way I wanted it to. It's pretty ugly, though, to have to sprinkle those formula nodes around my code, so I made it into a subvi. Even with required inputs and subroutine priority, the subvi implementation is ~3000x slower than the formula node on its own. I understand that there's overhead associated with calling subVI's, and when the contents of the subVI are very fast, that overhead will become the dominant factor. Also, in this case, the factor of 3000 is the difference between "really fast (7us/iteration)" and "really really really fast (2.5ns/iteration)". That said, does anyone have any suggestions? Am I just stuck with that large (although possibly insignificant) slowdown as the price of having prettier code? Thanks, Gary
-
-
My turn to feed the bears... http://science.slashdot.org/story/10/05/05/0012215/Second-Inquiry-Exonerates-Climatic-Research-Unit
-
And no more gerrymandering.
-
This looks very much like example LabVIEW code that we've bought with some digital receiver cards. I wonder if it was written by the same person.
-
For loop parallelization
Gary Rubin replied to Gary Rubin's topic in Application Design & Architecture
Ben, Yes, Option 2 would be a single element Q, where that element is a preallocated array of fixed length. Is DVR efficient? For some reason, I thought references made copies. And there's not a lot of number crunching. Just lots of Array Subsets and Replace Array Subsets. Now that you mention it, though, that could be primarily a memory bottleneck, which depending on the architecture of my CPU, may or may not be helped through parallelization. Gary -
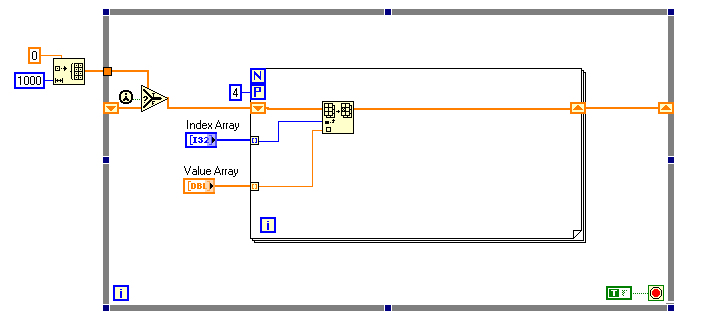
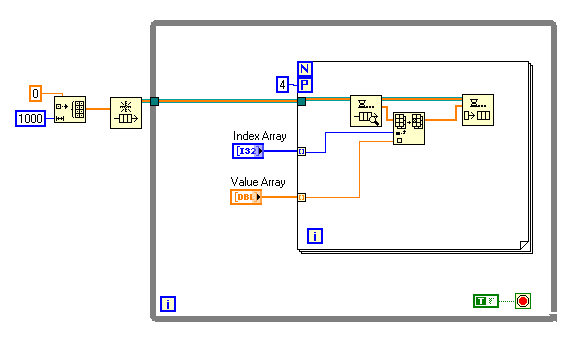
I have some code that keeps arrays of the most recent states of thousands of objects (1000 in the attached example). The basic architecture of the code can be represented as shown (this a very simplified example that tries to capture what the real code does). And yes, I know that the initialization function is run more often than necessary. I just threw this together quickly to demonstrate dataflow. Clearly, this does not work because the Parallel For Loop structure does not allow the use of the shift registers. I know, however, that I will never have duplicate index values in a call to this function so order of execution of the For Loop iterations does not matter. I also know that the lengths of the Index and Value arrays are highly variable at runtime. Because there really is no dependency between for-loop iterations, it seems like this should be parallelizable. So, does anyone have any suggestions? I was thinking I could maybe replace the shift registers with a queue containing the array: Is that inefficient? Unsafe? How does the Parallel For Loop deal with this case? It claims to be executable. After robustness, speed is the ultimate consideration here. Thanks, Gary
-
So, it seems that the hubbub over this is dying down, but there's still something about it that vaguely bothers me. I think it has to do with the whole upgrade/update vs. patch approach. Let's say I find a bug in LabVIEW. I report it and it gets fixed, but not until either the next version or the next revision (isn't 2009 SP1 the equivalent of 8.0 -> 8.2). So, in order to take advantage of the bug fix, I have to migrate to the newest version. I think the thing that bothers me about that is the lack of backward compatibility (i.e. I can't open 2009 code in 8.6 (yes, I know I can save back one version, but that's not the point)). One of our main products is still using LV7.1. When we sell a system, we often include a LV license. Then, if we need to upgrade the system, tweak things, add features, or whatever, the system already has a LV license that we can install and use. If we upgrade to a newer version of LV, then we can no longer use our latest and greatest code on those older systems without upgrading their LV also. I think this whole "forced upgrade" vs. patch or minor release approach would sit better with me if I could easily pass code back and forth between versions, with newer structures, functions, whatever showing up as broken icons (kind of like missing subvi's) if they aren't common to both the newer and older versions. Can you imagine the holy hell that would be raised if MS's response to Office bugs was "Tough s#!~, upgrade to the next version. Oh, by the way, you won't be able to share you files with other people unless they upgrade too."? PS: Maybe my LV usage is unique. I tend to use it for data acquisition and processing. I have no interest in OOP, and tend to not use much beyond the basic primitives. With the exception of the disable structure and queues, which I find quite useful, I don't think I'm using much that hasn't existed for the past few versions (at least diagram-wise; I know that what's under the hood is has improved from version to version). Because of that, I don't see why I should have to upgrade (whether I have to pay for that or not) just to make what I'm using work properly. And no, I haven't found a bug in quite a while - it's just the principle of the thing. PPS: If I remember right, LV 7.1.1 was a free bugfix patch to 7.1, wasn't it?
-
Cross-Poster come out of the Closet
Gary Rubin replied to Grampa_of_Oliva_n_Eden's topic in LAVA Lounge
I'm going go out on a limb and guess that is what he said. -
Cross-Poster come out of the Closet
Gary Rubin replied to Grampa_of_Oliva_n_Eden's topic in LAVA Lounge
I don't post much to NI Forums, but I'm grubin698 -
Anyone using Mercurial for source code control in LabVIEW?
Gary Rubin replied to Jim Kring's topic in Source Code Control
We've just started using Mercurial on our Matlab code. I think we'll probably try bringing in LabVIEW code in the next few weeks. -
There could be people sunbathing in my backyard - I just can't see over the snowbank to know if they're there or not.
-
Thanks Cat. I'll have to take a look. I understand what you mean about being housebound. My big adventure yesterday was walking 2-miles each way to a CVS to see if they had milk (they did).