Onno
-
Posts
29 -
Joined
-
Last visited
Onno's Achievements
")
Newbie (1/14)
3
Reputation
-
Newbie Question about Actor Framework
Onno replied to Jeannius's topic in Object-Oriented Programming
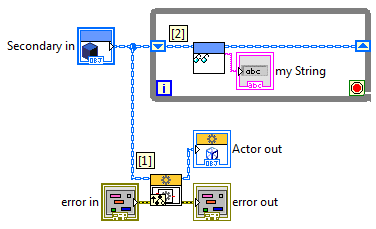
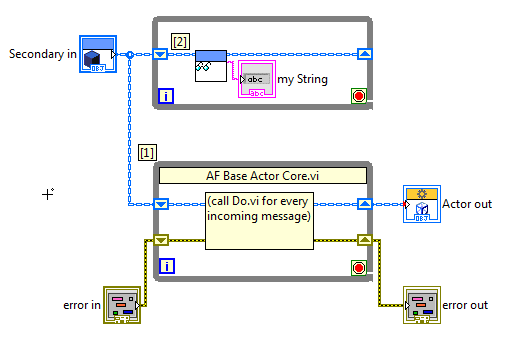
Hi Jean, You've hit into one of the things that also puzzled me at first with the AF Attached, you'll find a "fixed" version of your project. Let me explain what's going on here. What's crucially important in your understanding of the Actor Framework, is that LabVIEW objects are by-value, not by-reference (see the NI Whitepaper on LVOOP). So every class wire in your Block Diagrams has class private data clusters flowing through them, following the same data-flow rules that would apply to other wires. Let's have a look at the Actor Core.vi of your Secondary actor: The private data cluster of Secondary.lvclass comes in at the "Secondary in" terminal (top-left), but the wire splits in two branches. The branch labeled [1] goes off into the base class' Actor core, which contains an 'infinite' while loop that processes all incoming messages, and calls the "Do.vi" methods of your message classes. The branch labeled [2] goes into your parallel While loop. So, effectively, the above VI looks like this: What happens if your Secondary actor receives the Write my String message? Well, all this message processing takes place in the bottom While loop! Whatever happens to Secondary's private data cluster there, will stay within that bottom While loop, due to the way data flow works. The "my String" update will never reach the upper loop. All this means that getting data updates from your messages to your Actor Core's front panel is a very fundemantal 'problem' in the Actor Framework. The only way to solve this problem, is to somehow work with references to data, instead. There's two ways to do this: Use a Data Value Reference (DVR). Add a DVR to your actor's private data cluster, and use this DVR to communicate data between the upper while loop and the message processing VIs. (As a sidenote, you should be aware, if not already, that continuously updating your Front Panel like you did in your example project, is not very efficient). Use control refnums to your Front Panel controls and indicators, and store those refnums in the actor's private data cluster before the class wire branches off into [1] and [2]. You can then update Front Panel controls elsewhere in the code, whenever necessary. Strategy 2 is the one I've chosen in the attached sample, and also the one I've been using in my real-world AF project. It's a bit cumbersome, but works very well. I hope this clears a few things up! Best, Onno (Actor Message Learning_fixed.zip)
- 2 replies
-
- 1
-

-
- actor framework
- oop
- (and 1 more)
-
Getting the same error here (LabVIEW 12.0f1 32-bit). The project looks very interesting though!
-
Removing the "*.*" option will not remove the user's ability to show all files, and execute potentially unsafe programs. Just try entering "*" in any file dialog, and you'll all the files, no matter what the currently selected filter is. What you really want, is a way to lock down program execution on Windows. That is actually possible. It seems to be called Software Restriction Policy (SRP). Read about it on, for example, MS Technet.
-
Thanks so much for recording these, and making them available!
-
Which SCC software between Git and Hg should I use?
Onno replied to honoka's topic in Source Code Control
I've been playing around with Mercurial briefly, but went back to TortoiseSVN, both for reasons of stability and convenience. Especially getting Diff/Merge to work nicely with TortoiseHg was a major pain (not unsolvable — see other posts on LavaG — but too much of a hassle in my opinion). Not sure about TortoiseGit though. By the way: would there be any specific reasons to prefer a DSCC over SVN? Those SCCs seem to rely (*) quite heavily on merging, which is still a rather messy job with LabVIEW anyway. (Given the binary file format, custom diff/merge tools, and LV's propensity to modify files at will). (*) Maybe "rely" is not the best word to use here, but they do treat branching/merging as much more of a first-class citizen than SVN — which, for me, would be the most important reason to switch, I guess. -
Passing data between languages
Onno replied to Mark Yedinak's topic in Application Design & Architecture
XML and JSON are probably much better options for inter-language communication. Not in the least because that's the way people have solved this problem before. XML is of course well-supported, but I'm not sure about JSON. There's a Labview-JSON library, but that only works for encoding JSON, not for decoding it. -
Please, no! I guess something is to be said for removing visual clutter, but they've taken the minimalism way too far in the latest Visual Studio. And, as far as I know, putting things in all-caps is a well-known usability no-no. Besides, if NI decides to spend time on improving the IDE's user interface, I think there's other ideas that would have a much more pronounced effect on usability. And, on-topic: I'm fairly sure the new toolbar was introduced with LV 2011. I personally like it a lot, it looks much fresher!
-
Advice for building high-reliability LabVIEW process control VI?
Onno replied to Onno's topic in LabVIEW General
Haha, maybe I'm lurking too much But I'm doing my best to chime in where it seems useful! I couldn't agree more. But it's not my project, and I don't get to decide anything... But I'll definitely do my best to get that message across! What a coincidence I might just happen to, by pure chance, pass on your contact info, but it's going to take another month until the guy in charge of the project is back here. So don't hold your breath -
Advice for building high-reliability LabVIEW process control VI?
Onno replied to Onno's topic in LabVIEW General
Thank you, all, for the advice; it's very helpful! An especially warm "thank you" to you, crelf, for the extensive post I'd never have thought of the cFP/cRIO systems, since I have absolutely nil experience with them. But yes, come to think of it, it makes a lot of sense. The guy in charge of the project should be back from holiday by the end of August, so I'll discuss it with him then. But as far as I'm concerned, I'd definitely consider bringing in some external assistance. Just not sure if the research budget would allow for it! If I end up getting involved in this, I'll post back some time in the future with my experiences! -
Hi all, Here at my university, someone asked me for advice on how to build a process control VI for a scientific experiment. What he described seemed like a stereotypical LabVIEW application: the computer has to control a couple of pumps and switches, and apply some basic PID control to keep, for example, the pH (acidity) of a solution constant. All was well, until he added that this experiment has to run for at least a year; any interruption of a few seconds in the process control would mess up the experiment. Oops. So, it seems this should be a high-reliability LabVIEW application — something on a scale with which I don't have any experience. So I'd like to ask you for some advice: how to handle this? Any experiences you'd like to share? A few things that seem obvious: disconnect the controlling PCs from the network; disable Windows Updates (but that follows from the previous point, really); have two PCs, and implement some sort of failover mechanism (but how?); get a UPS, or maybe even a backup generator; test extensively, by simulating all sorts of failure scenarios (any tips here?); extensive logging and monitoring. [*]Anything else? [*]Do you know about any good whitepapers or examples? (I have tried Googling around, but haven't been able to come up with much useful information). [*]Or should we ditch the idea of building this ourselves, and get some professionals to look at it? Any pointers would be very welcome; thanks a lot in advance! Best, Onno
-
Objects deleted without call "destroy" vi
Onno replied to Maite's topic in Object-Oriented Programming
It's going to be really hard to help you out without seeing the code, I'm afraid. (Or maybe it's just me, and someone else is able to give some advice here?) Do you think you could create a small example project that demonstrates the problem, and post it here? -
Futures - An alternative to synchronous messaging
Onno replied to Daklu's topic in Object-Oriented Programming
Ah, of course, that's completely clear. Thanks! -
Futures - An alternative to synchronous messaging
Onno replied to Daklu's topic in Object-Oriented Programming
Thanks, Daklu, for the interesting post! I really enjoyed reading about your problem & solution — same goes for AQ's response. About the latter, I have a small follow-up question: Could you maybe elaborate on that? Why would polling the future's state every once in a while be such a Bad Thing? In my view, you're just pointing out a very fundamental problem of retrieving information from a parallel process, one that has nothing to do with futures in particular. It's the problem of having to wait for the requested info to come back, without locking up. That problem is universal to all approaches, right? Be it async messages, synchronous messages or futures. So I'm a bit confused: what's especially bad about this use of Futures? Thanks a lot Onno -
The LabVIEW community has a large number of incredibly useful tools (RCF, QuickDrop extensions, OpenG), but they're rather spread-out, difficult to find for newcomers, and not always very well mainainted. Over the past year or so, I've slowly accumulated a collection of these tools, but it'd be really difficult to explain to a new colleague where I found them all As such, some sort of "official community patch" sounds appealing: it'd make it way easier for relatively new developers to "upgrade their LabVIEW experience" (hm, that sounds cheesy). And I guess those people would be the main audience for such a patch? (Since most of the people in this topic already have their own sophisticated customizations, presumably). I do wonder about the technical difficulties, though, given the already mentioned "different workflows for different developers", and the non-trivialities of maintaining a modularized LabVIEW installation. VIPM may be a perfect implementation of a "community patch" — but that would also mean that more of the already available tools and libraries would need to be packaged. With important parts of VIPM's functionality being reserved for commercial users (esp. the creation of VIPCs), this might be an obstacle. Nevertheless, I would be interested in seeing how this develops! (If I could help, I would!)
-
Having worked with LabVIEW for a few years now, it seems to me that such dynamic user interfaces are simply nigh-impossible in LabVIEW. The way the front panel / terminal / block diagram system has been designed has some strong advantages, but dynamic control instantiation seems to be fundamentally incompatible with this paradigm. If you really think this type of UI is useful, you should consider using a different tool — .NET for example. There's plenty of extensive libraries for this sort of thing in the .NET world. You really don't want to solve the intricate usability issues of docking/undocking etc. yourself, if you don't have to On the other hand: does the UI you have in mind really solve concrete user problems? My experience thus far tells me that often a well-designed, static UI trumps an overly-configurable, dynamic UI. Especially for "your average user" (whatever that may be), too much configurability makes an application harder to use. For a good example on this, read the interesting story of how the Microsoft Office Ribbon UI was conceived. There's a reason Microsoft turned its back on the mess of floating toolbars, dynamic menus and over-configurability that was MS Office 2000-2003. (Even though, personally, I quite liked it!) One additional tip, to make this downer-of-a-reply a bit more useful: you can look into LabVIEW OOP (Object Oriented Programming), and the Actor Framework, to see some examples of how you can make a UI more 'customizable' — by, for example, making multiple versions of the same UI, and decouple those UIs from the underlying actual program. Let me know if I'm being too vague here, or if you'd like some more concrete pointers. Best regards, Onno