mike_spacex
-
Posts
39 -
Joined
-
Last visited
-
Days Won
1
Recent Profile Visitors
5,289 profile views




mike_spacex's Achievements
")
Newbie (1/14)
18
Reputation
-
Here's news worth sharing: StarUML is not dead! http://staruml.io/download They're working on v2 (major new release). They've rolled out 12 beta versions since May 2014. G# plug-in tool seems to work brilliantly with it. I reverse engineered a LabVIEW project with 18 classes, and liked the result much better than what the GOOP Development Suite UML Modeller produced (though I didn't make effort to tweak UML Modeller's reverse engineering settings). Though the G# add-in helps produce code and reverse engineer, I sure wish it could sync with a project like GDS UML Modeller does. StarUML doesn't have good diagram clean-up utility -- it took me an hour to get all my wires uncrossed and classes neatly laid out. Then, after I modified the code, all I could do was reverse-engineer again then hand-arrange the UML all over again (only 30 minutes 2nd go-round since I had previously worked out a neat arrangement). I'm still dreaming of the day we have a professional tool like Enterprise Architect with tight linkage to LabVIEW, but for now it's encouraging to see StarUML being brought back to life; it's a useful tool with much lower barrier-to-entry than EA; great for casual users.
-
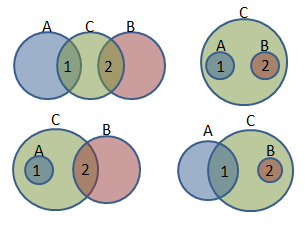
 I'm drawn into this discussion as I see two interesting parts to this problem: (1) What design pattern best suits the application? (2) How can the Batch Editor know which operations are available for a given file set of mixed types? (2) could easily be accomplished if reflection were available - simply query for the object hierarchy and determine the common set of available methods. Alternatively, reflection-ish behavior can be "faked" by maintaining a look-up table with this information. But, let's revisit (2) after answering (1). It seems to me that your problem is textbook case for Visitor Pattern. Read up on Gang of Four Visitor Pattern (here or here are satisfactory renditions). Don't get hung up on NI community example here (though it serves as an interesting specific use-case, I think it fails to capture the basic intent). Then try something like this: I also attached some java-ish pseudo code to demonstrate the call chain from main, through the composite FileGroup, to the Visitable Objects (your 'File' class structure), to the Visitors (the file operations). Using this pattern, you may feel like you're duplicating a lot of information from the Visitable classes to the Visitor classes in order to make it available to the client, but on the upside you're avoiding creating a bunch of proxy methods every time you want to extend the available operations set. Back to (2). For the Batch Editor to "know" the available operations, you can add a 'checkAccept' method alongside every 'accept' method, and a 'checkVisit' method alongside every 'visit' method. The 'checkVisit' methods in the concrete Visitor classes simply return 'TRUE' if they are successfully called. 'checkAccept' methods return the 'checkVisit' result to the client. In this manner, then client can call 'checkAccept' on every File in a FileGroup for every operation (Visitor), to quickly determine (without modifying anything) which operations are available for a selected file set. One final note, if you do decide to use this approach, it might make sense to enforce "friend" scope to methods in your File structure classes to only allow calls from their corresponding Visitors. This makes it clear that the only public API to your File structure should be the accept (and checkAccept) methods. Though this strengthens the API, it does require extra maintenance as new operations are added. Maybe there's a better pattern for this application, but this is my gut reaction. Please shoot holes in it as you discover its deficiencies. visitorPatternPseudoCode_FileBatchEditor.txt
I'm drawn into this discussion as I see two interesting parts to this problem: (1) What design pattern best suits the application? (2) How can the Batch Editor know which operations are available for a given file set of mixed types? (2) could easily be accomplished if reflection were available - simply query for the object hierarchy and determine the common set of available methods. Alternatively, reflection-ish behavior can be "faked" by maintaining a look-up table with this information. But, let's revisit (2) after answering (1). It seems to me that your problem is textbook case for Visitor Pattern. Read up on Gang of Four Visitor Pattern (here or here are satisfactory renditions). Don't get hung up on NI community example here (though it serves as an interesting specific use-case, I think it fails to capture the basic intent). Then try something like this: I also attached some java-ish pseudo code to demonstrate the call chain from main, through the composite FileGroup, to the Visitable Objects (your 'File' class structure), to the Visitors (the file operations). Using this pattern, you may feel like you're duplicating a lot of information from the Visitable classes to the Visitor classes in order to make it available to the client, but on the upside you're avoiding creating a bunch of proxy methods every time you want to extend the available operations set. Back to (2). For the Batch Editor to "know" the available operations, you can add a 'checkAccept' method alongside every 'accept' method, and a 'checkVisit' method alongside every 'visit' method. The 'checkVisit' methods in the concrete Visitor classes simply return 'TRUE' if they are successfully called. 'checkAccept' methods return the 'checkVisit' result to the client. In this manner, then client can call 'checkAccept' on every File in a FileGroup for every operation (Visitor), to quickly determine (without modifying anything) which operations are available for a selected file set. One final note, if you do decide to use this approach, it might make sense to enforce "friend" scope to methods in your File structure classes to only allow calls from their corresponding Visitors. This makes it clear that the only public API to your File structure should be the accept (and checkAccept) methods. Though this strengthens the API, it does require extra maintenance as new operations are added. Maybe there's a better pattern for this application, but this is my gut reaction. Please shoot holes in it as you discover its deficiencies. visitorPatternPseudoCode_FileBatchEditor.txt
-
Avoiding code duplication in state pattern
mike_spacex replied to MarkCG's topic in Object-Oriented Programming
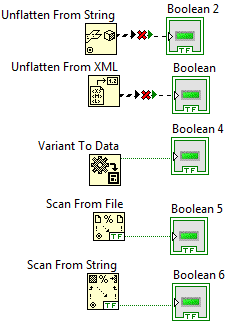
Paul is right, you need more information to know if there's a better way to structure your hierarchy. From what you told us, any of the following diagrams may be valid: A Venn Diagram is not a great tool for modeling behavior, but hopefully you see the point: You need to take into consideration all the behavior (and possible future behavior) you may want to incorporate into each state before settling on a design. One of the great things about the state pattern though is that it's very forgiving. If you do as Paul suggests and separate your implementation from your state methods, then molding it into a new hierarchy or adding or removing states & methods is fairly trivial.
-
Network Messaging and the root loop deadlock
mike_spacex replied to John Lokanis's topic in Application Design & Architecture
My 2 cents, from experience: Avoid developing your own TCP-connection-managing / messaging architecture! Polling is definitely the right name here, and this kind of scheme proved to be quite messy for me as requirements evolved. I initially thought the only challenge would be dynamically adding and removing connections from the polling loop and efficiently servicing the existing connections. Before long, I had dozens of connections, some required servicing small amounts of data at rapid rates (streaming, essentially), while others were large chunks published infrequently. While the polling loop was busy waiting-then-timing-out for non-critical items, some critical items would experience buffer overflow or weren't being replied to fast enough (my fault for architecting a synchronous system). So I incorporated dynamically configured connection prioritization to scale the time-out value based on assigned priority level. I also modified the algorithm to exclusively service, for brief-periods, connections flagged as potential data-streams when any data would initially arrive from these connections. This quickly became the most complex single piece of software I had ever written. Then I began using Shared Variables, and the DSC Module for shared variable value-change event handling. It was a major burden lifted. I realized I had spent weeks developing and tweaking a re-invented wheel and hadn't even come close to having the feature set and flexibility Shared Variables offer. [whatever]MQ is a great solution if you need to open communications with another programming language. But why take your messages out-and-back-in to LabVIEW environment if you don't need to? Sure, RabbitMQ was easy to install and configure for you... but what about the end user? Complex deployment = more difficult maintenance. I would only recommend TCP messaging if you need high-speed point-to-point communications, but for publish-subscribe you ought to highly consider Shared Variables + DSC module. If you do go the route of DIY TCP message handling, I recommend lots of up-front design work to take into account the non-homogenous nature of messaging. -
While I agree 100% with this, I'm still on the fence. If there's a 'type' input, my personal preference is to be explicit and wire it up. But, then again, the fewer replacements I have to make if I change types later, the better. When it comes to remembering to modify the data originator, a broken run arrow in the receiver won't help my brain synapses work any better unfortunately. So, rather than vote bug or no-bug, I'd rather just push for consistency; Either give me the "magic" everywhere, or none at all. The inconsistency can definitely be cause for confusion:
-
-
-
mje, dave: I was listing those tips for the sake of the newbies who might care to read as you vent your frustration; I realize I'm mostly preaching to the choir here though. I second the motion that Elijah should do an article on Dependency Management.
-
For the Discovery Channel Telescope software, we make extensive use of libraries and classes. We never have this issue when editing classes. Perhaps what helps make this possible is 1. Programming to an interface, not an implementation: Abstract classes with pure virtual methods separate almost every call layer. 2. For each software component we do development work within several small lvprojs (with few dependencies), then only one large project from which we do builds but typically no development work. 3. Architect to avoid overly-complicated dependencies.
-
Dave, Though I like your distinction of interface vs. Interface, I can't find this capitalization difference used elsewhere in programming language lingo. In looking at some examples of State Pattern in various languages, I do notice that care is taken in calling-it-what-it-is: Java and C# examples do implement State as an interface (and refer to it as such), while other language implementations call it an abstract class, and avoid use of the term 'interface' altogether. I'll try to make this distinction in future discussion, thanks.
-
This thread seems to have diverged into a few distinct topics: Original thread topic: How to distribute updated "preferences" data to multiple processes. Ancillary topic 1: Using classes to define configurable data items. Ancillary topic 2: Using configurable objects within a "configuration editor" (or "preference dialog"). On the original thread topic: If multiple processes require configuration and these processes operate as some sort of state machine: there is probably a valid state in which editing configuration should be allowed (and disallowed in other states), and there is probably a transition during which configuration should be loaded and cached within that process. If other processes requiring the configuration are state-less (except maybe init & run), then they probably need to be signaled to re-init (i.e. reload the configuration from disk, DB, or FGV) after it has been edited. On topic 1: There's a tradeoff between the beauty of mutable version handling when loading classes serialized to disk and the convenience of human readable/editable files. If you're attempting to maintain multiple deployments & versions, or if requirements are frequently evolving, then it's probably best to just flatten objects to disk. I find it hard to come up with a compelling case otherwise. On topic 2: Shane's suggestion is good, "self-displaying objects", but it's easier said than done. How would you handle a configurable object hierarchy, where each child class contributes its own configurable attributes. After the self-display method is running in a subpanel how do you pass in the current configuration to display, how do you signal it to stop then pass out or retrieve the updated configuration? Is each object in charge of it's own disk read/writes or does the top-level config editor handle it all generically? There are many right answers here of course, it's not "one-size-fits-all". I find that most solutions are either highly extensible but relatively complex to use and non-trivial to implement, or they are simple but rigid and limiting. For those of you who have a good solution or idea, please describe context in which it is applicable. I know that Paul's solution described above used on the Discovery Channel Telescope works well for state-based systems that are deployed to one location, undergo little to no change to configuration datatypes, and require separate applications to edit and load configurable items.
-
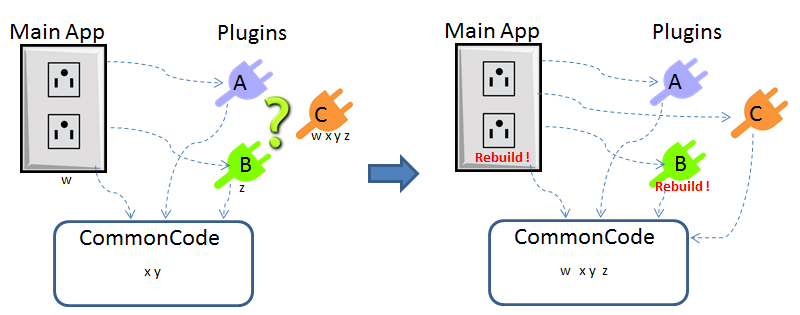
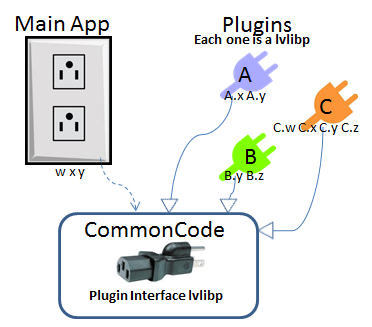
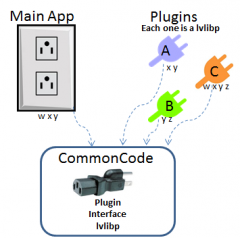
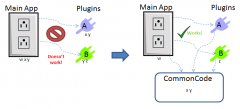
Having tried many of the solutions suggested here (and having authored the doc on the dark side about plugin architecture) I have a few comments based on much time spent wrestling with these issues. Agreed. Since Chris wants "plugins... able to update independently of the application", this is not an option. You're on the right track here, only it's widely considered poor practice to have anything in source directory have dependencies in builds directory. I tried this once - problem is, you end up with duplicate copies of many things in vi.lib. If you want to develop new plug-in code that links to this common source distribution, you can't drop vi.lib functions from the palette anymore. I tried to work around this with a "build wizard": In development, my plug-in would link to vi.lib and other common code as normal, but as a prebuild step the wizard would check all dependencies against the common code library, exclude these from the plug-in build, and perform relinking. The problem I didn't anticipate, is that new plugins often introduced new common dependencies! So, the wizard actually then had to check the main app and all existing plug-ins, to see if any new common dependencies needed to be moved to the common code library distribution, then I had to rebuild the main app and all affected plug-ins. It was a nightmare, and didn't even satisfy the original intent of decoupling. Here's the idea, illustrated: Plugins A & B have shared dependecies x & y with the Main App. Loading plug-ins directly from built app doesn't work. Moving x & y to common directory does work if the main app and plug-ins are linked to this common code distribution. But, when we introduce plugin C that has shared dependencies with the Main App (code w) or another Plug-in (code z), then those dependencies must be moved to common or else the new plugin (or existing plugins if the new one is loaded first) will be broken. The fix requires moving w and z to common, and rebuilding Main App and Plugin B. The solution using packed project libraries is a fairly elegant solution to this mess. Here, the interface is the only common code, built as a packed proj library (to the source directory, and treated as source code). The Main App uses this interface, not directly calling the plugins. The plugins are classes that inherit from a plugin interface class in the built lvlibp (yes, OOP makes this so much simpler). Lvlibp's build all dependencies into their own package using unique namespace. So, although there will be bloat to the program where dependencies are duplicated, the upside is that they can vary independently and not introduce conflicts with other plugins or the Main App. I'm sure there are other great solutions out there... but this one works for me. Go here for a more thorough step-by-step and example code. Hope this helps!
-
-
-
Thanks to Ram Kudukoli (of NI R&D) for sharing this with us at the recent CLA Summit: If Façade is not executing fast enough to keep up with data updates, it causes the updates to queue up. The updates will happen even after the VI stops running. To reduce data updates: - Open the Xcontrol .xctl file in a text editor like Notepad. - Add the bolded line shown below: <Property Name="NI.Lib.Version" Type="Str">1.0.0.0</Property> <Property Name="NI.XClass.Flags" Type="Int">0</Property> <Property Name="NI.XCtl.OptimizeDataUpdate" Type="Bool">true</Property> <Property Name="NI.XItem.DeclaredLeakProof" Type="Bool">false</Property> - Save the .xctl file.
-
James, The "unresolved issue" can be fixed as follows: Change the 'View A' and 'View B' static VI references to NOT strictly typed. In 'SubView Helper.vi', instead of the 'call by reference node', use 'Control Value.Set' invoke node to pass the 'Shutdown Event' then run it with 'Run VI' invoke node with 'Wait Until Done' set to TRUE. By not requiring a strict VI reference to the 'Launch SubView' VI, you also gain some flexilbity in what VI's could be used since there's no more tie to terminal pane configuration.
-
Thanks G Systems! Count me in.