Aristos Queue
-
Posts
3,183 -
Joined
-
Last visited
-
Days Won
207
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Aristos Queue
-
LabVIEW Community Edition 2020 is now available for download. The commercial edition will follow sometime in May. We prioritized the Community release for all the engineers stuck at home under quarantine. LabVIEW 2020 introduces interfaces as a companion feature to LabVIEW classes. I and Allen Smith will be presenting what would have been our NIWeek presentations as a webcast this Friday. Two topics, one time: Intro to Interfaces (Stephen Loftus-Mercer) Interfaces and the Actor Framework (Allen Smith) Friday, May 1 10am, CDT Join here (Microsoft Teams required): LabVIEW 2020: G Interfaces [EDIT] The same link above will let you watch the recording for the next 90 days. After that, NI will find some place to more permanently host the video. Youtube Link If you have any follow up questions, Allen and I are both monitoring a specific forum thread on ni.com for this presentation for the next couple weeks. To start learning about interfaces today, please see the Fundamentals>>LabVIEW Object-Oriented Programming section of the LabVIEW 2020 shipping documentation the shipping examples in examples\Object-Oriented Programming\Basic Interfaces examples\Object-Oriented Programming\Actors and Interfaces If you are someone who already knows about interfaces from other programming languages and want to understand why G interfaces work the way they do, you may be interested in reading LabVIEW Interfaces: The Decisions Behind the Design.
-
I don't want to just remove the privates completely ... if you're working inside the class, you may need those. But there's an old compromise in the actual palette code... if a library is locked (not just read-only but actually locked) or password-protected, then hide the community and private scope methods. Our theory was that if a class is locked then its internal development is finished and published and any of its friended components are probably also done (or they know that they are friends and can go get that information). Similarly if all children are either non-existent or also locked, then remove the protected scope stuff. I don't know how hard it is to get that info without opening a class library refnum. I sooooo wish that getting a library refnum wasn't a performance death sentence. I had nothing to do with creating that code. In retrospect, I wish I had stuck my nose into that project. I've looked into refactoring it... it's a mess.
-
 You cannot use any reference to the class itself within the class. Technically, we could enable some things, like a DVR of the class within the same class, because the default value is Not A Refnum. But we chose -- consciously -- to make the rule "no references to yourself in your own private data." It's an easier rule to teach, and it has various performance benefits for initialization (that mattered more on the hardware from 13 years ago than they do today). And it has come up very rarely. In fact, I think you're the first person whose asked me specifically about the VI reference case. All the others have a reasonable workaround... need an array of X? Use an array of its parent class (which may be LV Object). Same trick works for most refnums... or you can always cast a refnum as an integer and cast it back when you need to talk to its data. But casting doesn't work on strict VI refs and you cannot use it as its parent class type. I think you're stuck. I can't see a way out of that box.
You cannot use any reference to the class itself within the class. Technically, we could enable some things, like a DVR of the class within the same class, because the default value is Not A Refnum. But we chose -- consciously -- to make the rule "no references to yourself in your own private data." It's an easier rule to teach, and it has various performance benefits for initialization (that mattered more on the hardware from 13 years ago than they do today). And it has come up very rarely. In fact, I think you're the first person whose asked me specifically about the VI reference case. All the others have a reasonable workaround... need an array of X? Use an array of its parent class (which may be LV Object). Same trick works for most refnums... or you can always cast a refnum as an integer and cast it back when you need to talk to its data. But casting doesn't work on strict VI refs and you cannot use it as its parent class type. I think you're stuck. I can't see a way out of that box. -
No. I didn't take the time to do that. Would be cool if it worked though. If you decide to patch it up (there's no passwords on those VIs), I'm happy to ship the revision.
-
In LV2019, I extended the right-click plug-ins to be able to attach a graphical palette so you can drop items from the menu. Then I added the right-click menu item to populate the palette for classes. And I just found out (thanks, Darren) that LV2020 doesn't update this graphical palette for methods coming from parent interfaces. Haven't even released... already have a patch list. *sigh*
-
LabVIEW NXG Feature Parity to LabVIEW "Classic"
Aristos Queue replied to lvb's topic in LabVIEW General
> Admittedly, it has been probably a year since I heard that discussion. About a year... yeah. 🙂NXG's G scripting priority was... shall we say... re-evaluated after the European CLA Summit in 2019. It was kicked up a few notches after some very pointed comments from the user community, confirmed by Americas CLAs later that year. I'm not on that team and haven't kept tabs, but there should be some scripting support soon if it isn't already there. -
Bah, Crossulz! You are definitely not invited to the next White Elephant gift exchange. You'd show up with a wrapped present and just announce, "It's socks. Just so you know."
-
You know how all LV objects are represented as cubes? What do you call just the surface of a cube? 🙂
-
> I have heard directly from NI that there are no plans to delay the releases that were planned for NI Week being in May. A few are moving a bit earlier even. I'll be flagging LV 2020 on LAVA as soon as it is available (if the NI marketing folks don't beat me to it). I'm maybe perhaps just a little bit excited about this particular release.
-
That pretty much defeats the purpose of the VI. The whole point of the exercise was to figure out how big to size the VI relative to the monitor so the caller VI could maximally lay out its controls without taking up the whole screen... and if I don't know which monitor it is on, it doesn't work. 🙂 BUT... you made a great point about the run-time engine. You're right that I should have avoided the use of scripting, esp since there's a dead obvious existing VI to use -- the subVI itself! So I eliminated the app reference (HUGE performance savings closing that reference), and the creation of the new VI (no screwing with the Untitled VI count every time this VI runs), and got rid of the close ref of the new VI (another major savings). And now it'll work in a run-time engine, and it is now fast enough that I don't have to worry about caching. Thank you for the suggestion. Saved, as before, in LV 2014. Note: I worked in LV 2020, and I just picked 2014 as the version to save back to... it'll go back earlier if someone needs it, but, honestly, folks, I only get paid if you upgrade! 🙂 Compute Maximum Desktop Bounds.vi
-
Have it working. @The Q : Darren had the same suggestion you did. Worked just fine. See attached VI, saved in LV 2014. Compute Maximum Desktop Bounds.vi
-
LabVIEW NXG Feature Parity to LabVIEW "Classic"
Aristos Queue replied to lvb's topic in LabVIEW General
I'm still working on LabVIEW 20xx full time, and I'm not alone. So it isn't this year. 🙂 But NXG releases full versions more than once per year. Right now, we (NI) aren't publishing a timeline for end of development of LabVIEW 20xx. We have a date we'd like to see, but it'll depend upon NXG code velocity and customer adoption rates. There are already customers who only work in NXG. Each customer will have a different key feature where they say, "Ok, NXG is ready for me." Eventually, it'll be the vast majority of our users. My hope is that we won't ever announce a planned end date. Instead, we will keep announcing how much more awesome NXG is than a few months ago. And, one day, you all will stop asking me for new features and I'll stop wanting to add them into LV 20xx because everything we need is over in NXG, and why would we stay in 20xx when that other platform has prettier graphics, and VIs that can't crosslink paths, and a reasonable componentization system, and Unicode support, and integrated hardware panels, much more impressive FPGA abilities, and Web integration, and... and that's all the stuff it already has today. NXG already is the platform I really want to be able to use for G. Someday, it'll be the platform I can use. On that day, you all won't care that I'm moving away from LV 20xx because you'll be already over there. And on that day, I'll make a choice: to either go join the NXG team (again -- I did develop on it for four years early on) or finally abandon text programming and become a full-time G programmer. The only thing I'll say about the roadmap is this: that day is coming. You tell us when. -
Multiple EXE instances crashing at the same time?
Aristos Queue replied to drjdpowell's topic in LabVIEW General
Another idea: Does the DLL possibly reach for some external resource, like a database or network connection? If that thing fails, maybe their error handling for the failure is poor, and all the EXEs would see the failure at roughly the same time. -
Multiple EXE instances crashing at the same time?
Aristos Queue replied to drjdpowell's topic in LabVIEW General
Another possibility is that the DLL creates a separate process to do some work and then communicates with that process... if that process is a single instance that all DLL instances talk to, that would be another way to get a crash like this. Look for another process appearing in your Task Manager right after you start the first copy of the app. -
Setting the key focus on an array control programatically
Aristos Queue replied to John Lokanis's topic in User Interface
Benoit: I just saw this post while hunting around for a bit of help myself. I looked at your VI. It's not a bug. You aren't ever setting the active element of the array -- the same physical position remains active unless you click with the mouse or use TAB key to move to the next element. To the best of my knowledge, there is no programmatic way to set the active physical slot of the array control other than simulating a mouse click or something exotic like that. The array control is not a particularly good control for UI, in case you hadn't noticed. It was never designed for a interactive front panel. The one in NXG is better. -
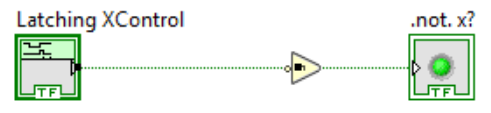
Does anyone have a picture showing how, given a VI, I can get ... ... the size of the monitor hosting that VI's panel... ... minus the taskbar size (if any) on that monitor... ... in a platform (OS) independent manner? I had a clean-but-annoying way to do this until I discovered that Windows10 has a mode that lets the task bar be replicated onto different monitors (and, worse, those taskbars aren't necessarily the same size). The only trick I can come up with is to maximize the panel momentarily and grab the panel size at that moment, but that creates flicker in the UI. Yes, I am aware of these two properties: They do not suffice. The first one gives all the monitor sizes without accounting for taskbar. The second one only reports taskbar on primary monitor. If I could be sure the taskbar was only ever on the primary monitor, I can figure it out from this info, but discovering taskbars on multiple monitors was an option throws a wrench in that plan.

-
Nifty trick! I'm impressed with the ingenuity. But two minor caveats... Warning 1: This XControl allows local variables and Value property nodes. LabVIEW prevents the built-in latching Boolean controls from having either a local variable of the latched Boolean (compile time error) or a Value property node (run time error). Those things would mess with latching, and will interfere with this code executing correctly. You should not use either of those things with a latching XControl. Warning 2: This XControl uses an unpublished private method of scripting that is known to have problems with thread synchronization. It was created to handle some very specific editor operations. It is not a safe thing to use generally, which is why it has never been made public, because of inplaceness optimizations that make multiple wires share the same memory. I think the use in this case is safe because there isn't any optimization that I know of that will make LabVIEW avoid the data copy if a downstream node modifies the value. For example: The above image shows the Buffer Allocation dots... and we can see that the Not copies the Bool, even when debugging is turned off. I will ask my team if there are any scenarios where inplaceness will elide that dot. I don't think there can be (because So it seems to be ok here, but I would not advise freely using that method in code generally.
- 1 reply
-
- 1
-

-
Reusable Events Between Parent and Child Classes
Aristos Queue replied to GregFreeman's topic in Object-Oriented Programming
> If a second loop is needed, it could probably be handled through composition instead of inheritance. Agree in general. Composition can get complicated if that second loop needs to be a Timed Loop -- if the timed loop's operation sometimes needs to be reconfigured while it is running, messages may be needed that extend Actor's API, and avoiding that is just more complicated than I think is worth doing. It may be a technical conflict of SRP, but practicality does temper the principles sometimes. There may be additional cases. -
Reusable Events Between Parent and Child Classes
Aristos Queue replied to GregFreeman's topic in Object-Oriented Programming
Actors in Actor Framework inherit from each other, and if the parent defines a message to be handled, then the children can handle that message. Put another way -- I built an entire framework to handle that exact problem. It doesn't use the Event Structure. The only solution I came up with that I liked that used the Event Structure was an entirely new conception of inheritance, a new fundamental type of VI, and a new editor. It not only solves the problem of event inheritance but also front panel inheritance. I have it all mocked up in PowerPoint to build someday (when LV NXG is mature enough). -
Is LabVIEW a programming environment, vs Doom
Aristos Queue replied to Mefistotelis's topic in LabVIEW General
This is not really true. I mean, it's kind of true, insofar as LV executes assembly level instructions, not byte code. But it is also misleading. LabVIEW doesn't ever get to a deep call stack. Suppose you have one program where Alpha VI calls Beta VI calls Gamma VI calls Delta VI and a second program which is just Omega VI. Now you run both and record the deepest call stack that any thread other than the UI thread ever achieves. What you'll find is that both programs have the same maximum stack depth. That's because all VIs are compiled into separate "chunks" of code. When a VI starts running, the address of any chunk that doesn't need upstream inputs is put into the execution queue. Then the execution threads start dequeuing and running each chunk. When a thread finishes a chunk, part of that execution will decrement the "fire count" of downstream chunks. When one of those downstream chunk's fire count hits zero, it gets enqueued. The call stack is never deeper than is needed to do "dequeue, call the dequeued address"... about depth 10 (there's some start up functions at the entry point of every exec thread). -
Is LabVIEW a programming environment, vs Doom
Aristos Queue replied to Mefistotelis's topic in LabVIEW General
A programming language exists in any Turing complete environment. Magic:The Gathering has now published enough cards to become Turing complete. You can watch such a computer be executed by a well-formed program. People might not like programming in any given language. That's fine -- every language has its tradeoffs, and the ones we've chosen for G might not be a given person's cup of tea. But to claim G isn't a language is factually false. G has the facility to express all known models of computation. QED. -
This might vary by operating system, but I think you're correct. I have only once had reason to drill that deep into the draw manager layer of LabVIEW's C++ code. But the whole point of deferring updates is to avoid flicker, so it would make sense that LV would aggregate into a single rectangle and render that as a single block... if it tries to do all the small rectangles, that's probably (my educated guess) the same flicker that would've occurred if defer never happened.
-
A call to a static dispatch VI will always invoke that exact VI. A call to a dynamic dispatch VI may invoke that VI or any VI of the same name of a descendant class. Exactly which VI will be called is decided at call time based on the type of the object that is on the wire going to the dynamic dispatch input terminal. A dynamic dispatch VI is equivalent to a virtual function in C++, C#, or JAVA (and other text languages).
-
For anyone else interested in how far this bug goes, I got this from one of my coworkers: From my research it affects all processors based on the Zen 2 architecture (AMD processors that started being released in July of last year). AMD claimed that they dropped support in Zen 1 for fma4 instruction set, and the illegal instruction causing the crash is part of that set. The first series Ryzen processors sound like they may still work, but I didn't have access to any to verify one way or the other.
-
The MKL problem is in the wild? I thought that was something that was only affecting LV 2020 (now in beta) because we were updating to the latest MKL. The bug isn't on my team's plate... I just sit near the people who are handwringing a lot about it. If that's in the wild affecting already shipping MKL versions, then, yeah, that could be it. I still don't know how the node is rolling back to its last known good resolve path... I can't find that path stored anywhere... but if we assume it is binary encoded *somewhere* in the node's saved attributes, then this makes plausible sense. Workaround is to a) get a new CPU or b) wait until LV issues a new version where we do whatever we are doing to avoid calling certain CPU instructions (I'm unclear what the planned solution looks like).