PaulL
-
Posts
544 -
Joined
-
Last visited
-
Days Won
17
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by PaulL
-
I hadn't heard of IntelliJ IDEA, but I looked it up (IDEA). It is a Java IDE and as far as I can see it's main UML functionality is that it supports a version of a class diagram (Class diagram). So it is difficult to do a meaningful comparion of IDEA and Enterprise Architect since they are radically different tools. Not all Object-Oriented languages support multiple inheritance. (Java, does not, for that matter!) (Java Language Environment) I agree with NI's decision not to implement multiple inheritance in LabVIEW (Decisions Behind the Design) since I think multiple inheritance opens the door to more problems than it solves. I agree something like Java-style interfaces could be quite useful. Agreed. Of course, if a tool can do "auto documentation" (i.e., reverse engineering) then it pretty much has the capability to do code generation, and if you have these then you might as well take advantage of the features of a truly powerful tool, I think.
-
I spent some time thinking about your reply overnight: Symbolic paths, Quick Drop, Palettes--all these are good points! While none of these is particularly compelling for our particular (internal!) use cases (our relative paths are the same--enforced via version control--and we find it simpler to use the project interface than wait for Quick Drop or set up the Palettes), certainly if one ever intends to hand off a tool, for example, to an external user I see that the code should very definitely be in the user.lib, for all the reasons you stated, and it is simpler from a long-term maintenance standpoint to put it there initially. Point taken. [Also, if one isn't using projects and project libraries one simply can't do what we do, as noted.] Our team should take a closer look and see if there are frequently-used tools we should put in the user.lib. Thanks! Paul
-
OK, I've been wondering about this for a while... What are the advantages of putting code in the user.lib? Is it to put things on the palettes? (See Organization of LabVIEW.) Does it also somehow help to maintain multiple versions? (I'm not aware of anything in this regard.) Is there some other advantage? What we tend to do is put our reuse libraries in a Common directory in our general code file. What is essential is that each chunk of reuse code is in a project library (.lvlib), which functions as a "package" in our terminology. Since we are using project libraries, a change to a project library in one project will propagate to all projects, and we just need to check out the latest version from Subversion to use the latest code. I guess the limitation is that we don't set up the user.lib palettes, but for our purposes we find it easier to drag anything we need (which is uncommon anyway) from the library in the project. (There is also strictly speaking nothing limiting who is able to make changes to a library. In our experience we haven't found that to be an issue.) Note that we don't have to maintain lots of versions (2009 vs. 2010, for example) for our applications. That would certainly make life more difficult, although I'm not sure using the user.lib helps in that respect. Does it? (I imagine VIPM can be very useful for this sort of thing.) The only things that end up in the user.lib for us are error code files, just because LabVIEW requires them to be there (which I think is an unfortunate departure from the project paradigm, by the way). The Common folder with project library approach is quite simple, works exceptionally well for our use cases, and doesn't rely on a third party package. I can see that if you want to use the palettes (e.g., for core toolsets) you'd want to use the user.lib. Otherwise, why? Paul
-
 I should reiterate that I think using project libraries (.lvlib files) is a very good idea. There are some issues with the implementation of project libraries as well, but they are quite helpful in managing code.
I should reiterate that I think using project libraries (.lvlib files) is a very good idea. There are some issues with the implementation of project libraries as well, but they are quite helpful in managing code. -
Yes, the namespace changes. Fortunately, LabVIEW 2010 does make the process easy for you--in one direction only. You can click on a project library (.lvlib) in a project and choose to replace it with a packed project library (.lvlibp). LabVIEW will update all the callers in the project. When I tried this it worked fine. Note that LabVIEW 2010 does not support the reverse process (automatically replacing a .lvlibp with a .lvlib), so be sure you really want to do this before you make the change! (We have an open support case with NI to do just that. The AE wrote a scripting VI that does much of this, but it doesn't yet work for certain pieces.) I'm not sure about your second issue (LibC.lvlib). When I built a packed project library that had dependencies on another library, I built the dependency into a packed project library first. (So all callers in a project would call LibC.lvlibp.) I'm not sure that in principle it would be appropriate to do otherwise, but I still would like to know the answer to your question. In our case we found the following with packed project libraries in 2010: 1) Projects took much, much longer to open (20 minutes in one case!) after we replaced .lvlibs with .lvlibps. (Yes, the project mentioned was big but it didn't take nearly that long to open when we just had a .lvlib.) 2) Executables took just as long to build after we replaced .lvlibs with .lvlibps. (I think expediting build times would have been the main reason for using packed project libraries.) 3) We had circumstances where a contractor needed access to the source code anyway because they needed to modify shared variable properties for testing. For these reasons (worse performance instead of better, lack of flexibility to revert callers to link to .lvlibs--which is exceptionally limiting and was in our case quite costly to fix, no benefits whatsoever), we managed to revert our .lvlibps to .lvlibs (the AE's tool got us most of the way) and have abandoned .lvlibps entirely, at least in their current instantiation. Honestly, I wish I hadn't wasted my time with packed project libraries as they are in LabVIEW 2010. That was just a big mistake on my part. I'd love to hear what experiences others have had, good or bad, though. Paul
-
My perspective (at the risk of repeating much of what Dave said) is this: We want components to be as independent of one another as possible. We want a component to respond to data received on its external interface. A component can receive data via a wire or via some sort of communication. If the component is running in its own thread and needs to respond to external data at any time then we need to implement some sort of communication (signaling). (Yes, we can also use by-reference objects to do this, but I think this obfuscates the code and makes it much more difficult to maintain, since it increases the coupling between classes. In most cases it is far better to define an external data interface for a component.) If we choose to use signals we can send any type of data we want, but we should define the simplest external interface possible for a component (to make the intent clear and to minimize the need for changes by decreasing coupling)--and use an appropriate messaging paradigm. (Very important: The message content and the messaging paradigm can and should be independent of one another! We should be able to change one or the other as needed!) We can send any data by flattening it (to a variant or a string or XML) but the receiver needs to know the type in order to interpret the message. To achieve that we can use one type per message or, send the type as part of the message (can get complicated), or, if we are using objects, make the top-level type of a single message an abstract class and use dynamic dispatching, extending the abstract class for each actual message type as needed (which is the essence of the Command Pattern). (In this case a sender or a receiver needs to have access to the definitions precisely for the objects it sends and receives, but not for other messages. This is the essence of defining component interfaces.) Paul
-
There is a well-established design pattern to do exactly what you want. See the Memento Pattern in GoF Design Patterns. Also look at how you can combine this with the Command Pattern. You can support undo operations; the different commands and their parameters can be of arbitrary complexity, and can each have its own parameters. I highly recommend you take a look at this proven approach.
-
How to read the name of caller inside his subvi.
PaulL replied to Matteo's topic in Application Design & Architecture
OK, this doesn't answer your question directly, perhaps, but can you explain further what you are trying to accomplish by doing this? I can imagine a situation where a method (your subVI) operates on any of a number of instances of some component. In an Object-Oriented world I would instantiate an object for each instance of the component and then pass that object as an input to the subVI. Certainly one could do a similar thing without objects by passing some sort of reference (could be just a VI name) from the caller to the subVI. Does this get you any closer to what you are trying to accomplish? -
Yes, my suggestion applies only if the developer can write an FPGA VI.
-
Where is the VI-to-be-triggered running? If you read the microswitch on the FPGA you can generate an IRQ on the cRIO FPGA and respond to that IRQ in the Real-Time (RT) code to trigger a VI. To do this: Set up a loop in the FPGA code to read the value of the microswitch. When the microswitch value changes call the Interrupt function on the FPGA (Synchronization palette) to assert a specified interrupt. On the RT side, in a loop (assuming you want to be able to respond to a change more than once) use the Wait on IRQ method--select this on an Invoke Method (FPGA Interface Palette) with the correct FPGA VI Reference. When this method returns execute the desired RT VI. (Note there is an Acknowledge IRQ method here as well in case you want the FPGA to wait for acknowledgment before sending the next interrupt.) (For the record, if the VI to run is on the desktop--specifically in Windows, you could, upon receipt of the interrupt in the RT code, write a value to a shared variable, and then handle the shared variable value change event in the desktop application. Of course, there will be some network latency, and shared variable value change events are only available with the DSC Module, which in turn only runs on Windows.)
-
After lunch... OK, this seems to be an argument in favor of packaging things in project libraries. Actually, that's what I am trying to do at the moment--replace code with code in a library. There's actually only one call on the RT side, so it's really not hard at all for me to fix in any event for this situation, but it does kind of point out what I think is a problem. At least at the top level if you go against advice Daklu offered on another thread and change the namespace of something called in another application space, you can end up with broken and not at all easily fixable code.
-
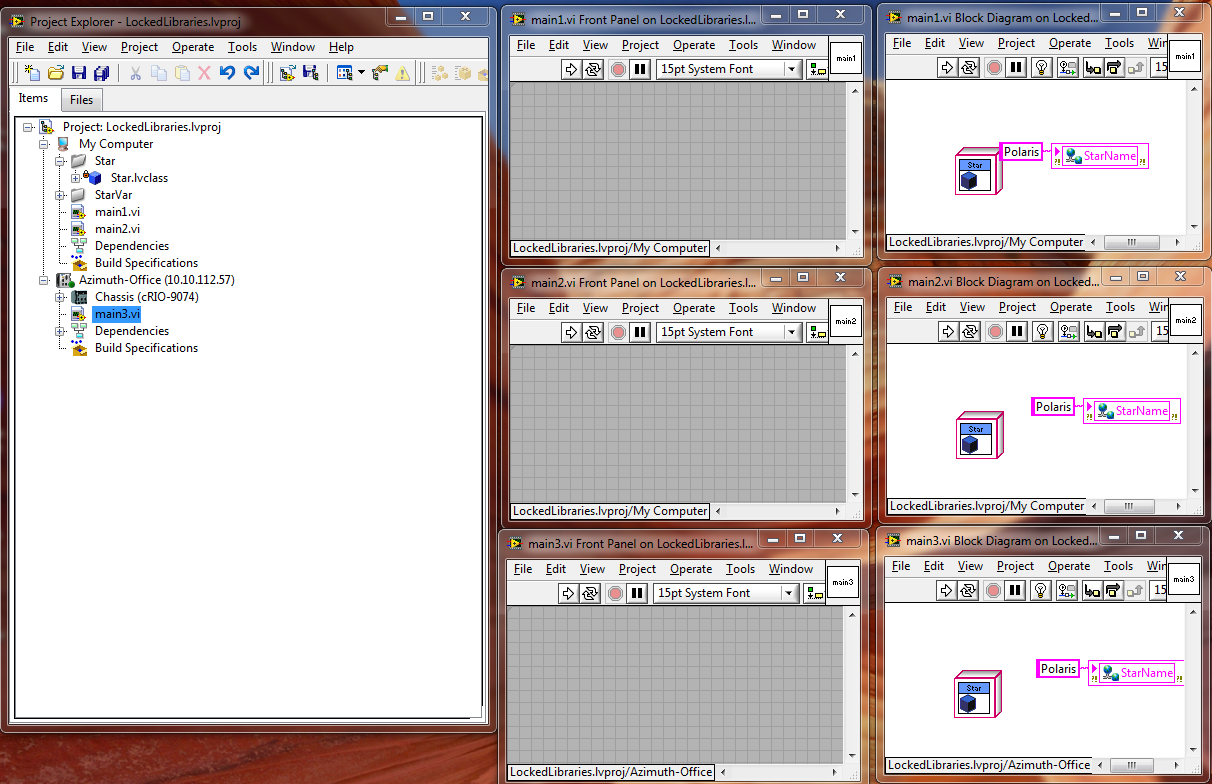
OK, I see. I did find a helpful page on what an Application Instance means in LabVIEW Working with Application Instances. For the record, I did the following test: I created a test project in LabVIEW 2009SP1 and added a class to it. I called it in a top-level VI (main1.vi) on the same target, then main2.vi on the same target, and finally in main3.vi on a different target. Only when I added main3.vi to the second target did the class library lock. I do see, then, that is a good argument to create separate projects for RT Targets (which is not what we have been doing), as you suggest. In our situation we have to be sure we handle our networked shared variables correctly, but I don't think that's all that much of a problem since the shared variables are in a project library, and in principle it can be more flexible. (Note that you can update a shared variable project library open in two projects simultaneously, as long as you update the library in one instance if you've changed it in the other.) OK, the thing that troubles me is the renaming issue (already touched upon in other threads). Let's say I use a class (or any library) in two projects and rename it in one project while the second project is closed (necessary, as we just said, in the case of classes). This will break all the callers in the second project, and I can't just do a quick replace in the second project to remedy that. (LabVIEW tells me the class, for instance is not loaded, but I can only load it with a class of the same name; I can't replace it with the renamed class.) (Hmm... if I copy rather than rename the class then the second class will point to the original, which I can then replace. That might be a workaround, but it is definitely a workaround.) In any case, doesn't that seem like a serious limitation? (It certainly is one we have encountered.) Maybe it would be sufficient if LabVIEW would let you replace an unloaded class with another class (certainly OK if it is just the renamed version, but of course I would expect callers to break if I picked the wrong class). Or is there a better way to deal with this? I just checked and replace is not an option for a class in a project, even if it is loaded.

-
Hmm... maybe so. I can't remember if this was the case before. It doesn't present the same cross-project issue AQ was describing. I don't think there's a reason a change to a called class can't update both callers within the same project. (In the current instance, I just want to resave the class to a new location on disk. I don't remember not being able to do that just because I have two callers--in the same project--before, but maybe I'm wrong.) Later... OK I found this link Link on locked classes and it's all consistent, but something still seems not right to me, but probably that's an end-of day-thing. In any event it seems more problematic than I remember it being. There usually is an easy way to work around a class lock, but the solution isn't jumping out at me tonight. Tomorrow morning, then!
-
I just got the same message and I only use the locked class in a single project. There are no other projects open. For the record, I just installed the LabVIEW2010f2 and RTf1 patches today.
-
Thanks to you both for this exceptionally helpful information! We struggled with this a while back and then pushed off the resolution to a later date. This gives us a workable solution! Reputation points coming your way! A couple things I observed: In zobert's 20Sept post I think the quotation marks should enclose just the font name, not the size. Anyway, it seemed only to work for me the one way. I found that if I changed the .ini file for a built application (.exe) I had to recreate any shortcuts. (If I just ran the application from the existing shortcut the changes to the .ini file were not applied.) In practice, I expect that won't happen often, but when I was trying to follow what you all were suggesting I ran into this and found it quite confusing. (Nothing I changed in the file made a difference!) Thanks much!
-
It's interesting that you mention this. I was just working on a DAQmx application today (I actually don't do this very often, actually, since we've been using mostly cRIOs), and originally I tried to put the acquisition, resampling, and logging in the main loop. After several minutes the application started lagging (I'm not actually quite sure why) way behind. I then started dividing the pieces into loops and before long into separate VIs and therefore threads (using networked shared variables, of course, to handle the signaling), and the timing of the application now works perfectly (and the CPU usage also reduced dramatically). I was actually quite surprised that doing the same things but in separate threads would make that much of a performance difference, but it surely did for this application! (It's a bit easier to debug, too.)
-
The normal Windows jitter--10 ms or so. Note that we don't run our TCL all that fast--only 62.5 Hz, but we do a lot in it (probably too much). Windows handles the shared variable logging, and other clients need some of the published information but not in a critical time period. I couldn't agree more! OK, I've said as much before. The bottom line is I think some sort of implementation of the Observer Pattern/Publish-Subscribe-Protocol is essential for creating any sort of meaningfully scalable component-based system. I think in order for LabVIEW to be competitive in that market (or really any application market, since separating pieces of an application into threads is important in just about any application) LabVIEW needs this. Java has Swing other things. LabVIEW now has it, but unfortunately not all the essentials are in the core product, so they don't see as much use as they should. In particular, shared variable events and control binding are essential shared variable features. Why would anyone use shared variables without events? I think the logging can be an extra feature for the DSC Module (and I think it's well worth it), but LabVIEW developers need to think of shared variables (or the equivalent) when they are designing a system or really any application, and I suggest they will if these features are available. I think then NI would sell more LabVIEW licenses in more places and more DSC licenses. (It also means NI would devote more energy to improving the shared variable implementation, since more people would be providing feedback. Everybody wins!)
-
So one would think, but actually one can use a network-published shared variable even in a time critical loop on RT--as long as one configures it to be RT-FIFO-enabled. Then LabVIEW is smart enough to wait to do the networking part of the operation outside the time-critical loop. (Of course, there will be jitter in when the remote recipient gets the data because of the networking, but if this is OK for your application--as it is for ours--then this works fine. One of the folks at NI recommended I do it this way a couple years back, and it works.)
-
I can't post the source code from the paper. On the other hand, I have been thinking about just coding up the relevant examples from Head First Design Patterns in LabVIEW and making those available. That, I think, might be helpful.
-
Shared Variables 2010 now support Type Def Linking
PaulL replied to jgcode's topic in Development Environment (IDE)
That's one we had asked for, too! Thanks for pointing it out! It is indeed an important improvement! -
If you want to call the same method on the data, but you want the behavior to be different based on the type (i.e., you have a different algorithm for each), this suggests the use of the Strategy Pattern. Check out the first chapter of Head First Design Patterns.
-
packed project libraries
PaulL replied to PaulL's topic in Application Builder, Installers and code distribution
Oh! Well, I completely misunderstood, then. Thanks for the link to the other thread (which for some reason I had completely missed!). I'll have to read that thread carefully. We use essentially the same approach you describe for our file structure. Part of the problem was we started in the My Documents folder, and then had the version control folders and so on before we ever got to the code. Then we encountered long file names when we tried to do a Save As.... Since we moved everything out of My Documents we've been OK. -
packed project libraries
PaulL replied to PaulL's topic in Application Builder, Installers and code distribution
You are correct that this is currently the situation but I think I should comment on this issue because it troubles me--greatly. So what follows is an aside on that topic. Caveat lector! :-) {It certainly is true right now in LabVIEW, but it shouldn't be as bad as it is. [The worst part, in my experience, is that LabVIEW won't let you correct the problem--or more accurately some manifestations of it--in any reasonable fashion. Right now a LabVIEW class converted to be inside a library will show up in the dependencies (when called in another project) when an external caller VI includes a class constant or control of that class, and, worse yet, even if one clicks Load and points LabVIEW to the class file on disk, it won't load the class and fix the problem. So, yes, if you have a lot of such calls think twice--or thrice--before changing the namespace!] Note that UML/Enterprise Architect does not have this problem--even between projects. (OK, there may be a way to force the issue but in practice it doesn't happen.) This is because of the way EA handles the links between elements. LabVIEW could use this model between classes (and probably in principle LabVIEW's model is not so different, just not fully or correctly implemented). (OK, the tricky part is in the relationships embedded in the code of the method calls themselves, but I think this is not really all that different. Actually, we know it's not, since if we resave a linked file within a LabVIEW project all the callers update correctly. So the sort of relinking I am envisioning is quite possible.) (If we had a full-featured UML tool with forward and reverse code engineering, we would just restructure the relationships in the model, then rebuild the code. ) This could be--and should be--easy as pie. Why are we as application developers thinking about file paths at all? (I suggest with a bit* more work on LabVIEW itself this would be totally unnecessary.) I suggest--by no means a hard number but an educated guess--that such an effort would reduce our development time by ~70%. That would be an awfully good return on the investment! [*Disclaimer: I don't know how large the bit is but given that the technology readily exists elsewhere I don't think it's really all that much. In fact, I think the first part is in the realm of bug fixes in LabVIEW right now.]} Of course, I have addressed these issues in other threads so I will let it go at that. At the present moment the reality is that changing namespaces when there is a caller in another project will result in broken callers and lots of extra work to fix formerly working code (I just spent the last week plus doing just this), so, yes, do this sparingly. I completely agree, except that one can actually run into the situation where there are long file names that LabVIEW (or the O/S) can't handle, so letters aren't quite totally "free." (We actually moved our working directories closer to the drive root a few months ago to avoid that situation.) Of course I am assuming that you reflect your library names in your file structure--which isn't strictly necessary but I expect is standard practice. -
OK, someone needs to start a thread on this new feature in LabVIEW 2010. Who has tried it and with what results? How does one work with packed project libraries most effectively? --- I considered this one of the more promising features of LabVIEW 2010, since we have large collections of reusable code that we realized we needed to put into project libraries. It would additionally be helpful indeed to build each piece only once (per change), which was the promise of the packed project libraries. The obvious application for us to try this on was one that took 40 minutes to build and consisted of a small application that talked to a large existing collection of code (in classes) used elsewhere. I assembled the reusable large portion into a library in one project and built it, included the referenced build in the calling project (OK, this was a nightmare--the lesson learned is to put your code properly into project libraries before attempting to reuse it!), and built the calling application. The build took... 40 minutes. Using packed project libraries didn't help at all as far as the build time goes. On the other hand, using packed project libraries does mean the dependencies of the called .lvlibp files are hidden in those libraries rather than in the top-level dependencies. I should also note that I built debuggable files. I didn't strip the diagrams, which certainly could make a difference. Another thing we noted is that if we build nonLabVIEW files (e.g., configuration files) when we build a sublibrary, we have to include those files as well in the build definition for any callers if we want to include them in the destination directory for the caller's build. Moreover, the caller's destination directory includes a copy of the sublibrary builds as well, which I understand because it makes it easy for the caller to find them and be sure to have the correct version, but it does mean that if you rebuild a sublibrary you have to then rebuild the caller (that is, if you want to reuse the new version) or copy the newly built sublibrary wherever it is used (which I understand will be legal if the interface hasn't changed). This presents a bit of a maintenance problem. Probably the easiest thing is to rebuild every caller in a hierarchical fashion, but right now we don't have a tool to facilitate that process. We have to be savvy maintainers or build our own batch build tool. (We attempted to get around this by putting all the builds in the same directory but LabVIEW won't build the caller if its dependencies are already in the destination directory. NI already thought of that and defeated it.) So... have packed project libraries been useful to you? If so, in what way? How do you handle maintenance issues (making sure you have the right versions of the packed project libraries where you want them)? Do you just stick with project libraries unbuilt (with which you may have only a single copy!)? Do you use project libraries at all? (Not so long ago we didn't much at all but my current thinking is they are critical to facilitate effective code management.) What best practices have you learned to share with the community of LabVIEW developers and, of course, advanced virtual architects?
-