PaulL
-
Posts
544 -
Joined
-
Last visited
-
Days Won
17
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by PaulL
-
No doubt! I think this is a great idea. We just haven't done this (except for some test cases) ourselves yet for the following reasons: 1) Most of our subsystems use RT SVs where (prior to LabVIEW 2009) LabVIEW objects didn't exist. (This isn't a dealbreaker, though.) 2) Our data SVs have been clear at design time and it has just been easier (and still successful) to create them using the project interface. That doesn't mean the better way wouldn't be to create them programmatically. Ideally that is what we would do. 3) On Windows we do support dynamic object data messages but to do this we create string variables ahead of time and send flattened LabVIEW objects of various types on a shared variable (topic) or two. We have implemented the Command Pattern effectively using this methodology. Again, we probably should create the string SVs programmatically but we haven't bothered to do that yet. The more SVs we create, though, the more important it would be to do this programmatically. Paul
-
True. If, on the other hand, it is an option it is a good one. For the record, I think for a number of reasons that the functionality in the DSC Module ought to be part of the LabVIEW core. In particular, the functionality in the DSC Module is an extension of existing functionality in such a way that it can take a while to figure out where the boundary lies. Moreover, the publish-subscribe option (Observer pattern) is extremely useful--and pretty much a common programming standard--and NI ought to promote its use in most applications. I think doing so would make LabVIEW development more effective and presumably enhance its marketability in turn. I didn't try this, but I'm guessing from your question that it will be big. Then the developer must choose whether the larger memory footprint justifies the ease of development for the particular application. (I also presume that the footprint does not scale linearly with the number of shared variables.) I think for many (most?) applications the larger footprint is not a serious issue.
-
The DSC Module allows one to create shared variable value change events that one can wire into the dynamic event terminal of an event structure. The DSC Module also allows one to create shared variables programmatically at run-time. (I see jgcode just mentioned this.) Currently this feature only supports basic shared variable types, unfortunately. In our code we use shared variable events a lot and they work great. In practice we haven't needed to create SVs from scratch at run-time yet. We have done something similar by programmatically copying existing shared variable libraries (with new SV names) and then deploying the copies, which is a useful way to work with multiple instances of a component. Shared variables have come a long way from their original instantiation and I think networked shared variables are a pretty reasonable implementation of a publish-subscribe paradigm. They can be pretty easy to implement. (Don't get me wrong, there are some things I still want to change, but we find them quite useful.) I recommend taking a fresh look at them. Paul
-
Networked shared variables implement a publish-subscribe paradigm (with buffering if desired). Each subscriber receives each message.
-
Do you want controls or indicators? Can you be more specific about what doesn't work?
-
First I'd like to offer a clarification. An abstract class may have one or more abstract methods, but it may contain nonabstract methods as well. If all the methods are abstract then it functions like a Java interface. (See p. 170 in An Introduction to Object-Oriented Programming, 3rd. ed., by Timothy Budd). Of course LabVIEW OOP does not currently support the definition of abstract classes or interfaces, so anything we do here is on our own. (I agree that I would like NI to change this in the future.) Currently the class hierarchies we use pretty much always include classes that we define within our project (via UML models) as abstract. This works well for us but only because we use the classes correctly based on agreed convention. It would indeed be problematic if we wanted to release the classes for general use by other developers.
-
Are all the applications using the messages LabVIEW applications? If so then I think the simplest and quickest way to implement this is to use networked shared variables. These allow you to use a publish-subscribe protocol. (You said you wanted to broadcast the message.) If you just have one message you write periodically you could use just the TCP/IP primitive VIs in a loop to write the same message to each recipient. (Or you could use UDP to broadcast.) There is also a Simple Messaging Reference Library (STM) available. Personally I think these can give you a good idea of how things should work, but I don't know why anyone would use them instead of shared variables (since these already do the work for you).
-
There are a couple interesting things here in LabVIEW. First, LVOOP class data is always private. This was a (very good, I think) design decision NI made. It promotes the use of accessor methods, which OO designers generally consider a good idea. (For more on this, see An Introduction to Object-Oriented Programming, 3rd ed., Timothy Budd.) Second, LabVIEW 2009 introduces the concept of "community" scope (in addition to public, protected, and private). LabVIEW is probably the first language to use such a scope! Setting the scope to community for a class method specifically adds it to the list of methods that a friend can access. (By the same token, methods with community scope are the only methods of the class that the friend(s) can access.)
-
LabVIEW 2009 introduces a "friends" relationship. Essentially ClassA can declare ClassB (or another type of library, or even a VI) to be a friend. Then ClassB can call any methods ClassA sets as "community" scope. NI has updated these pages with the details: LabVIEW Object-Oriented Programming: The Decisions Behind the Design Creating LabVIEW Classes
-

State Machine with Refs and Local Variables
PaulL replied to pete_dunham's topic in Application Design & Architecture
Pete, Mark's suggestion is a great one. (Separate the view from the model.) One way of doing essentially this very easily is with shared variables. Paul -
I just added a topic "Add numeric types with units as natively supported shared variable data types" to the LabVIEW Idea Exchange. I'm curious if anyone has experience dealing with this issue and has a suggestion.
-
Actually, I'm hoping for some clarification on this one. AQ is right almost all the time, so I pay a good deal of attention to his suggestions. I'm skeptical of the above description, though. I like that on a subVI the class control and indicator are cubes or boxes. This is one advantage over using large clusters. (Something like visual encapsulation, maybe?) Of course it would be good to have a way to display the contents of an object easily on a UI, and I can see how XControls are well-suited for this task. I just want to ensure I can still use the box control or indicator on the front panel (or the block diagram as a constant). Paul
-
Bugzilla for requirements management
PaulL replied to ASTDan's topic in Application Design & Architecture
Yes, Chris, I glossed over the important distinction that one doesn't, for instance, write requirements in NIRG. One imports requirements into NIRG to facilitate traceability and generate reports based on the links one establishes. Thanks for catching me! (Note that it is possible to keep the NIRG file in a project and under version control.) All, Maybe it will help the discussion to include one expert's definition of requirements management in order to evaluate whatever tool or methodology you are considering: "The central purpose of requirements management is to manage changes to a set of agreed-upon requirements that have been committed to a specific product release. Requirements management also includes tracking the status of individual requirements and tracing requirements both backward to their origins and forward into design elements, code modules, and tests" (Karl Wiegers, More About Software Requirements, Microsoft Press, 2006, pp. 7-8). By the way, I attended Jeff's NI Week presentation and I highly recommend downloading it if you weren't there. Really good stuff! Paul -
Bugzilla for requirements management
PaulL replied to ASTDan's topic in Application Design & Architecture
I found the idea of using a bug tracker for requirements management intriguing. Mind you, my first inclination was that it wasn't a good idea, but I decided to try and figure out what the advantages and disadvantages were. A couple issues came to mind. 1) It may be possible to establish some sort of traceability in certain issue tracking tools if you can link issues to one another. (We can do this in the issue tracker we use, JIRA). On the other hand, this is not document-centric and thus it would be difficult, if not impossible, to generate a report indicating which requirements one has linked to design, or to a test plan, or to test results, or to code. 2) While some level of hierarchy is also possible (JIRA lets the user define subtasks) simply entering issues does not allow the issue tracker to present the requirements in a single structured document (especially if one adds or removes requirements later!). In short, I would recommend using a requirements management tool designed for the job (DOORS, Requirements Gateway, traceability within Enterprise Architect), which I think one will need for a project of any significant complexity. Traceability is demanding to do even with the right tools for the job! Paul -
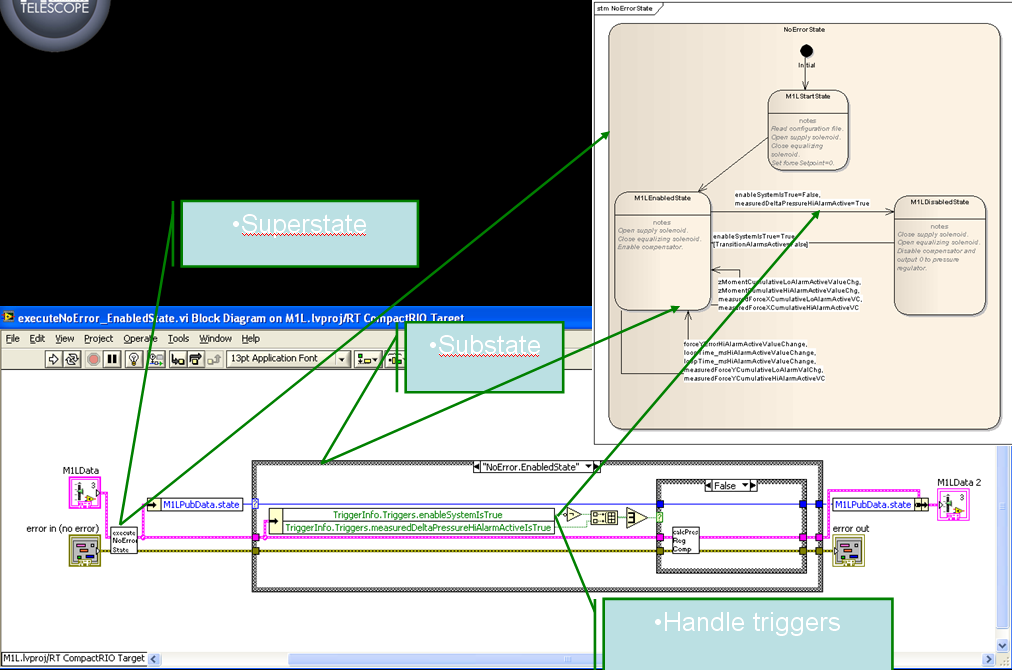
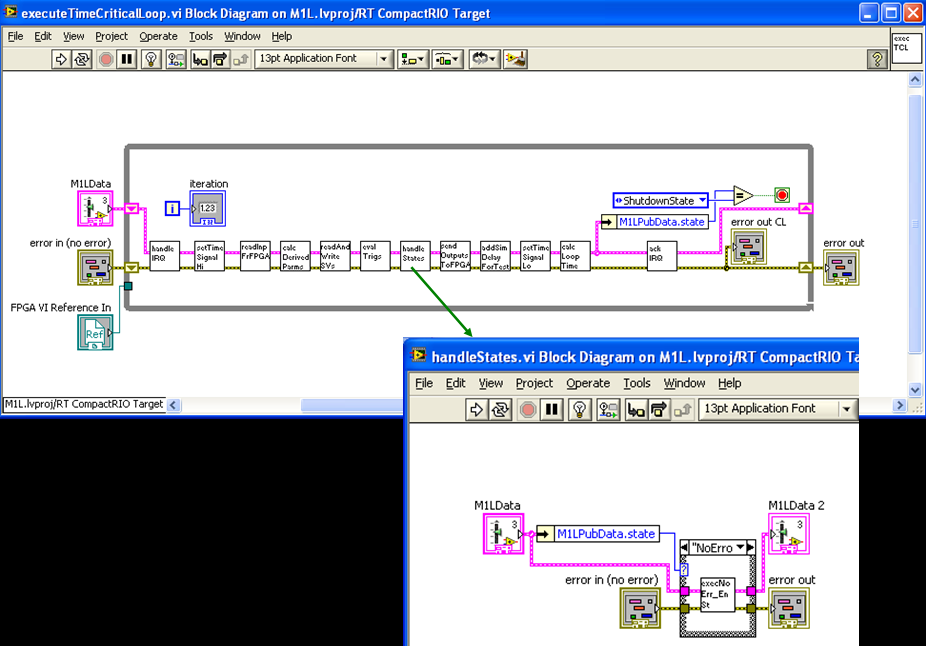
OK, the approach I use is a particular implementation of the State Pattern (OOP, when possible). The example I will show is in RT and hence not OOP (but future implementations on RT will be OOP now that LVOOP works on that platform!). A particular state looks like this: Notes: I pass in the model as a single cluster (would be an object). The model should be separated (independent) from the controller so I think this is the way to go. I create a UML statemachine diagram that shows the states and the transitions. The transitions appear in the code It is easy to handle multiple state levels. (It's even easier--and more flexible--with OO since the states follow a simple inheritance hierarchy.) The layer above looks like this: Note that with an OO implementation I don't need the enumerations or the case structure since the states are themselves objects (and hence we can use dynamic dispatching). Paul

-
Or a shared variable. Make it a network shared variable and now you can run your VIs on separate computers. (Of course if your VIs aren't running in parallel and one is subVI of the other just use wires and connectors! Likely you are considering a more complex case.)
-
Warren, For what you describe an ActiveX Container (or .NET Container) may be a more appopriate method to achieve your goals. Paul
-
Eugen, The other thing I would recommend is that the dynamic VIs (the command handlers) would delegate the tasks to the model (which is a separate class). Then the dynamic VIs wouldn't have any partial model outputs. (It might have the model itself as an input and output.) Keep the Model-View-Controller separation principle in mind. Paul
-
Eugen, You asked, "Should I create a VI for overriding for this Wait On Action VI to use them in my Admin Client Class, but with an othe Action Enum Output?" In a word, yes! You are moving in the direction of implementing the Command Pattern. The Gang of Four Design Patterns Book and other sources cover this well and I highly recommend taking a look at these sources. The Command Pattern is straightforward to implement in LabVIEW and is quite helpful. We use it in our project successfully, even over a network. One note. You are concerned about not having the outputs of your override VIs match. To get around this (and for other design reasons) if you need to output something put the data you need into an object defined in a common class or in the class on the dynamic terminals. (Explore the concept of composition. This is extremely powerful.) Paul
-
Yes, you need some sort of message-passing mechanism if you use different projects, since you are communicating now between two different applications. Networked shared variables (used properly and on a supported platform) offer a good solution for this, but you can also use TCP/IP, UDP, or the like. You might try looking at the Simple Messaging Reference Library (STM) on NI's site. If I faced the same problem (and I do) I would use networked shared variables for this purpose, as they probably offer the most flexible and most easily configurable solution (and with the DSC module we can add logging and alarming functionality). If your applications are on the same machine you can use .NET or a Windows message service, but the former is not very efficient and the latter is quite nontrivial (and both require Windows). You also can use a web server, which is at least platform-independent, but your message timing and delivery reliability will suffer. Will your applications always run on the same computer? What requirements do you have for message timing and delivery? You could also consider building one project's top-level VI into an application (e.g., .exe, .dll) and exposing calls to the other application. Or you can import one project into the other (which it sounds like you have considered) and if you can build only one application you can still use notifiers and semaphores. This can be a very simple solution and will work well as long as your applications run on the same computer (or a desktop and a cRIO or the like). In the current version of LabVIEW you can't add two desktop computers to a project, and you can't use queues and the like over a network anyway. Hopefully I've said everything correctly but my descriptions may not be 100% correct. I suggest using networked shared variables offers the most flexibility and offers one of the best performance options, too. Paul
-
We do exactly what you suggest (essentially an implementation of the Command Pattern), even over a network (flattening the object to strings, which means both senders and receivers must share the same class definitions, of course, so version control is crucial), and it works quite well. I haven't counted the class definitions in our hierarchy but a quick survey shows there are about 100.
-
Do you want to keep the data from the previous run of the application? If not, then you will want to initialize the shift register (with an empty array). Paul
-
You might take a look at this topic: Timer Control. There are quite a few suggestions there. My shared-variable base approach using the Elapsed Time express VI has worked well for me. (I've modified the code somewhat since that post.)
-
read .m file and convert the text into Binary
PaulL replied to engineer09's topic in LabVIEW General
Do you mean by "converts the text into binary" just that the script should be executable? If that is all, then you will want to try your own suggestion. Yes, you can import a script into a MathScript Node. You can run the VI in which the node appears, and you can build a stand-alone executable of the VI. (Of course the script must use methods supported by LabVIEW's MathScript.) -
It is also possible to do a text search for the name of the shared variable to find a specific shared variable. LabVIEW will return matches for the hidden shared variable labels. Actually, the SV label includes the path so including a backslash ('\') before the shared variable name helps to eliminate other unwanted matches. This is not the ideal solution but it works well in many cases.