Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-
It's white. The room was actually fairly dim when I took the picture. The monitor looks so bright because I had to use a fairly long exposure--about 1/6 sec I think.
-
Last month we had a multi-day power outage. Less than 2 minutes after the power returned, I found my daughters doing this... It's a good thing power returned. I was going nuts with all the "When can we go find a hotspot?" whining.

-
90 days start to finish. I wonder how many man-hours.
-
FYI for you guys, once you're comfortable working with LVOOP and ready to move to the next step, Head First Design Patterns is an excellent book for learning how to use OOP to do what you want. (Warning: After reading it you'll want to use patterns everywhere you can. I did and I've seen posts from other hinting at the same thing. That's a great way to learn how to implement the patterns, their pros and cons, and how they apply to LV, but it will add time and complexity to your projects. I'm just sayin...)
-
 Thanks for the shout out and I'm glad you're finding it useful. (My personal belief is the best teaching tool is all the code you throw out when trying to figure out how to do something.) My sense is if the application is already well structured, replacing string-variant messages with LapDog would be fairly straight forward and can be done incrementally. (Though I've never actually tried it.) Where it gets tricky is if the application uses a lot of globals, local variables, control references, and things like that for communication. (I have tried that.) It's really hard to refactor one section without changing a lot of other sections as well.
Thanks for the shout out and I'm glad you're finding it useful. (My personal belief is the best teaching tool is all the code you throw out when trying to figure out how to do something.) My sense is if the application is already well structured, replacing string-variant messages with LapDog would be fairly straight forward and can be done incrementally. (Though I've never actually tried it.) Where it gets tricky is if the application uses a lot of globals, local variables, control references, and things like that for communication. (I have tried that.) It's really hard to refactor one section without changing a lot of other sections as well. -
I'm sure that is true; however, it seems to me that... a) LVOOP will be the faster route only for those developers already experienced in OOD/OOP, and... b) Experienced LVOOP developers will get limited value out of posted examples, while at the same time... c) Inexperienced LVOOP developers will have a hard time understanding the design decisions and associated tradeoffs. For those on the fence about using LVOOP on the CLD, I admit I used it on my CLD exam. (At least I'm pretty sure I did... it was several years ago.) In my case I got a coupon for a free exam so the cost of failure would only be a hit to my pride. I decided to use LVOOP partly to prove to myself I could do it, and partly because my thought process was so deeply OOP oriented I felt like it would be harder to switch back to traditional techniques for the exam. At the end of 4 hours I was not confident my solution would pass. It did, but in retrospect I think it would have been easier had I stuck with traditional techniques.
-
Another battle in the never ending war between safety and flexibility. I agree it is a bit annoying at first, but I also believe it is the right decision for Labview. Actually, I use it as a template, not a parent class. When creating a new slave loop class I copy the template and customize it for the specific task. That's why there are no accessor methods for children. Why not use it as a parent class? Primarily because the parent-child relationship creates a dependency, and I think it's more important to manage/limit dependencies between various application components (lvlibs.) If the parent is in one library and the child is in another, then the library with the child class is dependent on the parent's library. If I want to reuse the child's library in another app I have to drag the parent's library along with it. Also, there are really only 3 methods in the class: Create, Execute, and Destroy. My convention is that Creators are not overridable, since they have to accept all the data that is unique to a specific class. Execute must be overridden by each child class, so there's no opportunity for reuse there either. Destroy can be reused, but there's not much savings in doing it. It takes maybe a minute to write it. In short, there's no benefit to making a SlaveLoop parent class and it requires more effort to manage. I can envision scenarios where it would make sense, but I haven't encountered them in the real world. [still need to respond to your earlier post...]
-
LVOOP and Message Objects (LapDog mainly)
Daklu replied to jbjorlie's topic in Object-Oriented Programming
You can lead a horse to water... (Why would they be too intimidated to read the forum?) It's okay in that there won't be any naming conflicts with LapDog. My personal opinion is the class name should describe what the class is. Typically if I have a plural class name it's because the class is a collection of items. "Messages," to my way of thinking, is a collection class that holds multiple messages. Additionally, your Messages class is just one particular kind of message--a command message. There may be other messages that are not command messages in your application. My preference would be to name the class "CommandMessage." [Edit - I rename classes and methods a lot as the code evolves--it helps keep the code readable.] Nope, at least not the way I think you're thinking about doing it. Since the DequeueMessage method output terminal is a (LapDog) Message class, you'll need to downcast to your CommandMessage class in order to wire it to the Do method. The Message class doesn't have a Do method, so trying to connect CommandMessage.Do will give you a compile error. Downcasting (and upcasting, to a lesser extent) tends to trip people up when learning LVOOP. I know I struggled with it a bit. The key for me was realizing we are downcasting the wire type, not the runtime object. In LV when you create an object, that object will always and forever be an object of that class. It will never be an object of its parent class or child classes. Labview's on-the-fly compiling feature tends to blur the line between edit-time and run-time. LVOOP is a lot easier to understand when you conciously distinguish between the two ideas. They are essentially the same thing. Technically, "Dynamic Dispatching" is what happens during program execution when the LV runtime engine chooses whether to execute the parent vi or child vi. "Overriding" is a more general term that usually means, "create a method in a child class with the same name and conpane as a method in the parent class." It's something the developer does, not the runtime engine. They both refer to using the inheritance feature of OOP. [Edit - I was thinking about this a bit more and decided that statement isn't accurate. "Override" is context dependent... "You should override the CommandMessage.Do method in each CommandMessage child class." "During execution the child class' Do method overrides the parent method on the block diagram." Both are legitimate uses of the word, even though one refers to developer activity and the other refers to runtime activity.] -
Yep. If you read my posts far enough back you'll find I'm not real big on the queued state machine. However, the one place I do recommend using it is for the CLD exam. As much as I cringe at the thought of using QSMs, the exam problems and requirements are set up such that the most direct route to a passing grade is with the QSM.
-
Grr... lost my response in an automatic reboot. It'll take me a couple days to respond.
-
Alex, I'm working on a response but would you mind reposting this in the slave loop thread? It will help when people search for information in the future.
-
Yep, OOP is very much a learn-by-doing skill, not a learn-by-thinking skill. I can't count the number of times I've thought something would work only to discover during implementation that it doesn't quite do what I thought it would. Any chance you can start incorporating it into your every day job? (FYI, I've spent *many* nights and weekends in front of the computer implementing different ideas to see how they worked out.)
-
CLD sample exam organized using LabVIEW classes
Daklu replied to Aristos Queue's topic in Object-Oriented Programming
Amir, remember the goal is to pass the exam, not create a well-designed application. I'm not saying AQ's submission isn't well-designed, but the design is secondary to the functionality. (Incidentally, this is exactly why I resisted so much in the other thread. It's impossible to justify a design based on a bad spec document.) Personally I agree. However, people place different values on the various tradeoffs. AQ tends to favor code that is verifiably correct. He's willing to give up a bit of readability to achieve that. I can't see that either approach is objectively better than the other. They each have their pros and cons. What inherited ATM? The spec doesn't say anything about multiple types of ATMs. I agree it's a natural extension point an alert developer should discuss with the customer, but it's not in the spec and (presumably) isn't going to gain you any points. (The spec does say "Be easily scalable to add more states / features without having to manually update the hierarchy." Unfortunately that's way too vague to be a helpful guideline when making detailed design decisions.) -
Yeah, but come Thanksgiving you're fat and happy while they're having nervous breakdowns. I do it forward. It sorts better and I've never been in the military.
-
LVOOP and Message Objects (LapDog mainly)
Daklu replied to jbjorlie's topic in Object-Oriented Programming
Close. DequeueMessage is a method, not an object, of the Message class. Correct. That gives you a compile error (broken run arrow) because there's no way for the compiler to guarantee the object on the wire during execution will be a LaunchView object. That's what I do when I'm casing out based on message name. I wouldn't say there's a "more correct" way of doing it, but there are "different" ways of doing it, from wrapping the DequeueMessage and downcast in a sub vi to subclassing the MessageQueue class. That's the command pattern and it's easy to implement in LapDog. 1. Create a class called "Command" and make it a child of the Message class. 2. Add a single dynamic dispatch method named "Do." 3. Change your messages to inherit from Command. 4. Add a Do method to each message with the appropriate execution code. You'll still need use the To More Specific Class assertion to downcast the Message wire to a Command wire before connecting to the Command.Do method. If that really bothers you there are various things you can do to hide the downcast from users, from wrapping the DequeueMessage method and downcast in a sub vi to creating a new CommandMessageQueue class. -
Yep, that's a fair assessment of the bare framework. It's intentionally similar to string/variant messaging so people who are not familiar with OOP will not be faced with a steep learning curve. As a developer gets more familiar with LVOOP they can incorporate more complex OO patterns into the messaging system. It's not intended to be a complete messaging system that meets everyone's needs. It's not obvious to those not familiar with OOP, but the power comes from the extensibility of classes and the ability to customize the messaging system for your environment... or even for each project. (All my projects contain custom, application-specific messages in them.) Need to eliminate the possiblity of run-time type mismatch errors? You can do that. Willing to accept the burden of testing for type-mismatch errors in exchange for faster coding and looser coupling? You can do that. Want to protect a queue so there is no chance another developer accidentally releases it in his code? You can do that too. Discover you need to replace a regular queue with a priority queue? Pretty simple to do. And if that doesn't convince you, hey... the reentrant flag is already set for you.
-
Sorry for going off-topic, but I haven't encountered this behavior recently. Which VIPM version/build are you using? Which LapDog.Messaging package version do you have? Does anything show up in the VIPM error log? (c:\ProgramData\JKI\VIPM\error) You might try deleting any LapDog.Messaging packages from VIPM's cache (C:\ProgramData\JKI\VIPM\cache) and then reinstalling the package.
-
This is incorrect. By default no sub vi inlining is done. If multiple loops are attempting to execute the same non-reentrant sub vi, loop 2 will remain blocked until loop 1 finishes that sub vi. Reentrancy is safe as long as you understand a few rules. It might help you understand what is happening if you create a sub vi (Inc.vi) that increments an uninitialized shift register and experiment with that. First, each vi is allocated a data space in memory. A non-reentrant vi has a single data space that gets reused every time it is called. When you put Inc.vi in multiple loops the shift register acts kind of like a global value. Each loop, though independent, increments the same value. That's because all the loops are accessing--and incrementing--a value in the same data space. Using the "shared" reentrancy option means if LV discovers Loop A is blocked waiting for Inc.vi to finish executing in Loop B, it will allocate another data space for a new instance of Inc.vi. You might have 7 loops using Inc.vi, but during execution LV might only require 3 instances of Inc.vi to prevent blocking. Note you cannot associate a specific instance with a particular loop. The natural consequence of this is that you will not be able to predict the value on the shift register for any given Inc.vi execution. Using the "preallocate" reentrancy option does what you originally expected was the default behavior. Every instance of Inc.vi on a block diagram has it's own unique data space in memory. The shift register value will increment only when that sub vi on that block diagram executes. Making the message handling code OO doesn't affect how many instances of the vi are in memory. That is still determined by the vi properties execution options dialog. Reentrant in LV implies multiple instances in memory. "Single memory instance reentrant" in an oxymoron. There are several OO messaging frameworks already published that have been around for years. Before rolling your own you might want to look at them. -Actor Framework -LapDog -JAMA Searching for any of them on LAVA will turn up a bunch of information.
-
That doesn't answer my question. How do you want potential CLDs to benefit from the example? What form does the benefit take? What is the potential CLD supposed to take away from the example? Is the goal to get them to pass the test, or is it to show them how to structure a LVOOP application? The only reason I can think of for posting a minimal (meaning nothing added to accomodate stuff not specifically in the requirements) example LVOOP implementation of the requirements document is to help someone design a solution to the problem. If a potential CLD doesn't know LVOOP well enough to already have a good idea of how to solve the CLD exam problem, they probably shouldn't be using LVOOP in their solution. Traditional LV programming will likely be faster to write and produce simpler source code. Anyone who is knowledgable enough to be using LVOOP on the CLD isn't going to get much value from looking at someone else's minimal implementation since it doesn't reflect reality. If you wanted to use a sample exam as the starting point, scrub the requirements to make them a little more real-world, and build a solution to that I think there could be a lot of value. But a minimal solution to the given requirements... *shrug*... that's just bad design. The intent may be for the CLD to be a code monkey working under an astronaut architect. I know of exactly one place where I think that *might* happen... VI Engineering. (And I only say that because Chris is an architect and I know they have lower level developers writing at least some code.) JKI is stocked with CLA's already. There aren't that many big LV development houses around. I believe most CLDs are in fact creating their own designs with little to no architectural oversight. Giving them examples that reinforce a bad design isn't going to help anyone.
-
It's still not clear to me what the overall goal is. a. To give examples of how to pass the CLD using LVOOP? b. To give examples on how to build an application using LVOOP? c. To compare various LVOOP techniques such as Actors and Observers? d. To compare traditional Labview vs LVOOP? Writing a LVOOP solution strictly to the given spec might be useful if the goal is to show how to pass the CLD, but even then it won't be a good way to illustrate good LVOOP practices. The given spec doesn't have value if the goal is any of the other three items. Funny, but the evidence suggests LVOOP has already succeeded. Furthermore, the implied assertion that "LVOOP must be applicable to all situations for it to be successful" is flawed. Sometimes business priorities take precendence over good software design decisions. The CLD exam scenarios are examples of that... all sorts of good practices are sacrificed for the sake of getting done in 4 hours. A bad application spec is not a good foundation on which to compare different techniques.
-
Fair enough. Personally I find the LVOOP implementation of the strict Car Wash requirements document uninteresting and... mostly pointless I guess. No it isn't. Real world applications projects (I should have said project in my original post) have something the CLD does not--a customer that is going to use the code. Yes, the CLD and real world projects both have a spec and a deliverable. The spec is only useful as a mechanism for communicating the customer's desires. Unless you're willing to spend NASA-like time and money on a spec document, no spec will accurately convey all of those desires. Writing code strictly to satisfy a spec will (imo) lead to an unsatisfied customer. Real world projects with real world customers need to address things like: - Does the requirements document provide solutions to the customer's intended use cases? - How will the software accomodate hardware changes, such as updating obsolete hardware? - What is the testing strategy and does it provide enough coverage? - What happens when the software is installed on multiple platforms with different hardware configurations? - What are the expectations for ongoing sustainability? The CLD spec document is fine for an exam. As a spec for a real world project it leaves a lot to be desired. It doesn't address any of the questions above. In many places the spec document is defining implementation details instead of user requirements. (That's a huge red flag for me.) Many of the requirements just flat out don't make sense from a real-world point of view. "The controller should disable the Wash Options buttons [when the Start button is pressed.]" No it shouldn't. The car wash controller is a business component, not a UI component. It shouldn't know anything about Wash Options buttons. On top of that, in the real world mechanical buttons often can't be disabled. Disabling a button on the simulated entry console as a way to control inputs to the car wash controller opens a huge hole for bugs when the simulated input panel is replaced with real world hardware. Not only is that requirement defining an implementation, it's defining a particularly bad implementation. "The controller should check if the vehicle is at the appropriate stations for the first step in the selected wash type by monitoring the Car Position Slider." This has the same problem of not separating the business logic and user interface as above. It also makes the slider problem I mentioned in my first post a *requirement* of the application. How are we going to test how the controller handles sensor failures? Obviously the "customer" hasn't even considered the possiblity of a sensor failure. That's another huge hole for bugs when the controller is deployed on a real system. The document is littered with requirements like that. It's fine for a timed exam, but it has far too many flaws and unanswered questions to be the basis for a real-world project. Without a customer to discuss these issues with, my real-world solution for this example would include many things that are not in the spec document because they are the better long-term decision. Those things take time to design and implement, but pay off down the road. With the exam there is no "down the road," so it ends up looking like pointless overhead. [Note: I'm pretty sure there are at least two versions of the Car Wash sample example floating around. Broadly speaking they are the same but I believe there are significant differences in the requirements.]
-
Just curious... are you looking for a sample CLD solution, or a sample real-world application based on the requirements of a sample exam? They have different requirements and will result in different source code. (For me anyway.) For example, the car wash example uses a slider to indicate the car position. That is complete inadequate for building a real world system. In the real world the sensors are independent of each other; you can have multiple sensors signalling the presense of a car, or you can have no sensors signalling the presense of a car. With the slider, one sensor--and only one sensor--is always signalling the presense of a car. Given the time constraints of the exam I'm going to take every shortcut I can and use the slider. If a customer gave me that requirement document I'd point out the flaw and encourage a better solution, like checkboxes for each sensor.
-
Dynamic SubVI Questions
Daklu replied to theoneandonlyjim's topic in Application Design & Architecture
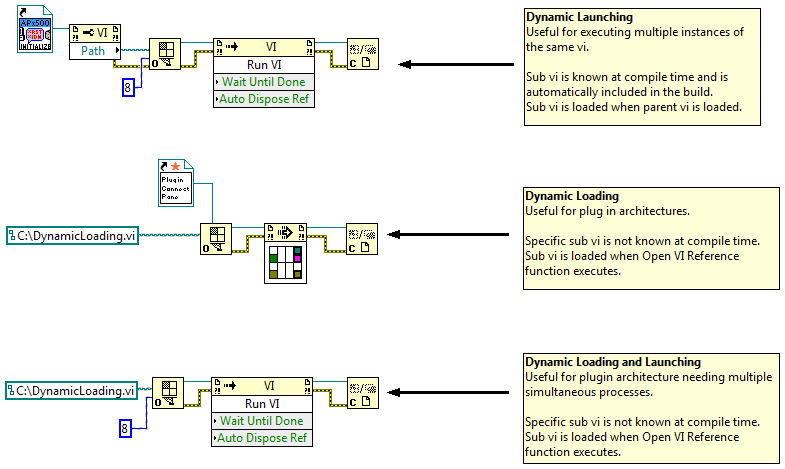
First, as far as I know the main use cases for using traditional "dynamic sub vis" are: 1. The application allows plug-ins that will be created after the main application is compiled. (Dynamic loading.) 2. You want to improve the application start up time. (Dynamic loading.) 3. You want to start an unknown number of identical processes. (Dynamic launching.) If one of those three isn't your goal you might want to rethink using dynamic vis. IMO it will add unhelpful complexity to your project. (There may be other non-oop reasons for using dynamics I haven't mentioned.) "Regular" sub vis on a block diagram are loaded when the parent vi is loaded. I'm going from memory here and haven't tested it all thoroughly, but here's my understanding: It depends on whether you are using dynamic loading or dynamic launching. Here's an example of the difference: The top example has a static reference to the vi that is going to be executed. Since LV "knows" which sub vi is going to be used, you don't need to specifically include it in the build and the sub vi is loaded when the application starts. The middle example does not have a static reference to the vi that will be executed. The reference shown is for a vi that *only* defines the connector pane. (No BD code.) All plugins will need to use the same connector pane pattern. The vi located at that path (if one is there) is loaded when the Open VI Reference function executes. If you have vi's in your project you are loading using this method, you'll need to "always include" then in your build. (It kind of defeats the point of having a plugin though.) The last example is a hybrid of the two. Yep, especially if you're using dynamic loading to load vis already built into your executable. If the sub vi is going to be included in my build anyway I use a Static VI Reference and avoid all the management headaches.
-
Re-Designing Multi-Instrument, Multi-UI Executable
Daklu replied to jbjorlie's topic in Application Design & Architecture
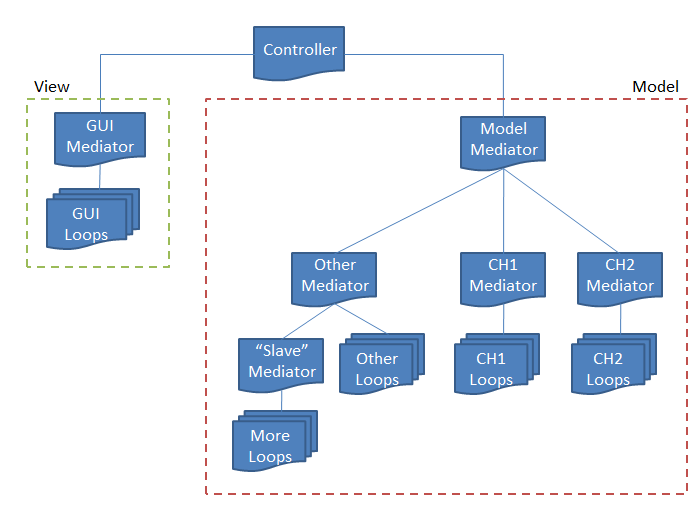
Close. What you show is more of a mixed model. A strict hierarchical messaging topology looks more like this. (I don't know what those symbols mean in a flowcharts, but here it just represents one "thing" and multiple "things.") A couple things to note: 1. The "things" on the diagram do not represent individual vis or even classes; they are loops. IMO loops are the fundamental unit of execution. 2. The hierarchy represents "is responsible for," not "is dependent on." A vi containing a sub loop may or may not be on the block diagram of the mediator vi. I think it's easier to start with the responsibility tree matching the dependency tree, but it is not a requirement. 3. The purpose of a mediator loop is strictly message routing. They don't do any file IO, VISA commands, etc. This helps prevent message queues from getting clogged. 4. The messages the mediator loop accepts from and sends to "higher" loops define the public api for all the functionality below it. Mediator loops also handle message routing between its immediate sub loops. (i.e. Messages always go up or down; they don't go sideways.) 5. The diagram shows the controller being responsible for the UI and Model components. In truth any of them can be responsible for the other two--it just depends on your goals. It's probably most common to use the UI as the root. There's a lot of other little bits of information rattling around in my head... I'd better stop there lest I get too long winded. This is just my opinion, but the model should be self sufficient except where user interaction is required. I'd definitely put temperature monitoring and automatic shutdowns in the model.
-
If by "plug-in" file reader you mean, "I can drop it anywhere and it will read the ini file," then yes, you could do that. (Though typically you'd only want to read the ini file once and just keep the settings in memory.) If you mean "I can use it as a generic sub vi to read an arbitrary ini file," then no, you cannot. You'll have to create a unique copy for each ini file. What I often do is wrap my constants in a vi and give it a really obvious name, like "_CONST_ConfigurationKeys.vi." That makes it really easy to find in the project. If I also want to store the default values I might have a second string array output terminal for the default values. You could use a 2d array as well. Then all the ini file keys and default values are stored on the block diagram of an easy to find vi, and that's *all* that's on the block diagram. Makes maintenance pretty easy. Glad you like it. Keeping it simple has been one of my primary goals. That brings the total number of LapDog.Messaging users up to... 3.