Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-

Futures - An alternative to synchronous messaging
Daklu replied to Daklu's topic in Object-Oriented Programming
I think I need to spend time revisiting your dispatcher in the CR. It looks like your messages include destination information that allows the dispatcher to read and route the message appropriately? That certainly allows you to write a generic dispatcher, but I still don't see how you manage to customize a particular message's destination for each application. There needs to be glue code somewhere. Nevertheless, I'll put off further questions until review your dispatcher code. I don't either, but in this app the UI very clearly has different display states so I went ahead and refactored it into a state machine. Same for me. The difference is while my UI controller is logically separated from my UI front panels, it is not necessarily physically separated from them. Often the UI controller is implemented on the same block diagram as the UI. However, the UI controller loop only interacts with front panel controls via messages to/from the other UI loops. I guess I don't understand the benefit of physically separating the code doing the low level UI display control from the display itself. Maybe if you reuse the same display in different applications... This seems... peculiar? The notion of directly updating a display over TCPIP conflicts with how I define the responsibilities of components. For example, the networked component would send event messages to the UI controller (or AppController if there is one) like "OvenSetpointChanged." It's up to the UI/App controller to decide how to respond to the event. Messaged Futures aren't intended to be a replacement for an asynchronous messaging system. They are an alternative to synchronous messages when you don't want your message handling loop to block. I agree there is a lot of potential to shoot yourself in the foot if overused. This comment reenforces my thought that we use fundamentally different messaging paradigms. Getting a status value implies query/response messages. I develop using request/event messages. In my apps the UI rarely needs to ask for a status value as it would be automatically notified when it changed. I find it much easier to keep my components decoupled this way. I would say the "real value" of Futures is in the abstract concept. It's the idea of creating and holding an object that doesn't have the value you need yet, but it will sometime in the future. How you use it to solve a specific problem is something different and unique to each developer/project. I've decided to call what I've shown in this example a "messaged Future" (as in "a Future sent via messaging") in an attempt to separate the idea from the implementation. I did think about that while writing my solution. Unless I'm misunderstanding you this is an extension of normal query/response messaging patterns. There are organizational advantages (or disadvantages, depending on one's preferences) to using a helper actor in that it physically separates the code responsible for receiving the responses from the Consumer (or Requestor.) Other than that you still have to write all the same functional code that you would if you had the Consumer collecting the responses and Futures become unnecessary. (Unless, as you pointed out, there was some metadata associated with the responses that couldn't be retained in the response itself or reasonably communicated to to the the helper via a message.) If you're already using an asynchronous query/response messaging paradigm there is probably limited value in messaging Futures. An event-based messaging system occasionally benefits from query/response style messages, and messaging Futures is a way to get the functional equivalent without implementing query/response logic, in certain situations. -
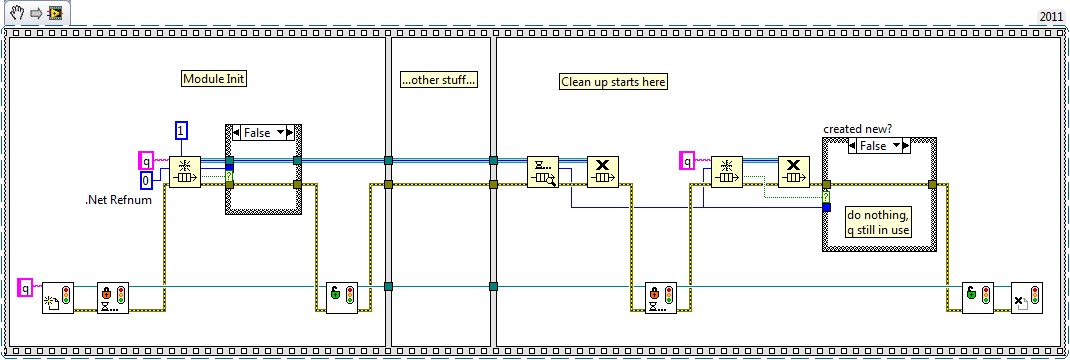
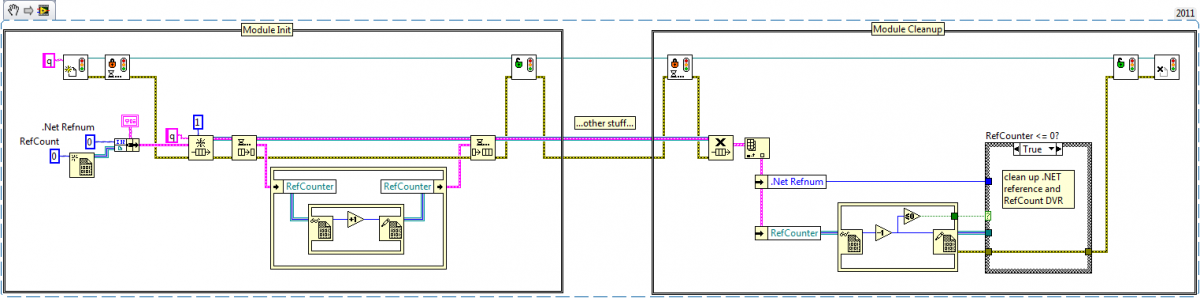
I believe this is intentional behavior in asbo's code. During initialization each module checks to see if the .Net reference exists. If it does not, the module creates it. Presumably persisting the .Net refnum when no modules need it isn't necessary. I can imagine situations where one might choose to use that strategy. Maybe a db connection or some other resource bottleneck. I am curious what kind of data this .Net refnum represents... The fundamental problem causing the race conditions is the test for clean up and the clean up itself is not an atomic operation. There's always the chance Module 2 will do something--after Module 1 tests for cleanup but before the cleanup is performed--that will make the test results invalid. Depending on the circumstances and implementation you'll end up with either a memory leak or dangling reference. Here are some snippets illustrating the race conditions. The first is asbo's code showing a how a memory leak can occur and the second is my code showing how a dangling reference can occur. Asbo's code could also have a dangling reference if Module 2 was initialized between Module 1's test and cleanup. I don't think it's possible for my code to end up with a memory leak, but I'm not certain about that. You need some way to make sure other Modules don't invalidate the cleanup test before the cleanup is performed. They can't be allowed to increment or decrement the RefCounter (whether explicit or implied.) You can use a semaphore like in my example above or wrap the Init and Cleanup processes in an action engine. I'm pretty sure it's possible to add a semaphore to asbo's code and avoid an explicit RefCounter, but I haven't thoroughly analyzed that. As near as I can tell you can't avoid race conditions using only unwrapped queue prims.

-
I'm fairly certain that restriction applies to decompiling Labview's source code, not source code written using Labview. On top of that, in the US I *believe* courts have found certain exceptions to those limitations. Reverse engineering for compatibility or debugging is permitted. How much extra "stuff" is injected into a VI's compiled code to facilitate LV's shared multi-tasking engine? The Labview Compiler document mentions a "YieldIfNeeded" node. Is that pretty much it or is there more?
-
I think this gets rid of the race conditions.
-
The example you posted does have a race condition, but I don't think this does. [Edit - I was wrong, it does. This race condition manifests as a dangling DVR rather than a memory leak. At least a dangling DVR can be detected and you can recreate it in the rare case it happens.] However, personally I think your code structure requires the module to know information it shouldn't care about. Namely, it has to know if any other modules are still using the .Net object. I think creating the queue one time in external code and injecting it into the module when it is created/initialized is a much cleaner solution. Then the module just uses it as a resource and doesn't have to worry about clean up--that's handled by the calling code. [Edit - Having just seen your explanation about modules dropping in and out at any time, I understand why you are making each module responsible for obtaining and releasing the queue.] Shaun's method will work. All the queue refs are not released--one persists until Destroy is called. But it doesn't solve your problem of requiring the module to know if everyone is done with the queue. It would still need a RefCounter or a single Destroy placed in the calling code when all the modules are done executing.
-
Thanks for the info Shaun and asbo. I'll try to track it down later when I have more time or get tired of dealing with it. Yep, I can still browse to the correct variables. Erm... sort of. The customer wanted a quick-and-dirty app to test and characterize a system they're building. I don't have much experience (or infrastructure code) with cRIO so I copied an existing project and heavily modified it. But yes, the entire project was copied to another pc using a usb stick. Given the info from Shaun and asbo, I don't think it is. I have seen broken scan engine variables when the "no disk" error didn't appear. ---------------------------- Another question regarding shared variables: Are shared variables dynamically namespaced? I ask because something else occurred a while back I did not expect. The shared variable library is located under the RT target. While working on the host app I noticed the shared variable library was showing up in dependencies, like how a vi used in the host app and RT app will show up under both targets. I moved the shared variable library from the dependencies and grouped it with the rest of my host app source code for convenience. That didn't work so well. Later on I discovered the variable YC-301 dragged from the pc target is not the same as YC-301 dragged from the cRIO target. (As an aside, even though I am using the shared variables in the host app the shared variable library no longer shows up in the pc target dependencies. I have no idea why it was there in the first place or why it isn't there anymore.)
-
Sure, and there may even be multiple right ways, but knowing whether a solution is right or not depends on a whole host of application and business requirements that are not specified in the example. I run into this problem any time I use examples to learn a new api or software technology. Sometimes I can easily see how to correctly apply the example to my project; other times I can't. Perhaps a better way to phrase my request is: Include comments explaining why a particular implementation is used, where it is applicable (and not applicable,) and what the tradeoffs are versus other solutions. That's a tall order and complete documentation could probably fill a book, but I hope there is at least an attempt to include that information. My favorite is when I'm starting to pull into a parking space and my wife will say, "there's a spot over there." She doesn't do it anymore--we've been married 20 years--but the first 10 years or so she would do that all the time. Now we joke about it. Another one she used to do is tell me how to load the dishwasher. She learned when she gets too critical of how I do things I quit doing them. Her solution was to stop telling me how to do it and just rearrange the dishes after I'm done.
-
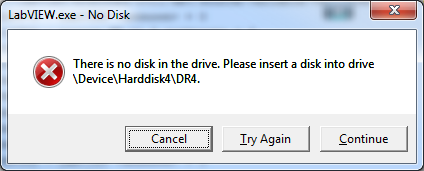
I have a cRIO project that uses shared variables to transfer fp control states to the RT engine. The shared variable library is located under the RT target. Whenever I transfer the project source code to a different computer the shared variables used in the UI Main (under My Computer target) break, and I get errors stating the shared variables are not linked. I suspect I'm misusing them somehow. Can anyone explain this behavior? [Edit - The broken variables are actually digital I/O signals exposed via NI's Scan Engine. They are all related to one specific module; none of the other modules have this problem. I think these are the only Scan Engine variables that are used in the UI. Are Scan Engine variables supposed to be used only on the RT target? Is it "bad" to use them on a pc target?] ----------------- I don't think this is directly related to what's happening above, but when opening UI Main I get this unusual error: I've never seen this before. Cancelling lets the vi open normally (albeit broken due to the previous problem.) I'm guessing it's because I didn't set up a cRIO through NI Max on this pc?
-
Mark's thread here and recent crashes when starting Labview got me wondering about the viability of using Windows debuggers like WinDbg for analyzing executables built from G source. Has anyone tried this? I've never even looked at disassembled code from a G exe. I have no idea how similar it is to disassembled c/c++ code. Apparently debug symbols don't exist in G (which I don't understand.) That might make it harder to figure out how to map our app code to specific assembly instruction patterns, but again I don't really know. I really have very little experience using Windows debuggers, but they are powerful tools and freely available. Does it make sense to use them or does the way LV distribute code chunks to threads make it not worth the trouble?
-
Do we have to wait until we see it to give feedback? One thing I *hope* it does is identify what lessons people should take from the example. There appears to be a common perception that examples show the "right" way to do a particular task instead of "a" way to do the task.
-
Futures - An alternative to synchronous messaging
Daklu replied to Daklu's topic in Object-Oriented Programming
I agree if you want blocking behavior a notifier is a better option. I'm a little gun shy about blocking on one-off notifiers like that. If for some reason the notifier is never filled the blocked code will never release. In general I prefer to implement a solution that lets the redeem operation fail if the Future hasn't been filled. The process can be retried if necessary. Failing in TransformData is no big deal; I'd just trap the error in the message handler and discard it. In certain situations I'd probably even choose polling over blocking. (Blasphemy!) Blocking is clearly an easier implementation though, so in simple applications that can easily be verified for correctness I might go with a blocking notifier. -
Can you correlate the memory leak with any particular application activity? Is the growth rate the same when the app is doing nothing vs when it is engaged in an activity? One thing that might be useful is Dr. Damien's WinDbg logging vi. He told me about it at the summit and I have found it extremely useful for grabbing quick debug logs from executables. I believe it is in his nuggets thread but I don't recall exactly. (Every so often someone posts about an unusual problem they're having with an app using a user-event based messaging system. I won't claim anyone is wrong for using it, but I honestly don't understand its appeal. Compared to a queue based messaging system it is less flexible, less capable, and less transparent. Even if this leak isn't related to user events at the very least a queue based system would let you eliminate that as a source of errors. Is it that user events support built-in dynamic registration/unregistration and queues do not?) Smart. I hadn't thought of that.
-
Fair enough. I know I spent some time looking for it too. I've since decided it doesn't exist and have instead focused on developing practices that facilitate easy refactoring as requirements change.
-
Futures - An alternative to synchronous messaging
Daklu replied to Daklu's topic in Object-Oriented Programming
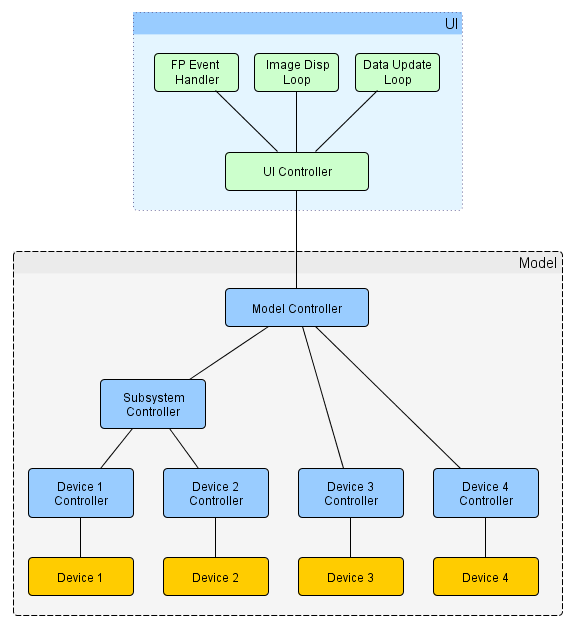
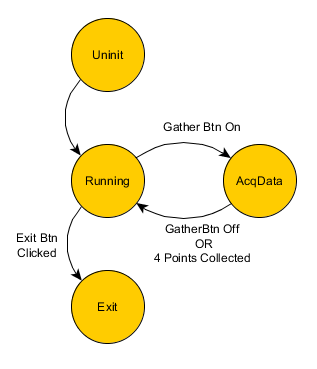
Yeah, coordinating the UI's state (which may or may not be implemented as a state machine) with the Model's state while keeping them lightly coupled is a tricky problem. I think this is the first app where I've implemented the UI as a state machine instead of just as a straight message handler. While implementing the example solution I discovered a behavior that could be a problem in certain situations. If you click the Set Pt button four times quickly then immediately click the Gather Data button, you'll get an Unhandled Message error from the UI for the debug message returning the four transformed values from the Model. Unhandled messages are intentional in my state machine implementations. Any message a state shouldn't react to is unhandled. But if for some reason that return message were necessary for the application to work right that state machine implementation starts to break down and begins requiring duplicate code. (Identical message handlers in different states.) There are ways to eliminate duplicate message handlers. Often I'll encapsulate each state as a class with an EntryAction, ExitAction, and MessageHandler methods. The base class implements message handlers for message that should always be handled. Child classes (the states) implement message handlers with a Default case that call the parent class' message handler. That's not a perfect solution either; it works if your states' behavior can be organized as a tree structure, which isn't always true. I've toyed with the idea of creating a separate MessageHandler class structure and injecting the correct MessageHandler object into the state at runtime. Of course, this all adds a lot of complexity and is far beyond what I wanted to illustrate with the example code. In any event, the debug message wasn't important in the context of this example so I choose to call it "expected behavior" instead of "bug." Not really. My original post was just to share a neat concept I had run across and used. Now I'm trying to gain a deeper understanding of the applicability of Message Futures. Are they a "good design idea" or simply an "acceptable temporary solution" to a design that is starting to crack around the edges? Originally I thought "good design idea." The recent discussion is pushing me toward "acceptable temporary solution." Aye. Imprecise terminology has got to be the single biggest problem in software engineering. (At least it is for me.) It doesn't help that I'm not very consistent with my terminology, even in this thread. (It's so much easier in mechanical engineering. A gear is a gear whether I'm in Arkansas or Argentina. I don't have to abstract it into "rotational load transfer device" and figure what it looks like in a universe with different laws of physics.) I don't consider my applications as having an MVC architecture, but that's the closest representation most people are familiar with so I try to accomodate it. Usually they are more of a Model-Mediator/Controller-UI. At the highest level, the Mediator/Controller is the glue code between the UI and the Model. In general I try to write my Model so I could use it as is in an application with similar functionality. It does not necessarily include all the non-UI logic and data the system requires. The difference between a Mediator and Controller is a Mediator's primary responsibility is to translate messages so the UI and Model can talk to each other. It's more of a facilitator. (i.e. A "BtnClicked" message from the UI means I need to send a "DoThis" message to the Model.) A Controller does that as well, but it exerts more direct control and manages higher level states that cannot be completely described in the UI or Model by themselves. There is a lot of fuzziness surrounding the two ideas--I just wave my hands and say when a Mediator starts tracking state information to filter messages or change message handlers it becomes a Controller. As near as I can tell my high level Mediator/Controller (or "Application Controller") largely fills the same role as your Dispatcher. To add to linguistic confusion, I also use the term Controller for any functional component that manages a subsystem, whether it is a single device or several devices. Each controller has to be written specifically for the subsystems it manages, but most controllers also expose a public messaging api to allow external systems to interface with it. (AppControllers don't typically expose a public api, but the option is there for when I need it.) (Your message naming convention reveals possible differences between our design philosophies. Having a device controller accept a "MoveBtnClick" message and send a "DisplayPosition" message indicate the device controller has knowledge of the how the device is being used in the application. The message phrasing implies the device controller is responsible adapting to meet the dispatcher's api rather than the other way around. My controller components encapsulate higher level behavior for the calling component, but their messaging interfaces remain agnostic of the code using the controller. The messages between the device controller and dispatcher would have names like "MoveToPosition" and "PositionUpdated.") Here's a diagram somewhat representative of the current communication map after various evolutions and refactorings. You can see there's no dedicated AppController. The UI Controller has filled that role so far, and while the design is not ideal it has been sufficient. That's the $100 question. Below is a state diagram for the example problem's UI display states. Using query/response async messages requires recognizing the trivial "user has sent four data points to be transformed but the Model hasn't finished them yet" state. Where should that new state go? Conceptually it doesn't fit with the UI state machine very well and I can't think of a suitable set of transition conditions that would give me the desired behavior without making everything a lot more complicated. I could have the Model store the transformed data points and avoid the asynchronous problem entirely. In fact early implementations did just that. I switched responsibility for maintaining the transformed data points to the UI because it feels like that's where it should be. The Model doesn't care about each point individually; it only cares about the complete set of points. That leaves me with the options of using a Future or refactoring to implement an AppController/Dispatcher. Okay, this needs clarification. What do you mean by "can be brought directly into other apps?" Do you just mean each of those has no static dependencies on other code? Or are you saying they are generic enough you can pull them in and use them without editing their source code and messaging api? I can see how certain components could be easily reused as-is, such as device 1/2 and the TCPIP module, but I don't see how you avoid having app-specific code in your device controllers or dispatcher. The thing I thought was unusual about your architecture is the device controllers sit betweeen the device and dispatcher as I'd expect, but the UI and TCPIP controllers do not. Maybe I'm missing something fundamental about what you are doing? I agree there has to be logic, state, and sequencing somewhere, but I'm having a hard time understanding the rest. Can you explain what you mean by "they can sometimes be all of the diagrams you depicted earlier?" Do you mean a Future could be a synch message, asynch query/response message, or a fire-and-forget message?
-
Futures - An alternative to synchronous messaging
Daklu replied to Daklu's topic in Object-Oriented Programming
Two questions: 1. I assume by "dispatcher" you mean inserting an abstraction layer between the UI and the Model? 2. Do you mean easier than the solution I used given the conditions, or easier if I could only change UI code? I'm fairly certain I'll eventually have to insert another abstraction between the UI and Model. Often I have a Controller component coordinating information between the UI and Model. This project evolved in a way that left the Model with no public representation of individual states. As far as the UI was concerned the Model was a simple message handler rather than a state machine. (Though some Model subcomponents are implemented as state machines and this is known to other subcomponents.) All the application states the user is aware of are implemented in UI code, because they represent changes in UI behavior. Inserting a Controller layer just to manage the UI pseudostate between "last TranformData message sent" and "last DataTransformed message received" seems like overkill. I know complex refactorings often have to start by adding code that looks out of place or makes the code harder to follow. This project is at the point where development could stop for years after each new release, but no feature list for the release is comprehensive enough to justify doing the entire refactoring in one fell swoop. I'm reluctant to start a refactoring process that I'm not sure I'll be able to finish before putting the source code on the shelf. It's probably psychological weakness on my part... -
Sure, if you can manage to get the IDE to load the code in the first place. There was this one time I was trying to work on a 3 GB assembly source code file...
-
Futures - An alternative to synchronous messaging
Daklu replied to Daklu's topic in Object-Oriented Programming
Here's my Futures solution to the problem code given above. The changes required are pretty minimal I think... especially when compared to any other solution I can think of. I'm still interested in seeing other people's ideas if they're willing to share. A couple notes: - This solution changes the Model interface. Specifically, it changes the payload of the TransformData and DoCalc messages. If Model were a shared component or service, obviously this would cause problems. I haven't thought at all about what the implementation would look like if the Model had to support Futures without breaking backwards compatibility. - I'm really curious what a solution would look like if changes were restricted to UserInterface.lvlib. The problem given in the example code feels like a UI issue, so I'd think it would be solvable by changing UI code. The reliance on asynchronous messages leads me to think I need to better separate the UI's display state from the UI's behavioral state for that to be applicable in the general case. Hmm... I'll have to think about that for a while. Asynch Messaging Solution - Daklu.zip -
My opinion is I am completely unqualified to make any kind of assertion as to the cause of the slowdown. I don't have sufficient knowledge of how Labview is implemented under the hood. I personally don't believe it is entirely related to using LVOOP. As I recall, the one project I worked on many years ago that had the most problems with IDE slowdowns didn't use LVOOP. It was developed using procedural methods and implemented as a QSM. I believe the slowdown is mostly related to the user's source code. To expand a bit on my earlier post, I disagree with mje's argument that the ability to prevent IDE delays using good architectures is "irrelevant because you can't always force such practice into a project." It essentially makes NI solely responsible to fix or prevent problems created by the end user's software implementation. NI is limited in the problems it can "fix" with LV source code changes by finite computing resources and their desired user experience. I don't think it is fair to burden NI with the task of making sure the IDE remains snappy in all situations regardless of the source code we are working on. (And I suspect the restrictions placed on developers to ensure IDE responsiveness would be met with howls of outrage.) To my eyes the issue of IDE responsiveness is mainly one of knowledge. There are one or more constraints of some sort being violated that is causing the IDE delays. Obviously some of those constraints are not widely known to developers, and they may not be known to NI. When the constraints are not known we cannot design around them, and we end up frustrated by IDE delays that appear with no apparent cause. On the other hand, we develop code within known constraints all the time without demanding fixes from NI. Most developers understand and accept there will be IDE issues in the case of very large VIs like Rolf described. That limitation is a natural consequence of a user experience requiring on-the-fly code compiling. We may not like the delay, but we accept it as being a result of poorly written code, not a flawed IDE. I agree it is in NI's responsibility to understand the constraints and communicate to us those we are violating when we experience IDE delays. If the constraint is caused by a bug they can fix, great! If it's because we are unintentionally placing unreasonable expectations on the IDE, then it's up to us to adopt practices to work within the constraints (or move to another platform without those constraints.)
-
Futures - An alternative to synchronous messaging
Daklu replied to Daklu's topic in Object-Oriented Programming
The implementation of Futures I used in my project would not help you. It's a fairly unique set of circumstances that makes it work in my original project. Namely, the actor setting the Future's value is also the actor that eventually reads the Future. Using normal asynchronous messages this would be like making 1.5 round trips between the two actors instead of just a single round trip: Async Message Sequence: 1. UI sends the untransformed data to the Model. 2. Model transforms the data and returns it to the UI. 3. UI stores all transformed data until it has enough, then sends all transformed data back to the Model. Equivalent Future-based Sequence: 1. UI creates a DVR (Future) and sends the untransformed data and a copy of the DVR to the Model. 2. Model transforms the data and puts it in the DVR. 3. UI stores all created DVRs until it has enough, then sends them all to the Model. Because the Future is being set and read by the same thread, I can guarantee the Futures have valid data before being read by sending messages to the Model in the correct sequence. On the other hand, if the UI were reading the Futures (a single round trip), the Model would still need some way to notify the UI the Future is set, which mostly defeats the whole thing in the first place. (It can still work if you're willing to fail the operation requiring the Future or block execution until the Future is set.) My Socratic question to you is, why does the DAQ loop care whether or not the FTP transfer was successful? -
My impression is the edit-time slow downs are more tied to the desired user experience rather than Labview's source code design decisions. I can't speak with authority though... it's just my impression. In theory we could give up instantly recompiled vis and a host of conveniences in exchange for snappier editing regardless of source code size or structure. There have been many times when I was ready to do just that. Still, I doubt NI is willing to make that trade off.
-
Futures - An alternative to synchronous messaging
Daklu replied to Daklu's topic in Object-Oriented Programming
Having confidence your code will behave correctly is a perfectly valid reason to favor direct thread control even if there is no performance benefit. (I doubt it will be enough to convince NI to expose more direct thread control to users, but maybe you can get them to implement a super-secret "rolf" ini switch for you.) Only to return the poke. Feel free to ask questions if you don't understand something. The only dynamic dispatching is related to the messaging framework, which fundamentally behaves very similarily to normal string/variant messaging. I suspect you won't have too much trouble with the OO nature of the app, though you might have questions about some of the application framework code. -
I tend to agree with this. In the past I have experienced the editing delay mje mentioned; however, it hasn't been an issue for me for quite some time. I like to think it because my coding has gotten better.
-
Futures - An alternative to synchronous messaging
Daklu replied to Daklu's topic in Object-Oriented Programming
For kicks and grins I mocked up a simplified project (Async Messaging Problem.zip) with all the major elements related to the problem I was faced with. It contains an implementation using asynchronous query-response messaging and explains the flaw in that design. The task is to fix the flaw. I'll post my solution using Futures soon. I'd be interested in seeing how others fix the problem. Notes: * The top level vi is located in User Interface >> UserInterface.lvlib >> Main.vi * Code is written in LV2009. I use LapDog for the messaging, but this project has a private copy so you don't need to install the package. * It does not have extensive documentation describing how the application works. There is a fair bit of application framework code required to implement the design. I hope between the documentation that is there and stepping through the code it will be easy enough to understand. In particular, the UI State Machine is implemented using a less-well-known design. (Mostly it's just known by me.) * The sections that will most likely need changing are explicitly identified. In LV we have queues, notifiers, etc. for exchanging information between parallel threads. Does Java have something similar? Yeah, but the 21 threads available in Labview's thread pool still exceeds the number of simultaneous threads most processors can run. Doesn't an Intel processor with Hyperthreading essentially support two threads per core? That's only 8 threads total on a quad core processor. What advantages would you get by increasing the size of LV's thread pool and managing threads directly instead of letting LV's scheduler take care of it for you? Is it mainly for when you need to squeeze the last drop of performance out of a machine? My cookies defy poking. If you are missing anything I'd guess it's that I wasn't starting with a clean slate. I had to fit the changes into existing code. To be honest I'm having a hard time visualizing what your proposed solution would look like in my project. If you have time would you mind trying to implement it in the attached project? ------------ Edit - My solution is posted here. Async Messaging Problem.zip -
I know the "Delegation Pattern" has been mentioned in some early versions of OO pattern documentation on NI's website. In my opinion it is more of a strategy or technique than a pattern. Delegation just means having some other class or component do the work. Patterns give class structures (sometimes with minor variations) to solve fairly specific problems. Delegation is far too broad a topic to be contained in a pattern. The Best Practices link illustrates the problem. Compare the "Single Inheritance with Delegation" diagram with the "Cat" diagram in the structure section. The class structures are substantially different and there is no explanation as to why they are different. The Cat diagram is an example of dependency injection. (I do this all the time and it is hugely beneficial for unit testing.) I'm not quite sure what to make of the "Single Inheritance..." example. It doesn't work as a general replacement to multiple inheritance like the text implies, though it might be adequate for specific situations. Yes, both examples use delegation to achieve their results, but neither adequately defines delegation. This is really the comment that prompted me to respond before I got sidetracked on the response above. Delegating to a composed class is probably the most common way it is used, but I don't think it is necessarily a "key idea" of delegation. There are lots of ways to ask another class to perform a task without using a direct method call.