Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-

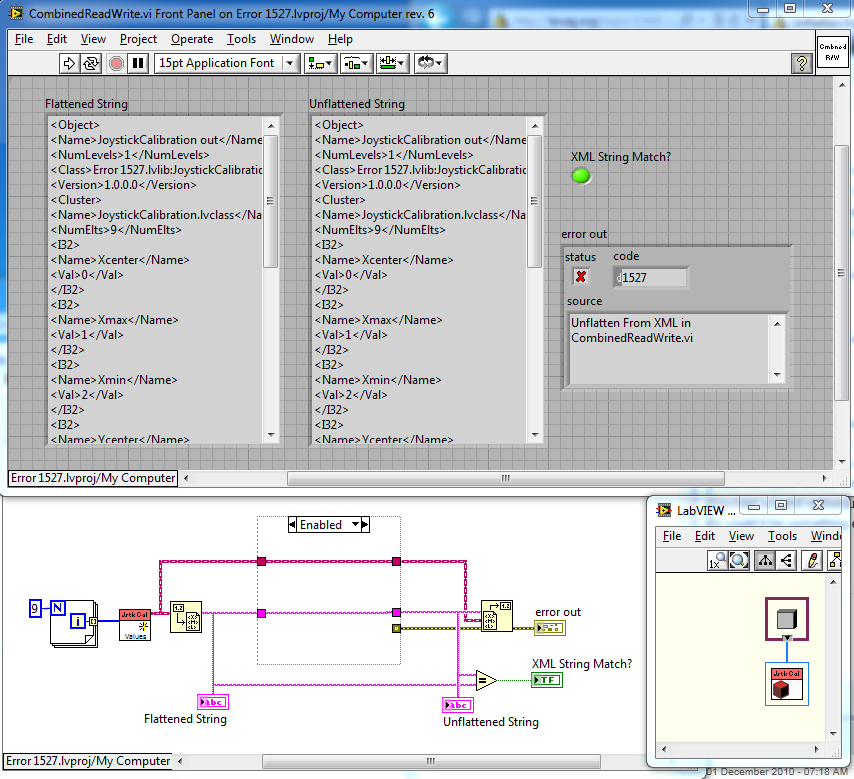
Unflatten From String on Class - Error 1527
Daklu replied to jgcode's topic in Object-Oriented Programming
Yes, when not in the library it works fine. (It also works in 2010.) One of your earlier posts indicated you had it working in 9.0.1 even though it was in a project library... or did I misinterpret that? I still don't trust auto mutation enough to commit to binary strings. At least with xml the data is readable and relatively easy to recover should anything bad happen. My solution is to transfer the relevant class fields to a cluster and flatten that to xml. Kind of pain, but safer than auto mutation. -
Wow... that's quite an interruption.
-
Unflatten From String on Class - Error 1527
Daklu replied to jgcode's topic in Object-Oriented Programming
I've now run into this same problem using Labview 2009 sp1. Can anyone tell me why this code generates an error? Error 1527.zip
-
Pseudocode is too close to implementation for it to be much value to me. I'll do pseudocode in text languages when I'm trying to figure out how to implement an algorithm. In Labview I'm usually working at a higher level than specific algorithms. It's fine for single threaded apps, but I haven't had much luck modelling multi-threaded applications with it. Like Felix I'll sketch out state diagrams or flow chart-ish diagrams during design to clarify my thoughts.
-
Meaning it's 75 deg and sunny instead of 95 deg and sunny? Quick! Somebody call the wahhhmbulance.
-
Well, seeing as how Australia is fueled by beer and bikinis, I'd look for the engines in bars and beaches. Best bet is prolly beach bars.
-
Self-addressed stamped envelopes
Daklu replied to drjdpowell's topic in Application Design & Architecture
I agree. I don't like locking a loop while it waits for a response from another loop at some unknown time in the future. I've used synchronous messages and sometimes you're kind of forced into them, but I prefer to design my system using asynchronous calls. When I do use synchronous messages I usually put a timeout on them to prevent perpetual hangs. To my way of thinking the situation you're describing is sequencing a series of operations, not sychronizing them. I interpret synchronizing as making sure all the processes start at the same time or have other strict timing dependencies. Personally I'd probably opt for a Rendezvous to provide synchronization instead of a synchronous message. That way the loop sending the message isn't stuck waiting for a response. Your example shows three different loops: the controller, the spectrometer, and the handler. Assuming sequencing--not synchronization--is the goal, you can accomplish that using asynchronous messages and a state machine in the control loop. Make the response messages from the spectrometer and the handler act as triggers for the state transitions, and then in the next state you'd send the next message in the sequence. It's a little bit more to set up on the front end, and state machine execution flow is a little more abstract than sequentially connected wires. On the other hand, I think the second option is more self-contained and less prone to unforeseen interactions. It also has the advantage that you don't have to invent alternative communication channels to work around the problem of blocking your control loop's input queue. That's not to say I think synchronous messages are bad or wrong. I don't think they are. I *do* think they are more dangerous to use, just like globals, reference data, and GOTO statements are more dangerous than alternatives. And I certainly don't feel as strongly about synchronous messages as I do about, say... queued state machines. Anyhoo, I'm enjoying your posts and seeing the designs you're implementing. Psst... priority queue. -
I've been using MAX to set up 7358 parameters for a motion control application and I swear* MAX is intentionally trying to irritate me. I must have put the same settings in half a dozen times, saved them, and even set them to be the default values for the controller card. Yet every so often the settings change in an unpredictable way. I mean, yeah, I'm resetting the card, loading (or trying to load) different configuration files, but sometimes the settings stick, sometimes they don't. If there's a logical explanation for the behavior I'm at a loss to explain what it is. Oh yeah, I had hoped to read some of the controller card settings from the MAX file or using the motion vis--specifically the motor step/distance and encoder count/distance ratios--but there doesn't seem to be any way to get that configuration data from the file or the controller card. Grr... (*NOT a figure of speech)
-
https://decibel.ni.com/content/blogs/memberfeatured/2011/07/25/july-2011-community-member-of-the-month-jonathon-green
-
Self-addressed stamped envelopes
Daklu replied to drjdpowell's topic in Application Design & Architecture
I have not examined either this or Mark Balla's messaging framework in depth (and probably won't have time for several weeks) but I did want to make a few comments: First, I'm thrilled to see more people adopting object-based messaging systems. I find the natural encapsulation of classes makes it easier to use, read, and extend. Plus it's a relatively safe way for people to get started with object-oriented programming. I wasn't the first to propose them (I think MJE was pitching his message pump before I started using message objects) but I do believe it is a natural fit for LV's dataflow paradigm. Second, there are a lot of cool features that can be added to a messaging framework, but... these features come at the cost of additional complexity. The complexity is found not only in how the framework internals are implemented, but is also often found in how the framework is used--its api. This can present a significant barrier to entry for new users, especially if they do not have experience using LVOOP. If the messaging system is intended for a small group of co-workers it's probably not a big deal. New employees can ask around to get clarification on how it works and how to use it. It might be too complicated if you're hoping to release it to a broader audience. My "ideal" messaging framework is one small enough to be picked up easily, light enough to be suitable for small projects, and flexible enough to be able to adapt it to more complex situations. At the risk of sounding like a shill for my own messaging system, those are the things I find so valuable with LapDog's Message Framework. The barebones functionality looks very similar to standard string/variant messages so it is familiar to non-LVOOP programmers. (I've received resistence to LVOOP from most LV programmers I've worked with. Familiarity helps reduce resistence.) If I need something a little more advanced, such as Command Pattern messages, I simply subclass the Message class to create a CommandMessage class, implement an abstract Execute method, and create all my Command classes as children of CommandMessage. Callbacks can be created in much the same way as you and MJE have done. Giving programmers the ability to use and learn only as much as they need goes a long ways towards enabling adoption, imo. (Of course, LapDog Messaging has been available for over a year and I know of exactly one person other than myself who has tried it, so take that for what it's worth.) Third, passing queues as message data can be very, very useful. If I have a lot of data going from one component to another that is far away on the hierarchy, I'll set up dedicated data "pipe" between them to avoid overloading the control message queues. However, too much direct messaging between components makes it very hard to understand how all the components are interacting. I get a lot of value out of having all the message routing information and slave interactions contained in the mediator loop. It is relatively easy to page through the message handling cases in the mediator loop and understand what conditions messages are forwarded to other slaves and what conditions they are handled differently. Also, I have found one of the harder things in debugging asynchronous messaging is figuring out where unexpected messages originated. (I use a "Source:MessageName" notation to help with that.) With hierarchical messaging I *know* the message must have come from the master, so I open that vi and figure out what triggers the message. I can rinse and repeat through the hierarchy until I find what caused the unexpected message to be sent. With direct messaging it's much harder to trace a message back to its source. I think direct-response messages are best used in situations where serveral clients need to interact with a data source on an irregular basis. Suppose we have a time provider but clients don't necessarily want to receive a time update every second. They do need to know the time occasionally, so sending a direct-response message to the time provider seems to be a reasonable solution. Lots of people use singletons or by-ref classes for instruments. I prefer to implement them as slave loops with messaging. Direct-response messages would probably work well there too when many clients need to communicate with the same instrument. However, I don't think I would be terribly thrilled with inheriting an application where the entire messaging system was direct-response. Don't quit working on it though. One of the most important things I've learned over the past several years is it is impossible to judge how useful and usable a reusable component will be by considering the design and creating sample code. You have to build something real with it--better yet, build several somethings with it. I've built components that worked brilliantly in one project but failed miserably when I tried it in the next. -
Sounds related. I posted there issue here but didn't get a CAR.
-
If you remember to do it before opening the project. (I usually didn't...) I get the impression VIE uses the UTF. In your opinion, does the UTF work well for testing object oriented code? I get the feeling UTF is better suited to testing procedural-based vis and JKI's VIT is better for testing objects. (Seems to me the NI and JKI should swap names of their unit testing tools. )
-
Bad me. I neglected to mention I've been using JKI's VI Tester. I've tried NI's UTF but had some issues with being unable to remove tests from the project and it annoyed me. Yeah, that's what I've been doing. But before I create the vi I have to create the class, and sometimes the method will return other classes, which means I have to go create them too. I think there's a real benefit to focusing on high level behavior by writing tests first. What ends up happening is I have to stub out the entire design before I'm able to write any tests, and that drags me into thinking about implementation instead of high level behavior. One of the ideas of TDD is to create a test, watch it fail, then implement enough code to make the test pass. I tried creating a generic test stub class and methods to use as filler while creating tests. That didn't work so well. It requires too much temporary code (to prevent compiler errors) that gets removed when the implementation is ready to be tested. I also don't really like the idea of editing the test to replace the generic stubs with the real code. Unfortunately I don't really see a good solution here. I suppose dynamically calling the code being tested would work, but that doesn't sound like a very good idea. I guess I'll have to keep creating stubs of my production code and try not to think about implementation.
-
I've attempted TDD in Labview a few times over the years and believe it would be a huge benefit... if I could figure out how to do it effectively. There's one issue I keep running into--namely, doing TDD in most languages entails writing the test code before writing any of the functional code that will be tested. Problem is... we can't do that in Labview. I can't drop a non-existent method for a non-existent class on the test method's block diagram. So I have to create the class and method stub before I can make any significant progress on my test, which disrupts the TDD process and eliminates at least some of the advantages of doing TDD in the first place. Is there anyone who feels like they have successfully implemented a TDD process for LV development, and if so, can you share some of the strategies you use to work around our inability to code to non-existent classes and methods?
-
Application File Structure + LVClasses and Methods
Daklu replied to durnek60's topic in Application Design & Architecture
Thanks Jon, that's good to know. Couple questions: 1. Your llb file names are prepended with an underscore. Do you do that because of potential naming conflicts between the llb and the class/library name? 2. I assume you have to create a unique source distribution for each llb, and the llbs have to be built before you build the application. Do you script your build process to control the build order? (There's a hanging curveball for you to hit out of the park.) 3. Why do you have a directory dedicated to Yair? -
Yeah, I guess that's the only solution currently available. It'd be nice if there were a better way to deal with the issue, but it is what it is. So that leaves my other question unanswered. Other than deleting records to reduce the class file size, are there any use cases where editing the mutation history would be beneficial?
-
Application File Structure + LVClasses and Methods
Daklu replied to durnek60's topic in Application Design & Architecture
I can't claim it's common, but here's what I do: For development, my applications are designed as components, each component consisting of one or more libraries (.lvlib), and each library containing one or more classes. Each class has a unique file system directory that matches the name of the class. I put the .lvclass file and all methods in this directory. Since each class member must have a different name and I work through the project explorer window instead of the file system, I don't bother creating subdirectory to group class methods. It creates too much maintenance during development. I group them using virtual folders in the project explorer. I do the same thing with libraries. Each library gets its own directory of the same name. All classes that are members of the library go in the library directory. My directory trees often look like this: ProjA\ProjA.lvproj ProjA\src\MyLib\MyLib.lvlib ProjA\src\MyLib\ClassA\ClassA.lvclass ProjA\src\MyLib\ClassA\Method1.vi ProjA\src\MyLib\ClassA\Method2.vi ProjA\src\MyLib\ClassB\ClassB.lvclass ProjA\src\MyLib\ClassB\Method1.vi ProjA\src\MyOtherLib\ClassA\ClassA.lvclass etc. For distribution I just copy the library's directory, assuming it doesn't have any external dependencies. -
Ahh... I see. The name index and version number define the unique key to look up the correct mutation record. So, I know it's possible to unflatten an object when the original class has been destroyed, but it requires the developer to have intimate knowledge of the flattened object's class properties. What about this scenario... A developer creates simple class C (non-container, non-child) and persists object 1 (C version 1.0.0.1), object 2 (C version 1.0.0.2), and object 3 (C version 1.0.0.3) to disk. The developer's cat then walks across the keyboard and deletes C.lvclass such that it is unrecoverable. The developer knows he has these flattened objects on disk, but he can't remember what data types each of them contains or their class version number. What I'd like to do is create a tool that helps the developer recreate class C so the persisted data is not lost forever. (If I had that tool I'd feel much more comfortable persisting objects directly to disk.) If I recall correctly, unflattening an object goes through several checks before it returns successfully: 1. The object's class name must match the class name wired to the unflatten type terminal. 2. The object's name index and version number must match with one of the mutation records. 3. The object's data cluster must match the data cluster in the mutation record found in step 2. If any of these steps fail, the unflatten fails. Since the data required to unflatten an object is embedded in the flattened data, it should be possible to read that information from the three flattened objects and create a mutation history for a new version of class C. I'll have to scour old threads to see if you've mentioned how that information is encoded when flattened. [Edit - I just remembered (or at least think I remember) data types aren't recorded as part of the flattened data. If that's true, recovering a flattened object would be a guess-and-check process.] Let me rephrase a bit to make sure I understand... Flattened child and container objects include the flattened data of the parent and/or contained object, right? And from what I understand a flattened object only contains the class name, index/version key, and data values. A flattened object does not include mutation history or even an entire mutation record; that information is looked up in the lvclass file. If the flattened object is a child or container object, I'd need to recurse* through the data doing the same process for each object I encounter before I can successfully unflatten it. That's going to be an extremely difficult process, perhaps impossible. Given the difficulties and uncertainty involved, is there any pratical value in having a tool that can edit the mutation history versus one that can simply delete unneeded records? (*Damn. And damn again. Recurse.) Sure, as long as your lvclass file doesn't grow to 25 mb. (Thanks, that's a good tip to know.)
-
I don't think Jason is suggesting a competing security system; he's saying use the functionality provided by the OS. (i.e. Windows login.) Ultimately the decision is driven by customer requirements. If they want a single password for all valid operators or if they don't have a good IT infrastructure, I expect I'd go more along the lines of what you suggested. If they want finer-grained control and have the infrastructure to back it up, using the available windows security functions seems like a better solution.
-
Application File Structure + LVClasses and Methods
Daklu replied to durnek60's topic in Application Design & Architecture
Good point, I hadn't thought of that. My classes are almost always contained in a library with other classes and I prefer my distribution format is consistent regardless of the content. Distributing an llb when there's no name collisions and a file system directory when there are name collisions kind of rubs me the wrong way. (This is just my personal preference... afaik there's nothing inherently wrong with doing that.) Come to think of it, I've been assuming it's not possible to split a lvlib or lvclass into multiple llb files. Is that correct? -
Doh! Sorry. (Though I did figure out why Jeff popped into my head.) BTW, the secret pass-phrase is ctl-space, ctl-d. (Make sure you have quick drop installed.) I made up the part about sacrificing Peeps.
-
Application File Structure + LVClasses and Methods
Daklu replied to durnek60's topic in Application Design & Architecture
When a class is loaded into memory all methods are loaded into memory as well. .llb files are old technology and don't work well for distributing classes. Packed project libraries *may* be an option, but there are lots of gotchas and you need to be careful. There isn't really a LVOOP-compatible equivalent of llb files yet. -
This is pure speculation, but my guess is manually forcing the version to 1.0.0.0 has created a conflict. If there are relatively few classes, I'd try doing a Save As on all your classes so LV sets them back to 1.0.0.0 itself.
-
Yeah, and if not allowing him to go to the event was intended as punishment I'd be inclined to agree with him. On the other hand, if the parent disallowed it to prevent the teenager from being in an environment where he is more likely to make bad decisions, then the whole issue of fairness is removed from the discussion. (Heh... as if irrelevance ever stopped a teenager from trying to win an argument.)
-
I didn't when I was trying to figure out how to get it to work. It's just something weird I stumbled upon. Only if you know the secret pass-phrase and sacrifice a box of stale Peeps in a WalMart parking lot.