Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-
I was cleaning out some dead code from a project I've been working on lately and discovered two of my .lvclass files each are nearly 25 mb in size. I'm not one to spend extra effort trying to minimize the size of my source code, but 25 mb seems excessive. It's not like there's a huge amount of data on the class ctl. Maybe 15 double precision floats (all default values) and a few comments. Even after removing all the private data, all the class members, and renaming the class to kill the mutation code it's still sitting there at ~25 mb. Granted this is with LV2009, but still... Anyone ever run across this before? Bloat.zip
-
During our family 4th of July get-together I was talking to my almost-14-year-old nephew, "B." He was telling me how he and his dad had a really hard time finding root beer extract to make the homemade root beer. When they finally did find some, there were only half a dozen bottles remaining and B wanted to buy them all. His dad--my brother--said no, and B finished his story with an emphatic, "It's not fair!" I couldn't pass up the opportunity to needle him a bit, so I said, "What's not fair about it?" B: "I wanted to get all 6 bottles but my dad wouldn't do it!" Me: "Right. Why isn't that fair?" B: "Because he wouldn't get 6 bottles!" Me: "I understand what you're saying. Why is that unfair?" B: "I wanted to get lots of extract so we could make a lot of root beer!" Me: "I see... you wanted to get all the extract but your dad said no." B: "Yes!" Me: "But you still haven't explained what's unfair about it." At that point gave me a look turned to my daughter (also almost 14 years old) and as they walked away I heard him say, "I don't understand what he's saying." That made my day.
-
So *that's* why you've been MIA... for you!
-
Well it certainly doesn't tell me enough... If I were to take a shot in the dark I'd guess some kind of feature that wraps structure nodes in a vi-ish type icon, perhaps without requiring it to be saved as a separate file. Kind of an "embedded" (or maybe "parasitic") sub-vi. Double clicking on it might open it in a separate window for viewing and editing with the changes being saved back to the host vi. Maybe in the project window the host and embedded vis will be displayed as a tree, complete with twist-outs so we can expand and collapse the view. Possibly there are different kinds of embeds for different structure node. A case structure embed could have a project window twist out that reveals all the cases. Same idea for an event structure embed. For and while loop embed twist-outs could show the number of iterations and/or stop conditions. Stacked sequence embeds will automatically torch all ethernet and wifi hardware, and crunch the usb host processor to prevent it from escaping from that computer. For good measure I think it ought to expose the user to electroshock therapy. Embeds are an interesting idea, but I haven't convinced myself they're a *good* idea. I can't figure out what problem it solves. Block diagrams are too big? Use sub vis. Too many files on disk? I know a lot of people complain about that (I did when I first started using LV) but there are real benefits to having lots of sub vis when it comes to multi-developer projects, source control, and testing. Not enough conpane terminals on sub vis? Use clusters or classes. I suppose one benefit would be the ability to use local variables and control references in the embeds directly instead of passing refnums through. Is that enough? I dunno... part of me thinks embeds would be encouraging bad programming habits. I considered a few other things too: -Eliminating sub vis completely and forcing us to write applications using a single block diagram. (Yeah, right.) -Eliminating structure nodes and allowing unhindered data flow. Nodes have a nasty habit of holding on to data at exit boundaries when it could be released to the next data consumer, but that would fundamentally change the way Labview behaves and make programming harder I think. But, you know... I'd only throw that out there if I were to take a shot in the dark. (How far off target am I?)
-

Object-Based State Machine Pattern
Daklu replied to Daklu's topic in Application Design & Architecture
Actually, I was glad you made the comment. It gave me a nice segue into my response. I often worry that I come across as an arrogant know-it-all descending from the mountain top to bless the unwashed masses with my wisdom. Every now and again I feel like I need to make a statement assuring people that's not how I think about myself. I talk a lot about my ideas and the things I'm doing with the hope of generating discussion. Hopefully through the free exchange of ideas we can discover new and better ways to build our applications. Very cool! Any chance you could post it? Don't worry about the spit and polish or completenesss--I'm interested in seeing your state machine implementation. I'm also curious what differences (if any) you noticed in your dev process or your code by implementing it as a state machine instead of a QSM. I know what *I* think about state machines vs. QSMs, but it might just be the way my brain is wired. [ironically, certification exams are one of the few places where I do recommend using a QSM. The problems are broken down in a way that assumes a QSM implementation and given the time constraints it's easier to go with the flow.] -
Object-Based State Machine Pattern
Daklu replied to Daklu's topic in Application Design & Architecture
Let me quickly address this comment first. I realize you may have intended it as a tongue-in-cheek comment or maybe as a bit of self-deprecating humor. Either way, I want to make it clear I do not think I am a "greater" programmer or that others are "lesser" programmers. We are all just programmers attempting to write applications that best fit our customer's needs. To do that we draw on our experiences and knowledge. My experiences and knowledge don't make me any more or less of a programmer than anyone else. I do think the LV path I travelled over the past 5 years has led me to develop coding practices that produce better code, but that is not the same as being a better programmer. What with this thread being about object-based state machines and all I figured it's kind of an inherent assumption that we're talking about state machines. Unfortunately Amazon isn't carrying "The Idiots Guide to the Complete History of the QSM" and my searches for its origin or how it was originally intended to be used have not been fruitful. I'm left to surmise it's original intent based on what it does well and how I see it implemented. I suspect many *think* they are using it in a way similar to how I use a message handler. What I see (especially in applications that have evolved over time) is message handling loops that no longer simply process messages, but which take on the characteristics of a state machine. That's not to say I see that from the typical Lava contributor... it's just what I see in general. I don't call them QMH's... that just leads to more confusion. Usually I call them "mediators" or "mediator loops," since that's often the role they fill in my code. (Mediating messages between different functional parts of the application.) "Message Handling Loop" might be a better generic term--emphasize the message instead of the queue. Yes, strictly speaking, a JKI-SM or PC-QSM can be made to be functionally equivalent to an MHL. It is possible to create sequences of states and manipulate the state queue in a way that gives the same result as the sub-vi's and case statements of an MHL. My question is why? Using queue-based sequencing makes the code harder to understand and is more difficult to verify. We could take it a step further and instead of queueing of states, we could link sub vis to create sequences within each state. After a state executes we could have it return immediately to the message receiving state. But if we want to do that, why use a JKI-SM at all? Seems to me we've just discarded nearly all of the functionality the framework provides and our code will be a lot simpler by using something else. The one thing that all QSM's support (and even encourage) is actively manipulating the flow of execution via some sort of queue. That, to me, is the defining feature of a QSM. That's the practice I'd prefer to see follow the path of the "Goto" statement. Do we *have* to use that functionality in a QSM-type structure? Nope. Are we going to use it when a customer is breathing down our neck and it's the fastest way to give them what they want? Probably. Are there better patterns that don't expose us and our customers to those issues. I believe the answer is yes, which is why I continue to talk about it. I appreciate the feedback. It's always a struggle to figure out the best way to communicate what is a really a set of complex interacting issues. I'm not sure I agree with the implied assertion that most people use QSMs to implement complex stateless processes. I've seen plenty of QSMs (and written plenty of my own) that ended up attempting to represent states as well. Often that results in lots of conditional logic in the Timeout case or weird waiting loops and queue manipulation in subsections of the execution flow diagram. I've written a lot about the QSM. Ultimately my writings have taken a two-pronged approach, though it may not have always been clear: 1. If you use a QSM to sequence a series of stateless processes, create sub vis and wire them together directly. 2. If you use a QSM to implement something that has states, use a real state machine. The prong that resonates with any particular person depends on what they are using the QSM for. I don't think I can focus on one argument and ignore the other. I'll also add that my LV experience has been almost exclusively in the desktop application space and that is the platform I'm referring to. I've never done FPGA, Fieldpoint, or CRIO in Labview. It may very well be that the QSM is one of the better patterns for those platforms. I don't have the knowledge or experience to make a claim one way or the other. -
Yep, I've seen that before a few times. Most recently was just a couple weeks ago. Unfortunately I don't remember exactly what I did to make it stop. I know I didn't have to replace the event structure.
-
Parallelism isn't inherently bad, nor does it necessarily require by ref objects. You can have lots of parallel loops executing without using any by-ref data. A recent small project I did had... I dunno... a dozen or so(?) loops running in parallel depending on the state of the application without a single bit of by-ref data. (I used queues to pass the data around instead of accessing it directly.) I think I remember Ben mentioning having hundreds of loops running in parallel. By-ref data structures are either a) a shortcut to sharing data because you don't know how or don't want to take the time to implement a by-value solution, or b) a necessary sacrifice to meet performance constraints. You mentioned you want a high degree of modularity. Modularity --> Loose Coupling --> Abstraction --> Additional Complexity. How much decoupling do you want? Using some sort of messaging system as glue for parallel components probably produces some of the least coupled code. I've found it works well for desktop applications when I don't really know what the final design will look like. It may not be a good solution for high performance data collection. If one module is producing data for several other modules to consume, I'd look into using some form of publish-subscribe or observer pattern. One solution is to have the producer send a data message to a mediator loop, which then resends the message to each consumer. (Or to the next mediator loop in the chain on the way to a consumer.) Another solution is to require each consumer to provide a queue when subscribing so the producer can pipe data directly to it. If this is the first big OOP design your group is undertaking I can almost guarantee you'll get the design wrong. Unless you have time and budget for your group to work through the OOP design learning curve, I'd recommend spending a little money to get an architectual consultant involved in the initial phases. They probably won't be able to give you a complete solution you can run off and implement, but they'll help prevent you from going down the wrong path and save you time and money in the long run. I hesitate to mention names for fear of leaving someone out, but I'd feel comfortable hiring Chris Relf at VI Engineering, Tomi Maila at JKI, or Stephen Mercer at NI. (I'm sure there are others at all three of those companies who could help as well... those are just the three who I preceive as having the most OOP experience there.) Spot on. That line of thought tends to put some limitations on how you use objects. Doh! May I propose a slight variation? I view the loop as LV's fundamental living process. (To be precise I should say the "parallel execution path" is the fundamental living process, but loops are the most common manifestation of PEPs.) We choose to wrap a loop (or group of loops) in a vi, class, or library to simplify the interface to its functionality and provide some level of encapsulation.
-
Sure... to figure out what my project is still dependent on. Mostly I use it for project maintenance when I'm refactoring and cleaning out dead code. During development I end up with a lot of vis (and classes and libraries to a lesser extent) that I used for preliminary work but have since discarded as the application evolves. I don't want to delete them from the repository or my hard drive unless I'm sure there aren't any lingering dependencies. Right-click, remove from project, check the dependencies folder to see if it showed up there. It's really useful when trying to disentangle someone else's code to exact a bit of useful functionality, or when replacing one library with a functionally similar library. (Say... switching from LapDog Message Library v1 to LapDog.Messaging v2.) I've also used it in the past when I've had private packages I've deployed using VIPM but haven't created palettes for. I don't really want them to be part of the project, but I do need them to be accessable.
-
Object-Based State Machine Pattern
Daklu replied to Daklu's topic in Application Design & Architecture
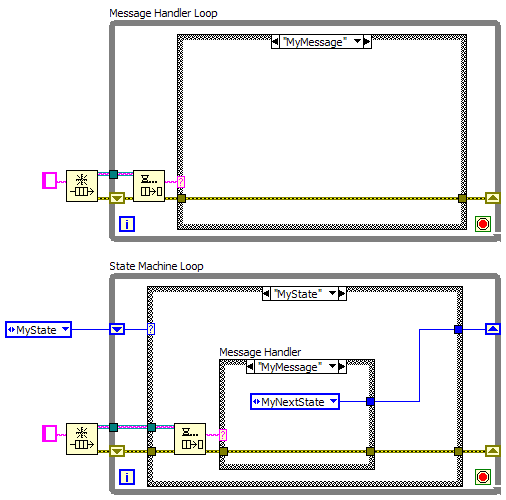
One of the problems with the QSM's poor name is that it doesn't give a clear idea of what it actually is. As near as I can tell there is no concensus on what characteristics make a QSM a QSM. Everyone has their own idea about what a QSM looks like. I generally focus my criticisms on the producer-consumer QSM model I posted here because I see it used a lot and many people do not understand its structural flaws. The reason I don't use QSM's of any flavor run much deeper and reflect a fundamentally different approach to programming. That's my point. Project requirements, not implementation, determine whether or not asynchronicity is needed. Case in point: Several months ago I wrote a small, independent component that captured, processed, stored, etc. I2C data from several sensor chips. It ran on a computer dedicated to collecting data while a robot did various things to the DUT. It had a front panel that allowed operators to start and stop data collection, view data, save to disk, etc. After a while the operators decided they wanted the component to start collecting, stop collecting, save data, etc automatically based on commands from the computer controlling the robot, BUT, they also wanted to be able to interact with the front panel at the same time. One process, two clients. "Bottom of the ninth and QSM Engineering is down by six runs..." At bat: Ugly Hack On deck: Race Conditions In the hole: Mayhem JKI's state machine combines the producer and consumer, so the statement is rather meaningless in that context. I don't remember ever runing across a PC-QSM in the wild where the producer loop didn't directly initiate state changes. (Except for my own explorations before switching to object state machines, but that doesn't really count.) In the example I posted the default behavior of any state is to ignore a message. You, the programmer, add code to enable the correct message response. QSMs have the opposite behavior; by default they accept and execute every message they receive regardless of the state of the loop. You, the programmer, have to write code to prevent an incorrect message response. Which is the safer approach? Which is easier to verify? As change requests come in and you add more messages, which is going to be easier to maintain? In the case of your Start button, the state machine ignores the message if a start message doesn't make any sense given the application's current condition. Maybe it's already running. Maybe the instruments aren't initialized. Maybe there's an error. It doesn't matter why the message is invalid, it just matters that the message is invalid. This makes the state machine robust to errant messages and near bulletproof. To handle user interfaces, usually my state machines will broadcast general messages ("DataCollectionStarted") to notify clients about what is happening in the state machine. Client code can choose to do (or choose not to do) things like disabling a start button, popping up a dialog box, or electrocuting the user if desired. But this is implemented in UI code. It is not part of the state machine. It's interesting you say this. I have no idea where exactly QSMs came from, but I've long suspected there were three main things that influenced its creation: 1. A strong desire to keep the block diagram size to a single screen or less. 2. An unhealthy reluctance to create sub vis. 3. Using flow charts as the primary (and perhaps only) tool to model the application. Your question reflects the fundamental differences I mentioned earlier. I don't implement complex flow charts because flow charts don't do a good job of modelling a solution to requirements placed on modern-day applications. Flow charts are particularly useless (IMO) for modelling event-based programming. I do use flowcharts during development to clarify processes and decision making, but my application is not structured around flow charts. When I have sequential processes that can be modelled accurately using a flow chart, I implement it the same way as everybody else--with case structures, loops, and sub vis. It's far, far easier to follow the logic when well-named sub vis and switching conditions are layed out sequentially than when I have to flip back and forth between case frames as they manipulate the state queue.* (*Using a queue to control execution flow is one of my biggest issues with all QSM patterns. There's potential there for creating self-learning applications and other interesting behaviors that aren't explicitly defined during development, but when was the last time you wanted an application to do something unpredictable? Execution flow is most clearly expressed by using wires to connect sub vis.) I'm not suggesting using a state machine for everything... just those things where a chunk of functionality needs to have different responses to the same message depending its current state. Things like instrument APIs and high level application logic. I don't typically use state machines in my UI code, but I may at some point. It's usually not required. State machines do play a major role in my applications because application behaviors usually have to change depending on the state of various components. I also uses message handling loops a lot. A message handling loop looks a lot like a PC-QSM consumer loop. The difference is in how it is used and what limitations I put on it: 1. The most important thing is that I do not--ever--let a message handling loop put messages on its own queue. This rule prevents any sequential dependencies between cases from forming. In fact, I don't allow the queue wire to connect to the case structure at all. That makes it easy to see that I (or someone else) hasn't accidentally created an internal sequential dependency. If I want to reuse the code in another message handling case I make it into a sub vi and call the sub vi from both cases. 2. Message handling loops don't have any self-state. It's not "uninitialized," "initialized," "running," etc. The loop is either executing or its not. It may, depending on the needs, maintain information about loops it communicates with, but it is not stateful in itself. 3. Each message must be independent of all other messages. That is, messages can be called in any order and at any time and the message handler must remain fully functional. As long as I've adhered to rules 1 and 2 this one usually follows without any additional effort. State machines and messages handlers are the two flavors of loops I use on my block diagrams for non-trivial applications. The diagram below illustrates the differences in a nutshell. (Notice neither of them puts messages on their own queue.)
-
Me too... but to be honest I'm more grateful for the time *you* invested in creating and releasing an awesome tool. I'm sure my investment was a pittance compared to yours. I did experience one inconvenient issue. After opening VIT, running some tests, and closing it, opening it again would cause an insane object error and LV would exit. I had to close the project and reopen it before starting VIT again. This is with LV9 sp1, Win7, and the latest version of VIT. It could be part of LV's object growing pains or something unique in my environment. I haven't had time to investigate the error at all and while inconvenient, it wasn't a big enough problem to prevent me from using the tool. One minor wish--I use the project dependencies folder a lot. Is it possible to wrap all those dependencies in a library?
-
Yep. I don't think LV keeps track of the active window--that's the OS's job. You might have to make windows api calls to get that information. There's a small visual basic example here that get the title of the window currently active. Perhaps you could parse the window name to get the vi name, and get the reference from that?
-
I've used VI Tester (and NI's Unit Tester Framework) in the past, mostly to explore what they can do and how I can use them to improve my normal workflow. I've never been in a situation where I've *needed* to use it to get the job done--until now. I'm currently working on a motion-vision system where I'm dealing with 8 different frames of reference. Needless to say, the bookkeeping has been dizzying. Changes to one reference frame has a ripple effect through to the dependent reference frames. After spending several hours last week trying to sort out exactly how a change I had made broke the rest of my code and realizing I couldn't keep it all in my head at once, I decided to pull in VI Tester. Over the last several days I built 50+ unit tests to test the key transformation algorithms I have been using. My code was changing a lot so I probably spent more time writing and editing my test cases as I did writing production code. With deadlines looming I had to force myself to keep the unit tests up to date instead of abandoning them. In the end I was able to get the algorithms right with at least 6 hours to spare. I can't emphasize enough how valuable it was to make a change, run the tests, and get instant feedback on what effects the change had on the rest of the system. Understanding the benefits of unit testing is one thing--experiencing the benefits of unit testing is a whole 'nother feeling. Thank you JKI!
-
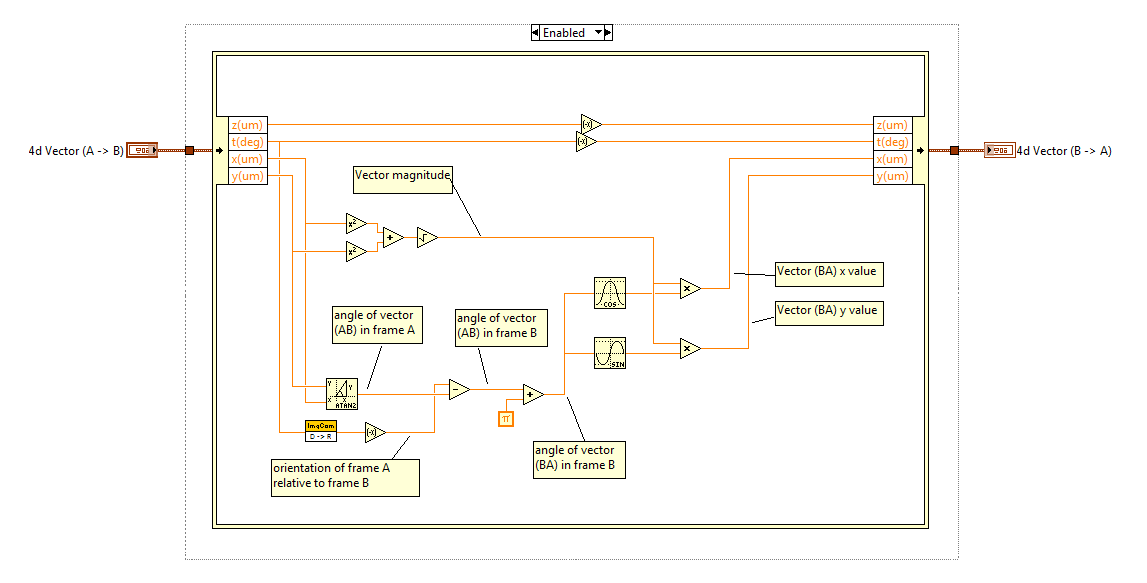
I'm working with 3-point vectors (x, y, and t) where x and y define the location of point p and t defines the angular orientation of point p relative to the vector's frame of reference. For example, if vector AB is (2, 3, 30), that means point B (B is actually the origin of another frame of reference) is located at x=2 and y=3 in A's coordinate space and it is oriented +30 degrees with respect to A's coordinate space. Now the problem: Given vector AB in unknown coordinate space A, how can I calculate vector BA in coordinate space B? In other words, knowing only vector AB's values (2, 3, 30), I need to find vector BA. I'm pretty sure it's solvable mathematically--I can sketch it out on paper and visualize the solution. What I have so far works for some restricted situations but isn't robust enough to handle an arbitrary input. Any ideas?
-
I agree, yet I run across many experienced developers who still use it without recognizing it has significant issues. No teachers are as effective as personal experience. The JKI SM is a big improvement over the QSM illustrated above. It does not, however, solve all the issues with QSMs. IMO what it does is decrease the opportunity for common mistakes by imposing more constraints on the developer. That's not meant as a criticism and imposing constraints is not necessarily bad... it just means that the problem space in which the solution can be cleanly applied is reduced. (Of course, it's been a while since I've looked at the JKI SM and I've never used it extensively, so it could be that I've misunderstood how to best apply it.) Personally, I would recommend people starting to use QSMs take some time to learn the difference between a state diagram and a flowchart and explore consequences of choosing one over the other.
-
Object-Based State Machine Pattern
Daklu replied to Daklu's topic in Application Design & Architecture
It's very unlikely I will release this version as a package deployed to vi.lib. Doing so prevents customizing the existing state classes to meet the specific application requirements. It's possible to add plumbing that allows overridden core state classes to be used in place of the core state classes, but it adds complexity to the implementation (which is already difficult for many to understand) and I don't see much value in that feature. Putting the state machine template in vi.lib works best when you have many state machines across several projects with similar behavior. Single developers or small groups working in a relatively small domain are likely to be able to do that. As a developer creating code for other developers, I need to keep it as flexible and easy to use as possible. It's just like any other template code available in LV... except this template includes several classes the work together whereas most other templates fit on a single block diagram. The template doesn't prevent having multiple or nested state machines in an app. Just give each containing library a unique name. Can you post it? I agree everyone tends to use their own messaging system. Unfortunately there isn't a clean way (I can think of right now) to allow users to inject an arbitrary messaging system without modifying the core code. The states *have* to get signals from external sources somehow, be it queues, notifiers, DVRs, etc. That said, I'm perfectly willing to discuss alternatives. Of course. -
Obviously I can't speak for NI, but I suspect not. One tip I got from my review panel was to do a somewhat detailed implementation for one module and refer back to it with the other modules. But your question highlights the hardest thing about the CLA--figuring out what work scores points and what work doesn't.
-
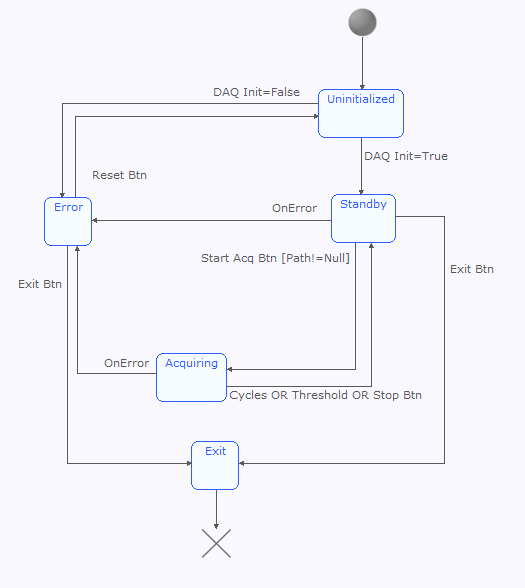
I didn't examine the diagram in depth, but your requirements and questions suggest a "quick-and-dirty data acquisition vi" will not adequately meet your needs. Personally I'd refactor into a event-based producer/consumer design. Labview includes a "Producer/Consumer Design Pattern (Events)" template that is a good starting point. (File -> New... -> From Template -> Frameworks -> Design Patterns) The template's consumer loop is set up as a simple message handler. At first glance it sounds like a state machine in the consumer loop will fit your needs better. I posted an example of how to implement a simple event based state machine here. Skip the Entry, Exit, or Transition actions if your state machine doesn't need them. I strongly suggest sitting down with paper and pencil and creating state diagram that defines the core behavior you're looking for. It should include: States: Uninitialized, Standby, Acquiring, Exit, Error, etc. These five states are probably sufficient for this app. Add new states if needed. Transitions: Decide which transitions are valid and draw an arrow connecting the states. For example, it doesn't make sense to transition from the Uninitialized state directly to the Acquiring state. Triggers: Triggers are actions that cause a state transition. List the triggers next to the transitions. Guard Conditions: These are conditions that much be true for a transition to take place. Guard conditions are contained in square brackets following the trigger. Getting the state diagram right will go a long ways towards simplifying the coding part of your application. Here's a quick example state diagram based on your requirements.
-
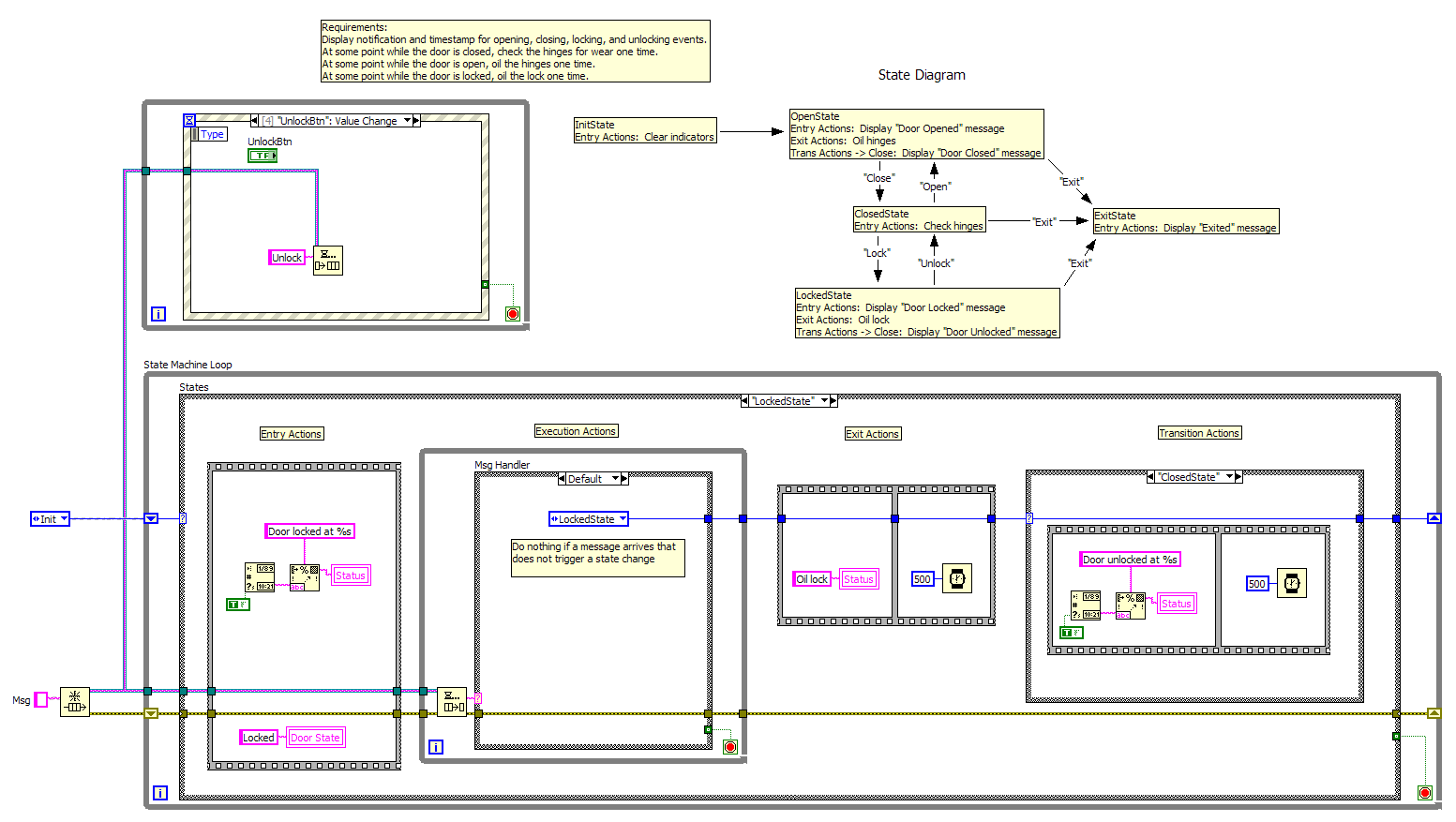
Two states... fire, no fire. My understanding is that it's a variation of a Harel state machine. I posted a non-oop implementation illustrating the idea here. It's not really that complex once you understand it. In truth anytime a state machine grows beyond a handful of states there really should be a diagram describing the state machine for future developers, and if you have a diagram it's very easy to understand and maintain.
-
Object-Based State Machine Pattern
Daklu replied to Daklu's topic in Application Design & Architecture
By the way, here's an example (LV2009) of similar Harel state machine behavior without using objects. The main differences between this and the object implementation are that there is no state specific data or error handling in this example. The example also doesn't have any execution actions other than monitoring messages from the user. A couple things worth noting: 0. This example makes extensive use of local variables in the state machine loop. I did this for simplicity. Usually I will have a separate display loop and have the state machine send messages to it when fp controls need to be updated. 1. The producer loop does not directly initiate state transitions. It sends a message to the state machine requesting a state transition, which the state machine will do if a valid transition is requested. If an invalid transition is requested the state machine ignores the message, though in the past I have sent debug or status messages to the UI to let the user know what is happening. Allowing producer loops to directly control state transitions is IMO the single biggest flaw in the traditional QSM. You have to break that link if you want to create more robust and scalable code. 2. Using a "real" state machine means all my transition logic *has* to be contained in the state machine loop instead of distributed across several loops. It's way easier to verify that my code correctly implements the state diagram and way harder for other developers to use the state machine loop incorrectly. There is simply no way for a rogue producer to initiate a transition that violates the conditions defined by the state machine. 3. This model provides better separation from the UI. I have often seen devs disable front panel controls to prevent invalid transitions when using a QSM. I usually ran into synchronization issues when tried that--controls wouldn't always be enabled or disabled at the right time. Here I don't have to worry about that--the state machine just ignores the message. If I want to disable a control I'll have the UI display loop do that in response to the state transition messages sent by the state machine. (Not shown in the example.) 4. It's ridiculously easy (and safe) to have multiple producers controlling the same state machine loop. Just give the new producer a reference to the state machine's input queue and start sending it messages. Asynchronicity is not an issue as far as the state machine is concerned. (Try that with a QSM! ) ------------ When I wrap everything in classes the concept seems more complicated that it really is. I hope this example helps people understand the core functionality at work and why I think it's time for the Labview community to move away from the QSM (unless you're taking a certification exam.) If anyone feels like comparing implementations I'm curious what a traditional QSM looks like that has this same behavior. SimpleStateMachine.vi
-
Object-Based State Machine Pattern
Daklu replied to Daklu's topic in Application Design & Architecture
Doh! Sorry about that. I was in a rush trying to get the post finished this morning and stupidly linked to the wrong zip file. I attached the correct (I hope) zip to my post above. -
Object-Based State Machine Pattern
Daklu replied to Daklu's topic in Application Design & Architecture
I've attached a state machine template I've been working on. It requires LV2010 and the LapDog Messaging Library v1.2. The main state machine loop is designed to run in parallel with other processes, so I've wrapped it in another construct I use--a SlaveLoop object. SlaveLoop.ExecutionLoop is where you'll find the main state machine loop. You can take it out of there and drop it on a Main.vi if you want to ditch the slave loop. IIRC the main differences between the original state machine implementation and this template are, a) the "inner" while loop is now implemented in each state's ExecutionActions methods instead of on the State Machine Loop diagram, and b) the error handling mechanisms in BaseState.TransitionActions is a little more robust. I'll answer your questions in the context of the template, not the original example. Transitions seem to be handled in Entry and Exit actions. But what if I want an action to be executed only in a from one state to the other? (i.e. a transition action) Transition actions are implemented by checking which state is present in the NextState field and casing out the possibilities. The ExecutionActions method sets the NextState field when the input conditions trigger a state change, but the current state isn't actually changed until the TransitionActions method executes. Transition actions are ideally implemented by overriding the BaseState.TransitionActions method, but strictly speaking they could also be implemented in the MyState.ExitActions method. If you do override the TransitionActions method, be sure to call BaseState.TransitionActions right before exiting your method. BaseState.TransitionActions does the error checking (substituting the ErrorState if an error is present) and prepares the NextState object for execution. I will use the SM from the GUI, which will trigger state changes. Can I use the SendMessage method for that? I ask this because it is currently a private method of the SM The way I typically handle that is by having the GUI events call SlaveLoop methods. The mediator loop in SlaveLoop.ExecutionLoop handles the message and in turn sends messages to the state machine. The mediator loop appears to be a needless complication, but that is where I implement multiple triggers when I want to progress through a series of states, such as when exiting the state machine. What needs to be done if I want a more generic SM class that will be inherited, in order to be reusable from one case to the other? This state machine is implemented as a collection of classes, not a single class. I haven't explored inheriting an entire state machine since I haven't had a reason to do so. Subclassing a single state within your state machine might be possible--I haven't tried it. The main complication is if your parent class has data the subclass requires you'll need some way to set the parent data when the subclass in created. (I do that in BaseState.TransitionActions so the new state object has correct queue references.) Have you considered to make it an OpenG package? The Beagle code specifically or this state machine pattern in general? The Beagle code, no. The State Machine template, yes. (Well, a VI package, not an "OpenG" package. LapDog and OpenG have slightly different purposes and don't quite fit together.) There are a couple things that have been delaying releasing the template as a package: 1. This template is copy-and-paste reuse, not vi.lib reuse. I need a scripting tool that will copy the template library to the user's project directory and include it in the project. Scripting isn't my strong point and I don't have time to figure it out. This is the biggest reason. 2. It depends on the LapDog Messaging Library. I'm reluctant to release code with dependencies on other packages because it can easily lead to a variation of dll hell. It will probably be okay since this is a template, but I'm still not very comfortable doing it. 3. I have other LapDog packages in my queue that have had a higher priority. If there's demand for the template I can certainly shift priorities. [Edit - Replaced the zip file with the correct one.] LD StateMachineTemplate.zip -
NI had already laid claim to the name "QMH" as a starter template that ships with LV. It's vaguely similar to the QSM but completely sidesteps the problems associated with a producer-consumer QSM by virtue of only having a single loop. I proposed calling it a "function machine" here, and "Hector" here, neither of which gained much traction. (Go figure...) I'd support calling it "painful," "job security," or "bad idea" if anyone else wanted to take up the cause. I'm still fairly well convinced the QSM pattern shown here is not a very good design for anything other than NI's exams or prototype (read: throwaway) code, but I've written much on that already and won't repeat myself here. If you're comfortable with objects I posted an object-based state machine here. I've refined it a bit since that post but the principles are sound.
-
Thanks Ben. I hadn't considered copy on write, but that makes a lot more sense than either of the two options I posted.
-
I've been refactoring some prototype code that uses globals extensively. Consider the following situation... One loop writes to the global infrequently in response to a front panel event. A parallel loop reads from the global on every iteration. My understanding is that LV creates a copy of the data in a global every time it is read (eager copying) rather than waiting to for someone else to attempt to change the global while the data is in use (lazy copying) before making a copy. Eager copying makes more sense for LV's primary market, but I've kind of been talking myself out of it. Can anyone confirm?