Leaderboard




Popular Content
Showing content with the highest reputation on 05/02/2014 in all areas
-
In other words to what Logman said: if you have a bag that is to small to put in 6 apples in their own little baggy, then try to put in 1 apple a time without baggy, you still won't be able to to put in all 6 apples!1 point
-
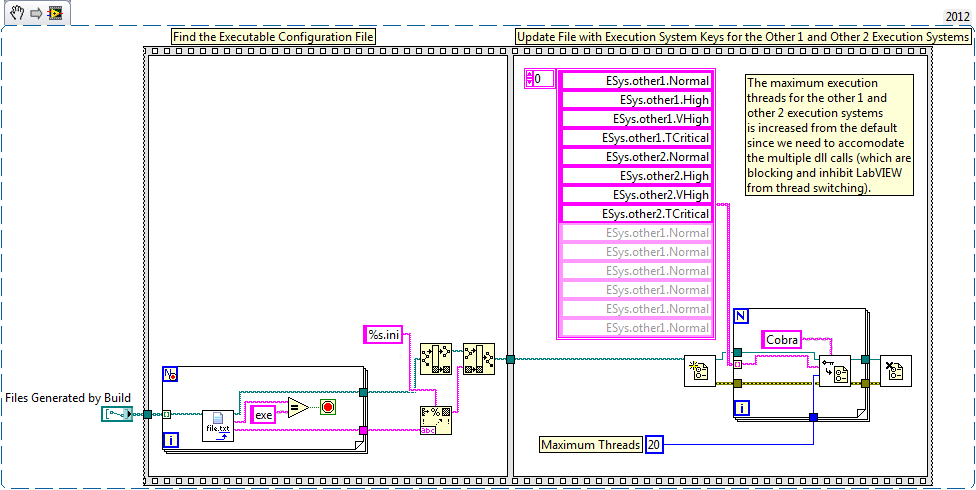
The configuration is contained in the *.ini file for the built application along with other properties such as vi server configuration. Here's an example of the content that updates the Other1 and Other2 execution systems maximum thread count for each priority. You can generate this programmatically as part of the application build spec with a Post-Built Action : ESys.other1.Normal = 20 ESys.other1.High = 20 ESys.other1.VHigh = 20 ESys.other1.TCritical = 20 ESys.other2.Normal = 20 ESys.other2.High = 20 ESys.other2.VHigh = 20 ESys.other2.TCritical = 20 Note that you could also just use the same property settings in your LabVIEW.ini file for the same effect in the development environment. I believe this is all threadconfig.vi actually does however it doesn't touch any application build specs (not that sophisticated I'm afraid). Here is a quick post build vi I cobbled together to generate the entries on every application build:
 1 point
1 point -
I didn't look at Ton's attachment but I have done this in the past using a .NET System Filewatcher Object and registering a callback VI for when the .NET event fires. It works pretty well, the only challenge was that the callback was called in a LabVIEW context that you can't debug directly.1 point
-
Wow. Lots to respond to here. You can also pass in floating point numbers, but be careful: LabVIEW uses the IEEE 754 round-to-nearest even integer rule when rounding numbers that end in .5. 102.5 rounds to 102. 70.5 rounds to 70. 71.5 rounds to 72. Also, the behavior changed in LabVIEW 2010. To Upper Case, To Lower Case, Octal Digit?, Decimal Digit?, Hexadecimal Digit?, White Space? and Printable? all allow you to wire in a numeric. According to their documentation, those nodes evaluate the numeric as the ASCII character corresponding to the numeric value and in all other cases return FALSE. In LV 2009, they return false for any value over 256. In LV 2010 and later they return true for some values -- corresponding to the proper return value for the lowest 8 bits. E.g. LV 2009's White Space? primitive returns true for Int32(10) -- the line feed character -- and false for Int32(266). In LV 2010 it returns true for both. I'm usually the loudest complainer about people treating strings as a byte arrays. In most programming languages, strings are not bytes arrays. In some languages, for legacy reasons you can treat them as byte arrays. In LabVIEW they are byte arrays. That results in interesting things with Multibyte Character Sets. I don't have any of the Asian localized LabVIEWs installed, but I think strings in those languages will have a string length reported as twice the number of characters that are actually there. When you have the unicode INI token set, this is definitely the case. Arguably that's wrong, but there's no way to go back and change it now. I couldn't agree more to your first three paragraphs, but I've got to disagree about the difficulties. The platforms which are supported is entirely related to the language and compiler for that language. Any time -- absolutely any time -- strings move from one memory space to another (shared memory, pipes, network, files on disk) the encoding of the text needs to be taken into account. If you know the encoding the other application is expecting, you can usually convert the text to that encoding. There are common methods for handling that text that doesn't convert (the source has a character that the destination doesn't have), but they're not perfect. The good thing is that it'd be extremely rare since just about everything NI produces right now "talks" ASCII or Windows-1252, so it's easy to make existing things keep working. What you're talking about is how the characters are represented internally in common languages. In C/C++/C# on Windows they're UTF-16. In C/C# on Unix systems they're UTF-32. As long as you're in the same memory space you don't need to worry. There is no nightmare. Think of your strings as sequences of characters and it's a lot easier. As soon as you cross a memory boundary you need to be concerned. If you know what encoding the destination is expecting you encode your text into that. If/when LabVIEW gets Unicode support, that will be essential. Existing APIs will be modified to do as much of that for you as possible. Where it's not clear, you'll have the option and it'll default to Windows-1252 to mimic old behavior. Any modern protocol has its text encoding defined or the protocol allows using different encodings.1 point
-
I have a subVI that calls subVIs that in turn call other subVIs. I need to be able to run the top level subVI in parallel with itself. At what level do I need to use reentrancy - just at the top level or do all the subVIs down to the lowest level all need to be reentrant? George1 point
-
There are a lot of considerations when deciding which VIs to make reentrant. Its about finding a balance between maximum performance and minimum memory usage. Any VI that maintains state needs to be either non-reentrant or fully reentrant depending on its requirements for that state. If there are any VIs that truly can't be called at the same time, those should stay non-reentrant. This could be things like configuration dialogs or file modification. Non-reentrant VIs are one of the easiest ways to serialize access to single instance resources. Any VI that is part of a performance critical code path probably should be made fully reentrant. This avoids synchronization points between multiple parallel instances of performance critical code or non-performance critical code getting in the way of performance critical code. Beyond that you can start to favor non-reentrant or shared reentrant to reduce memory usage. As crossrulz said, VIs that always execute quickly can be considered for leaving as non-reentrant. Keep in mind that there is a difference between a VI that always executes quickly and one that typically executes quickly. Anything that does asynchronous communication (networking, queues, ...) should be considered slow, because it could take longer than expected. Making VIs that are called from a lot of places shared reentrant instead of fully reentrant will slightly increase execution time but can greatly reduce the number of instances required and thus memory usage.1 point
-
My understanding is that for true parallelism all of the subVIs should be reentrant. If you have VIs that are really short/fast, you could possibly get away with not making them reentrant to save a little memory. I will throw out the warning to be careful about VIs that need to maintain state (FGVs, Action Engines, whatever you want to call them) and reentrancy.1 point