Leaderboard




Popular Content
Showing content with the highest reputation on 03/15/2011 in all areas
-
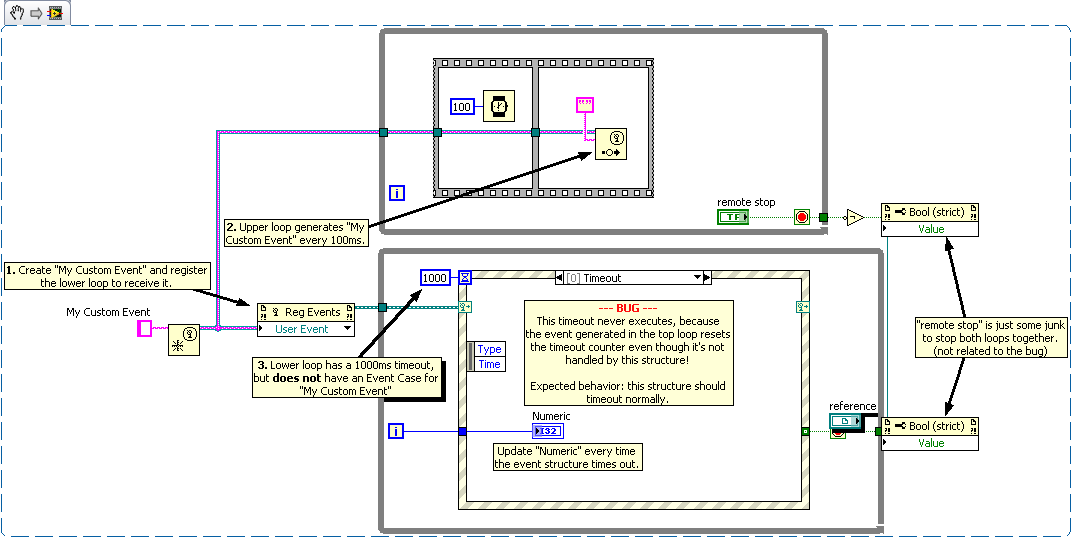
Something finally clicked for me during my CLA Summit presentation last week (thanks, Steen, for triggering my brain!). Here's the issue: Any event for which an event structure is registered, but for which it does not have a case, resets the timeout of that event structure anyway. To put it another way, imagine you have a custom event that's wired to multiple event structures. However, not every event structure actually handles the event (i.e. they don't all have a case for it). When you fire that event, it will reset the timeout counter for all the event structures, even the ones that don't handle the event. This means it's possible to have an event structure in your code that never times out, and also never executes an event handler, even though it's got a non-zero timeout value. This feels like a bug to me for the following reasons: We register for Front Panel events by creating event cases for them, and events that don't have cases don't interrupt the timeout. Why would we not expect User Events to work the same way? It's virtually impossible to detect when this is happening in your code. In the attached example, the event structure looks like it should be timing out, and in a complicated application it's almost impossible to tell why it's not. However, at the CLA Summit there was some room for disagreement about this. LAVA, what do you think? Screencast: http://screencast.com/t/qDIKpn9oQnlD Snippet: (note the snippet creation made those crazy non-static property nodes on the stop logic; that's not me ) Code (LV2009): Event Structure Timeout Bug.vi
 1 point
1 point -
Not sure if this is the best place to post but check our white paper for accelerating the FIX protocol using FlexRIO and LabVIEW FPGA http://www.wallstree...a.com/fixcancel Feedback and comments are appreciated.1 point
-
Oh, I'm not saying that it's counterintuative - it totally is, until you stop and thinking about what's going on. That can be said for several things in LabVIEW (remember the first time you branched a by-reference wire and couldn't fathom why the data "on" the other wire was changing?) Maybe there should be an option to unset this should be available (like an "allow unhandled events to be registered" checkbox in the event dialog if the dynamic event handles are shown). That said, I'm sure AQ will agree that it's a little more complicated than just adding a chekcbox1 point
-
You don't expect me to read threads do you? Apologies. He's all yours1 point
-
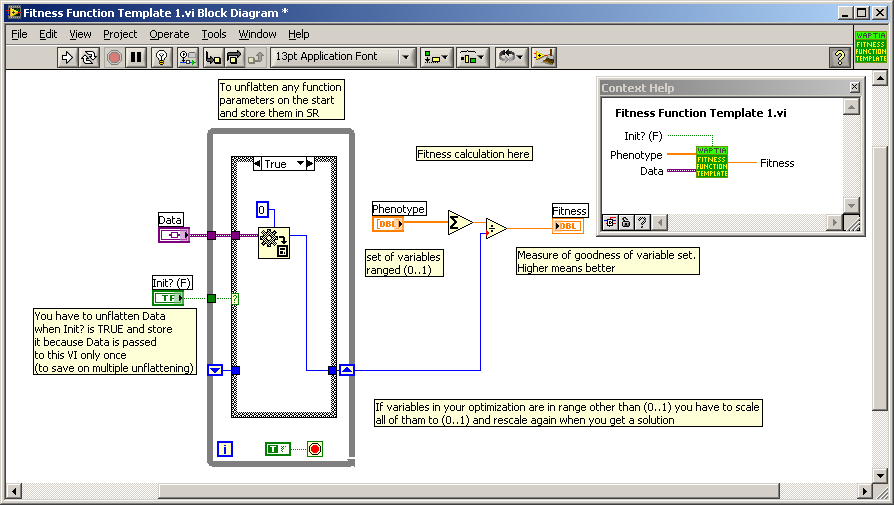
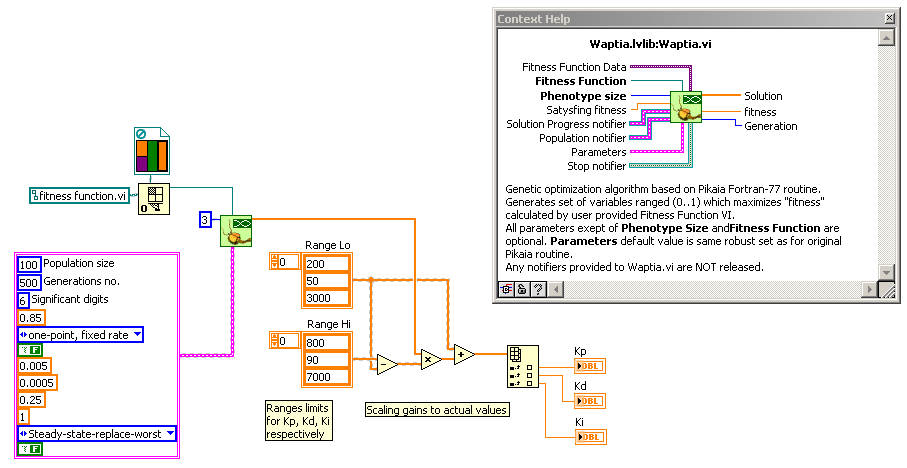
Short explanation first - this is continuation of ours private discussion, so I repeat some things already said. Thanks for asking it - PID optimization is a very good use case for genetic algorithm. But you have to remember that it is only good for off-line optimization as it base on huge number of trials. So you have to have prepared a numerical model of your object of control - a program (VI in case of LabVIEW) which respond on control signal exactly the same way as real object would respond. To prepare it you have to know what phenomena drives your object, what are their equations and you have to implement them with proper coefficients (measured i.e.). To be more specific I have to know what exactly do you want to control with PID. Once you have the model you have to insert it into simulated PID loop, so you have a model of whole control system with Kp, Kd and Ki coefficients as parameters (gains of proportional, differentiating and integrating blocks respectively). Than you have to determine what will be the measure of quality of regulation. Typically parameters of response on step-like excitation are used for this purpose: You have to decide which of these parameters are more important, which are less important, which are not important at all and combine them into one number which is the higher, the better regulation is. It may be for example weighted sum: a*(1/rise_time)+b*(1/overshoot)+c*(1/settling_time), where a,b,c are the weights. In genetic algorithm such a number is called a fitness function and PID optimization process may be now described as: find such Kp, Kd, Ki which maximizes previously defined fitness function. You have to implement a fitness function as a VI which takes certain Kp, Kd and Ki parameters, makes a simulation of control system's response on step-like excitation, calculates quality parameters out of the response and combines them into final quality measure. In Waptia you have to implement fitness function as a strictly typed VI. There is a special template in main Waptia directory (Fitness Function Template.vit): Phenotype input (1D array of doubles) in terms of genetic algorithm is a set of parameters describing the system, which are the subject of optimization. In our case size of this array will be always 3 and Kp, Kd and Ki will be coded in it. Coded, because optimizer requires all parameters to be scaled to 0..1 range. So you have to know the expected ranges for optimized gains (you could determine them using i.e. Ziegler–Nichols method and some manual checking). Your fitness function VI could look like this: Data and Init? inputs are not required in simplest approach, but they may not be deleted as VI must be strictly typed. You could use these inputs to control other parameters of the models which are not to be optimized (i.e. coefficients of equations of the model). Code for actual optimization of PID gains is now as simple as: Values from final solution have to be scaled, because optimizer works on 0..1 range and it doesn't know anything about scaling you use. Most significant parameters for optimizer are population size , number of generations (both affect computation time) and number of significant digits. All parameters are described in documentation, but if you need more detailed explanation, don't hesitate to ask. It was quite general introduction for PID optimization using genetic algorithm. To help in anything more specific, I have to know more details on what do you want to control. But if you already have a model as you said, you are very close to make an optimization of PID gains.
1 point
-
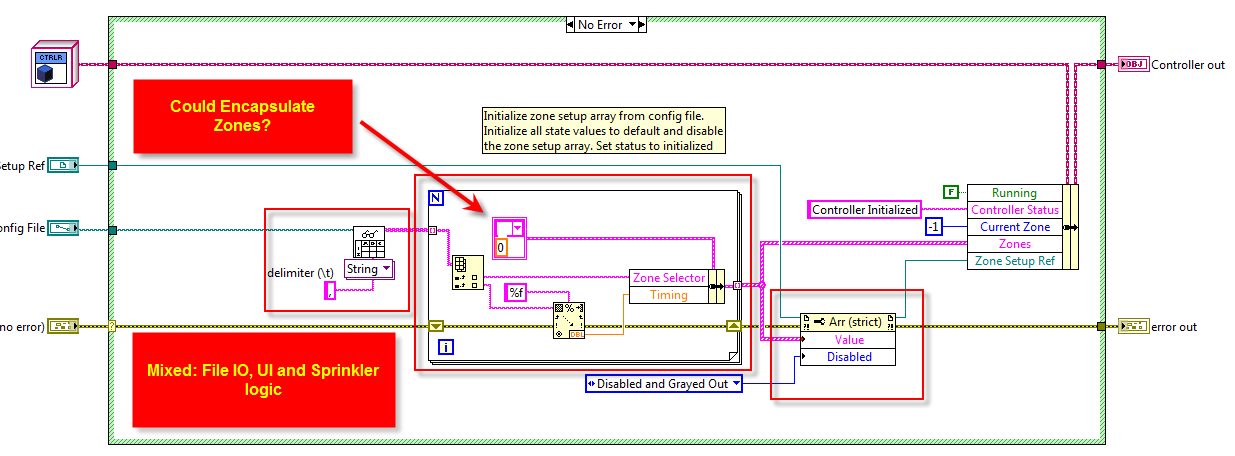
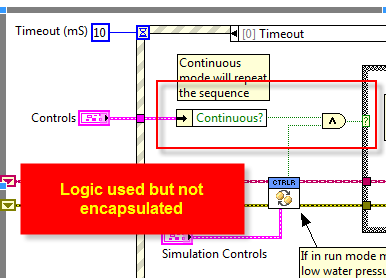
Hi Steve Firstly, this is just my opinion. Secondly, if it works - it works (so good job ) - but I always like to ask myself can it be done better? So on that note, comparing your two posts, it feels that you have just used LVOOP for the sake of it. As a result you have coupled your UI to the logic of your code. I discussed this on the darkside here with respect to the CLD so I won't regurgitate it again, only to say that you mention that... ...yet you have used logic (nodes) on the top level BD which are not encapsulated. Additionally, you have used typedefs that are not part of a Class, but which form an interface to your Class (i.e. public clusters) (private clusters is another topic for discussion when persisting data to disk not relevant to this one). This is not always a bad thing, I do this for: UI Classes where the role of the Class is to essentially take data and format it for display (but note there is always that distinction) - I do this as opposed to breaking out an X-Control when I don't need to. Very Top Level Class which is just wrapping up all the Classes e.g. so method calls do not sit on the BD of a process\loop etc... - this is what I think you have done however, underneath it is still coupled. Therefore, I think there is the opportunity to encapsulate more. However, given the size of the application it may be overkill, but would definitely be a good exercise. I don't think LVOOP makes it more exciting, perhaps using LabVIEW 8.6 instead of 2010 was a better idea this time to cover more reviewers? Although I prefer LVOOP when programming day-to-day, I ended up using a more traditional approach for the CLD given the nature of the question\solution, time available etc... Cheers -JG
1 point