Leaderboard




Popular Content
Showing content with the highest reputation on 10/23/2011 in all areas
-
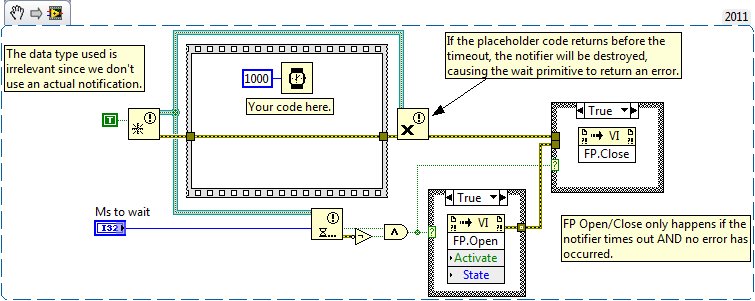
I don't think that's true. Note that although the template today uses primitives that I wrote, older versions of the template existed before I started at NI, so I can't be certain of the intent -- I don't even know where they originated -- but to me, the master/slave pattern is useful because the master may change its mind about the next direction. The slave carries out some order. In the interim, the master may change the next order several times. This occurs during navigation type operations, where additional data is coming in all the time about road hazards, so the information sent to the slave is the master's "best guess for next action", which may be changed frequently. It needs to be sent and updated continuously because the master has no idea when the slave is going to get around to asking for the next instruction. Day trading applications use this pattern, with a master system evaluating the market and multiple slaves responding to "buy this" or "sell that" orders, orders that might be redacted before they are actually acted on. You're missing something bit: Notifiers have an implicit message ID system. The "Preview Queue Element" node will copy the front element of the queue (assuming the queue is not empty) every time the loop repeats. The "Wait For Notification" node will copy the element of the Notifier ONLY if this particular Wait node has not seen this particular notification before. That means that the Notifiers are not only a broadcast mechanism that wakes everyone up when a notification is sent... they are a mechanism that guarantees that each listener is woken up at most one time for that notification. This is covered in the documentation of Notifiers and various other places on the 'net if you want more details. Short version: You cannot effectively build a Notifier out of the Queue primitives without introducing some reentrant wrapper VIs that store state so that each Wait call can remember what message ID it saw last. Even more, you cannot build "Wait For Multiple Notifiers" at all without turning to some sort of polling mechanism inside those reentrant VIs or reaching for the very low level Occurrences and using the less-than-intuitive canonical correct usage pattern for Occurrences that I posted last week. [Later] I went ahead and built the "wait for multiple queues" example because it was such a good example of the purpose of Occurrences. You can see it here.1 point
-
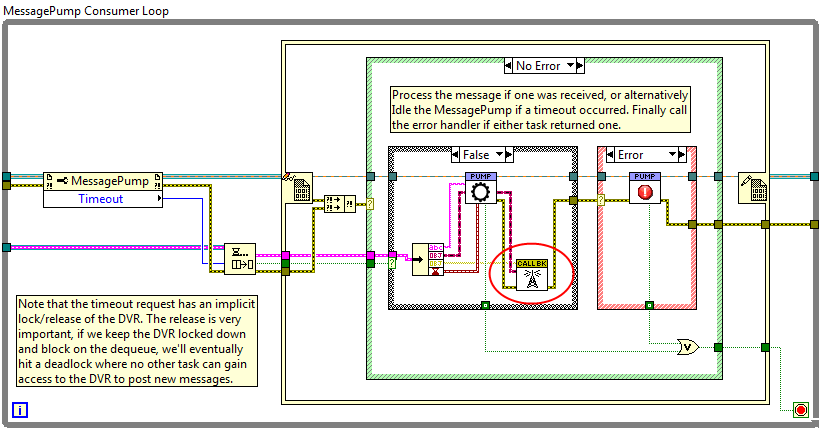
James already commented on this, so I'll repeat what he said in a slightly different way. Broadly speaking there are two ways of sharing a resource among parallel processes: The first is using references. You share the object directly using DVRs, FGs, globals, etc. These are effectively forms of object references. If the "reference" is maintained internally within the class, it is a "by-ref" class. GOOP, G#, and possibly some other frameworks appear to be built around by-ref objects. The other way is to share access to the resource. In other words, have the object executing in it's own process and communicate with it via the messaging transport it exposes. I almost always use a queue, but it depends on the intent of the specific class. The Actor Framework and my coding style are based on this kind of sharing. AQ used the term "handle" for the queue. I'm inclined to stick with that instead of overloading the word "reference." AQ pointed out the difference recently but I don't have the link at hand. Reference objects methods are synchronous and execute in the same thread as the calling code. "Messaging" objects (for lack of a better word) are asynchronous and execute their methods in a separate thread. It's much more event-oriented and a bit of a shift in thinking about how to approach the problem. If I have to share an instrument among parallel processes I'll wrap the instrument class (which is usually a simple wrapper around the manufacturer's api) in a slave loop. I may or may not put the slave loop in a class. The slave loop api--the messages it can act on--is designed according to the amount of detail the calling loops need. Ideally they will only need a couple high-level messages that wrap a bunch of low-level details, but it's not always the case. The loop's error out is wired to ReleaseQueue for sequencing. I don't want to release the queue until the loop exits but since the MessageQueue doesn't propogate through the loop that leaves me with the error wire. I could use a flat sequence (and sometimes do if there's a lot of clean up code) but it's not necessary in this case and just clutters up the diagram. Errors are in a SR because the Dequeue method looks for errors on its error in terminal. When it finds one, instead of dequeuing the next message it packages up the error in an ErrorMessage object and spits it out in a "QueueErrorIn" message. Then the error handler case is just like any other message handler. Some people put an error handler vi inline after the case structure. Nothing wrong with that. I prefer this way because it puts my error handling code on the same level of abstraction as the rest of the message handling code and it gives me a more coherent picture of what the loop is doing. Overall my approach to error handling in slaves may be a little different than what is common. I don't terminate the loop on errors. That's fine for quick prototypes but I don't like it for production code. Unless you're dynamically launching your execution loops, terminating a loop is an unrecoverable error; the app has to be restarted. Good applications will gracefully self-terminate when unrecoverable errors occur rather than let the user unknowingly continue with incomplete functionality, so usually there's a cascading trigger mechanism that stops all the loops when one of them stops. But I find that behavior rather inconvenient during active development. Lots of times I want the execution to continue so I can repro the conditions that cause the error. If the error isn't handled locally in the slave loop it propogates up to its master as a message, which can choose to act on it or pass it up the chain. Eventually someone decides to do something with it. Right now unhandled errors are eventually converted to debug messages containing the source and summary of the error and displayed in an indicator on the fp. Later on in development I might convert that to a stored error log. My slave* loops don't get to decide on their own when to stop. The slave exits only when the master sends it an Exit message. (Exceptions noted below.**) Here's how my apps might respond to a low-level error that requires termination: 1. A terminal error occurs in a low-level slave loop. 2. If necessary the slave puts itself in a safe state, then sends a RequestShutdown message to its master. 3. The RequestShutdown message is propogated up through the app control structure (master-slave links) until it reaches the top of the chain--the Grand Master. 4. If the GM agrees termination is appropriate it sends Exit messages out to its immediate slaves. Those slaves are in turn masters of other slaves, so they copy the message for their slaves. This repeats so all slaves receive the message. The masters do not terminate yet. 5. When a leaf slave (those slaves that are not also masters) receives an Exit message it cleans up after itself and terminates the loop. The final act by any slave loop is to send an Exited message to its master. 6. Once the master receives Exited messages from all its slaves it terminates and sends its own Exited message to its master. Eventually the GM receives exited messages from all its slaves and terminates itself. *[This is my preference. I don't consider it part of the definition of a slave.] **[There are two exceptions to this rule. 1) If the slave's input queue is dead someone else has incorrectly released it. Since it cannot receive an Exit message the slave should terminate itself. 2) If the slave's output queue is dead the master forgot to send the slave an Exit message before terminating. Since nobody is able to listen to the slave's outputs it should terminate itself.] Seems like a lot of extra work, doesn't it? One of my rules for master loops is they do not terminate until all their slaves have terminated. (With the same two exceptions noted above.) This rule grew out of my exploration with Active Objects a couple years back and problems with trying to shut down dynamically launched vis during active development. Eventually I decided most of my requirements were better addressed by statically launched parallel loops, but I kept the master requirement for a couple reasons. 1. It's easy to define a controlled shutdown process, regardless of the reason for the shutdown. 2. During active dev, when a loop doesn't shut down correctly it's fairly easy to find the offending loop. It's the one that didn't send an exit message, and since I can define the UI to be the last thing that terminates I'm not left guessing whether or not the messages were sent. 3. If I want to dynamically instantiate multiple objects at runtime it's dirt simple to convert it to an actor style object. The thing that immediately jumps out at me is you'e wired a MessageQueue constant into the Digitizer Execution Loop. That won't work. You have to use the Create method. I realize you probably did that so you could run the vi, but I wanted to make sure the requirement was clear. Your simulated and custom Digitizer classes inherit from the abstract Digitizer Base class. In general I have discovered abstract base classes tend to get in the way unless you have very specific and well defined reasons for using them. I make better progress by starting with a concrete class. I'd just use the Custom Digitizer class and subclass the Simulated Digitizer from it. Others probably have different opinions. Later on if you need other digitizer classes with very similar behaviors you can make them subclasses of the Custom Digitizer as well. If the other digitizers implement different behaviors you can then subclass them all from a common parent, or create a separate class hierarchy and delegate to the digitizer classes. (I usually like delegation better.) Regarding where to put the Create and Execute vis, creating a DigitizerSlave class too early can slow down development because you're shuffling back and forth between the two block diagrams to make sure all your message names and message types stay synched up. I usually start the slave loop on the same block diagram as the master and push it down into a slave class if the need arises. (Though dynamically launching the execution loop does qualify as "need.")1 point
-
Just because you use a class, doesn't make your program an object oriented design any more than passing a value from one function to another makes it dataflow.1 point
-
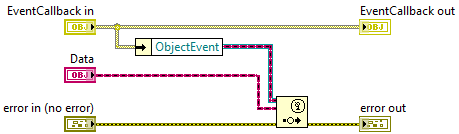
I think this is a good way of doing things. With a mechanism like what you describe, asynchronous message replies become trivial, and you can even implement synchronous messages* in the same framework if you ever need them. In fact I have my own architecture which does pretty much the same thing you have done (don't we all have our own it seems now a days): Any message which is past in is compromised of four things: a message identifier (string), some parameters (LabVIEW Object), an optional parameter to signal a reply with (Callback Object), and an automatically created time stamp. After every message is processed, the operated parameters are passed to the corresponding Callback object's broadcast method (circled in red in the screen shot above). A default Callback Object's broadcast method does nothing, meaning the default configuration for passing message if you don't supply a Callback derived class is to operate in fire and forget mode (pass a message off and don't care about a reply). The magic of using a class for a reply command (or Callback in my language), is that you can extend the reply mechanism to use any type of object, from native LabVIEW synchronization primitives like notifiers, to other messaging architectures. For example, if I want to send replies to a generic user event, I create an EventCallback class and implement the broadcast method as: Using something like that, message replies can pretty much be sent anywhere, to any type of framework object or primitive construct. All of this of course means that the originator of the message needs to know where the message reply is required to be sent to. That doesn't mean that you can't also have the system configured so the message handler decides what to do with a reply, though I don't advise mixing the two. *A word about synchronous messaging (where a message is sent, and the sender blocks until a reply is obtained): Be very careful. Deadlock is very easy if you introduce circular dependencies, I've pretty much learned to avoid any form of synchronous messaging, even though it's easily done with the reply-to mechanism.
 1 point
1 point