

ShaunR
-
Posts
4,942 -
Joined
-
Days Won
308
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by ShaunR
-
-
The insert table writes data only as a string. Please guide me, how can I write the data as real.
If you give me a a specific example of what you mean. Maybe I can help more (but read the link first)
-
I've never found an easy way to do do this programmatically within LV.
I use one of two techniques.
1. Create a function in the DLL called Get_Ver which will return the the dll version and LV version used (I don't use this much any more)
2. When you build the dll, put the LV version in the description section.
It won't help you for the current DLL. But you shouldn't have a problem in the future.
-
sooo... it's kind of a sin to do this in an excercise as simple as this one...
Sin? Noooo.
But this is an interesting one. It will fit on 1 screen. Just do a "Clean Up Diagram" with shorter variable names and you're pretty much there. But that's not the interesting bit

There is a large number of operations that are identical. Identical operations easily be encapsulated into sub-vis. This not only shrinks your diagram, but also segments it into easy to digest chunks of code.
Consider this piece of code....
this is replicated no less that 6 times.
I would be tempted to do something like this :
It achieves several benedits.
1. it is more compact
2. It is easier to identify repeated functions..
3. It reduces wiring errors
4. It gives more control (you can, for example make it a "Subroutine" for faster execution)
5. You can re-use it .
There are many more places within this piece of code where it could benefit from sub-vis. The net result would be that it will probably fit on 1/4 of a screen and be a lot easier to read/maintain.
There are also a few areas that would benefit from "For Loops" too.
-
No, not a touchy-feely post about love amongst mankind, but a philisopical question about access scope. I have two classes: Class1 (contains MethodA) and Class2 (contains MethodB). When I set MethodA's scope to community, and I want to put it on the block diagram of MethodB, I need to make MethodB friends with Class1. Why can't I just make MethodB friends with MethodA?
Because classes aren't very friendly?

I would imagine it's because a class is an entity and you access that entities data through methods and properties by exposing them to a greater or lesser extent (I think of it like a box with buttons and indicators on it). As such your interface boundary is the "class" so you are in fact saying that the Method B should be able to poke a couple of wires behind the buttons and indicators when all Method B can do is press the buttons and read the indicators.
But then again. I usually over-simplify things
 there's probably a more technical explanation.
there's probably a more technical explanation. -
Hi All,
I am using MySql server as my backend for current project. I need to store around five records per second to my database. Is there any way to check for duplicate record present in the databse while inserting the data? Retrieving the complete data and checking it with current record is not a good solution all the time I guess.
Thanks in advance,
Suvin.
You can use "REPLACE" which will "INSERT" if it doesn't exist or, "DELETE" the old record and then "INSERT" if it does.
-
Queues are good for this sort of thing. they give you inherent FIFO sequencing. You can use the "Event" structure to place the controls' refnum on the queue then replicate the changes by emptying the queue.
-
Hi,
I work with a team of very experienced LabVIEW developers, but none of them can answer this question! I seem to remember being able to drag and drop a diagram snippet from the block diagram of a subVI from it's icon.
Imagine you have your function pallet open, and you grab a VI, and instead of its icon being placed, it's the code snippet from its block diagram. Kinda like a template. The VI DOESN'T HAVE A FRONT PANEL!!
Have I simply dreamed this up!? I don't really need this functionality, but I would love to clear my head.

Thanks in advance,
Andrew
Indeed. You can.
When you edit the pallet menus, there is an option (right click on the VI) to "Place Vi Contents". I you create a VI and set this value, the contents of the VI will be placed in the diagram instead of the icon.
lol. JGCode is a faster typist than I
-
I've explored using user events for various things and eventually came to the same conclusion. Setting up user events is kind of a pain, so mostly I just use them to send messages to my fp event handling loop.
Has there been any discussion of revisiting user events and making them easier to work with?
I don't think they are any more painful than, say, queues or notifiers. My only gripe is that there aren't more built-in ones.(but that's something different).
-
For me It's Ok

Hi ShaunR,
Yes that worked fine.

Thanks,
Subhasis
Sweet. I'll update it for the next release.
-
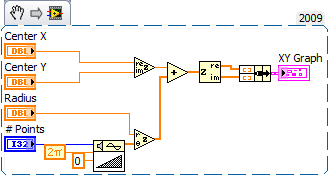
The pi is imaginary!
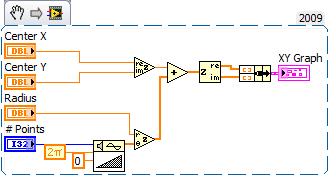
An elegant solution
 . That's going in my snippets draw.
. That's going in my snippets draw.
-
What's wrong with using "File>>Save For Previous Version"?
-
OK.
Definitive answer. Change the "SQLite Read Blob.vi" moveblock call to "LabVIEW" (note the case...it matters!) instead of "labview.exe" or "lvrt"
Let me know if it fixes your issue and I'll add it to the API library.
-
Hi,
I am trying to use the sqlite functions in an executable. DO I need to add something in the installer for this to work successfully?
Please guide me.
Thanks,
Subhasis
It is looking for labview.exe which it can not find, and so the SQLiteRread Blob could not load.
Hmmm. This could potentially be a nasty one
Open the SQLite project and Find "SQLite Read Blob.vi"
Open the "MoveBlock" call library node and change it from "Labview.exe" to "lvrt"
Click "OK"
If it starts to search for the dll, Help it by browsing to your "/program files / national instruments / shared / Labview Run-Time / [your version] directory and selecting "lvrt.dll".
Save the vi and the project.
You should now be able to open your project and build the app. It may ask you again to find the lvrt.dll. If it does, so the same "browse" again as the above.
I can put in a switch to detect the change between run-time and dev, but if its not automagically picking up the run-time dll, this will cause a huge headache in multiple version systems.
I'll look more closely into this, but the above should enable you to build your app until I find a better solution.
-
Maybe we should reserve LVA.org, just in case...

www.ni.info is available
-
@ShaunR
The number of changes is constantly being updated and saved in a shift register. Therefore a value change will not be missed.
You're right. In my quick scan of the examples I assumed that identifying which ones had changed was also a requirement. If it's only the number then it should count them OK.
-
a little suggestion.
I think it could be usefull to add an Order By array input in the select Vi.
You can use the "Order BY" in the where clause.
e.g
Note that you have to have a where statement of some description so you can use RowID>0 to return all rows in a table if you have no "Where" constraint.
-
C/C++, C#, Matlab, Step7, Visual Basic, Python, Indusoft.
@ShaunR; Php can't really replace LabVIEW can it
It beats the cr@p out of Labview for web services

But my response was to the question "what other languages do you use".
-
Would somebody please tell me why i can't convert crossrulez example so that it can work with a 16x14 array?
have you customized the arrays somehow?
I can not figure out what is going wrong.
Because his example only updates and checks when there is a change in data. Your version (without the event case) continuously evaluates the difference between the current and previous values so you miss the change. By the time you press the stop button, the previous and current values are the same (although different from the starting values) therefore you don't detect a difference.
-
I don't think I could live with non G code. I continue to use LV, until some other replaceable solution, preferably open source, came alone.
At ShaunR: Cool, 999 posts
Not any more

-
 1
1
-
-
I meant move the column count out of the while loop.
IC. Yes I tried that and didn't notice much of a change, but then again 3% on 40ms is only about 1ms which is in the noise level. I would have expected more, But it seems DLL call overhead is virtually non existent when set to a subroutine.
You might want to put a note in the documentation on which execution system you're using. I've just been using the same as callers in mine. I haven't really experimented with tuning priorities in LabVIEW.
IF I ever write a manual. I will
If you don't use execution systems and/or priorities, then you are limited to 4 threads (+1 for the UI). I don't think most people worry about it (LV is very good t making things appear to be very multi-threaded), but with very IO oriented asynchronous designs,it improves performance immensely (if used correctly). ThreadConfg.vi is my favourite VI

I didn't find it that to be much of a problem (you would just need to add it to your SQLite_Error VI, and maybe call it a bit more often). It helps a lot with debugging, of course I'm working with raw SQL strings far more often than you are.
I'll keep it in mind for now.
-
I wonder if it is possible to do it the same way they did.
Nope. We've wanted the ability for years(along with control creation at run-time). We got xnodes instead (a compromise).
-
Hi, if Labview went bankrupt. What other alternatives are there to use?? What other languages do you use??
Delphi, PHP, and (when I'm dragged kicking and screaming like a 5 yr old girl being chased by a great white shark
) C/C++ -
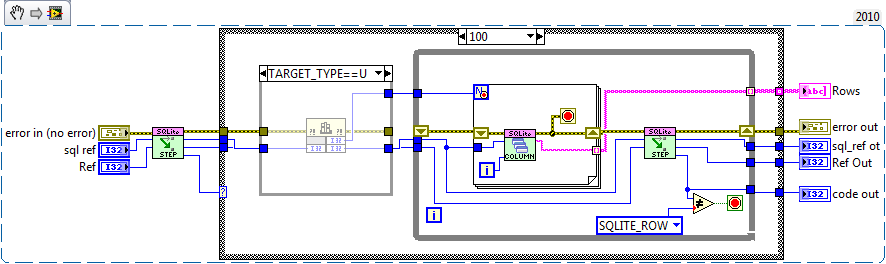
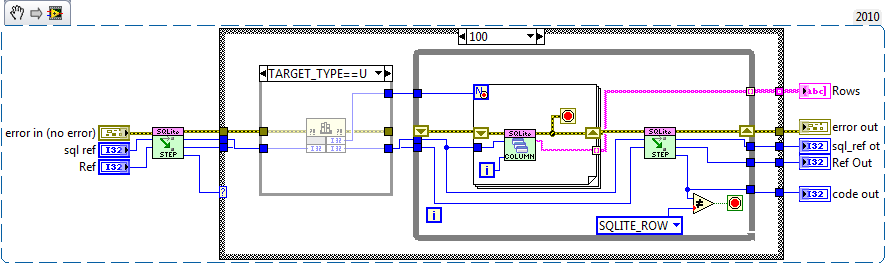
If I modify your fetch all on LV2010 64 on win7 I gain about 13 ms on a select with 100000 records.
Thats about 3% which is hardly worth the effort
(although I'm not sure what you mean by modifying.....in-lining?) If I in-line the VIs I get exactly the same performance for insertions as you. But slightly slower on select (only gaining about 5ms in the 10,000 test)A few more suggestions on your version.
Drop the high priority execution setting, typically disk IO is considered low priority (starving data collection would be bad).
That won't happen. I use a high priority but in a different execution system and therefore force LV to run the queries in a different thread from the users application (assuming the user isn't using the same execution system of course). It basically forces a high priority thread rather than VIs which should mean it gets a higher priority on the scheduler. On my machine I always run with the maximum number of threads (~200) since a lot of my systems use asynchronous tasks at various priorities. This is the way things like VISA work Although I did notice it is set to "Standard" and should be set to "Other 1" (not quite sure how that got changed).
You should support for sqlite3_errmsg in your error handler, since that'll give a much explanation of the error (stuff like table names or which command is misspelled).
I did look at it. But found that I needed to check the error every dll call and extract the string if need be. So I went for passing the error code up the chain and converting it at the end.
You'll probably want update to use binding, since currently you can't update to a blob value.
Indeed. Missed that one.
-
Ah a shame the replace thing doesn't work on all cases. If you want to replace a control, for example, you can only replace it by a other control but not by a constant or indicator. There are some few exceptions however... for example you can replace a constant by a control... this is the result:

xD
You can use the "Toggle" or "Change to Control" properties for this.
http://www.screencast.com/users/Phallanx/folders/Jing/media/6d33f01c-4961-4c88-9944-e3290ab349a0
-
1
-
Performance testing
in LabVIEW General
Posted
Haven't had time to go into all the above.
But have noticed that your bottom loop (dequeue) is free running (0ms between iterations). I get a very stuttery update (just ran it straight out of the box). Changing the time-out (deleting the local and hard-wiring) to, say 100ms, and everything is happy and the dequeue loop updates at 3ms. I imagine there's a shed-load of some time-outs going on which is causing you to miss updates (not sure of the mechanism at the moment)..