

ShaunR
-
Posts
4,940 -
Joined
-
Days Won
308
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by ShaunR
-
-
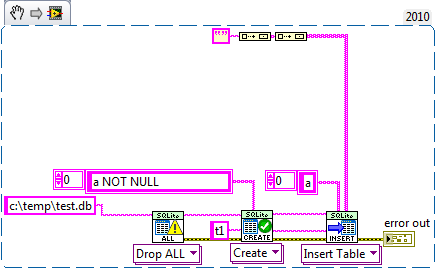
Exactly, without the fix the empty string is bound as a NULL (unless the pointer passed to the dll happens to point to a \00), which fails the constraint. With the fix it get's bound as an empty string and passes the constraint.
I figured out the 2x size 32 bit example slowed down. I had left the speed test front panel open, without the front panel being open it doesn't slow down.
I thought about this a while back.
Labview has no concept of "NULL" string. We can neither create it nor check for it. If we put a string control / constant down, we can only have an empty string (and any of our VIs that accept a string will have a string control).
So the choice becomes do we allow a write to a NOT NULL field to always succeed (which is what will happen with your suggestion) or do we define an empty string in LV as being the equivalent to a NULL string. I think the latter is more useful.
I figured out the 2x size 32 bit example slowed down. I had left the speed test front panel open, without the front panel being open it doesn't slow down.
Good job I cannot take back the rep point eh?

-
 1
1
-
-
Found a bug will optimizing mine that affects yours as well.
If you insert a blank string it'll probably be bound as a NULL.
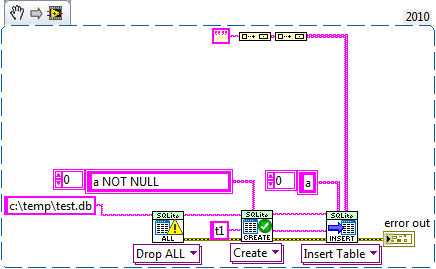
It can be fixed if the empty string passed to sqlite3_bind_text is null terminated (I'm not sure if this is a bug with sqlite or a undocumented feature to allow writing nulls with string binding).
Inserting as a string instead of a byte array also fixes it since LabVIEW will null terminate all strings passed to the CLN.
I get error code 19 with your 1st snippet
Abort due to contraint violation
SQLite_Error.vi:2>SQLite_Bind Execute.vi>SQLite_Insert Table.vi:2>Untitled 1
If the field is not declared with NOT NULL it succeeds.
-
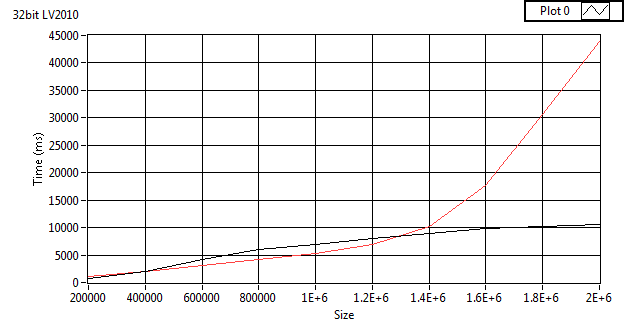
I tried to replicate your result for x32 but couldn't..
Mine is still linear.
Its fairly consistent.
Here's up to 5 million.
-
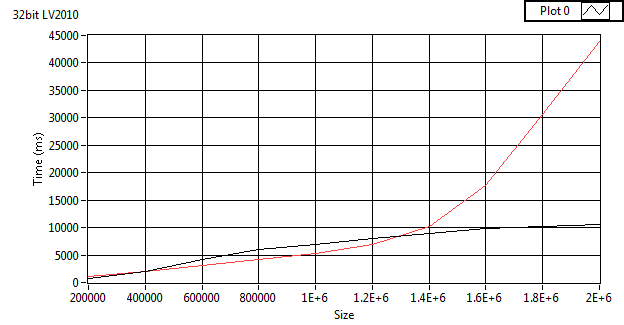
I tried to replicate your result for x32 but couldn't..
Mine is still linear.
-
Time scale in the waveform graph ( waveform Data type) always displays that the data starts from 0. irrespective of the to (time stamp) assigned.
Is this a bug in LabVIEW?
Thanks,
Pandiarajan R
Your graphs' X axis property are set to "Loose Fit".
Loose Fit Property
Short Name: LooseFit
Requires: Base Package
Class: ColorGraphScale Properties
If TRUE, LabVIEW rounds the end markers to a multiple of the increment used for the scale.
-
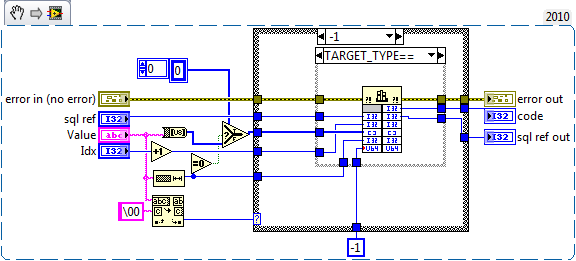
My understanding of the problem is that the bound data isn't read until you step the statement, and labview may unallocate the data passed to the dll by that point (in this case it's reusing the data pointer from null terminated copy for both calls), by passing -1 sqlite makes it's own copy of the data before returning.
The conversion should be free (it's just a static type cast). Passing the array avoids LabVIEW making a null terminated copy, which should speed things up. But you need to be certain LabVIEW doesn't deallocate the memory the string data until after you've stepped the statement. I think the IPE can do that (that's how I interpret it's help entry), but I'm not absolutely certain what the IPE structure does at a low level. Without the IPE (assuming it does make that guarantee), your risking the compiler deallocating it. Different platforms, future versions of LabVIEW, and different optimization cases may break it. I'm using -1 just to be safe. I would suggest you at least use an IPE to be sure the relevant string data is in memory. If you can find documentation that the IPE will always delay deallocation, let me know then I'll switch over mine as well .
Indeed. It was an oversight. It should have been -1. I don't think an IPE is really the way forward as I don't see any performace difference between 0 and -1 (KISS).
The problem is LabVIEW is allocating a array (arrays need a continuous chunk of memory) of string pointers in the while loop autoindex. When that array fills LabVIEW makes a new array larger array and copies the old one into it. The copy is the main cause of the slow down. Now LabVIEW seems to increasing the size of the new array in chunks (at least when the array is large). And since in 64 bit the pointers are twice the size the array needs to be resized and copied twice as often. Since the copies cost depends on how much data is getting copied, this leads problem getting exponentially worse with increasing array size.If I'm correct the size of data elements should not affect when the exponetional error starts showing up, and the 32 bit should look like the 64 bit when reading the twice the number of rows as the 64 bit.
Which is the case.
This can be avoided by growing the array exponentially (for example doubling it's size when filled), but you'd have to code that by hand (and it's slower since I used to do that before I saw the autoindex in yours). You could check if the returned array has reached a size, this say number of columns * number of rows read = 500000 (and half that limit in 64bit), then switch to doing exponentional growth by hand.
I consider it as a Labview limitation rather than the API, In theory they should behave identically regardless of the implementation specifics. Differences between compiling in different IDEs is a little disconcerting since I think we all assume that what works in one will work identically in the other. But it looks like one of those "not a bug. not desired" effects.
But good call. on finding a probable explanation (your C experience obviously shining through). I think it will be rare occasions that anyone will be querying that many records at a time and it is still an order of magnitude faster than other DB implementations (like Access). You never know, they might optimise it in LV 2011 2015.
-
Version 1.2.1 just released.
Upgrading to 1..2.1 is highly recommended to address an issue with bulk inserts on LV x32.
-
You'r correct there is a bug in SQLite_Bind.vi change the 0 on the bottom to -1 and it'll work.
I'll release the next version a little earlier than planned (later today) since it will eradicate this (well spotted). Funnily enough. It only seems to happen on LVx32. x64 is fine.
I must of ran my 32 bit test in 64 bit since the problem no longer shows in 32bit.
I would suggest just binding everything as a string, then you can speed up the binding by not checking for \00 and just inserting the data as if it was there (string length is constant time in LabVIEW but searching for /00 requires checking each byte of the string). Then you just need to add support for reading strings containing \00.
The next release passes an array of bytes to the bind function, which is faster than passing a string even with the conversion to a U8 array. It also removes the aforementioned "bug".
The API already supports reading strings containing \00 (since V1.1). The field just needs to be declared as a blob. I did agonise about making it generic (just involves a direct replacement of "Fetch column" with "Read Blob"), but decided the performance advantage of not using the generic method outweighed the fact that you just have to define a field type.
I'm saying that internally LabVIEW string ARRAYS are an array of pointers to pascal strings. The CLN interface has nothing to do with it.
Well. I don't think that is the issue, since the later tests should have reduced the allocation to a smaller difference and I would have expected the x32 to be more like the x64 - which it isn't. Sufficed to say, there is a difference and, that LV x64 is vastly less efficient at building large arrays of strings than x32 (which I find surprising).
-
The string array is an array of pointers to the individual strings (I wasn't thinking right with my original explanation
 ) so extending the inserted data shouldn't change the performance of the while loop index. The reason the strings need to stored as pointers in an array is because they have unknown lengths. If they where stored in one huge block then to index the array you would have to read all the earlier strings. As an array of pointers you can calculate exactly where the offset is with a single multiplication and addition.
) so extending the inserted data shouldn't change the performance of the while loop index. The reason the strings need to stored as pointers in an array is because they have unknown lengths. If they where stored in one huge block then to index the array you would have to read all the earlier strings. As an array of pointers you can calculate exactly where the offset is with a single multiplication and addition. A little more info here on what I'm talking about
http://en.wikipedia....ide_of_an_array
A lot of LabVIEWs array operations just adjust stride lengths and array pointers which avoids data copies. Off the the top of my head this should include any form of indexing, subset, and reshape array (assuming the new size fits)
I'll try to figure why mine shows the problem in 32bit, since last I checked our implementations of select should be exactly the same on the index memory requirements.
I think you are describing a **char. When I iterate over the rows and columns, I only retrieve a "C String" type (*char), which I then build into a 2D array. The Labview CLN automagically dereferences this to a labview string (i.e it adds the length bytes and truncates at \00). In this sense, it is a pointer to an array of bytes rather than an array of pointers.
-
I found that the speed example also has the same problem. It does not write PASS to the first column. It writes the value in both columns in the DB. Please correct me if I am wrong.
Thanks,
Subhasis
What version of Labview and operating system are you using?
-
My guess is that since each string includes a pointer there is an extra 4bytes for each string in 64bit, and since each string is rather short in this test, the extra 4 bytes makes a significant difference in the memory needs of the different platforms.
That doesn't make a lot of sense to me. Surely pointers are just references to where the data is stored rather than being stored as part of the data.
But I ran the tests again to make sure. This time inserting 500 chars rather than the <10 as before. Everything else is the same apart from taking an average of 5 to cut down the test time.
Pretty much the same. There must be a difference between the memory managers and the way x64 manages allocation. Surprising really. I would expect LVx64 running on a x64 windows platform to outperform a x32 app.
-
I'm not sure if I have time to help track down the issue. My first guess would be with memory allocation. Perhaps on the autoindexing on the while loop (if the allocation size is increased in limited sized chunks instead of exponential growth this could happen). Or maybe memory fragmentation (I'm not sure what algorithm LabVIEWs garbage collection uses, but I doubt it's compacting). The desktop trace tool can be used to check the while loop. Fragmentation would be harder to figure out.
Definitely the former.
If I pre-allocate the array and replace elements rather than auto index, then they perform exactly the same. But what I'm confused by is why there should be a difference between x32 and x64. After all, it should be the same amount of memory being (re)allocated and it is a LV internal implementation.
-
crelf, I disagree with your statement. When I wire a variable to a Sub-VI, upon entry into the Sub-VI the placeholder control that was on the Sub-VI front panel assumes the value of the incoming wire. So if I wire a graph I expected EVERYTHING from the graph to be transferred as well. Now I know that only the DATA are passed to the Sub-VI. IMHO this breaks the concept of passing an object.
I'm guessing you were a C++ programmer in an earlier life (I also suspect you haven't been using LV since 1998 as your profile suggests).
Labview passes data. Not pointers, objects or lemons (unless you specifically tell it too and even then its just smoke and mirrors). All functions in LV are designed to operate on data. It is a data-centric,data-flow paradigm. Moreover it is a "strictly typed", data-centric, data-flow language. When you connect two VI's together, you are passing a value, not an object. When you use a reference, you are also passing a value, however, the property nodes know (by the type) that they need to "look up" and de-reference in order to obtain the data. They are,if you like, a "special" case of data rather than the "norm" and require special functions (property and method nodes) to operate on. If you were to inspect the value of a reference, you would find a a pointer sized Int. However, if you looked at the memory location you would not find your control or indicator or even its data..
-
Hi All,
Can you please help me someone.
I need to preparing a detailed Architecture document for the Lab VIEW Simulator project. Please anyone can share me template that would awesome
Sure.Here are a couple I have have used.
-
OK.
I'm fairly happy with the performance of the API (there are to be a couple more minor tweaks but nothing drastic). So I started to look at SQLites performance. In particular I was interested in how SQLite copes with various numbers of records and whether there is deterioration in performance with increasing numbers of records. Wish I hadn't
Below is a graph of inserts and select queries for 1 to 1,000,000 records.
The test machine is a Core 2 duo running Win 7 x64 using Labview 9 SP1 x32. Each data point is an average over 10 bulk inserts using the "Speed Example.vi". The database file was also deleted before each insert to ensure fragmentation and/or tree searching were not affecting the results.
I think you can see that both inserts and select times are fairly linear in relation to the number. And (IMHO) 5 seconds to read or write a million records (consisting of 2 columns) is pretty nippy

Now the same machine (exactly the same test harness) but using LV2009 SP1 x64
Hmmm.
It's interesting to note. that up until about 100,000; x64 it performs similarly to x32. However, memory usage reported by the windows task manager above 200,000+ shows x64 starts to climb further. Typically by the end of the test x32 has consumed about 450MB whilst x64 is about 850MB when viewed in the windows task manager. Checking SQLites internal memory allocation using the "Memory.VI" yields an identical usage between both tests. However,. LV x64 seems to be using 2x windows memory. I'm tempted to hypothesise that it is memory allocation in LV x64 which is the cause.
Can anyone else reproduce this result? A single check at (say) 500,000 should be sufficient.
-
Reproduced also in LV2009 x32 & x64 (PDS) as well as LV2009 x64 & x32 (PDS)
I also noticed that if you run it before saving (i.e. have modified VI's in memory because I switched from LV x32 to x64) you get the same results. If you then "Save all" it runs ok. However, after invoking the Icon Editor, "Save All" or a re-compile has no effect.
-
I on't think you can write service applications in LV.
But sc.exe serves the same purpose as srvany.exe.
Go to a command prompt and type in
sc.exe create myservice binpath=pathtomyservice DisplayName="mydisplayname"
(of course change myxxxxx with the appropriate names and paths)
-
This was my first post here and I am impressed by the helpfulness and quality of this forum


You smooth talker
-
Hello,
I could not find an answer to this (I tried a search).
I have a main VI with an IntensityGraph with cursors. I want to read and change the positions of the cursors (among other things) in a Sub-VI. The reason for doing that is that the block diagram is already huge and very complicated, so I want to move some of the tasks to a Sub-VI.
So I wire the IntensityGraph to one terminal of the Sub-VI connector. But when I read the cursor position with a Property Node inside the Sub-VI, I get the cursor positions of the "fake" IntensityGraph that I put in the FrontPanel of the Sub-VI, NOT the the cursor positions of the original graph in the main panel that I wired to the connector of the Su-VI.
I hope I made myself clear.
I am miffed by this behavior, which is not how all other "normal" variables behave when you pass them to a Sub-VI.
My workaround now is to extract the cursors' positions in the main VI and pass those in a cluster to the Sub-VI.
Is there a way to do it?
Thanks.
You need to pass the "reference" of the control to the sub VI. By wiring the graph control you are only passing the "data" that the graph contains,
-
I'd offer you my tinfoil hat, but then I'd be exposed to the radiation falling from that missile launch on the west coast last week.
http://www.metacafe.com/watch/1154898/how_to_make_a_tinfoil_hat/
This one's for you guys (via Michael)
<object width="480" height="385"><param name="movie" value="http://www.youtube.com/watch?v=7UAeSsvHhTg?fs=1&hl=en_US"><param'>http://www.youtube.com/watch?v=7UAeSsvHhTg?fs=1&hl=en_US"><param name="allowFullScreen" value="true"><param name="allowscriptaccess" value="always"><embed src="http://www.youtube.com/watch?v=7UAeSsvHhTg?fs=1&hl=en_US" type="application/x-shockwave-flash" allowscriptaccess="always" allowfullscreen="true" width="480" height="385"></object>
I wonder what colour the sky is on her planet
-
Code like this: Caution: Bad code! is very common!
That's fantastic

Just goes to show.
"There are no bad programs, only bad programmers".
I think I'll set that up as my wallpaper....move over Grace Park
-
What is the format of the input for value table in SQLite_insert_Table.vi?
Take a look at the speed example.
-
Thanks for answering my question. I am lucky that the new version just got released.
 . Actually every time I will write data to a new file.
. Actually every time I will write data to a new file. Which function can I use to create a new file.
You do not need to explicitly open or create a file with the any of the high level API (the exception being "Query by ref") as it will open or create a file if one doesn't exist. Just specify the fie name.
Is there any difference between using SQLite as a database and writing to it and using it as a file format and storing data in it? Can the later be done by without using the SQL queries?
I am completely new in this area. So please ignore if my questions sound foolish.
Thanks,
Subhasis
You cannot write directly to the file using standard file write functions. A SQLite file has a complex structure.
-
thanks men.... you are "la hostia"
I don't think I'm that bad
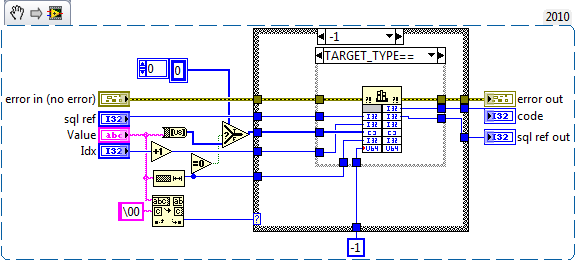
[CR] SQLite API
in Code Repository (Certified)
Posted · Edited by ShaunR
An empty array is slightly different.
Since I use self indexing for loops, the bind never gets executed. However. I've just noticed that the classic problem also occurs. The sql ref and the DB ref are passed as "0" to the Bind Clear meaning they never get freed. Whilst his is obviously undesirable, I would have expected SQLite to return a "Misuse" error. It doesn't Instead error 1097 occurs which isn't good (possible crash under the right conditions). I will put some defensive code around this
Instead error 1097 occurs which isn't good (possible crash under the right conditions). I will put some defensive code around this
So inadvertently you have uncovered a bug, although not the original one