

ShaunR
-
Posts
4,937 -
Joined
-
Days Won
305
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by ShaunR
-
-
At my company, we don't get administrative rights to our office computers (fortunately, this does not apply to our laboratory machines, YET). Anyway, when I install software on my office machine, I have to call IT, who can remotely log in to my computer and temporarily elevate my account to administrative rights so I can do my own installs. It used to be that they would elevate rights then leave you alone and trust you to reboot to return to standard user rights.
But my last install, I was informed that they would have to stay remotely logged in to watch my actions to make sure I wasn't doing something bad. When I informed them that the NI installs take hours (4+ in the this case), there was dead silence on the other end. They very quickly developed a new procedure where they can grant exemptions to the new rule.
Yup. I had a similar experience. At my old firm IT insisted that the had to install everything. I gave them a list of Labview and all the packages I needed and went and played with some instruments. After an hour they called me back to say it was complete. Great
 Where are the toolkits/packages? Umm. how do you install them (they said). So I showed them.
Where are the toolkits/packages? Umm. how do you install them (they said). So I showed them.After a few hours of sitting watching the install and drinking copious amounts of coffee the IT uy said "OK I'm off home". I said "When you come in tomorrow you need to phone NI and get all the activation codes (license was in ITs name). See you tomorrow so we can activate them all. Oh and by the way, we need to do this all again forl 8.2, 7.1 and 6.0 Can we do that the day after?"
Next morning I had local admin rights and they transferred the license into my name

-
SQLite API Version 1.2 released.
-
 1
1
-
-
Grab a good Russian novel with that sleeping bag. I typically start that sort of thing before I go home for the night.
Tim
Indeed.You will still have plenty of time to learn Russian so you can read it
-
I have to do a complete uninstall and reinstall of my LV 2009 and DSC module. No problem. I'm surprised it's lasted this long without any corruption issues considering how hard I've been hammering it.

I inherited this system and the guy who installed the software installed EVERYTHING. EVERYTHING. After selecting EVERYTHING NI in Add or Remove it told me I had 567
 programs to uninstall. Now I'm on 17 of 567. I started almost an hour ago. A couple of questions:
programs to uninstall. Now I'm on 17 of 567. I started almost an hour ago. A couple of questions:How long will this take? Do I need to go home and bring back a sleeping bag and an overnight bag?
After this and msiblast is there anything else I need to do before I consider this time well spent and I can install a fresh copy of 2009?
Thanks in advance.
I hope your machine is networked to the internet. Mine isn't and after an install I have to hand type in 23 activation codes
 It's all got a bit ridiculous
It's all got a bit ridiculous 
-
SQLite shows a download size of 4.8 MB. But the latest upload is only 1.8 MB. It looks like its the sum of all the versions.
Is that right?
The download page is geared towards showing information about a particular version (file name, version number, page title etc). Shouldn't it only show the size and download speed of the latest version?
-
Hi,
I have just started to use SQLite. I downloaded this toolkit and inserted data to a database using the insert function. But it seemed to be too slow. Is there any functionality in the toolkit, where i can do bulk insert into the db. I have never used any db before. So, I don t know about how fast it could be.
My application requires me to write 500 rows and 5 columns of data into one table and about 5 rows and 2 columns into another table in less than 500 milliseconds. Can I do this using bulk insert. Or is there any other way to do this.
Thanks in advance,
Subhasis
If you are using Version 1.1, then you can use the "Transaction Query.vi" as JCarmody referenced.
If you are using version 1.2 (just uploaded so unlikely
 ) then you can use the "Insert Table.vi"
) then you can use the "Insert Table.vi"  or "Transaction Query.vi".
or "Transaction Query.vi".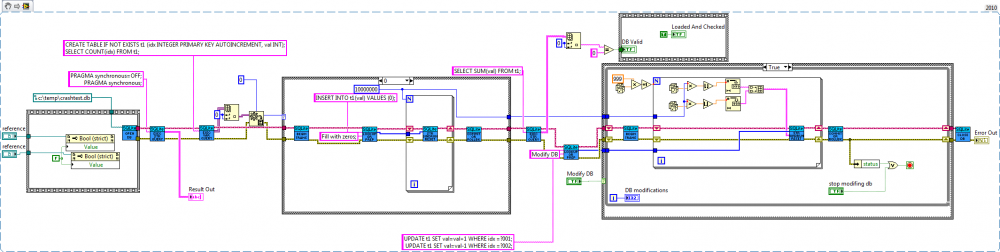
PLEASE at absolute bare minimal put an easy to find warning about how their data is not safe by default, unlike normal SQLite, and how to fix it.
Well. I cannot replicate your test because you haven't released the VIs. But I ran the speed test inserting 1,000,000 rows with version 1.2 and reset the PC. After 12 resets the DB was fine although Labview forgot all its palette settings on the 3rd reset
 . At that point I got bored since it takes about 1 minute for my PC to boot
. At that point I got bored since it takes about 1 minute for my PC to boot 
-
I'd like to see a native "HTML" string control

-
-
I guess it depends on the XCode and OS version you are using. There is an option to tell XCode to build for all format (i386,x64 and PPC)
You may also links against various OS version. I usually do build for 10.5 SDK.
Yup. Still trying to get my head around all the compiler options (haven't even looked at linker stuff yet). Some compile, some don't.
Bitness? unless you have installed the SDK for 10.4 you should not have a bitness issue.
I've got them all installed
 I'm trying to compile against 10.4, 10.5, 10.6. Sometimes they won't compile at all depending on certain settings. I need to be able to figure out the minimum version since I won't have the luxury of just getting it to work on my system alone (looks like I'll have to install a few more Mac versions)
I'm trying to compile against 10.4, 10.5, 10.6. Sometimes they won't compile at all depending on certain settings. I need to be able to figure out the minimum version since I won't have the luxury of just getting it to work on my system alone (looks like I'll have to install a few more Mac versions)The wrapper was needed since I (ok the OS) dynamically call the built in OSX version of sqlite using the -lsqlite3 in the linker flag. I had to rename calls to avoid conflict.
This limit will go away if you compile the source for sqlite3.
Indeed. I'm in two minds about this. I would like to compile from source. But at the moment the debug is 5MB and a release is 2.4MB

There are many to play with. I'm far for mastering all of them....
I'm looking forward to see it
Chris
Xcode is not very intuitive and as soon as I figure out how and what it's doing..... will ditch it in favour of something else. In theory, we shouldn't need it at all since the Mac version of SQLite has all the scripts etc to build and install it.But I don't know what half the files are for (yet). It's a steep learning curve having never used a Mac before (just finding stuff takes me 1/2 an hour...lol). But getting there

-
I've used Inno Setup for a number of years now. Again its free. Very, very powerful and creates very compact intalls (typicaly 1/2 the size of msi).
In it raw form its almost unusable, but with this or this GUI its very sraight forward.
-
The order of writes to the hard drive is determined by what how the OSes elevator algorithm wants to sort the write requests in the write cache. The hard drive can also reorder things when they reach its cache. The application order determines when things are put into the cache. From the perspective of the programmer it appears that it happens in order, since the OS keeps the read cache directly in sync with the write cache.
Here's the best description I've found online of some of issues.
That is an interesting article. But it is very Linux oriented (in particular XSF and changes between kernel versions). I don't know much about Linux file systems. But I do know NTFS does not suffer from this and the only currently supported OSs are windows.
My example code was an attempt at illustrating what happens at the hard drive level (it's not real code, but LabVIEW seemed an good choice for showing order of operation issues). Basically that the implicit order of the application doesn't apply at the hard drive level. But you can enforce an ordering with write barriers (fsync). I was mistaken about needing two files for there to be a problem, since a transaction in sqlite involves more than write request to the journal, and can easily take more than one the database file (so it's worse than I said). After looking more into it, I think that, with synchronous off, database corruption is quite likely if there's an OS/Hardware failure during a write.
"fsync" and "write barriers" are not the same thing. The latter is a firmware feature and the former is an OS function. Admittedly, on some OSs (read Linux) you can turn it on or off. But you cannot under Windows (I don't think).
Anyway if synchronous=off, on journaled filesystem was safe, you would think somewhere on the sqlite website (or mailing list) someone would mention the safe easy way to drastically improve speed on virtually all modern desktops, workstations and servers.
That depends. If the programmers are mainly non-windows programmers,then they may not mention it since they use a "cover-all" statements. After all. If they were wanted NTFS to be "utra-robust" and were worried about ll this. then they could have used "CreateFile" with the "FILE_FLAG_NO_BUFFERING" and "FILE_FLAG_WRITE_THROUGH" options. then they would not need "FlushFileBuffers" and not have the overhead associated with it..
Also if you really don't want to believe me about the reordering. NTFS only journals the metadata, not application data. In other words the file systems structure is safe from a crash but not files being written to it.
http://en.wikipedia....i/NTFS#NTFS_Log
As does EXT3 by default (ordered)
http://en.wikipedia....urnaling_levels
Although in EXT3 appened and making new files is as safe as the full data journal mode (I don't know if this also applies to ntfs). But SQLite often writes in the middle of the file.
In other words synchronous off is a very bad default setting.
Your making a bit of a meal out of this.
 There are better ways to ensure data-integrity if the data is that important. Don't forget. I'm not "removing" the functionality. If you really feel strongly about it then you can just turn it on. Although I suspect you will never use the API since it is natural to prefer your own in-house solution.
There are better ways to ensure data-integrity if the data is that important. Don't forget. I'm not "removing" the functionality. If you really feel strongly about it then you can just turn it on. Although I suspect you will never use the API since it is natural to prefer your own in-house solution. -
Fantastic.
Many, Many thanks. I really appreciate it.

You examples didn't work straight out of the box. But I re-compiled the framework with i386 rather than x64 and labVew now accepts it and I can run your dll verson vi.
I found another framework that Labview could load in the /development/frameworks. There are 3 examples located in there. 1 I can load. the others I cannot. After getting yours to work it it must be due to the bitness (although I'm not sure how to check).
Thanks to your example, I've compiled a framework with sqlite 3.7.3 successfully (lots of warnings though) and your re-hashes of my low-level VIs seem fine. I have a rough idea how things fit together now and I think I should be able to compile a framework without the intermediary LV_SQlite wrapper.
Looks like I'm going to be very unsociable tomorrow whilst I play with the Xcode settings
I'll let you know how I get on later in the week. Muchos Grassy Arse
-
I'm talking about the ordering between multiple files not a single file. The write cache handles single files just fine.
The order is pretty much dictated by the way the application is written and has little to do with the cache. A file is opened when you instruct the OS to open it. If you write an application as in your second example, then sure, you cannot guarantee the order because you cannot guarantee the order that Labview will execute those functions.
My point was I'm not sure if a lose of power with fsyncing will necessarily lead to a detectable corruption (I think it would catch some if not the majority of cases). Just because the structure is valid doesn't mean the data returned is correct.
Well. Assuming that corruption is going to happen (which I obviously don't agree with....at least on windows) then probably you are right. But it would be far worse to for the structure to be corrupted therefore not enabling retrieval of any information.
While browsing the sqlite source I found
**...Transactions still work if synchronous is off,
** and the database cannot be corrupted if this program
** crashes. But if the operating system crashes or there is
** an abrupt power failure when synchronous is off, the database
** could be left in an inconsistent and unrecoverable state.
** Synchronous is on by default so database corruption is not
** normally a worry.
Indeed. But as I said before. I believe the latter to only be relevant on non-journalled systems. Don't forget that SQLite is applicable for many OSs that do not have such a file system.
I was thinking that those three should be put in their own folder (being the only ones outside of the main api that I could see someone using).
I think there are very few instances (perhaps the savepoints or an in-memory database) where people will need/want to use them. Those that do would quickly see the way forward with an example or two. The "query by ref" is already in the "Query" polymorphic VI and I think fitting for that function.
-
One page is best, but an example of when this can be hard/impossible is with ActiveX/dotNET/Reference-y-type calls with wide nodes.
In this case, as long as you only have to scroll in one direction, thats ok IMO.
well. ActiveX and dotNET are banned in my applications
-
Without syncing there is no guarantee that sqlite's journal file is written to disk before it's database file. The write buffer isn't a FIFO, it reorders to optimize bandwidth (the harddrive cache may also reorder things).
(LAVAG keeps erroring when I try to link urls so I have to type them out) http://en.wikipedia.org/wiki/NCQ
The OSes journal is an exception since it can adjust the buffers order (or use some kind of IO write barrier).
http://en.wikipedia....i/Write_barrier
As far as the OS is concerned sqlite's journal is just a file like the database.
Indeed. The OS does see the journal file as just a file (it couldn't see it any other way). But I think we would all be in trouble if we couldn't rely on the OS to write files in a certain order. Imagine overwriting a value in a text file. I don't think it would be very useful if we couldn't guarantee that the second value we wrote wasn't the final value.
I just hex edited a string saved in sqlite database, it still passes the integrity check, a crc would catch this kind of corruption. The question is whether it's catches errors caused during crashes with sync turned off (my guess is it gets some but not all).
I think "integrity_check" is designed to detect database structure corruption. Have you tried to change a non-data byte?
Try it yourself.Ahhh. You have to be careful here. You are using "stream" functions which are memory resident. SQLite (quite sensibly) uses "WriteFile". Additionally. It uses "WriteFile" in non-overlapped mode.
Try this instead.
#include <windows.h>#include <stdio.h>int main ( void ){ HANDLE out = CreateFile ( "test.txt", FILE_WRITE_DATA, 0, NULL, CREATE_ALWAYS, FILE_ATTRIBUTE_NORMAL, NULL ); char s[50]; int i,n;DWORD l; for (int i=0; i<10000; i++){ n=sprintf (s, "%d\n", i); WriteFile ( out, s, n, &l, NULL ); } int *nullptr = 0; *nullptr=1; //crash before closing CloseHandle ( out ); return 0;}In the documentation for WriteFile it states:
If lpOverlapped is NULL, the write operation starts at the current file position and WriteFile does not return until the operation is complete, and the system updates the file pointer before WriteFile returns.So it is a proper hand-off to the OS unlike the stream functions.
One way of doing my example without save points is to have the subvi's concatenate strings into a query that is run separately (this work around can't replace savepoints in all cases though).
Savepoints are easy for users to implement as long as there's an easy way to keep the database connection open between different calls. A midlevel api might work well in your case just something that handles preparing, stepping and column reading. The low level open and close vis and can be raised to the mid level api.
Indeed. As I said previously. "Query By Ref" is synonymous to "exec". So all you need is "Open", "Query By Ref" and "close". There is no need for an intermediate layer since the high level API is just a wrapper around the query functions. (In fact "Query Transaction" uses Query By Ref"). So. Nothing is precluded. Its just deciding what should be elevated to the higher levels.
-
The world is simply a better place when your vi fits on one screen.

Amen !
There is no excuse for it not to.
-
* If LabVIEW isn't open, Open Apllication Ref is returning an error. Is there a more elegant way of starting LabVIEW than using System Exec?
That's the only way as far as I know.
* How can I bring the LabVIEW.exe (or the opend vi's) to the front? Application.BringToFront didn't work (without error). Currently The opened vi's are behind my merge.exe and the hg repro browser.
You'll have to use OS specific calls such as "BringWindowToTop" if you are outside the LV environment.
-
I think the problem is that journal only maintains consistency (well not quite) on a single file while sqlite needs two files to be consistent with each other. Without syncing (which acts as a write barrier) the data may be written to the database before modifying sqlites journal. Now the OSes journal can be protected from that (since the OS can control the write buffer) but SQLite doesn't have such a protection. I'm curious how SQLite would perform if it used Transactional NTFS instead of syncs and an on disk journal.
The journal (either SQlites or the File systems) is always written to before any updates to the actual file(s) and the transaction is removed after the completion of that operation. In the event that something goes wrong. The journal is "replayed" on restart, therefore any transactions (or partial transactions) still persisting will be completed when the system recovers. The highest risk area is that a transaction is written to the DB but not removed from the journal (since if it exists in the journal it is assumed to be not actioned). In this case, when it is "replayed" it will either succeed (it never completed) or fail silently (it completed but never updated the journal). This is the whole point behind journalling. In this respect, the SQLite DB is only dependent on the SQLite journal for integrity. The OS will ensure the integrity of SQLites journal. And SQLite "should" ensure the integrity of the DB.
However. If the file system does not support journalling. then you are in a whole world of hurt if there is a power failure (you cannot guarantee the journal is not corrupt and if it is, this may also corrupt the DB when it is "replayed"). Then it is essential that SQLite ensures every transaction is written atomically.
That would be doable but the tricky part would be determining which is corrupt. The easy solution of storing the check sum of the database in another file suffers from the same out of ordering you can get without fsyncing (ie both databases are modified before the check sum is actually written to the disk). I'm unsure if pragma intergrity_check can catch all problems.
It ( intergrity_check) would be pretty useless if it didn't. I think it is fairly comprehensive (much more so than just a crc) since it will return the page, cell and reference that is corrupted. What you do with his info though is very unclear. I would quite happily use it.
I check that the number of input values is equal to the largest number of parameters used by a single statement. So all binding's must be overwritten in my API. The single question mark is confusing for multistatement queries. I could make an interface for named parameters (the low level part of my api exposes the functions if the user really wanted to use them). But I decided against it since I didn't think the lose in performance was worth the the extra dll calls and variable lookups. But named variable may be faster in some corner cases since my code will bind parameters that aren't used, but it's easy to minimize the impact of that (by optimizing the order of the parameters).
I could not detect any difference in performance between any of the varieties.There are no extra DLL calls (you just use the different syntax) or lookups (its all handled internally) and, as I said previously, it is persistent (like triggers). Therefore you don't need to ensure that you clear the bindings and you don't have to manage the number of bindings. It's really quite sweet
In my high level API, I now link to variable name to the column name (since the column name(s) must be specified).I just see composability to be a key feature of database interaction.
You'll probably want logging to be synced at least (a log of crash isn't useful use if the important piece never reaches the disk).
I think here you are talking about an application crash rather than a disk crash. If the disk crashes (or the power disappears), its fairly obvious what when and why it happened. For an application crash, the fsync (flushfilebuffers?) is irrelevant.
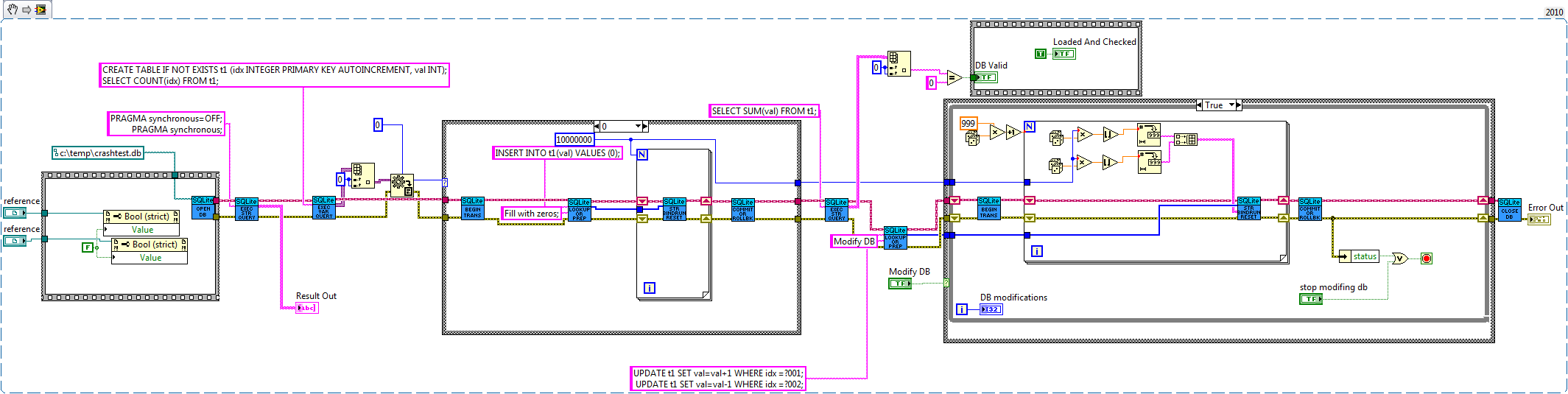
How about a bank example. Lets say you're writing a database for a bank. So we need a table for bank customers and how much money they have, and a second table for logging all the interactions on different accounts (so we can make bank statements). The following code is just hacked together for example so there likely are bugs in it.
We have three sub vis for our API, create customer, withdrawal and deposit. Now withdrawal subtracts money from the account and logs the withdrawal, and deposit does the same but increases the amount instead of decreasing. We want to make sure the logs match the amounts so we'll wrap all the changes in savepoints.
As for why this is useful consider what happens if I need to change the withdraw (maybe take cash from a credit account if it goes below 0 instead). Or I want the ability to lock an account (so no changes in balance). What happens if there are multiple connections to the database. If I wasn't in a transaction in the transfer the receipt account could be locked before the money is deposited which would error then I'd have to write code to undo my withdraw (now what do I do if that account get's locked before I can deposit it back). If I wanted to setup a automatic bill pay I could use the transfer vi in an automated billpay vi. In short savepoints allow for programmer to avoid code duplication by allowing composability of transactions.
Excellent example.
The more I think about this. The more I think it is really for power users. My API doesn't prevent you (the user) from using save-points with the low level functions, after all it's just a SQL statement before and after (like begin and end). However. It does require quite a bit of thought about the nesting since a "rollback To" in an inner statement will cancel intervening savepoints so you can go up, down and jump around the savepoint stack.
In terms of bringing this out into the high level APIs. I think it wouldn't be very intuitive and would essentially end up being like the "BEGIN..COMMIT" without the flexibility and true power of savepoints. Maybe a better way forward would be to provide an "Example" of savepoints using the low level functions.
-
1
-
-
Or you can use "vi.lib\Utility\config.llb\Escape String.vi" and "vi.lib\Utility\config.llb\Unescape String.vi" which are pretty good for dealing with these things (Although I believe I had to add something to deal with spave character '/20')
//Martin
Indeed. But if you know there are only a couple of escaped chars; then the above example is much faster.
-
I don't think it's *humanly* possible to have quite as good of a b-day as Penrod's was.

Oh I don't know. Depends on what they put in your drinks
-
I agree with Paul G. Sounds like it isn't really a text file (which is what the read spreadsheet is for).
Although.To answer your other question about getting rid if \## values.....
These are non-printable ascii values.
Use the "search and replace string" primitive and right-click on it to select "regular expression". Then create a "search" string. Right click on it to select "\" codes display.
Then you can use a string like [\04\12\14]+ to scan and remove the non-printable characters.
-
ok, i built this thing....
thanks a lot to the devil guy with the black eyebrows..
Sweet.
You could also make it a little more user friendly by causing the focus to go back to the input box so the user doesn't have to click on it after pressing a button and linking the "+" and "=" buttons to the keyboard
-
Can you dynamically register for the "Close Panel?" event on every VI in memory? Put up a poll for "all VIs in memory" that runs every 1/2 second or so and register for the "close panel?" event. I don't know how well that would work but it seems like something you haven't tried yet.
I think the target VI would have to be running to be able to hook that event.
-
Sorry, I meant, removed compiled code from VIs.
Darn..., to be clear the VIs posted at bitbucket should have the blockdiagrams present!
The world of SCC now gives me the power to get the latest version -1, remove the compiled code and recheck in.
EDIT:And if I really had removed the code, you could always get a version earlier.
Ton
Ooooh. Excited again
I'll be able to get my Twitter logger up and running once more
Nice work. Just need to remove the ogk stuff
[CR] SQLite API
in Code Repository (Certified)
Posted
You could have just used the "Query.vi" and put in "SELECT DISTINCT Col1,Col2,Col3 FROM TableName;" then you wouldn't need to filter the results.