

ShaunR
-
Posts
5,022 -
Joined
-
Days Won
312
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by ShaunR
-
-
The world is simply a better place when your vi fits on one screen.

Amen !
There is no excuse for it not to.
-
* If LabVIEW isn't open, Open Apllication Ref is returning an error. Is there a more elegant way of starting LabVIEW than using System Exec?
That's the only way as far as I know.
* How can I bring the LabVIEW.exe (or the opend vi's) to the front? Application.BringToFront didn't work (without error). Currently The opened vi's are behind my merge.exe and the hg repro browser.
You'll have to use OS specific calls such as "BringWindowToTop" if you are outside the LV environment.
-
I think the problem is that journal only maintains consistency (well not quite) on a single file while sqlite needs two files to be consistent with each other. Without syncing (which acts as a write barrier) the data may be written to the database before modifying sqlites journal. Now the OSes journal can be protected from that (since the OS can control the write buffer) but SQLite doesn't have such a protection. I'm curious how SQLite would perform if it used Transactional NTFS instead of syncs and an on disk journal.
The journal (either SQlites or the File systems) is always written to before any updates to the actual file(s) and the transaction is removed after the completion of that operation. In the event that something goes wrong. The journal is "replayed" on restart, therefore any transactions (or partial transactions) still persisting will be completed when the system recovers. The highest risk area is that a transaction is written to the DB but not removed from the journal (since if it exists in the journal it is assumed to be not actioned). In this case, when it is "replayed" it will either succeed (it never completed) or fail silently (it completed but never updated the journal). This is the whole point behind journalling. In this respect, the SQLite DB is only dependent on the SQLite journal for integrity. The OS will ensure the integrity of SQLites journal. And SQLite "should" ensure the integrity of the DB.
However. If the file system does not support journalling. then you are in a whole world of hurt if there is a power failure (you cannot guarantee the journal is not corrupt and if it is, this may also corrupt the DB when it is "replayed"). Then it is essential that SQLite ensures every transaction is written atomically.
That would be doable but the tricky part would be determining which is corrupt. The easy solution of storing the check sum of the database in another file suffers from the same out of ordering you can get without fsyncing (ie both databases are modified before the check sum is actually written to the disk). I'm unsure if pragma intergrity_check can catch all problems.
It ( intergrity_check) would be pretty useless if it didn't. I think it is fairly comprehensive (much more so than just a crc) since it will return the page, cell and reference that is corrupted. What you do with his info though is very unclear. I would quite happily use it.
I check that the number of input values is equal to the largest number of parameters used by a single statement. So all binding's must be overwritten in my API. The single question mark is confusing for multistatement queries. I could make an interface for named parameters (the low level part of my api exposes the functions if the user really wanted to use them). But I decided against it since I didn't think the lose in performance was worth the the extra dll calls and variable lookups. But named variable may be faster in some corner cases since my code will bind parameters that aren't used, but it's easy to minimize the impact of that (by optimizing the order of the parameters).
I could not detect any difference in performance between any of the varieties.There are no extra DLL calls (you just use the different syntax) or lookups (its all handled internally) and, as I said previously, it is persistent (like triggers). Therefore you don't need to ensure that you clear the bindings and you don't have to manage the number of bindings. It's really quite sweet
 In my high level API, I now link to variable name to the column name (since the column name(s) must be specified).
In my high level API, I now link to variable name to the column name (since the column name(s) must be specified).I just see composability to be a key feature of database interaction.
You'll probably want logging to be synced at least (a log of crash isn't useful use if the important piece never reaches the disk).
I think here you are talking about an application crash rather than a disk crash. If the disk crashes (or the power disappears), its fairly obvious what when and why it happened. For an application crash, the fsync (flushfilebuffers?) is irrelevant.
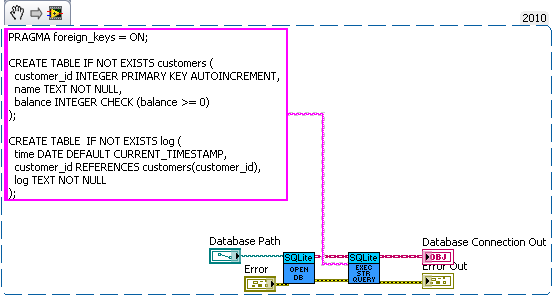
How about a bank example. Lets say you're writing a database for a bank. So we need a table for bank customers and how much money they have, and a second table for logging all the interactions on different accounts (so we can make bank statements). The following code is just hacked together for example so there likely are bugs in it.
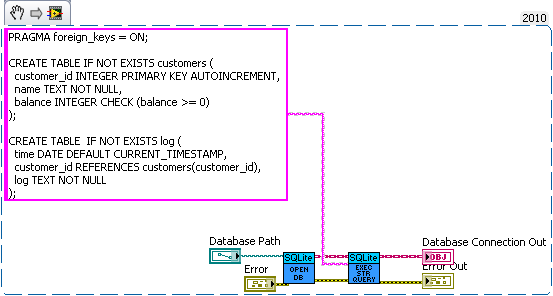
We have three sub vis for our API, create customer, withdrawal and deposit. Now withdrawal subtracts money from the account and logs the withdrawal, and deposit does the same but increases the amount instead of decreasing. We want to make sure the logs match the amounts so we'll wrap all the changes in savepoints.
As for why this is useful consider what happens if I need to change the withdraw (maybe take cash from a credit account if it goes below 0 instead). Or I want the ability to lock an account (so no changes in balance). What happens if there are multiple connections to the database. If I wasn't in a transaction in the transfer the receipt account could be locked before the money is deposited which would error then I'd have to write code to undo my withdraw (now what do I do if that account get's locked before I can deposit it back). If I wanted to setup a automatic bill pay I could use the transfer vi in an automated billpay vi. In short savepoints allow for programmer to avoid code duplication by allowing composability of transactions.
Excellent example.

The more I think about this. The more I think it is really for power users. My API doesn't prevent you (the user) from using save-points with the low level functions, after all it's just a SQL statement before and after (like begin and end). However. It does require quite a bit of thought about the nesting since a "rollback To" in an inner statement will cancel intervening savepoints so you can go up, down and jump around the savepoint stack.
In terms of bringing this out into the high level APIs. I think it wouldn't be very intuitive and would essentially end up being like the "BEGIN..COMMIT" without the flexibility and true power of savepoints. Maybe a better way forward would be to provide an "Example" of savepoints using the low level functions.
-
 1
1
-
-
Or you can use "vi.lib\Utility\config.llb\Escape String.vi" and "vi.lib\Utility\config.llb\Unescape String.vi" which are pretty good for dealing with these things (Although I believe I had to add something to deal with spave character '/20')
//Martin
Indeed. But if you know there are only a couple of escaped chars; then the above example is much faster.
-
I don't think it's *humanly* possible to have quite as good of a b-day as Penrod's was.

Oh I don't know. Depends on what they put in your drinks

-
I agree with Paul G. Sounds like it isn't really a text file (which is what the read spreadsheet is for).
Although.To answer your other question about getting rid if \## values.....
These are non-printable ascii values.
Use the "search and replace string" primitive and right-click on it to select "regular expression". Then create a "search" string. Right click on it to select "\" codes display.
Then you can use a string like [\04\12\14]+ to scan and remove the non-printable characters.
-
ok, i built this thing....
thanks a lot to the devil guy with the black eyebrows..
Sweet.
You could also make it a little more user friendly by causing the focus to go back to the input box so the user doesn't have to click on it after pressing a button and linking the "+" and "=" buttons to the keyboard

-
Can you dynamically register for the "Close Panel?" event on every VI in memory? Put up a poll for "all VIs in memory" that runs every 1/2 second or so and register for the "close panel?" event. I don't know how well that would work but it seems like something you haven't tried yet.
I think the target VI would have to be running to be able to hook that event.
-
Sorry, I meant, removed compiled code from VIs.
Darn..., to be clear the VIs posted at bitbucket should have the blockdiagrams present!
The world of SCC now gives me the power to get the latest version -1, remove the compiled code and recheck in.
EDIT:And if I really had removed the code, you could always get a version earlier.
Ton
Ooooh. Excited again
I'll be able to get my Twitter logger up and running once more
Nice work. Just need to remove the ogk stuff
-
> I too thought about using the pre-installed SQLite. But I'm not sure that I can guarantee that it will be 32 bit if the Mac starts in 64 bit mode. A wrapper is not a useful way forward as it requires upkeep of other code than Labview and > would require a lot of work re-implementing an interface which is already there. A windows wrapper went this route and its limited because of this.
> From my limited reading of the "framework" implementation its a bit like a fat arch. So does that mean I can compile a 32 bit and 64 bit and include both in the framework? Does the pre-installed SQLite have both 32 bit and 64 bit
> and switch transparently? Do I really have to type in each and every function rather than select it from the LV combo-box?
XCode will generate 32/64bit framework. I did not check it but I'm pretty sure the dylib is 32/64 bit. Anyway LV on the Mac is still 32 bit.....
And yes you will have to reselect the correct the lib and function name in you CLN. You could specify the lib name as a parameter of the CLN instead.
> (And does that mean I select the ". framework" instead of the dylib?) There seems to be little information on > the net for Mac developers.
Yes select "YourSQLite3.framework" in the CLN. Be carefull since LV does not unload it, you have to quit LV to load a new version!
> I will have a play with Xcode. I know its installed but not sure where to find it (doesn't show up under applications).
Its in /Developer/ or you may need to download the latest version from Apple.
> I've only just learnt to use CodeBlocks so naively though it would just be a case of re-compiling for the Mac (its also > available for the Mac)
It should work as long as it is able to generate frameworks.
ChS
OK. So I think you are saying that frameworks are the key and there's no such thing as a dylib in isolation (at least as far as Labview is concerned).
The problem I've come up against now is that I haven't been able to load ANY frameworks with Labview. Even those already installed with the Mac.
I managed to find the SQLite framework (its under TCL). Couldn't load that, maybe because its is compiled with the TCL interface (usual "not a valid library" error). I'm not familiar with TCL so don't know if that's the issue or just the fact that I cannot load frameworks full stop.
Bit of a newbies question. But.........
I can create a bare-bones framework structure using Xcode. And I can create a dylib with Codeblocks. I can also get it to copy the dylib to the framework. But under what do I add it to? Resources? Target? The framework seems geared towards distribution of applications and any tutorials I am able to find all talk about how to link the executable to the framework All I need is a wrapper for the dylib to get Labview to load it.
Like most things new to me. I tend to ask a lot of "silly" questions until I arrive at a "Eureka" moment when I am am able to visualise how everything fits together. At the moment I can see what I want. Have a some of the pieces needed to get to what I want, But don't know if I have all the pieces. Have the wrong pieces or Labvew is just being obstinate. Do you have an Xcode example of one that you made yourself using a dylib that Labview likes?
I've attached the dylib I've created. Perhaps you could wrap it so I can see how it all fits together?
-
Sorry for the late reply (I really want an up to date RSS-feed).
Here I have posted some VIs that are meant to calculate hashes and keyed hashes.
Ton
"removed source from VIs"
I was getting all excited until I read that
-
+1 for "couldn't give a monkeys" about twitter

-
I was using fysnc and FlushFileBuffers synonymously, since they perform the same job. There's probably some subtle difference between the two though.
Indeed. For windows there were "unconfirmed" reports of the OS ignoring (on occasion) the fushfilebuffers. And on "old" linux systems the fsync was a NO-OP.
I'm trying to minimize risk with the things I can control. For instance neither of us is using a memory journal since a crash in our programs in the middle of a writing transaction would very likely trash the database (even though it should be a little bit faster). I just like extending that safety to help mitigate hardware and os failures.
Well. thats not the reason I don't use it. There was little performance gain from purely having an in-memory journal alone (mainly because I open and close on every query). A WAL has a better impact, but at the expense of select queries.
There should be a flush cache command for the harddrive controller that the doesn't return until the cache has been written (this can be saftely ignored when the drive system has a battery backup, since it can guarantee that it will be written).
A good quality hard-disk will guarantee that data held in cache will be flushed on a power failure or brown-out condition (50 ms is required for CE approval). Which is probably longer than a couple of disk revs. From then on its up to the OS to re-construct using the journal. I think the real risk is if the file-system doesn't have journalling and therefore can exit in the middle of a write operation..
I work in an academic setting,so UPS and redundancy are often out of budget. I mainly using sqlite for settings, that if corrupted may cause serious problems. So backups don't help until there's been a problem. I would assume the extra durability would be good for embedded equipment in harsh environments.
I would be tempted to maintain 2 databases in this scenario (write to 2 one directly after the other). The probability that both would be corrupt (due to the reasons discussed previously) would be non-existent. And with the performance improvement of turning of Synch; you would still be in net profit.
If my transaction can't be written purely in one sqlite query (I put an example lower down in this post), then I need to keep the connection open. The low level stuff would work as well. Anyway in my library I need to keep the connection open to cache prepared statements.
If you don't "clear bindings". then the statements will be re-used. this is one of the good reasons for using named statements as opposed to the question mark or an integer.
The main use is to write composable transactions (in other words you can build a higher level api of subvi's that can be put together into a single transaction).
I my case I have a database of samples I'm keeping track off (this example is bit simplified). Now a sample has various properties, different classes of samples require different properties.
Now if the users wants to change a property a dialog vi pops up, this vi checks the type of property. For instance this says it's a ring it's so we call a subvi to update a list control of acceptable values that the user can select from. But the user wants to add a new possible value to ring. So the user clicks the insert new ring value button, types in a value and the new value is inserted in the database. So we recall the subvi to update the acceptable value list control. But the user changes his mind and clicks cancel, so we now need to remove the value(maybe multiple) he added. A very simple way to way to do this is to have the property editing dialog wrap every thing it does in a transaction, and just roll back if the user changes clicks cancel.
But what if the user wants to add a new sample. So the new sample dialog pops up, asks the users what class of sample to add. We look up which properties are required for that class, put that in a list of properties the users has to set (which might have default values). Now the user may cancel out of this new sample dialog so we're going to wrap this all up in a transaction as well. But we want to call our change property dialog to set each of the properties, but that was already wrapped in a transaction (and you can't begin a transaction within another transaction). Now an easy way to fix this is to switch from "begin transaction" to save points, since those can be put within each other, and they're functionally the same as begin transaction, when not within another transaction.
I think that's more of a case that you have coded to use a feature (I'm not saying that that's a bad thing!). There are many ways to skin this squirrel, even without using a database. I have thought about using SQlite for preferences (and also things like MRU lists). But for most applications I don't see much of a benefit (based on the fact that DBs are designed for mass storage and retrieval). Perhaps in your specific case this is appropriate. But I don't think most people think of preferences when they think of a DB. I see it being used more for logging, look-up tables and data that has to be viewed in a number of ways....all of which SQLite excels at.
Can you think of any other scenarios?
Many thanks. I'll take a look.
-
Saved for 8.6
-
1
-
-
Hi, everybody…
I’m new… how are all of you???…
Anyway… I’m a student at ITV, in Mexico… and I was bla bla bla bla bla
Does someone know how to use the same “numeric” as an indicator and as a control… You know… like in a single display calculator…
Yes I know… it’s very basic… but I’m running in circles… I actually have to build a .Vi In which I have to use just two buttons (plus “+” & equals “=”) and a single numeric and do as much additions as I want like in a calculator… in fact it is kind of a calculator… ¬¬
I’ve been trying to use the flat sequence stuff … in a case that stays in truth state when a button is pushed… but that’s all my brain can do on my own… does some one know or has anyone ever done something like this???…
Thanks…
sincerely yours: a Child with troubles…
PD. i don't speak in english... so i'm sorry about it...
Something like this?
-
Don't have a definitive answer. But some things perhaps you could look at.
Under the App properties there is a "source Control" sub menu that look interesting. Looks like a hook into the LV source control stuff (read/write config looks interesting) . Maybe you could find a way to make Labview Mercurial aware!
A bit of a kludge. But you could monitor the revision number and action when it changes. As far as I'm aware, it is only up-issued after a save rather than a compile.
-
I posted an example using that approach somewhere on the Dark-side.
Ben
Theres one in the Examples Finder with LV2009 that uses the picture control. Wouldnt take much to mod it (there a "scale" vi
) -
I've never noticed this before. Is it something that this site provides or does Google determine what shows up there?
He's LAVAs mascot
-
1
-
-
Hope your B'day was as good as Penrods
-
I too experienced " "You must enter a post" problem over the weekend (never before).
I also experienced "Error 403 Access Denied" for quite a while (happened a couple of times) when trying to view any pages. Not sure if they are related. I just assumed someone was updating the site (nearly thought I had been banned
) -
On OSX, LV expects to interface a ".framework" file. It has to be 32 bits as LV on OSX is still 32 bits.
The easiest way to produce a framework is to use XCode and select new project / carbon or cocoa framework.
XCode will prepare a skeleton ready to be used.
As SQLite is built-in OSX, you should use the provided implementation and just write a wrapper around it.
It is located in /usr/lib/sqlite3. This wrapper is only a few lines of code I've done similar wrappers for other libs.
Let me know if you'd like to have a copy of the XCode project and files.
Note that LV does not unload DLL/framework from memory. You have to quit LV. If anyone found an alternative I'm very much interested!
Chris
Many thanks Chs.
I too thought about using the pre-installed SQLite. But I'm not sure that I can guarantee that it will be 32 bit if the Mac starts in 64 bit mode. A wrapper is not a useful way forward as it requires upkeep of other code than Labview and would require a lot of work re-implementing an interface which is already there. A windows wrapper went this route and its limited because of this.
From my limited reading of the "framework" implementation its a bit like a fat arch. So does that mean I can compile a 32 bit and 64 bit and include both in the framework? Does the pre-installed SQLite have both 32 bit and 64 bit and switch transparently? Do I really have to type in each and every function rather than select it from the LV combo-box? (And does that mean I select the ". framework" instead of the dylib?) There seems to be little information on the net for Mac developers.
I will have a play with Xcode. I know its installed but not sure where to find it (doesn't show up under applications). I've only just learnt to use CodeBlocks so naively though it would just be a case of re-compiling for the Mac (its also available for the Mac)

-
I've had a quick perusal of the Mac framework link you provided (many thanks).
Sheesh!
 What a pain. It looked initially like the best way forward would be to link into the SQLite framework that is shipped with the Mac. But as LV for the Mac is 32 bit; you cannot guarantee that the SQLite will be 32 bit.
What a pain. It looked initially like the best way forward would be to link into the SQLite framework that is shipped with the Mac. But as LV for the Mac is 32 bit; you cannot guarantee that the SQLite will be 32 bit. It looks like Mac users are going to have to wait for me to complete the learning curve if there are no LV Mac gurus around to offer guidance (no response so far from my question in the Mac section). Or maybe it's a sign that it isn't that important (and the API is not that useful to the few Mac users there are
) and divert my attention to other things. -
I think guaranteeing no corruption is a rather subtle. On SQLite's How to corrupt your database. the first possible problem beyond the uncontrollable is the OS/Filesystem not fsyncing properly. The next is ext3 (a journaled file system) without the barrier=1 option (which to my understanding breaks sync with write caching). I think the problem (there could be more) is that writes to the hard drive can be reordered ( which I I think can happen when write caching and NCQ don't properly fsync, also an active sqlite database journal normally two files). You might be able to work it without a write cache on a journaled file system, or by modifify SQLite3 to use a transactional interface to the underlining filesystem (I think reiser supported something like that). Anyway I would suggest keeping sync full or at least normal,since it's easy for someone to pragma anyway the safety. The sqlite doc recommend normal for mac since on OSX it works around lying IDE controllers by resetting, which really slows things down.
fsynch is only used on unix-like OSs (read linux, Mac). Under windows "FlushFileBuffers" is used. It also states at the end of the paragraph that
"These are hardware and/or operating system bugs that SQLite is unable to defend against.
And again in Things that can go wrong section 9.4 it states:
"Corrupt data might also be introduced into an SQLite database by bugs in the operating system or disk controller; especially bugs triggered by a power failure. There is nothing SQLite can do to defend against these kinds of problems."
Where locking is "broken" (multiple simultaneous writes causing corruption) it seems to be referring to network file systems. In this scenario the websire states:
"You are advised to avoid using SQLite on a network filesystem in the first place"
The main issue seems to be cantered around old consumer grade IDE drives. I remember a long time ago reports about something like this. I haven't, however, read any articles about SATA drives having similar problems (much moe prevalent nowadays). But synchronous mode seems to be an attempt to "wait" a few disk revs in the hope that the data in the cache is finally written to a drive if its still in the drives internal write cache. (Still. Not a guarantee). And I think probably not relevant with many modern hard-disks and OSs (windows at least). Additionally. Putting SQLite (as a single subsystem) through our risk assessment procedure reveals a very low risk.
My view is that if the data is really that important, then classical techniques should also be employed (frequent back-ups, UPS, redundancy etc).
The problem with committing on every query is that you can't compose multiple query's. Which is something I do since I want the database to always be consistent, and a lot of my operations involve reading something from the database and writing something that depends on what I just read,
You can. You just compose them as a string and use the transaction Query". That is its purpose. Although in the "Speed example" it's only used for inserts. It can also be used for "Selects, updates, deletes etc".
The API is split into 2 levels.
1. The top level (polymorphic) VIs which are designed as "fire-and-forget", easy DB manipulation, that can be placed anywhere in an application as a single module.
2. Low level VIs which have much of the commonly used functionality of SQLite to enable people to "roll-your-own". You can (for example) just open a DB and execute multiple inserts and queries before closing in exactly the same way as yours and other implementations do (this is what "query by ref" is for and is synonymous to the SQLite "exec" function)..
Instead of reopening the file by default you could wrap all query's in a uniquely named savepoint that you rollback to at the end of the query. Then you have the same level of safety with composability, and you gain performance from not having to reopen the database file. The only trick is to have separate begin transaction and rollback vi's (since those can't be wrapped in save points), which I'd recommend as a utility functions anyway (those are among the main VI's in my library).
In benchmarks I ran initially, there is little impact in opening and closing on each query (1-15 us). The predominant time is the collation of query results (for selects) and commit of inserts. But it gives the modularity and encapsulation I like (I don't like the open at the beginning of your app and close at the end methodology). But if that "floats-your-boat" you can still use the low level VIs instead.
I did look at savepoints. But for the usage cases I foresee in most implementations; there is no difference between that and Begin / End transactions. OK you can nest Begin / End but why would you? Its on the road-map. But I haven't decided when it will be implemented. If yo can think of a "common" usage case then I will bring it higher up the list.
I think I figured it, my work computer is winxp and has write cache enabled which breaks fsync to some extent (I think). Now I see a difference on my WIn7 home computer which uses supports write cache buffer flushing (a proper fsync). Now I may need to get an additional hard drive at work just to run my database on if I want to guarantee (as best as possible) no database corruption.
See my comments above.
I think the difference between a Blank DB and :memory: db is that the blank is a data base with sync=0 and journal_mode=memory (the pragma's don't indicate this though), while with :memory: all the data in the database is stored in memory (as opposed to just the journal).
Indeed. And I would guess "Temp" tables are also in memory. I don't think there's much in it.
-
1
-
-
Hi,
I'm gearing up to start development of our next two projects in LV2010 and noticed I'm unable to create properties and methods on XControls (either new ones or existing ones from earlier LV versions). I checked this on LV2010f2 32bit version as well as on LV2010 64bit version. See what happens in the vid linked below.
http://screencast.com/t/IOBg5ir4y
Same happens for method creation.. LV then creates a 'normal' VI instead of a method VI.
I was unable to find any info or reports on this here and on the dark side..Maybe, I'm missing something here, but if this is a bug, it's quite a showstopper for me. We'll have to stay on 2009 then.
Anyone else noticed this weird behaviour?
Just save all. You will notice that it asks you to save the read/write vis (they have been created). Then the VIs will become visible.
[CR] SQLite API
in Code Repository (Certified)
Posted
Indeed. The OS does see the journal file as just a file (it couldn't see it any other way). But I think we would all be in trouble if we couldn't rely on the OS to write files in a certain order. Imagine overwriting a value in a text file. I don't think it would be very useful if we couldn't guarantee that the second value we wrote wasn't the final value.
I think "integrity_check" is designed to detect database structure corruption. Have you tried to change a non-data byte?
Ahhh. You have to be careful here. You are using "stream" functions which are memory resident. SQLite (quite sensibly) uses "WriteFile". Additionally. It uses "WriteFile" in non-overlapped mode.
Try this instead.
#include <windows.h>#include <stdio.h>int main ( void ){ HANDLE out = CreateFile ( "test.txt", FILE_WRITE_DATA, 0, NULL, CREATE_ALWAYS, FILE_ATTRIBUTE_NORMAL, NULL ); char s[50]; int i,n;DWORD l; for (int i=0; i<10000; i++){ n=sprintf (s, "%d\n", i); WriteFile ( out, s, n, &l, NULL ); } int *nullptr = 0; *nullptr=1; //crash before closing CloseHandle ( out ); return 0;}In the documentation for WriteFile it states:
So it is a proper hand-off to the OS unlike the stream functions.
Indeed. As I said previously. "Query By Ref" is synonymous to "exec". So all you need is "Open", "Query By Ref" and "close". There is no need for an intermediate layer since the high level API is just a wrapper around the query functions. (In fact "Query Transaction" uses Query By Ref"). So. Nothing is precluded. Its just deciding what should be elevated to the higher levels.