Rob Calhoun
-
Posts
33 -
Joined
-
Last visited
-
Days Won
3
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Rob Calhoun
-
Running a LabVIEW EXE from the Console
Rob Calhoun replied to John Lokanis's topic in Calling External Code
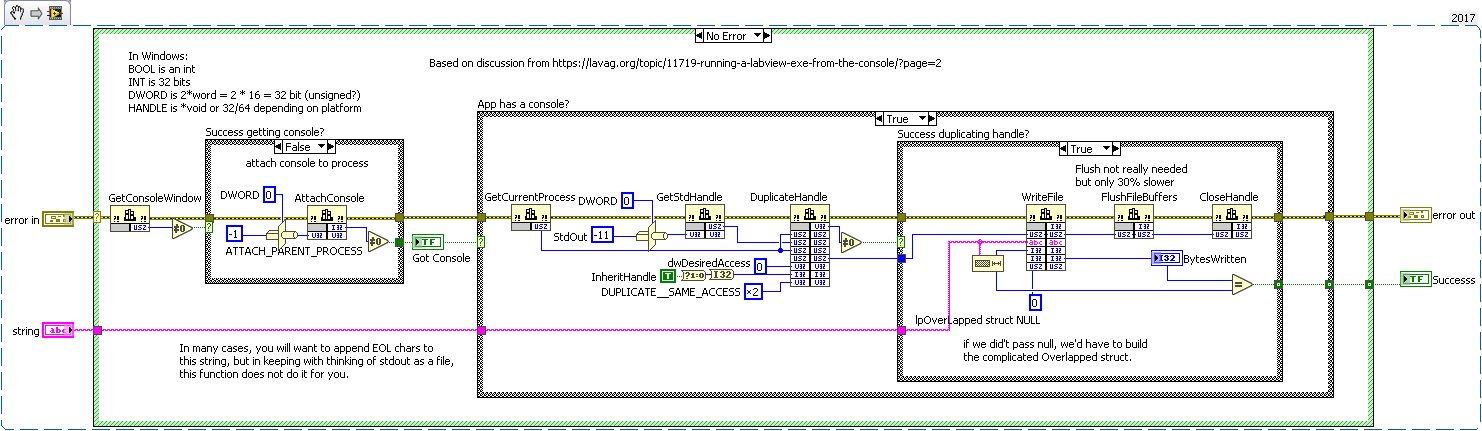
cross-reference: 32/64-bit compatible version of stdout writer for LabVIEW 2017. https://lavag.org/topic/20360-collecting-stdout-from-labview-when-run-from-jenkins/ -
Hi LAVA-ers, I'm finally implementing a long-delayed transition from our homebrew LabView build system to Jenkins. The best build-step option (for Jenkins under Windows) seems to be "Execute Windows batch command". My batch command looks like this: pushd "directory-containing-lvproj" echo "Running LabVIEW build process..." start "bogustitle" /wait "C:\Program Files\National Instruments\LabVIEW 2017\LabVIEW.exe" "Build.lvproj" "BuildJenkinsProject.vi" echo "complete, errorlevel %ERRORLEVEL%" popd where BuildJenkinsProject.vi is set to run when opened. BuildJenkinsProject.vi reads some environment variables set by Jenkins, sets up the builds (multiple EXEs and installers defined in a different lvproj) builds away. But my builds take a while, and I'd like to see the output from my logging system inside Jenkins while the build is in progress. Some Googling turned up these posts re: sending output to stdout from LabVIEW: https://lavag.org/topic/13486-printing-to-the-standard-output/ https://lavag.org/topic/11719-running-a-labview-exe-from-the-console/ I'm running LV 2017 64-bit, and none of the existing examples were handling 64-bit HANDLEs correctly, so I wrote a new version. This version uses only WinAPI calls (vs WinAPI + .NET), fixes some bugs, and it stateless, so you can call it anywhere in your code. Even when flushing the buffer after every write (which some on the Internet claim is necessary to get real-time log output; I am skeptical) it is plenty fast, around 10,000 lines per second. Since jdunham had previous written a fancy object-oriented logging system, I subclassed our logging system to write to stdout as well as the regular log. When I build from cmd.exe using the above batch file, it all works as intended. My problem: when Jenkins runs my batch file, I get something rather less exciting: nothing! E:\Jenkins\workspace>labview\Build\BuildJenkinsProject.bat E:\Jenkins\workspace>pushd "labview\Source\Build\" E:\Jenkins\workspace\labview\Source\Build>echo "Running LabVIEW build process..." "Running LabVIEW build process..." E:\Jenkins\workspace\labview\Source\Build>start "bogustitle" /wait "C:\Program Files\National Instruments\LabVIEW 2017\LabVIEW.exe" "Build.lvproj" "BuildJenkinsProject.vi" E:\Jenkins\workspace\labview\Source\Build>echo "complete, errorlevel 0" "complete, errorlevel 0" Not a big deal since I have my regular log files, but having gotten this far it would be nice for Jenkins to show work-in-progress. Any ideas? In the meantime, here is a stdout writer. (Released under MIT License, copy away.) -Rob Calhoun Attached: stdout writer function for LabVIEW 2017, and save-as-previous to LabVIEW 2012. WinAPI Write to StdOut Folder.zip

-
Hi Ton, You did a nice job with this! The code is both easy to read and easy to use. Was your library ever incorporated into OpenG? I did not see it there, so I downloaded it from the link above. It would definitely be a useful addition to the OpenG libraries. Thanks for sharing your work. -Rob
-
We use FireDaemon. As Swinders said you cannot have any UI when running as a service in Windows after XP/Server 2003. In the end we found the best way to handle per-instance configuration was to pass data in environment variables, which are settable in FireDaemon (which does have a UI for configuration) on a per-instance basis and easily read from the target application using a WinAPI call. If you want a free solution, try srvany from Microsoft.
-
Using VISA in an executable running as a service
Rob Calhoun replied to MartinMcD's topic in LabVIEW General
Likewise we run our LV applications as services using FireDaemon and have not had any trouble reading from serial ports using VISA under Windows Server 2003, 2008, or 2008R2. (At least not any trouble that can be blamed on running as a service...we did have an issue where the Microsoft Mouse Driver identified our GPS device as a serial mouse!) -Rob -
Interested in hearing from programmers who work remotely.
Rob Calhoun replied to Mike Le's topic in LabVIEW General
I've been working remotely for 10 years. Generally speaking you can get more code written out of the office but meetings / planning sessions / brainstorming are a bit harder and will require more effort on your end. Job interviews and other "managerial tasks" are particularly difficult. You are using a source-code control system, right? This is the most important piece of the equation, as in addition to all of the other benefits it takes care of synchronizing your code with others. Likewise your project documentation and bug-tracking system helps keep everyone informed of what is being worked on. Communication with your co-workers needs to have a low activation energy. You'll need to be on the phone a lot of course, but IM is great for quick back-and-forths. If there is a significant time zone difference, pick a time of day that is maximally convenient for both sides and block that out for collaboration. Don't be afraid to pick up the phone; get a headset and unlimited minutes on your phone or use Skype etc. You don't want to feel like there is a clock is ticking. For code reviews you need some sort of screen-sharing technology like gotomeeting. Written project plans (that are kept up-to-date!) become more important when you are off-site. If you have hardware you need to work with, you'll want a machine set up back at home with that hardware that you can connect to remotely. We use Microsoft's built-in solution (RDP) inside a VPN. Be super-nice to the people back at the office, since there is always the occasional need to have somebody plug in a cable in for you! Finally be tolerant when people call you in the middle of dinner etc. That's just the cost of working in a different time zone. Rob -
I too have used LabSSH and concur that its developer is super nice and quick to respond to emails. However in the end we did not use it because of how it handled timeouts and because of the licensing, which was per-machine rather than per-developer. (We have separate boxes for development, test, build etc and that was just not going to work.) We ended up installing cygwin and shelling out to it using the LabView System Exec function. It's kind of a brute-force solution but it is free and it works great. That gives you access to all of the usual ssh functionality, such as using RSA keypairs instead of passwords. Note that ssh is not included in the "standard" cygwin install but it is easy to add. -Rob
-
Wasted day at the track thanks to LV 2011, One more bug...
Rob Calhoun replied to JoeQ's topic in LabVIEW General
Alas, poor LabView 6! I knew him, Horatio: an application of infinite fast launch time, of small memory footprint and most excellent stability! But, one cannot use LabView 6 forever. I think you have a serial port configuration issues. I am no great fan of VISA, since all I ever need to do is read from a few COM ports and it is horribly bloated for that. VISA's serial port implementation had more than its fair share of bugs over the years, but the more recent versions seem to work pretty well. I suspect you are encountering something where the default configuration changed, or your code was relying on some bug (such as VISA ignoring what you told it to do) that was fixed in later versions. What properties are you setting on the serial port when you initialize it? I would in particular check flow control and make sure that is correct for your hardware (that it works with some serial ports and not others sounds very much like a CTS/RTS issue). -
Hi LAVA, We've been using a build system that uses multiple instances of LabView to execute the build process in parallel. Each build is single-threaded, but by running multiple builds one can use all the cores available on the machine. I posted some implementation details over on the NI forums, if anyone is interested. -Rob
-
We use subversion for both source code control and storing build products. (The cool kids are all using git or mercurial these days, but subversion is better in my opinion for binary files like LabView.) As long as subversion is using FSFS (the default) it works fine for multii-GB repositories with tens of thousands of revisions. Set "separate object code" flag on all VIs, and change the environment to make new VIs follow this. (It is annoying that LabView doesn't provide an easy way to do this; there are some workarounds posted on lava.) Otherwise, you run into "conflicts" that are really just recompilations. There are those who feel committing build products to a source code system is an abuse. To me subversion is just a distributed file system that provides a traceable history of what was put in when. It works very well for this. Putting builds in a different repository is one answer to complaints about repo bloat. -Rob
-
My comment above was written a year ago and refers to LV 2009 SP1. How did this thread get renamed "LabVIEW 2010 SP1"?
-
Experience with "Separate Compiled Code From Source"? (LV 2010)
Rob Calhoun replied to Rob Calhoun's topic in LabVIEW General
I have caught this three times "in the wild" but unfortunately I do not have a synthetic example. I am still working on it, and will post one when I can. You are correct. The LV runtime does not have a compiler in it, so yes, the object code must be re-integrated into each VI/control as part of the build process. I recommend you trash the object cache before building to prevent incorporation of any corrupt object code. (There is a VI Server method to trash the VIObjCache; it works in-process and it is fast.) We did have problems building projects that had "Disconnect Type Definitions" checked. Unchecking (which is the default for new buildspecs) and re-integrating the object code into controls programmatically before invoking the App Builder allowed us to build. (Builds failed two hours into the process with useless error messages; it was tedious to track this down.) But once built we have not seen any issues with the executables. -
Experience with "Separate Compiled Code From Source"? (LV 2010)
Rob Calhoun replied to Rob Calhoun's topic in LabVIEW General
This issue is real, and I am working with LabView R&D on it. In the meantime, I have a workaround that avoids (as far as I know) potential block diagram corruption caused by separating obj code from source code. Quit LabView, delete everything in your VIObjCache folder, and then make your VIObjCache folder unwriteable with directory permissions. LabView tries to save the obj code and fails silently (yay!); as a result, when a VI or control is loaded from disk the cached object code is never found and it is always regenerated from the source code. This ensures the object code state is always matches the block diagram state. (After the initial compile, there is no speed penalty; whether freshly recompiled or loaded from the disk cache, the obj code is held in memory during execution.) The cost of doing this is significantly increased load times, especially for large projects. I view this as preferable to going back to recompile-only conflict heck. (And, obviously, it is much preferable to code corruption.) -
Experience with "Separate Compiled Code From Source"? (LV 2010)
Rob Calhoun replied to Rob Calhoun's topic in LabVIEW General
I have more evidence of block diagram corruption as a result of using this feature. After modifying the type definition, a block diagram const array containing 11 type-defined enums was set to length 0 by LabView. I noticed, and therefore was able to recover my code by quitting LabView, trashing the object cache, and re-launching LabView. This makes the array re-appear. But if you run it in the corrupt state, you get an empty array on the wire, and (from my experience with another bug) if you modify and save a VI corrupted in this manner, you make the corruption permanent. We have already modified our build procedure to trash the object cache before building, but I am pretty close to throwing in the towel on this feature. It corrupts my code, which is completely unacceptable. If you're inside NI, I'm going to attached this to my previous CAR 277004. -
dynamically loading VIs from an application
Rob Calhoun replied to PA-Paul's topic in LabVIEW General
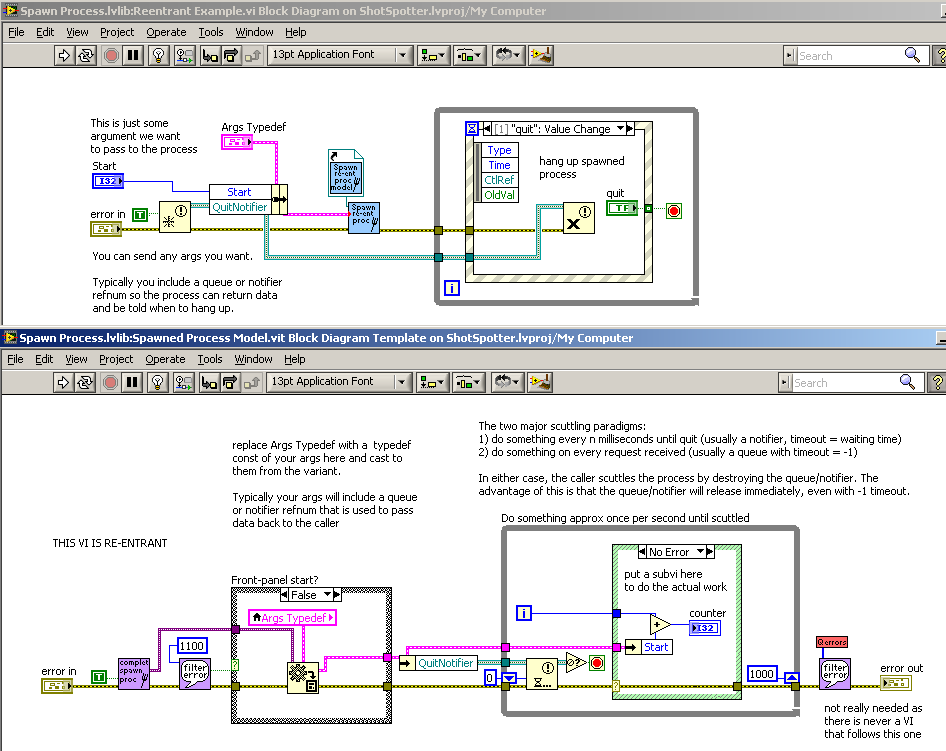
Like Mark said, just set "Wait Until Done" = F and "Auto Dispose Ref" = T. But it's sort of a pain to get all of the details right with passing arguments. Jason Dunham and I wrote a library that handles most of the nitty-gritty of spawning off a new process, including passing arbitrary arguments via a queue that shares the clone name and taking care of the handshaking. We think this is a better (albeit more complicated) approach than setting control front panels because sometimes you want the caller to be blocked until the spawned process completes some specific action. Our plan was to clean it up for release it through OpenG, but there never seem to be enough hours in the day. (How does Jim K. squeeze 56 hours into his day?!?) Here is a screenshot of a fairly complete example as a teaser:
-
Experience with "Separate Compiled Code From Source"? (LV 2010)
Rob Calhoun replied to Rob Calhoun's topic in LabVIEW General
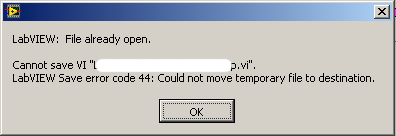
OK, now I have some experience with this feature and my experience has not been so good. First the good news: you don't get dirty dots all over the place when you change a typedef. Yay! Also VIs are (a little) smaller. Yay! The bad news: The converter tool in the project doesn't work at all, but you knew that. It makes building an application slower and less reliable. I'm not sure how much of the speed reduction is just the (more complex) LV 2010 compiler, but it takes just under 2 hours to build our product now vs about 50 minutes under LV 2009. Sometimes the builder stops working (stuck on build dialog using %0 CPU, forever), or throws a bogus error about how a "a bad VI cannot be saved without a block diagram" when in fact the VI is OK. Nuking the object cache and allowing LabView to rebuild it will fix the bogus error message, although it can come back if you build multiple products. Going through the source tree and removing busted stuff that isn't used in your application but is referenced in a library (or a referenced in a library that is referenced in a vi that's in a library that's in a vi that's in a library...I hate this behavior or libraries!) seems to help. Things can get COMPLETELY messed up if you revert your working copy in subversion. I moved a typedef into a library with only the library open (vs all of the source code), which turns out to be a bad idea because LabView can't figure out that "mytypedef.vi" at mypath is the same as mylibrary.mytypedef at mypath. Well, OK, I can sort of understand that, so I reverted the whole thing and pulled everything in memory so the linking would propagate. Total mayhem ensued. A whole bunch of callers now believed that mytypedef was still in mylibrary, even though (since I'd reverted) neither mytypedef nor mylibrary believed this to be the case. Trying to fix it manually by selecting the VI from the file dialog (like it asked me to do) resulted in the attached error message when trying to save the caller. Yikes. The problem was that although I had reverted the source code, there was still some object cache sitting around from mytypedef's short excursion into library-land. At this point I just wanted my code back, so I quit LabView, trashed ViObjCache, reverted everything and started over. That seemed to fix everything. I say "seemed to" because I found one block diagram constant of the typedef in question was sitting at value = 0, where it used to have value = 18. If you opened it directly from the windows explorer, or opened it with the vi server and then made a cosmetic change and reverted it (even though it was just loaded from disk and no changes had been made!) it fixed it. Trashing the object cache before launching LV also results in the correct value (18). But if you just used it (and there's no reason why I should ever look at it, given that it has not had a "real" code change in several years), the value of 0 was used. If you saved it or exported it in that stage, the bad value becomes permanent. Needless the say, the thought of LabView changing block diagram constants is pretty terrifying. We've never trusted cluster block diagram constants (that's a hard problem, updating the constant when the cluster is changed), but you'd think an atomic type (a U16 enum!) could not get screwed up in this manner. Well, I don't know exactly how it can happen, but it can happen. Yikes. I'm working with NI on this, but it's difficult to reproduce because any change to the vi (like moving it to the app engineer's computer) will generate a new viobjcache that won't be corrupt. So I don't really know where to go from here. I've loved not having recompile-only changes that interfere with reasonable use of a source code control system, but the thought of block-diagram corruption is extremely worrisome to say the least. I've been thinking more about the potential problems associated with reverting a file in subversion without reverting (or deleting) the relevant file in the VIObjCache; it's actually a hard problem from LabView's perspective, because things have changed without them necessarily knowing that they've changed. I don't know what algorithm NI is using to determine whether obj cache file is up to date or not; it seems to be pretty good, but it's not perfect. Next time I do any big-time reverts (that includes major typedef changes, for example), I'm going to quit LV and nuke the object cache. I'm not sure what to do with the more common let's-just-revert-this-back-to-the-current-revision revert; blasting the whole vi obj cache will really increase the overhead of doing that. Maybe we'll just go back to bundling the object code and source code, since then they at least get reverted together. I'm not looking forwards to that, but it beats having Labview corrupt my code.
-
We've been having a hard time building consistently. We build 5 related apps out of one project, and (aside from it being slow as the dickens) the builder frequently throws bogus errors ("can't save a bad VI without a block diagram") or just gets stuck. I didn't see this during the beta, possibly because I hadn't yet split source and object code on the whole hierarchy. (Blasting the object cache can fix it.) There are some workarounds but it's annoying. We're working with NI on the problem.
-
So it turns out this is called a reverse proxy server and there are a wide number of free and commercial implementations. If your web service will still work through the proxy, this is a good solution.
-
For reference Chris is referring to this tutorial: Tutorial 7749 The NI security model is weird. I looked into it and decided it was focused almost exclusively on granting access to an application rather than to a user in a browser. (I mean, sure, you could write javascript to generate the hash from security keys embedded in the javascript, but given that the javascript code is in plain sight, what is the sense in that?) What I ended up doing was using IIS and ASP for most of the web stuff. When I needed something LabView-specific, I used IIS as a proxy server. (Client authenticates with and talks to IIS on port 80; IIS talks to the LabView web server on port 8000; the LV web server is configured to only take requests from localhost, and port 8000 blocked to external users.) This way you get all of the various ways that authentication can be done with IIS (such as domain security); you could even do SSL. It's pretty easy; from the ASP app you just take apart the URL and rebuild it, repoint it to localhost:8000, then have the ASP app make an HTTP request to LabView and spit back whatever it gets to the caller. (I just used ASP instead of ASP.NET because I'm lame; don't do that, it's totally obsolete. :-) This works great, but doesn't seem like a good fit for live data. (How does LabView send live data anyway? Via asynchronous XMLHttpRequests?) How about this twist on what I made fun of in the first paragraph: write javascript that generates the required hash from the NI security code, and store it in an IIS-served directory. It's a pretty crummy security model, in that a user with read access could just save the javascript and do whatever with it, but if this is a read-only situation behind a firewall that is perhaps tolerable. In general I did not find working with LabView web services to be a lot of fun. There were lots of difficult-to-isolate bugs in it, like their default deployment generating pathnames that are longer than 255 characters, which Windows can't handle (see ). Hopefully things are better under LabView 2010.
-
The data types that can be passed via ActiveX are determined by COM, not by LabView. I'm not sure that there is a way to pass a cluster/struct directly using COM. You might be able to pass it as a variant type. That is the usual catch-all in ActiveX world. See this link. Or just throw a simple-types wrapper around your LabView function.
-
I haven't had stability problems with LV 2010, but I've only just started using it. (I'm hoping it is ok, because I for one would really like to get a functional Suspend When Called again!) This "silent crashing" behavior started with LV 2009, and boy is it irritating. We eventually traced one cause of this to an excessively long type descriptor inside a class, but it was very difficult to track it down because of the total absence of failure logs.
-
One of the most compelling features of LV2010 is the ability to remove the object code from VIs. This should greatly reduce the number of "recompile only" changes, which are a big headache for projects with multiple developers. Early in the LV2010 beta this feature was applied automatically across the board when upgrading; in the final build it is disabled by default and controlled with a Project switch. The Project Properties window has a "Mark Project VIs..." button that (theoretically) can be used to split up source and object code en masse. I found the "Mark VIs" button didn't work with my (large) project in the last beta I tried, and it doesn't work in the final build that I just installed either. ("Mark VIs" opens for 5 seconds, then closes without comment. It does work with a brand new project with a single VI, but that is not much of a challenge.) Since the approved method doesn't work, I'm considering walking the project hierarchy. We use dynamically-dispatched classes, recursion and various other modern LV complexities that mean I can't just call VI Open on App.AllVIs an expect it to work. Any recommendations on what to split? I.e., are there any types of VIs, such as dynamically---dispatched VIs, or VIs that get cloned at run time---that I should not split up?
-
Web Services in LV2009SP1
Rob Calhoun replied to John Lokanis's topic in Remote Control, Monitoring and the Internet
It did. I eventually figured this out by comparing a web service brought over from LV 8.6 that worked with one created under LV 2009 that didn't. (Of course I would have saved myself a day of hair-pulling if I'd just come back to LAVA to read your reply!) Thanks, John. I'm trying to write this up on the ni.com forums so that the build & deploy process gets improved in future versions of LabView. I haven't tried deploying on a machine that doesn't have LV on it yet. -Rob -
Web Services in LV2009SP1
Rob Calhoun replied to John Lokanis's topic in Remote Control, Monitoring and the Internet
Any chance this LV 2009 Known Issue applies? They say it only happens when the properties page is open. http://zone.ni.com/devzone/cda/tut/p/id/9951#139588_by_Category On a mostly unrelated issue, I've been debugging a web service for the last day. It is very slow going. Simple stuff works, more complicated stuff simply doesn't. It just returns http error 404. The only hints are in the LabView_Trace.log in %CommonAppDir%\NationalInstruments\Trace Logs. I'm starting to suspect the Windows path limit of 255 chars as the problem: LV puts web services 4 directory levels down in %CommonAppDir% with the result that ~170 chars are used up before you get to the first subvi. A typical error is: 5/14/2010 4:12:47.316 PM | t=C38 | ERROR | ws_shared | Unzipper::do_extract_currentfile | error opening C:\Documents and Settings\All Users\Application Data\National Instruments\Web Services 2009 32-bit\UserServices\deployed\Test-3CA39ABB-844E-43A0-8F88-DD1C45D2FE7A\internal.llb\LabVIEW 2009\user.lib\_OpenG.lib\error\error.llb\Build Error Cluster__ogtk.vi Pretty darn long, isn't it? Maybe that's why Microsoft still uses 8.3 filenames all over the place! I'll post again once if/when I've isolated it. -Rob Well, I can break it by saving a VI to a really long nested path, and un-break it by saving it higher up in the hierarchy, with the same filename. No warnings during the build process. Bug report time. ... I have no idea how to reconfigure LabView to store the web services less deeply in the hierarchy, but I do have a code obfuscater that replaces files with their MD5 hash. Maybe that will be sufficient. Otherwise, this is a major barrier to using web services since there are only about 85 chars available for user paths. -
LabView mathscript's syntax is very close to Matlab's mscript. You should be able to run matlab code inside a mathscript node with few changes. However, it is more designed for running specific chunks of code as functions inside a LabView application than for running a monolithic Matlab program from inside LabView. Also, as of LabView 2009, mathscript is now an add-on package.