
LogMAN
-
Posts
656 -
Joined
-
Last visited
-
Days Won
70
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by LogMAN
-
-
Are you working on a notebook by any chance?
In my experience LV2016 and LV2017 (never tested SP1 though) get stupidly slow if the graphics card is not powerful enough to render the selection box. Notebooks in particular use CPU integrated graphics and only utilize the "real" GPU if a program requires more demanding 3D capabilities. LabVIEW doesn't fall under that category (yet).
For the few test projects we do in LV2017 we use a sufficiently overpowered machine that can handle virtually anything you throw at it (designed to rendering 3D images from one of our cameras). It's ridiculous. Still not sure what to make of it...
-
6 hours ago, Michael Aivaliotis said:
The ones I've used have limitations and typically cap your repo size at 2 Gb. Recently I hit this limit on a large project.
Technically, no repository should ever grow to that size (as in "best practice"). Especially executables and installers will never change, so there is no reason to keep a history of it. I suggest putting them in a separate folder. For the same reason LV allows to separate compiled code in the first place.
If you insist on keeping these files in the repository, consider making changes to the structure of your repository to keep it manageable.
6 hours ago, Michael Aivaliotis said:So this question is mostly to get community feedback on what approach you use to handle this, if at all.
I've been in a similar situation in the past, where a repository exceeded a size of 10 GB. Very painful to pull and push, even on a local network. That repository contained installation scripts and of course the installation files that were bundled with it. Similar to your situation, these support files were the main reason for the size of the repository.
The solution was simple: Split the repository into two repositories. One repository contains the installation scripts, another the support files. The repository with the support files was made a submodule in the main repository (using git submodules), essentially keeping the original structure in place. To reduce the size of the main repository, history was simply rewritten using git filter-branch. Don't do that! First create a copy of the repository and then make changes to the copy. That way the old repository can be archived for future reference (lessons learned 😅).
Of course, the repository for the support files also grows over time. The solution is to create a new empty repository for every major revision (or whatever fits your needs) and re-link the main repository to it. It is still possible to checkout older revisions (the ones pointing to the "previous" repository) but it requires re-initializing submodules when doing so (because it points to a different repository).
6 hours ago, Michael Aivaliotis said:I also tried putting the build output and other transitory files to dropbox as well. However I found an issue because dropbox would interfere with the build process (any insight to this from others is welcome).
I had similar issues on Windows 7, where the build fails if the output folder is open in Windows Explorer.
You should take a look at the application builder palette and automate the process by moving files after the build finished.
We did so recently with great results. With a simple click of a button it builds all files, puts everything in a ZIP file (named according to naming standard) and moves it to a secure server location that is automatically shared to everyone who need to know about it. The only thing needed is to set the build version before pressing start and to commit (and tag) after it finished.
Hope that is of some use.
-
On 1/11/2019 at 8:30 AM, mischl said:
I was facing only one problem: '?-x' in a statement is processed as text and the question mark will not be exchanged with bind, use concat instead: ? || '-x'
Parameter bindings require you to follow specific syntax. It is explained here: https://www.sqlite.org/c3ref/bind_blob.html
QuoteIn the SQL statement text input to sqlite3_prepare_v2() and its variants, literals may be replaced by a parameter that matches one of following templates:
- ?
- ?NNN
- :VVV
- @VVV
- $VVV
In the templates above, NNN represents an integer literal, and VVV represents an alphanumeric identifier. The values of these parameters (also called "host parameter names" or "SQL parameters") can be set using the sqlite3_bind_*() routines defined here.
'?-x' gets interpreted as parameter, which doesn't work. Two solutions come to mind:
1) Use the concatenation function like you suggested. This makes sense if the suffix is static for all parameters.
2) Do the concatenation before binding the parameter (i.e. in LV). If your suffix can change, make it part of the parameter.
-
Indeed, the location is different => https://lavag.org/applications/core/interface/file/attachment.php?id=13529
If you go to your profile (icon in the top right) and select "My Attachements", the files listed there show a different file location than the ones in posts. Here is mine from above:
My Attachments
https://lavag.org/applications/core/interface/file/attachment.php?id=13701
This one probably works (not tested, just a guess)Edit: it doesn't.
Post
-
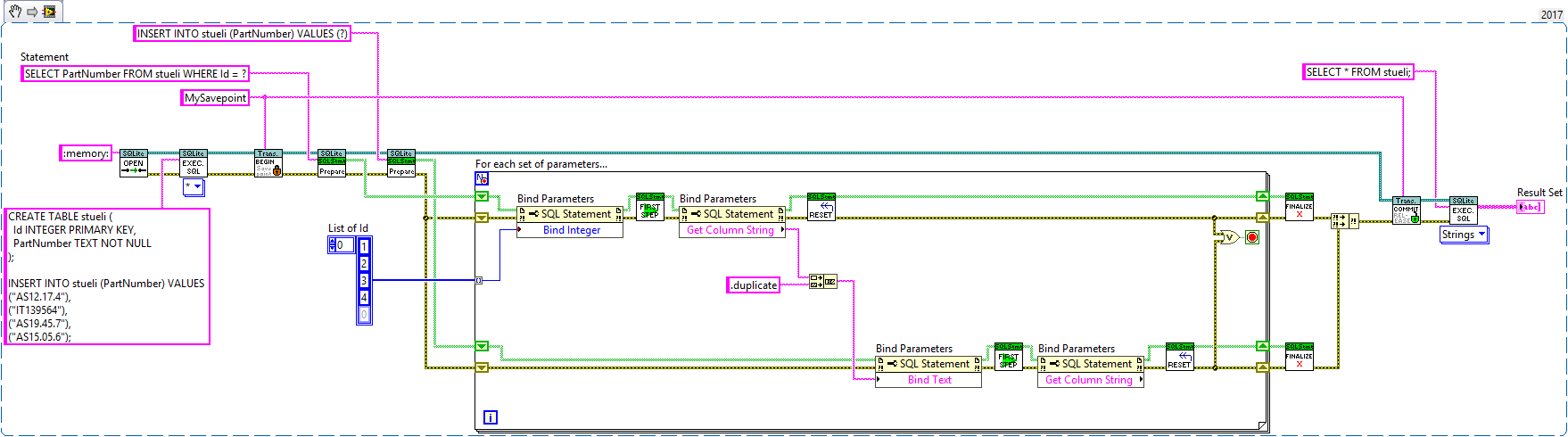
If you are set on doing multiple queries in the same loop, here is another example that might help understand how it should work. The VI is executable, using dummy data.
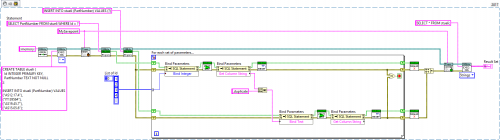
I've also attached the VI for LV2014, so you can play around with it.
-
18 hours ago, mischl said:
yes, but that is set already to false by default. isn't it?
You are right, my bad.
18 hours ago, mischl said:is the usage of the 'SQL Connection in' and therefore no 'SQL statement in' correct? Or how to use them?
Yes and no.
The SQL Prepare function creates the SQL Statement. It allows you to run the same SQL query multiple times, but more efficient. I've attached an example in my last post, using your SQL query:
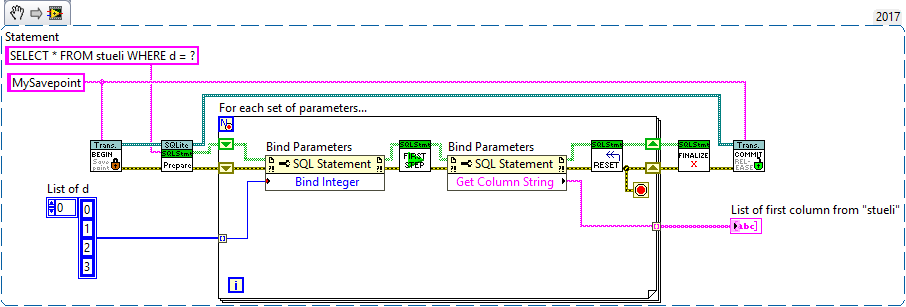
SQL Prepare (second VI from left) receives an SQL Connection and the SQL query ("SELECT * FROM sueli WHERE d = ?"). Note, that it says "d = ?". The "?" will later be replaced in the loop by the actual value.
In the for loop, the first node does exactly that. It replaces "?" by an element from the list. Note that you can have multiple values, using multiple "?" in your query.
SQLite First Step (the next VI) executes the query once and you can read the results using the node that follows (Get Column String).
Before running the same query again, you must reset the SQL Statement. Note, that everything takes place within the loop.
When the loop ends, you need to finalize the SQL Statement or it stays in memory.
18 hours ago, mischl said:in the example, the 'SQL statement' ends after the reset at 2. at 3 and 4 further ''SQL statement' are in used and only one can be finalized. but there are three now. how to handle that?
You must finalize each SQL Statement separately. In your example, everything is inside the loop, so you gain nothing by using prepared statements.
SQLite Prepare and SQLite Finalize must be placed outside the loop. I suggest you split those SQL Statements into separate VIs or it will be very confusing.
18 hours ago, mischl said:the 'Prepare' at 3 needs a 'SQL Connection', it is the one chained from 2, or?
Yes, they all share the same connection.
18 hours ago, mischl said:sorry, it seems that I forgot to attach the snippet. here is it. no problem if there are broken wires, but it might be easier to wire an example with the correct usage of 'SQL Connection in' and 'SQL statement in' than to explain them by text.
Actually, the snippet was attached, but Lava removes the source code of snippets right now (download the image and drag it into LabVIEW).
Can you copy the code into a new VI and post it here?
-
On 12/11/2018 at 6:16 PM, Michael Aivaliotis said:
I think something got changed in the upgrade, but i think i fixed it now.
Unfortunately it isn't. Can you check again?
Here is one of my posts for reference with multiple code snippets (also some of the previous posts as well):
The first image has an original size of 26,392 bytes but the file in the post is only 12,304 bytes. That is the fully-zoomed image from here:
Let me know if I'm doing that wrong
-
3 hours ago, mischl said:
I want to optimize the upper part on the screenshot with the lower (to avoid too many transactions).
My general advice for refactoring code is to do it step-by-step. Don't try to fix everything at once, as it will likely break your code (as it did in your case).
Note:
- I wasn't able to load your VI snippet. I'm not sure why though (either I'm to stupid to do it or Lava sanitizes images)
- My suggestions below are based on your original VI
Step 1 - Improve readability
Arrays and for loops
The outer for loop iterates over multiple arrays at the same time. This means that the loop will end after processing each element of the smallest array. I suggest you use one array for iteration and use the Array Index function to access elements from the other arrays. Here is an example:
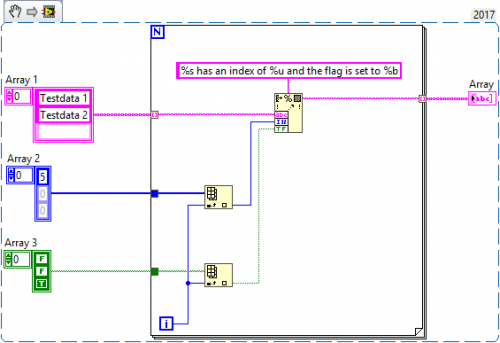
You should play around with it to see the different outcomes. Note that indexing an element from an array of smaller size returns a default value (i.e. zero for numbers, an empty string for Strings and false for Boolean).
Shift registers
The outer for loop uses a shift register for the SQLite instance as well as the error cluster. The inner for loop, however, doesn't. This can be problematic for two reasons:
1) The SQLite instance in the inner for loop gets reset after each iteration.
2) An error in the inner for loop is reset after each iteration and only the last error is returned.
The solution depends on what you want to do. If you want to abort as soon as possible on any error, I suggest not using a shift register but making the for loop conditional instead (exit on error). Otherwise use shift registers on both loops.
Step 2 - Optimize your code
Use transaction outside of for loops
Transactions are very useful for improving performance if used correctly. In your second example, you already added the BEGIN and COMMIT Transaction using "MySavepoint". This is generally a good idea.
3 hours ago, mischl said:1. place the BEGIN and COMMIT outside. ok
Disable transactions on Execute SQL
The Execute SQL function has an optional input on the top which you can set to false in order to disable transactions. This will already improve performance considerably.
Answering questions
3 hours ago, mischl said:2. the command in 2 and 3 is something like SELECT * FROM stueli WHERE d = 'xy'. Do I have to do that by bind or just as prepare statement on the picture?
SQL Prepare and SQL Finalize should be placed outside the for loop and you need to inject values for your parameters at some point (unless your SQL Statement is static, which it isn't according to your info above).
The "INSERT many rows Template code.vi" provided by the library (see Code Templates palette) visualizes that very well:
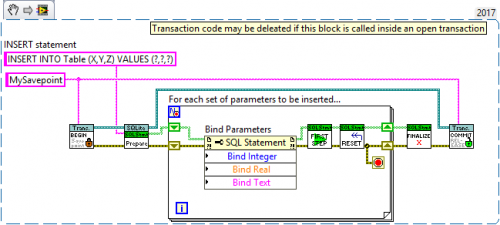
I highly suggest not using "SELECT *" but explicitly selecting particular columns instead. That way your SQL Statement becomes predictable.
3 hours ago, mischl said:4. here the 'insert many row template' is used without the BEGIN and COMMIT. So it is the same question as in 3: how to handle the connection.
Here is an example that may or may not work (I can't test it for obvious reasons):
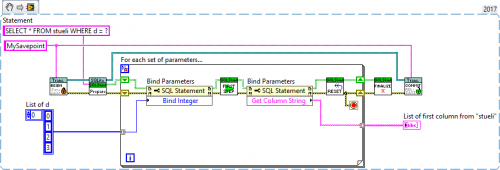
I suggest making a VI for each statement (without transactions of course). That way you can test things in isolation and be certain that it works.
3 hours ago, mischl said:3. is the usage of the 'SQL Connection in' and therefore no 'SQL statement in' correct? Or how to use them?
I'm not sure what you mean by that. Can you explain what you mean in more detail?
-
 1
1
-
On 11/22/2018 at 2:10 PM, Rolf Kalbermatter said:
Yes they are in a SubVersion repository so not the exact same experience as with GIT repos, but similar enough.
You can use git-svn to make your dreams come true (and nobody will know) ?
-
11 minutes ago, ShaunR said:
Lava serves this purpose well.
I agree. It just needs to be more visible to users (i.e. by putting "Downloads" in the main navigation bar next to "Leaderbord")
It also brings us back to this poll
-
1 hour ago, Michael Aivaliotis said:
The library is still useful. But it can be useful and dead at the same time.
I agree to what @ShaunR said, but let me add to it:
The library is not dead, because it is still functional and very useful - especially for new developers as mentioned earlier.
The project, however, is dead. As you correctly pointed out:
20 minutes ago, Michael Aivaliotis said:Bug reports and suggestions get ignored or go into a void. Documentation is missing or broken with no intent to be fixed. New improvements and efficiencies in LabVIEW have not been incorporated.
Technically anyone could fork the project (on whatever platform - SourceForge / GitHub / BitBucket - you name it). Development could even continue under a new name (probably even the same?). Yet the number of licenses being used right now is impossible to maintain, even for experienced developers. OpenG is also tightly coupled with lots of services (i.e. NI and VIPM link to the official repository on SourceForge). To my understanding (although I don't have facts on this), the lack of response in the main repository is the reason to why libraries like MGI were found in the first place. Just look at the bug tracker https://sourceforge.net/p/opengtoolkit/bugs/
This is also not the first time we discussed the (possible) future of OpenG. Here is a thread from two years ago:
The complexity of the main repository (i.e. the folder structure) also sets the bar very high for novice contributors: https://sourceforge.net/projects/opengtoolkit/files/
And let's not forget the difficulties in comparing VI revisions in general.
All things considered, the project is not a simple task anyone could just pick up and get going. Lot's of things need to be considered, which requires lots of experience in LV. Of course, most experienced developers have no interest in contributing to the project if it involves lots of administrative tasks on top of their regular job.
Maybe a shared library like OpenG is not the right solution for LV. A simple place to share VIs might be easier to manage and contribute to in the long run.
-
We used the OpenG library a long time ago, when LabVIEW was still new to us and we could leverage the power of OpenG to accelerate our development (between LV6.1 and LV2009). This is in my opinion still the strongest point of that library - it provides new developers (or teams) with lots of useful functions at the cost of dependencies.
We have since walked away from it due to incomprehensible copyrights, lack of updates (although it is very stable) and generally because we used few functions to begin with (i.e. Fit FP to largest decoration, filter arrays and some string manipulation). At some point the dependencies mattered more than the benefits. What we needed was rebuild in our own library, removing all dependencies from OpenG.
If the OpenG library were to be cleaned up, just removing functions is not a good solution because it breaks compatibility for anyone who depends on it. On the other hand, dependencies between the libraries can easily be removed.
For example, there is no need for OpenG String to depend on OpenG Error anymore. Instead OpenG String could be updated to remove the dependency (using only native LV functions) and still keep OpenG Error in VIPM.
OpenG Error on the other hand is technically unnecessary nowadays (as pointed out by @smithd above). This library can be archived (while keeping it in VIPM). Here is what we do with our libraries when they become obsolete:
- Remove obsolete VIs from the palette (but keep them in the vi.lib)
- Change icons and documentation to highlight obsolete VIs (similar to how NI does it, by adding red color to the icon - the more the better)
- Explain in the documentation why the VI is obsolete and how to replace it
- Add replacement code to the block diagram of the VI
- Remove password protection
- Enable inlining if possible
That way, when you come across obsolete VIs, you can simply use the "Inline SubVI" command to replace it: https://forums.ni.com/t5/LabVIEW/Inline-subvi/m-p/1279086/highlight/true#M532443
Of course, sometimes changes may destroy the block diagram of the calling VI, which is why those VIs have password protection removed, allowing the developer to inline the VI manually.
-
2 hours ago, Aristos Queue said:
so I hack up AppBuilder a bit so that when I get to the end of the build, I can open up the broken VIs and see what they look like.
Please share ?
2 hours ago, Aristos Queue said:Yet another reminder -- as if I needed it -- that computers only do what we tell them to do. And they do it very precisely.
 Amen.
Amen.
I was working on a nasty bug for the past few days as well. The source code looked fine, but the application didn't do what it was supposed to do (or so I thought). As it turns out the executable did exactly what it was supposed to do. And I was looking at the latest code, testing old software...

Reminder:
1) Always include und update the version number in your executables (and configuration data if possible)!
2) Work with the source code you used to make the executable!
3) If you are experienced enough to skip points 1 and 2, see points 1 and 2!
-
25 minutes ago, Neil Pate said:
Has this been in LabVIEW all along and I just never knew about it?
Yes, at least since 7.1, maybe earlier.
-
44 minutes ago, Michael Aivaliotis said:
Which notification? Do you mean the "Something went wrong" message? So I think you are mentioning 2 issues. One is the message and the other is the incomplete profile step.
Sorry, my bad. I didn't see the "Something went wrong" message, thought we were talking about the "Optional Profile Information".
-
This is awesome! Thanks Michael
 42 minutes ago, Michael Aivaliotis said:
42 minutes ago, Michael Aivaliotis said:How do you login? Using built-in login or facebook? I'm thinking it's a caching issue maybe.
I see the same notification using regular login (email + pw). Caching doesn't seem to be the issue. There are likely some new parameters which weren't available in the previous version.
Edit: Here is a capture of the requested settings (it says "optional" but if you click "Skip this step" it will continue requesting info):
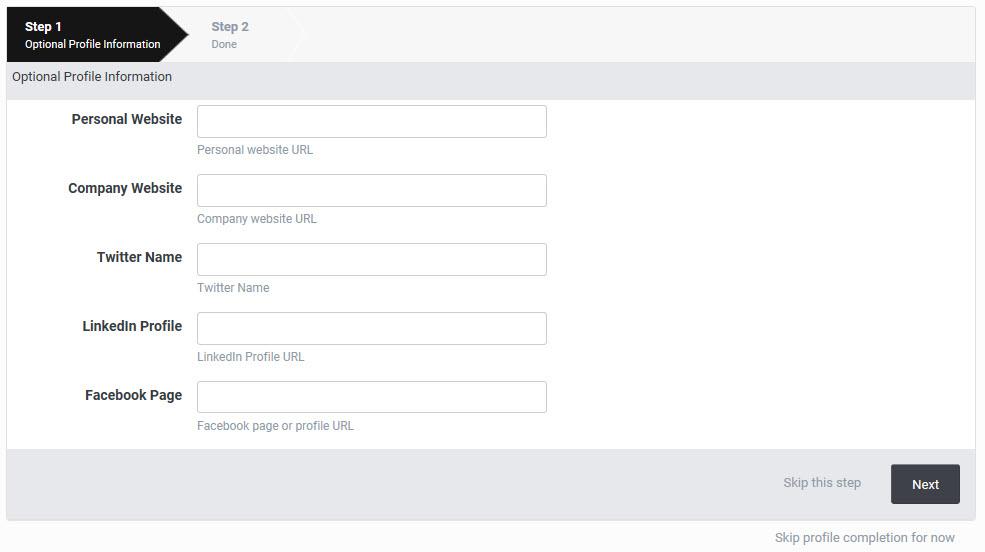
Update: Pressing "Dismiss" on the notification seems to work for me
-
7 hours ago, smithd said:
I wasn't able to find any example of code which offloads all the password handling to windows
Are you looking for something like this?
-
Here is a KB from NI on this subject: https://knowledge.ni.com/KnowledgeArticleDetails?id=kA00Z000000P7qjSAC
-
1
-
-
Which font do you use? On Windows we have "Small Fonts" which is the only readable one. Something similar should exist on Linux.
-
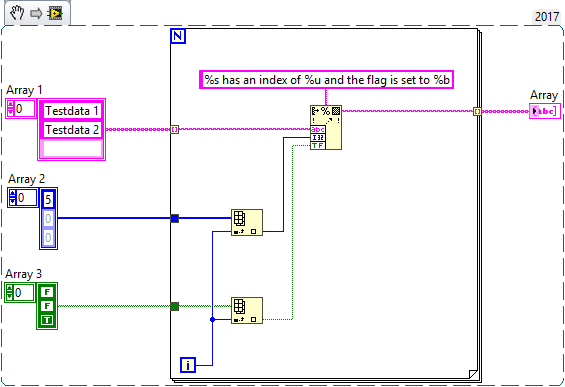
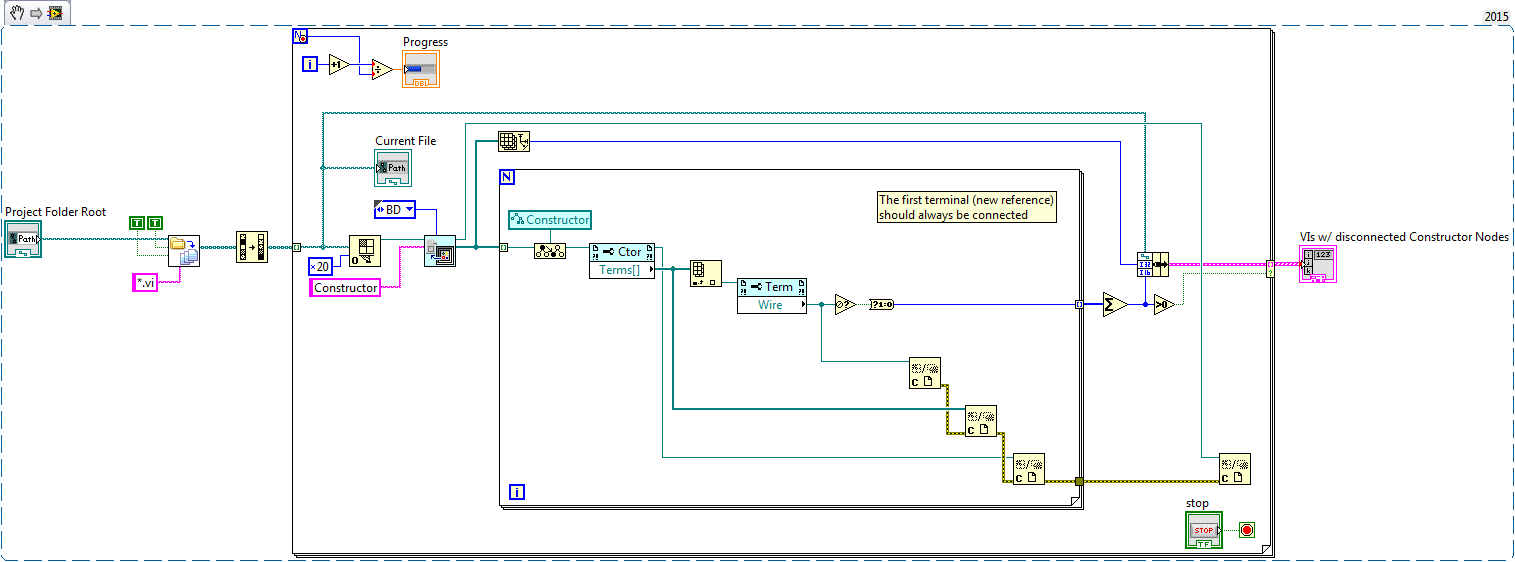
If anyone is interested in finding incorrectly connected Constructors automatically, here is a VI that will do that for you:
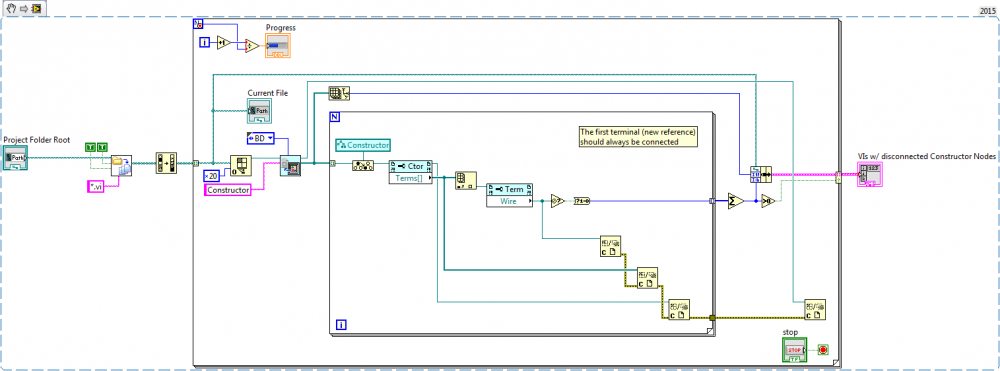
It's not very fast, but it does its job. The result is a list of VIs with the total number of Constructor Nodes found and the number of Constructor Nodes where the first terminal ("new reference") isn't connected. This is an indirect solution because the offending terminal officially doesn't exist (not accessible via scripting).
-
1
-
-
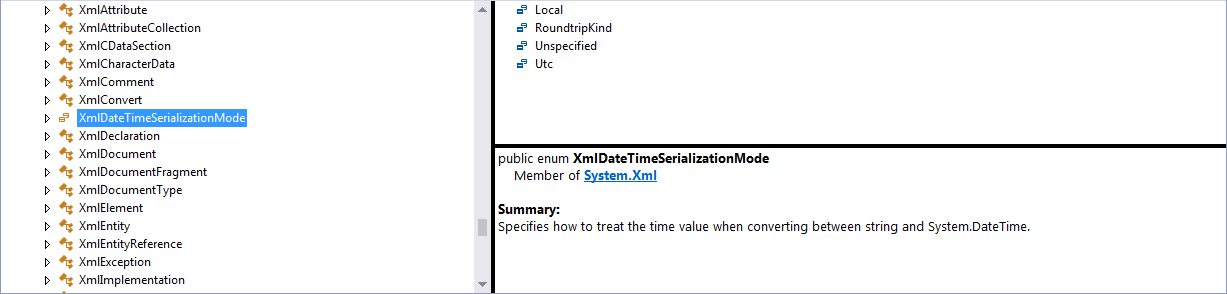
Thanks for reporting @_Mike_
Turns out the terminal adjusts to the object type (object or enum). In your case the Constructor is for an enum type, so it actually returns an enum instead of a reference. Here is another example:
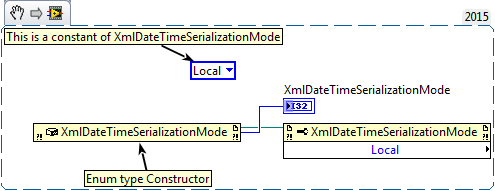
This is the corresponding definition according to Visual Studio:
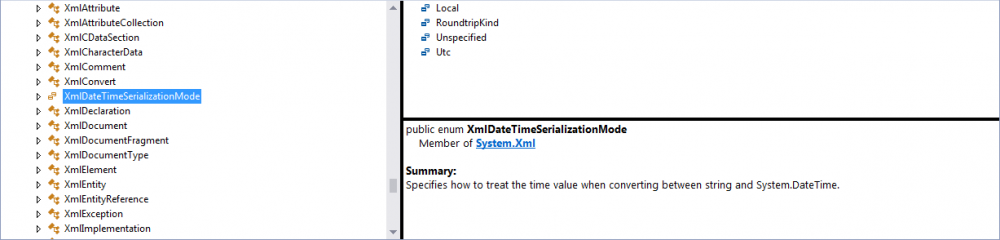
Very interesting behavior indeed.
-
1
-
-
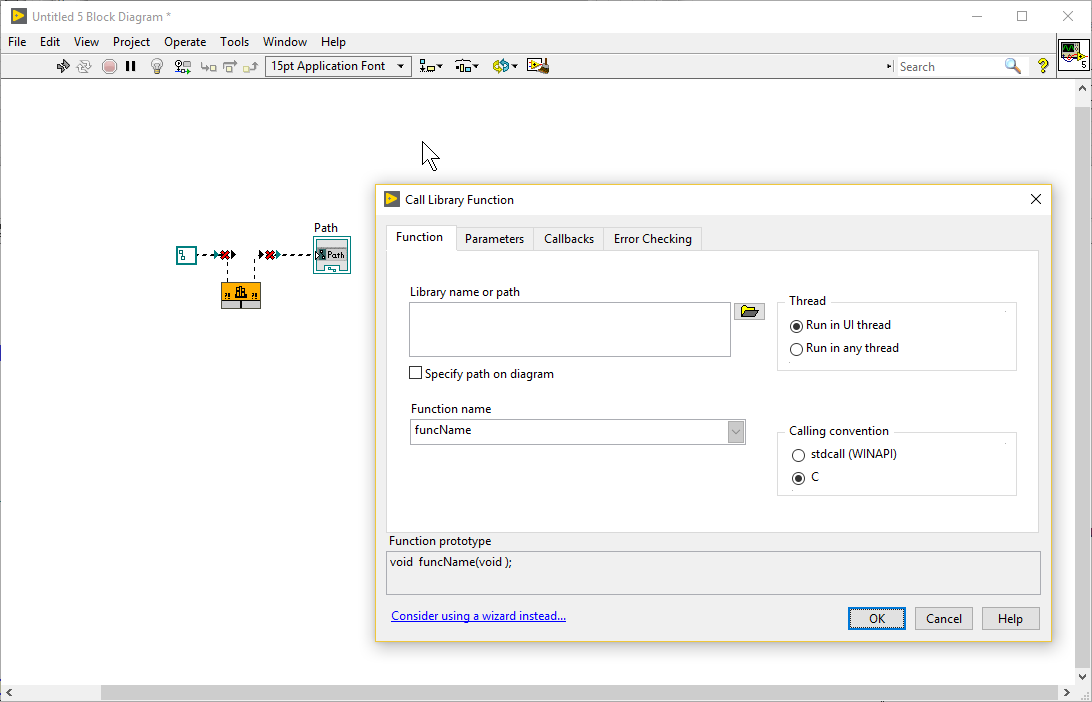
@Darren Would you be interested in adding another detail to the CAR?
Just for fun I went to see if I can break other nodes and actually got strange behavior from the Call Library Function Node in a very similar way (using LV2017). You can connect the "path" terminals, even if the option "Specify path on diagram" is not checked. I understand that this is probably a design choice to prevent wires from vanishing when unchecking this option and it doesn't do any harm, but the wire should break. Unfortunately, the output wire doesn't break initially:
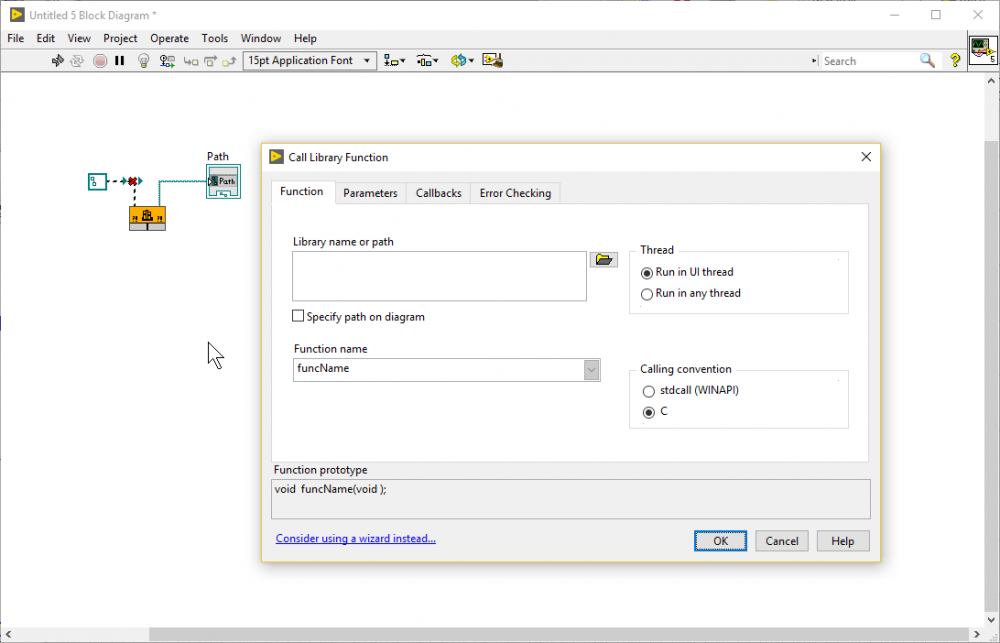
Notice: I just placed the node and connected the wires. The options dialog is open to show the checkbox is actually not checked.
Here is what I get after pressing the "OK" button on the dialog (you don't have to change any settings for this to work). You can see the wire is now broken, as it should be:
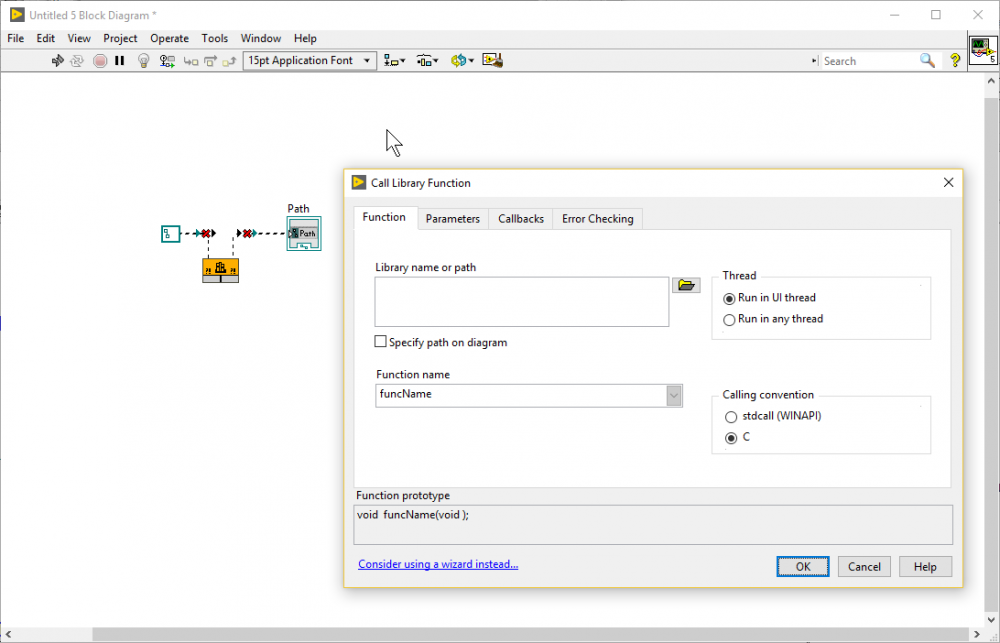
This is only a cosmetic problem because the function breaks as soon as you press the "OK" button. The behavior is strange nonetheless.
-
Thanks everyone! It's good to know I'm not (yet) going insane

Sorry for not mentioning how reproduce the issue in the first place. I suppose one reason this never occurs to anyone is because we all start wiring from the Constructor Node for obvious reasons, except sometimes we don't.
3 hours ago, Darren said:I have filed CAR 711518 on this issue. I agree that it is a significant usability concern that it is so easy to wire to that null reference terminal, have code that doesn't function correctly, and not have an indication as to why.
Awesome, thanks for sharing!
I'll inform my team to keep this in mind.
-
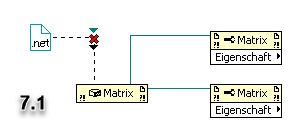
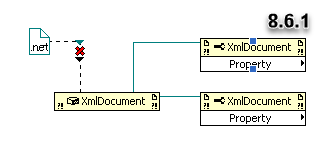
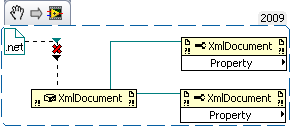
Okay, I just finished testing on various machines (virtual an non-virtual) with various LV versions and all of them support this feature! It is very unlikely that we somehow broke all machines and versions in our department for the past 15 years exactly the same way (although there is always a chance
 ). Find attached more snippets for all versions I checked (for 7.1 and 8.6.1 I had to take screenshots). I've also attached the VI for LV2017. So, in total I've positively tested these versions:
). Find attached more snippets for all versions I checked (for 7.1 and 8.6.1 I had to take screenshots). I've also attached the VI for LV2017. So, in total I've positively tested these versions:
- 7.1
- 8.6.1
- 2009
- 2011
- 2013
- 2015
- 2017
Unfortunately I currently don't have a 2018 Installation to check.
34 minutes ago, JKSH said:What happens if you load the project in a different dev machine?
It works just fine. We can load, edit, build and execute the project and all executables.
15 hours ago, Darren said:Also, I got a DWarn when I copied your snippet into my diagram
Darren, which version of LV have you been using at that time? Could this possibly have been changed in LV2018?


LabVIEW 2017 Editing Issues
in Development Environment (IDE)
Posted · Edited by LogMAN
That is very unfortunate. NI really needs to work on that.
For reference, I found a complex VI here and used that on my private notebook (decent hardware, enough for LV2015). This is what it looks like on my end (using LV2017.0f2).
It's a bit faster without recording of course, but not much. Also the CPU consumption is about 20% while dragging, which is way to high in my opinion. How did that ever pass testing phase? Looks to me like they never tested with more complex VIs like this because it works fine for smaller (or empty) VIs.
Anyway, it seems that the dragging operation in LV2017 is not a O(1) operation. More like O(n) where n is the number of objects on the block diagram. They probably check every object during the drag operation to figure out which one to highlight.
Works better on the front panel but that is probably because there are less objects on the FP (i.e. no wires).