
LogMAN
-
Posts
655 -
Joined
-
Last visited
-
Days Won
70
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by LogMAN
-
-
As @Daklu mentioned, "complexity" is being used for various perspectives in this thread. Maybe this entire discussion should also be moved to another thread?
On 10/17/2019 at 11:32 PM, Aristos Queue said:The requirement to create a class per message: that is complexity of the AF. The ability to send high-priority messages is not.
14 hours ago, Aristos Queue said:I'm not sure what the term is for the negativity introduced by options, but it is not (as I see it) the same as "complexity" being discussed elsewhere in this thread.
Here is a definition for "complexity" I find helpful at times like this:
QuoteBy the definition of complexity, its [(the software)] operating state space is very large and (all else being equal) it is more difficult to re-create an exact state in a large state space than to do so in a small state space.
The important part is "difficult to re-create". Now let me pick up the example from before:
By this definition of complexity, DQMH is indeed more complex than the Actor Framework because it produces many more potential outcomes (its operating state space is larger). The keyword in this example is "determinism":
- Priority messages in DQMH are nondeterministic (less deterministic is probably a better definition).
- Priority messages in AF are deterministic.
A subtle yet important difference. Of course, here we are looking at the complexity of the framework itself, not the complexity of the user's code.
On 10/17/2019 at 11:32 PM, Aristos Queue said:A framework's artificial complexity is only from the things that the framework forces on your code, not the options that it enables if you choose to buy into it.
AF and DQMH without priority queuing are no more or less complex than AF and DQMH with priority queuing. The priority queuing only becomes a part of the complexity computations if "priority" were a required input and you had to send some messages at a non-normal priority. Because you can use both frameworks entirely without ever using priority, it isn't part of the computation. It is an option that you can choose to exercise in your code or not.
"If you buy it, you pay for it" features don't add complexity. "Comes with the territory" features add complexity.
When designing the architecture of a software, optional features like this should be taken into account. If determinism is a key requirement, AF is certainly a better choice than DQMH (not taking other key requirements into account).
Let's assume we went with DQMH. This decision can lead to higher costs in the future if determinism turns out to be important and priority messages are being used a lot. In this case there are multiple options:
- Keep using DQMH and work around the problem with a custom solution => see sunk-cost-fallacy.
- Switch to another framework like AF
You might think "that's never going to happen to me" => see Murphy's law
If options were truly optional they would be extensions, not part of the core framework. The fact that priority messages are part of the core framework is a strong indicator that it is not possible to create the same behavior with the API. Thus, it is not optional but an important feature of the framework.
14 hours ago, Aristos Queue said:While the learnability of a framework might be impacted by options, I don't think the complexity is changed by them. Does that make sense?
As a user certainly, yes.
-
1 hour ago, ShaunR said:
But I was asking who is the maintainer?
According to the activity log @Rolf Kalbermatter is the only active user for at least the past 6 years (log ends there): https://sourceforge.net/p/opengtoolkit/activity/?page=1&limit=100
15 hours ago, Jim Kring said:If the aim is to promote better code and collaboration in OpenG, then what would help is to contribute/propose some ideas, especially around processes and structure for contribution.
@jgcode compiled a nice list some time ago. Not sure if all of these are done yet:
Here are some ideas that come to mind:
- Allow the community to participate in the project (create and maintain tasks/issues/features, add maintainers, add admins, etc...)
- Bring back openg.org (could be a different domain) and allow the community to contribute to the site via pull requests
- Split the monolithic repository into separate repositories for each project for best practice (and to prevent linking between projects)
- Convert the SVN repository to Git to allow offline branching, pull requests, etc...
- Use tags when releasing new versions, this allows everyone to use a prior version if needed.
- Add documentation for how to deploy new versions (the building process).
- Add documentation about which LV versions to use and what tests to perform before opening a pull request.
- Use a single license for all projects.
- Add a CLA to ensure the license holds for all contributions
- Work on Feature requests, bugs and change request (there are a lot)
15 hours ago, Jim Kring said:There are several efforts on the roadmap for OpenG, and we can certainly use some helpful participation.
- Share your thoughts
SF is a good place for a small team of developers, working on their project. Users are only meant to report issues and make feature requests. All development is taken care of by the admins/maintainers. Although there are ways to do pull requests, they are very inconvenient and tend to scare potential contributors away.
In my own experience, there are a few ways to revive a project like this:
- Get the original admins back to the project (unlikely, they left for their own reasons)
- Add new admins/maintainers who have full authority over the project => Requires at least one responsive admin / SF is difficult for contributors (compared to GitHub)
- Do what @Michael Aivaliotis did. Archive the original code base, move to a simpler platform and build on top of what is currently available.
Option 3 is most likely to bear fruit.
-
 2
2
-
Here are some common files that could be helpful:
- The contribution guidelines are shown for pull requests: https://help.github.com/en/articles/setting-guidelines-for-repository-contributors
- LabVIEW versions, build instructions and the release process are commonly placed in a README file: https://help.github.com/en/articles/about-readmes
- The license can be managed in a similar fashion: https://help.github.com/en/articles/licensing-a-repository
All of these files, if they exist, add to the GitHub experience. For example: https://github.com/microsoft/vscode
-
1
-
1 minute ago, Michael Aivaliotis said:
I think Github uses the email address, not the username.
They do: https://help.github.com/en/articles/setting-your-commit-email-address
-
@Michael Aivaliotis You are right, organizations are the only way to group projects. Just as @JKSH said, a prefix is very helpful in finding things.
On 10/5/2019 at 9:00 PM, Michael Aivaliotis said:@LogMAN, Is it possible to remap a source forge username to a GitHub username?
On 10/5/2019 at 9:43 PM, Michael Aivaliotis said:I've started adding repos:
Looks like you figured it out
")
-
2 hours ago, Rolf Kalbermatter said:
Do I have to redo that to get it in the new GitHub stuff?
I suggest informing all active contributors, that way everyone involved has a chance to push their changes before import.
2 hours ago, Rolf Kalbermatter said:And I'm still busy trying to add support for symlinks and utf8 filenames to the lvZIP library.
The import script supports branches. If you upload your current status as a branch (inside the /branches/lvzip/ folder), it will be detected and imported. Once the repository is uploaded to GitHub you can simply continue working on the branch using Git.
2 hours ago, Rolf Kalbermatter said:My SF account name is labviewer.
You have a chance to match it with your GitHub account (see 'authors-transform.txt'). This is only possible during transformation, however.
-
59 minutes ago, Michael Aivaliotis said:
Authors - The conversion I went through had the ability to add email addresses to the author names. I just don't know what the email addresses are for the authors in Sourceforge. I've attached the author list if anyone wants to help flesh out the email addresses.Then we can rerun the conversion.
The simplest way is to add "@users.noreply.sourceforge.net" to make them valid addresses that don't collide with any existing GitHub user (GitHub and SF both support these). It should be sufficient for this task. Here is my version: https://gist.github.com/LogMANOriginal/c4109873a5d524387d3fb46f5b83aa0a
59 minutes ago, Michael Aivaliotis said:Branches and tags. - I looked at the SVN repo and there's only one branch, SVN does not due branches well, so I'm not surprised nobody used that feature. There are a few tags and those are very old, circa 2007. Not sure if anybody cares about those. It seems the tagging procedure (if any) was dropped long time ago. You should be tagging with every release but that does not appear to have happened.
I agree. From what I can tell the reason it didn't work correctly is because each project has its own branch/tag subfolder. None of the standard systems support these (including git-svn). Find below a solution that can handle them.
59 minutes ago, Michael Aivaliotis said:One repo - The original SVN was a single repo, this is why i kept it the same. The conversion is a lot simpler. Breaking up a single SVN repo into multiple GIT repos and keeping the history intact seems complicated if you have commits that include files that cross library virtual boundaries. If you can think of a way to do this, that would help.
Done, see below.
59 minutes ago, Michael Aivaliotis said:Commit messages. - The commit messages are all there. It's the URLs inside the messages that are not pointing correctly, but I'm not sure what they should be point too and how to fix that during the conversion. Also, what if SourceForge changes the URL structure later? Again, is this important?
Sorry, my explanation wasn't very clear. My point is, that the original commit message actually doesn't have these URLs inside (see SF vs. GitHub). It was probably added during the Atlassian conversion process.
59 minutes ago, Michael Aivaliotis said:The alternative is to start fresh and create multiple GitHub repos, with the latest revision of the source. Then the SVN repo can be an archive if anyone wants to get at it.
I welcome your help if you can create scripts to solve some of the above problems.
Here you go: https://gist.github.com/LogMANOriginal/fa1e59703c41e27758bcb935f15bea21
The script must be placed in an empty folder next to 'authors-transform.txt'. It must be marked as executable (runs in bash, not sh). svn and git must be installed of course. Then start the script via './openg_import.sh' and it should work (unless it breaks of course).
It does a few things:
- Lookup all projects, branches and tags
- Import all projects into dedicated Git repositories
- Cleanup the Git repository (i.e. tags are imported as branches, so they need to be fixed)
The output are 39 bare git repositories, one for each project with full history, branches, tags and commits. Enjoy 😉
-
1
-
 1
1
-
- Popular Post
- Popular Post
It is good to finally see some movement in OpenG.
Git and GitHub are also the right choices (Bitbucket would probably also work). Even novice programmers will be able to participate this way. 👍That said, the current repository has a few problems:
- No tags
- No branches
- All projects in one repository
- Changed commit messages (the links in the commit messages are non-functional)
It is possible to transform an SVN repository into a Git repository while maintaining all tags and branches and updating the committers (because Git uses email addresses and SVN doesn't). Here are some instructions I used in the past for such jobs (instructions are for Linux of course): https://epicserve-docs.readthedocs.io/en/latest/git/svn_to_git.html
For OpenG this process is a bit more complex because of the way the repository is structured (i.e. tags inside folders for each project), so the scripts must be adjusted to take this into account.
I also suggest splitting the project into multiple repositories during this process to improve maintainability (unless there is a reason why it needs to be one repository).I could prepare the scripts to automate this process if you are interested.
-
3
-
2 hours ago, drjdpowell said:
Unfortunately, there is a significant learning curve for all frameworks, so it is hard to compare them.
You are right, frameworks do have significant learning curves. Still, if a framework can (potentially) satisfy your needs, even if it looks very complex, you shouldn't be afraid to take a closer look.
You can probably filter out most of the frameworks by reading the readme. No need to learn and compare all of them (unless you are scientifically interested of course 😉).
3 hours ago, drjdpowell said:Here though is a GDevCon1 talk by Richard Thomas, where he discusses frameworks
Very interesting, thanks for sharing!
Among other things, he lists quite a few frameworks, some of which haven't been mentioned yet (see timestamp 19:32).
I couldn't find the slides, so here is my attempt to restore the links:- Composed System STREAM (bitbucket)
- Dave Snyder Lap Dog API (GitHub)
- Delacor DQMH (product page)
- James Powell Messenger Library (bitbucket)
- JKI State Machine Object (built on JKI State Machine) (GitHub)
- Mark Balla Message Routing Architecture (LAVA)
- NI Actor Framework (part of LabVIEW)
- NI Distributed Control and Automation Framework (DCAF) (product page)
- S5 ALOHA Application Framework (product page)
- Event Source Actor Package (NI forums)
-
2
-
15 minutes ago, Michael Aivaliotis said:
What is important in choosing a framework?
Here are my main points. Most of them are only indirectly connected to programming:
- It should be necessary; Don't use a framework just for the sake of using it.
- It should solve a problem or provide desirable features, whatever that means for your project.
- Its external complexity should be reasonable for the task.
- It should provide a way to track and fix bugs without having to depend on 3rd-parties (what do you do if they disappear?).
- If it's an essential part of your project, make sure to invest enough time to understand its limitations.
There are of course a range of quality attributes that should be taken into consideration. Which ones are important depends on the kind of project you are working on.
Of course, do whatever you want for throwaway projects.1 hour ago, Michael Aivaliotis said:Jon argued that the complexity of a framework is secondary to the ability of a framework to allow certain programming concepts to be used during development. One being, separation of concerns. if you look at slide 4, Jon vehemently disagrees with that statement. In other words, you should not look at a complex framework and be afraid of it. Don't focus only on how easy it is to learn or get going with it.
Of course we shouldn't be afraid to learn about new frameworks, no matter how complex or simple they may appear. Even if we decide to never use them. How else would you know if they are up for the job?
Once you know their abilities and limitations you can make them part of your architecture design. The complexity is secondary indeed. -
I don't have good examples to share, but here are a few helpful links for you:
QuoteA Data Value Reference (DVR) is shared memory location where the location to the data is passed on the wire as a reference rather than passing the data. It keeps memory copies from being created by using In Place Element Structures to read and write to the data. DVRs are automatically locked from other writers while a process is writing to it and has the option for multiple parallel reads.
-- https://labviewwiki.org/wiki/Data_Communication#Data_Value_Reference_.28DVR.29
NI has an article dedicated to DVRs, which also explains the fundamental idea: http://www.ni.com/product-documentation/9386/en/
Here is a short video that explains how to use a DVR and some of the pitfalls: https://www.youtube.com/watch?v=VIWzjnkqz1Q
Of course, you'll find lots of topics related to DVRs on this forum.
-
1
-
-
- Popular Post
We use a variety of frameworks/templates/patterns for our architecture:
- The Actor Framework is used for asynchronous UI operations and long-running data processing tasks.
- Queued Message Handlers (not using DQMH or QMH template) handle simple asynchronous tasks.
- Action Engines encapsulate privately shared data for our translation and general I/O libraries.
- (Queued) State Machines ensure that everything runs in order.
- The proxy pattern is used to interface most customer libraries.
- We have our own frameworks for the test execution engine and test libraries (message based).
I find the publicly available frameworks and templates (DQMH, Messanger Library, NI templates, etc...) very valuable for learning and to get things started quickly.
More advanced projects, however, require a deeper understanding of the underlying patterns in order to develop your own architecture (which may or may not utilize these frameworks/templates).4 hours ago, drjdpowell said:I pick "Messenger Library", though as I developed that, my honest answer is that I use my own internal framework.
In your case these are synonymous 😋
3 hours ago, hooovahh said:It sounds like a lot of extra bells and whistles...
"Any sufficiently advanced technology is indistinguishable from magic." (Arthur C. Clarke)
For some reason that just popped into my mind...
3 hours ago, hooovahh said:...there are times I'll start a new project just doing my own thing from scratch. And every time I've done this I ended up regretting it because some feature was built into Glued that I would have to re-write or hack in my custom project. Over the years I've just convinced myself that even small projects should start with some actor based design.
If your entire architecture and thought process is fundamentally based on actors, any small project will of course have to depend on it as well. That is, unless you are willing to rethink (and probably reimplement) the fundamental architecture.
Then again, why reinvent the wheel?
-
3
-
@hooovahh is right, this is not doable. Your executable doesn't contain the source code and without the source code you cannot compile the application. If the source code is lost, you can either re-program the application (probably very costly) or convince your IT department to allow installing the LV2009 RTE for this particular executable.
That said, it is possible to copy the executable and the entire RTE to the target computer manually, for example as part of the "installer" for your executable (IT department mustn't know 😉). We have done so in the past (for the same reasons) and it works like a charm. Of course, this only works for utility applications. It doesn't work if your application depends on other drivers like VISA and the like. If this is not a problem for you, just copy the RTE folder from the NI installation directory ".\Shared\LabVIEW Run-Time\2009", put your executable inside and be happy. I just ran your application on a clean Windows 10 virtual machine and it starts without errors and terminates after a few seconds. It's worth a try in my opinion.
-
1
-
-
I had the same issue just now. Looks to me like something is wrong with the database (maybe an incomplete update?).
This is the closest information I could come up with: https://www.mediawiki.org/wiki/Topic:U26n1a1pgo0078ttInterestingly enough, after this error, there are two entries of the same file with the same timestamp.
The preview correctly shows the file I tried to upload. Still, it shows the old image in articles.
I don't think there is much we can do about it, one of the Admins will have to look into this.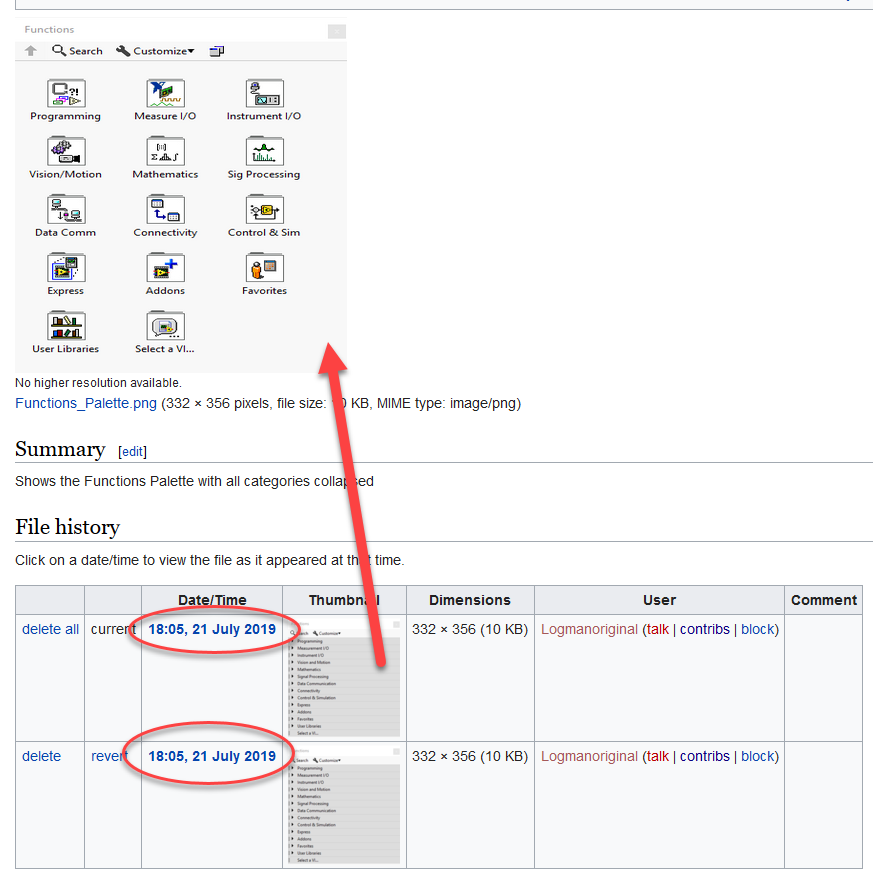
-
The "Individual Offline Installers" link below the download button points to the offline installer.
-
1
-
-
I found some spam on the wiki and would like to request deletion, but there doesn't seem to be an option (probably because I don't have the rights).
So, is there a way to notify administrators (currently only @Michael Aivaliotis?) directly or should we open new topics here?Here are the offending pages.
- https://labviewwiki.org/wiki/Is_there_some_magic_to_get_URLForUbiquityContainerIdentifier_to_work_besides_setting_up_the_Entitlements_Stupid_http://nfltickets.me/baltimore-ravens-tickets/_thing_keeps_returning_nil
- https://labviewwiki.org/wiki/Being_The_Best_Pet_Owner_In_Town:_Tips_And_Tricks_by_Gita_I._Reimnitz
- https://labviewwiki.org/wiki/Caring_For_Your_Kitty:_Top_Tips_And_Advice_by_Sindy_P._Lanterman
- https://labviewwiki.org/wiki/Jijijijijiji_te_dije_q_lo_usaras_http://convenientcarpetcleaning.com/washington/carpet-cleaning-in-pasco-wa/_rapidooo_merf
- https://labviewwiki.org/wiki/Prohibir_el_acceso_a_los_Colocolinos_que_portan_sus_entradas_es_sumar_mas_violencia_a_una_actividad_http://kyleleon-musclemaximizer.com/reviews/_que_esta_en_crisis
- https://labviewwiki.org/wiki/This_man_just_said_she_get_more_miles_than_a_18_wheeler_smh_http://convenientcarpetcleaning.com/new-mexico/carpet-cleaning-in-farmington-nm/_mauryshow
Edit: There also seem to be some orphan files that should be released of their existence:
- https://labviewwiki.org/wiki/File:Bomboniera_solidale_matrimo_2359.jpg
- https://labviewwiki.org/wiki/File:Betting_on_nfl_5601.jpg
- https://labviewwiki.org/wiki/File:Bitcoin_piracy_3126.jpg
- https://labviewwiki.org/wiki/File:Binary_options_3986.jpg
- https://labviewwiki.org/wiki/File:Abogados_Madrid,_Despacho_de_Abogados_laboralistas_2813.jpg
- https://labviewwiki.org/wiki/File:50_shades_darker_1556.jpg
- https://labviewwiki.org/wiki/File:Bomboniere_matrimonio_4754.jpg
- https://labviewwiki.org/wiki/File:Buy_dianabol_3532.jpg
- https://labviewwiki.org/wiki/File:Cakes_4375.jpg
- https://labviewwiki.org/wiki/File:Capetown_wedding_venues_1999.jpg
- https://labviewwiki.org/wiki/File:Cheap_costume_jewellery_2542.jpg
- https://labviewwiki.org/wiki/File:Cercacasa.it_5533.jpg
- https://labviewwiki.org/wiki/File:Cheat_hidden_chronicles_3336.jpg
- https://labviewwiki.org/wiki/File:Chicago_tuckpointing_2777.jpg
- https://labviewwiki.org/wiki/File:Christmas_bows_1816.jpg
- https://labviewwiki.org/wiki/File:Computer_system_clock_2606.jpg
- https://labviewwiki.org/wiki/File:Computer_training_1367.jpg
- https://labviewwiki.org/wiki/File:Contact_Us_-_4664.jpg
- https://labviewwiki.org/wiki/File:Bomboniera_solidale_matrimo_2838.jpg
- https://labviewwiki.org/wiki/File:Descuentos_3610.jpg
- https://labviewwiki.org/wiki/File:Does_wartrol_work_4699.jpg
- https://labviewwiki.org/wiki/File:Dog_ideas_1934.jpg
- https://labviewwiki.org/wiki/File:Driving_lessons_in_solihull_1129.jpg
- https://labviewwiki.org/wiki/File:Driving_schools_in_Solihull_1174.jpg
- https://labviewwiki.org/wiki/File:Find_out_more_about_Access_control_2363.jpg
- https://labviewwiki.org/wiki/File:Fixing_laptop_toronto_1598.jpg
- https://labviewwiki.org/wiki/File:Folding_camper_transport_884.jpg
- https://labviewwiki.org/wiki/File:Food_distributors_4956.jpg
- https://labviewwiki.org/wiki/File:Going_here_2091.jpg
There is no end to this...
- https://labviewwiki.org/wiki/File:Government_Debt_Relief_Programs_2346.jpg
- https://labviewwiki.org/wiki/File:Graphic_design_schools_2392.jpg
- https://labviewwiki.org/wiki/File:Hair_Style_Tips_4044.jpg
- https://labviewwiki.org/wiki/File:Healthcare_Administration_Training_Riverton_WY_1392.jpg
- https://labviewwiki.org/wiki/File:Help_available_5233.jpg
- https://labviewwiki.org/wiki/File:Here_3240.jpg
- https://labviewwiki.org/wiki/File:Hidden_chronicles_cheats_2585.jpg
- https://labviewwiki.org/wiki/File:Hidden_chronicles_cheats_4737.jpg
- https://labviewwiki.org/wiki/File:How_to_sell_gold_3730.jpg
- https://labviewwiki.org/wiki/File:Howto-grow-yourpenis.net_4497.jpg
- https://labviewwiki.org/wiki/File:Htc_one_x_update_2387.jpg
- https://labviewwiki.org/wiki/File:Illinois_home_inspector_directory_5003.jpg
- https://labviewwiki.org/wiki/File:Juridische_vertalingen_5007.jpg
Saving because I don't want to loose progress...
- https://labviewwiki.org/wiki/File:Laserbehandeling_ontharing_1003.jpg
- https://labviewwiki.org/wiki/File:MerrimanSnippet.png
- https://labviewwiki.org/wiki/File:No_No_hair_removal_reviews_2507.jpg
- https://labviewwiki.org/wiki/File:Paintball_1581.jpg
- https://labviewwiki.org/wiki/File:Pc_technical_support_toshiba_scarborough_4170.jpg
- https://labviewwiki.org/wiki/File:Personalised_christmas_sacks_and_stockings_5390.jpg
- https://labviewwiki.org/wiki/File:Pool_service_columbia_sc_4213.jpg
- https://labviewwiki.org/wiki/File:Privacy_Policy_959.jpg
- https://labviewwiki.org/wiki/File:Pure_argan_oil_for_face_2042.jpg
- https://labviewwiki.org/wiki/File:Read_here_4467.jpg
- https://labviewwiki.org/wiki/File:Reputation_management_1152.jpg
- https://labviewwiki.org/wiki/File:Reviews_3461.jpg
- https://labviewwiki.org/wiki/File:San_Antonio_Interior_Decorator_2940.jpg
- https://labviewwiki.org/wiki/File:San_Antonio_Interior_Decorator_4834.jpg
- https://labviewwiki.org/wiki/File:San_Antonio_Interior_Design_3474.jpg
- https://labviewwiki.org/wiki/File:Schedule_a_carpet_cleaning_2023.jpg
- https://labviewwiki.org/wiki/File:Smartrank_778.jpg
- https://labviewwiki.org/wiki/File:Social_bookmarking_service_1160.jpg
- https://labviewwiki.org/wiki/File:Social_bookmarking_service_1318.jpg
- https://labviewwiki.org/wiki/File:Social_bookmarking_service_1515.jpg
- https://labviewwiki.org/wiki/File:Social_bookmarking_service_2486.jpg
- https://labviewwiki.org/wiki/File:Social_bookmarking_service_2917.jpg
- https://labviewwiki.org/wiki/File:Social_bookmarking_service_3584.jpg
- https://labviewwiki.org/wiki/File:Social_bookmarking_service_3672.jpg
- https://labviewwiki.org/wiki/File:Social_bookmarking_service_3744.jpg
- https://labviewwiki.org/wiki/File:Social_bookmarking_service_4150.jpg
- https://labviewwiki.org/wiki/File:Social_bookmarking_service_4849.jpg
- https://labviewwiki.org/wiki/File:Social_bookmarking_service_5002.jpg
- https://labviewwiki.org/wiki/File:Social_bookmarking_service_5239.jpg
- https://labviewwiki.org/wiki/File:Social_bookmarking_service_5436.jpg
- https://labviewwiki.org/wiki/File:Social_bookmarking_service_757.jpg
- https://labviewwiki.org/wiki/File:Social_bookmarking_service_880.jpg
- https://labviewwiki.org/wiki/File:Too_much_iron_in_your_blood_1972.jpg
- https://labviewwiki.org/wiki/File:Toppik_uk_4349.jpg
- https://labviewwiki.org/wiki/File:Used_iphone_3_for_sale_1589.jpg
- https://labviewwiki.org/wiki/File:Valley_view_casino_1963.jpg
- https://labviewwiki.org/wiki/File:Video_promotion_by_ytpros_2952.jpg
- https://labviewwiki.org/wiki/File:Watch_avi_on_android_3765.jpg
- https://labviewwiki.org/wiki/File:Web_design_1869.jpg
Done.
-
2
-
9 hours ago, Aristos Queue said:
You people are so laid back and forgiving. I’m an editor on multiple wikis across cyberspace, and none of the others are anything less than draconian.
LabVIEW doesn't backfire for misspelled words, which means we don't freak out every time we see one.

Here are a few suggestions for draconian rules on the LabVIEW wiki 😇
1.1 Uploading sample code to the wiki
- Put input terminals to the right, output terminals to the left (on the block diagram and VI terminals)
- Use backwards wiring
- Show terminals as icons
- Don't use shift registers (use local variables instead)
- No error handling (disable debugging)
- Take a screenshot with your mobile phone (compress as much as possible before uploading)
Seriously, though. The wiki should have some guidelines for the structure and content of each article. Otherwise it will decay to some kind of link collection (formally known as favorites) with no added value (example). Those guidelines should be more general, as in:
- A page must be informative
- It should focus on one topic (create new pages for other topics)
- Citations must be marked clearly using the format "<blockquote>Someone said this!</blockquote>"
- ...
My point is: This page should be updated (last edited on 7 October 2007, at 11:18): https://labviewwiki.org/wiki/LabVIEW_Wiki:Manual_of_Style
-
1
-
2 hours ago, poc said:
Where did you find it?
I don't think they found the documentation, just an answer to their particular question or a solution to their particular problem. As Rolf mentioned above:
On 10/3/2007 at 9:18 AM, Rolf Kalbermatter said:… someone ELSE could put some time into it to help with documentation if they feel it is needed.
Documentation probably still doesn't exist.
-
No, that is not possible. Here is the official KB article from NI
https://knowledge.ni.com/KnowledgeArticleDetails?id=kA00Z0000019LtOSAU&l=en-US
-
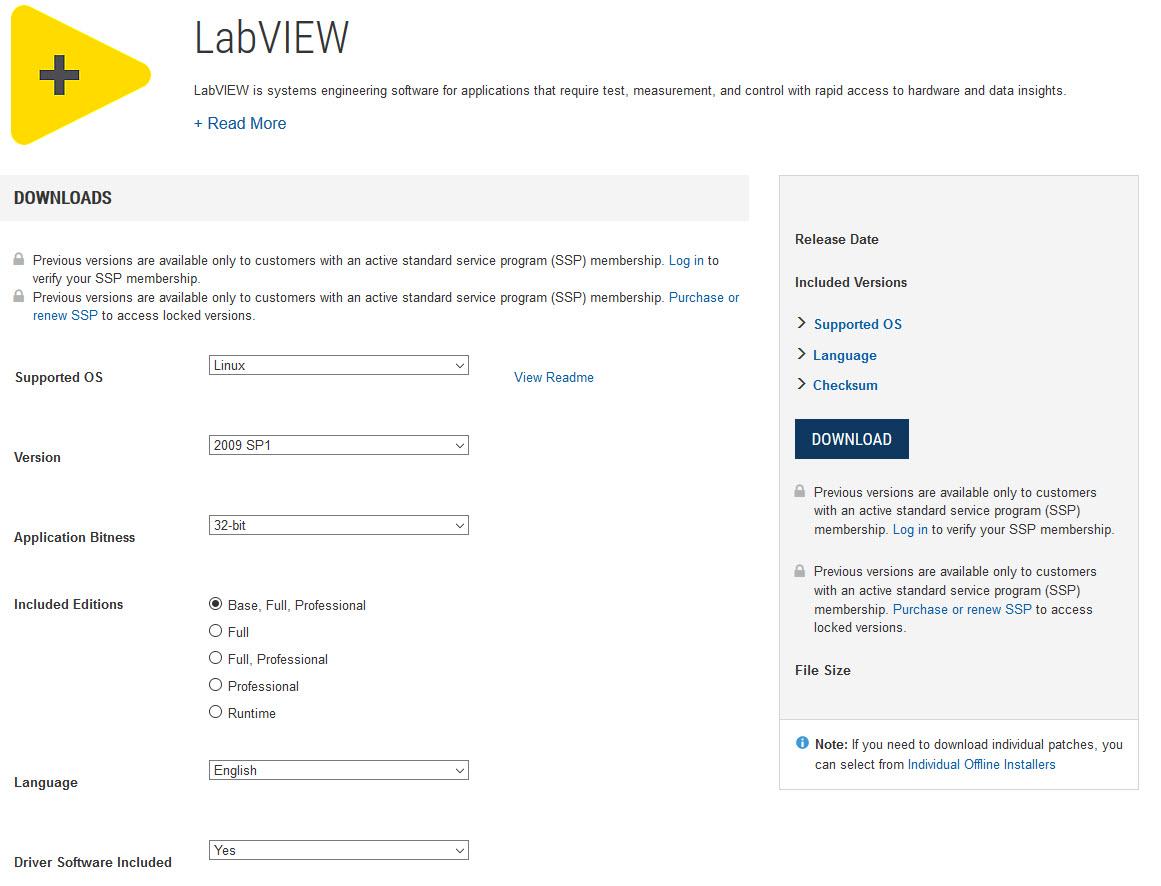
Very strange indeed. You are right, these extensions should not affect any of this.
I just installed the "Disable JavaScript" addon and can reproduce your behavior with the download button and version selection. In my earlier post you see the "normal" page. This is how it looks with JavaScript disabled:
Also, the download button now statically points to http://www.ni.com/en-us/support/downloads/software-products/download.labview.html#
-
13 minutes ago, Rolf Kalbermatter said:
I get redirected to the nl-nl page anyhow no matter what I do.
You need to change the location manually at the bottom of the page. After that you should always get to the same site.
 13 minutes ago, Rolf Kalbermatter said:
13 minutes ago, Rolf Kalbermatter said:And on that I can't download any versions prior to the 2019 version no matter if I only select the runtime version or if I'm logged in or not.
That is strange indeed. I just tried on another browser and can't seem to recreate this behavior, no matter which location I choose.
13 minutes ago, Rolf Kalbermatter said:On the page that I get to when clicking on the LabVIEW icon on the earlier mentioned download portal I get to https://www.ni.com/nl-nl/support/downloads/software-products/download.labview.html# (without the number at the end) and while it seems I can download anything (the Download button is always enabled), nothing happens except a page refresh when pressing that button.
Do you have extensions installed which block JavaScript or tracker?
They can sometimes cause strange results like this, especially if contents are dynamic (as the download button or the lock for Linux/Mac versions).
-
7 hours ago, MikaelH said:
Where did patch LV2018SP1 f4 go?
http://www.ni.com/product-documentation/55001/en/The link at the bottom will bring you to this page http://www.ni.com/en-us/support/downloads/software-products/download.labview.html#305508
You just have to select 2018 SP1 Patch and click download. This will download the f4 (latest) patch.
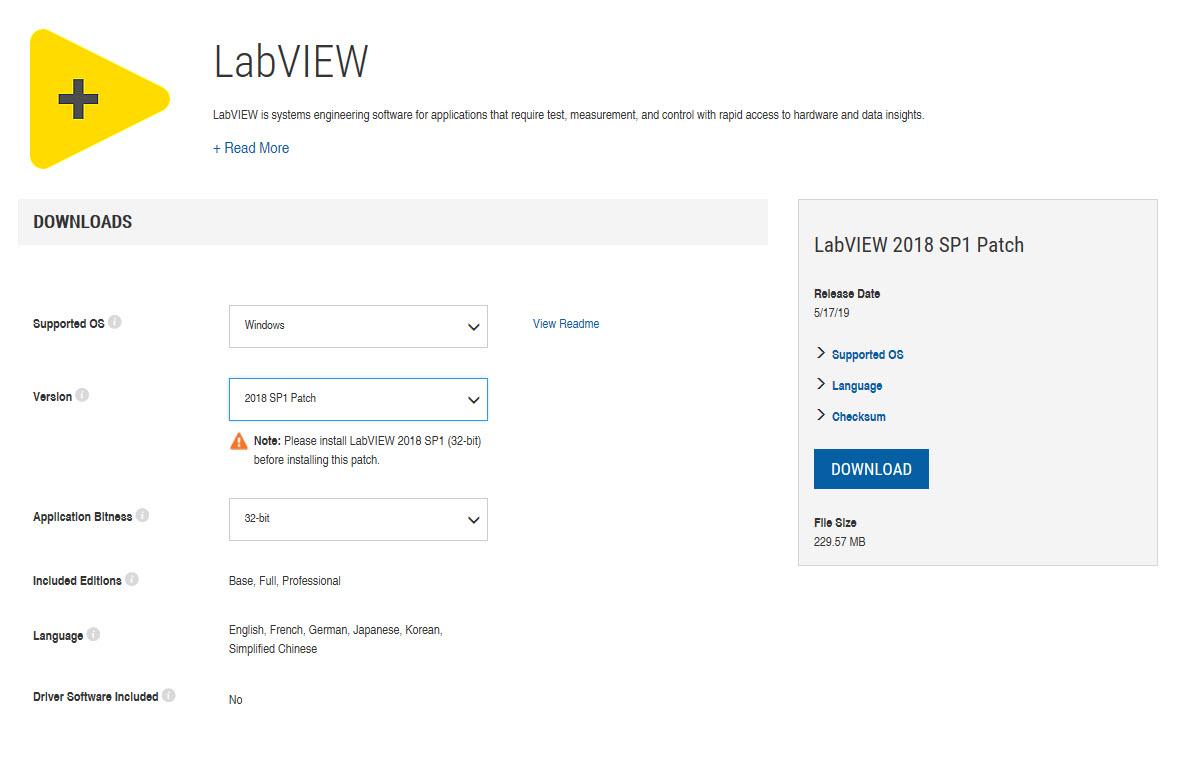 17 minutes ago, Rolf Kalbermatter said:
17 minutes ago, Rolf Kalbermatter said:However that page is borked in many ways (as a lot on the NI webserver)
The en-us version is pretty stable in my experience (except for a few dead links here and there). Can't say much about the others.
19 minutes ago, Rolf Kalbermatter said:and depending on from where you come it won't allow you to download anything (even simple runtime installations) even if you are logged in with an account that has an associated SSP license, or it will allow you to download absolutely everything even without valid user account login. 😭 Why am I not surprised!!
I'm still surprised they bother to check the associated SSP. Considering that the License Manager checks it anyway.
-
1
-
-
Thank you so much for sharing

-
Here are some additional pointers that might be helpful
- LabVIEW Help : https://zone.ni.com/reference/en-XX/help/371361H-01/lvconcepts/custom_cont_ind_type/
- UI Interest Group : https://forums.ni.com/t5/UI-Interest-Group/ct-p/7019?profile.language=en
- LabVIEW Playlist (see NI LabVIEW UI Tips videos) : https://www.youtube.com/playlist?list=PLE91C12E1A5E62F88
I also found a blog post with pictures that show the general process for customizing controls.
https://www.dmcinfo.com/latest-thinking/blog/id/9428/basic-labview-ui-control-customizationIf you are interested to see what is possible with LV, search for "2016 NIWeek - Designing Advanced User Interfaces in LabVIEW".
https://lavag.org/topic/20645-labview-videos-tecnova-download-site/-
1
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Poll on Architecture and Frameworks
in Application Design & Architecture
Posted
I wish it were that easy. Yes, they all adequately describe what's being talked about, but only when used in the same context. For example, what do you mean by "code complexity"?
It is my understanding that the first two points are about "readability", the third is "time complexity" and the last "code complexity".
Good point. "accidental complexity" confused me as well, but the more I thought about it, the more it made sense (good for me, I know). In my opinion "accidental complexity" is a good way to describe how architectures and frameworks can go sideways very easily if decisions inadvertently lead to additional complexity (code complexity, system complexity, whatever). I don't think it's an official term though.
Then again, English is my second language. I'll use that as an excuse 😋