
LogMAN
-
Posts
717 -
Joined
-
Last visited
-
Days Won
81
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by LogMAN
-
-
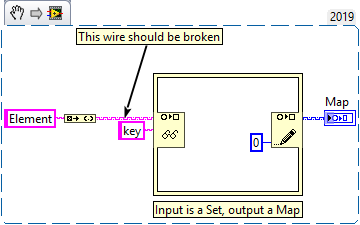
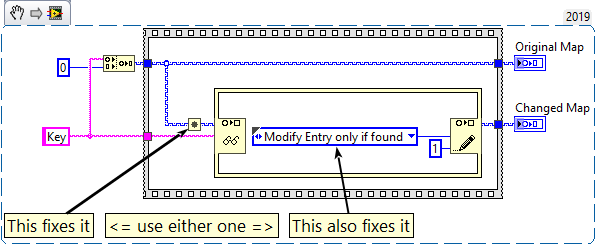
Here is another bug I discovered in LV2019+ which reliably crashes LV. Simply connect a set to the map input of the Map Get / Replace Value node on the IPE:

This VI is executable in LV2019 SP1 f3, which means that you can actually build that into an executable without noticing.
I have reported this, but there is no CAR yet.
-
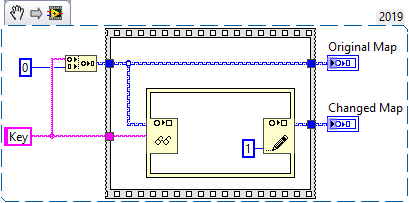
I want to share a bug that exists in LV2019+ that results in data being overwritten in independent wire branches when changing maps with the Map Get / Replace Value node of the IPE. Here is the code:
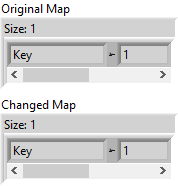
This should produce two maps
- <"key", 0>
- <"key", 1>
But the actual output is
- <"key", 1>
- <"key", 1>
As it turns out, Map Get / Replace Value breaks dataflow. There are two workarounds for this issue.
- Use the Always Copy function
- Wire the Action terminal of the write node
This was reported to NI with the bug report number #7812505.
-
 1
1
-
I agree with @hooovahh. This is likely an issue with Parallels. I don't have a VM to try this, but I assume that your cursor leaves the VM for a brief moment (the "stuttering"), which causes this strange behavior. Parallels probably buffers the cursor info and restores it in a way that is incompatible with LV.
Does Parallels allow you to "capture" the cursor, so that it can't leave the VM without pressing some master key? I can imagine this fixes the issue.
-
I have never seen such behavior in any version of LabVIEW. That said, I use 32 bit. Perhaps it's specific to 64 bit?
If Windows scaling is enabled, try disabling it. I had strange behavior because of that in the past.
-
Sounds like the compiler is busy figuring things out.
Just tested it on the QMH template and it is as fast as always (1-2 seconds). That said, the template is not very complex. Do you get better results with a simple project like that? -
On 7/9/2020 at 12:14 PM, JB_1592 said:
I work with a small team with a badly overdue need for SCC. I find myself in a position to change some things, but, unfortunately, I've spent most of my career here and I'm a bit lacking in experience myself, so I've been looking into available options for a few days. The more I research, the deeper down this rabbit hole I go. Maybe a bit of discussion will help solidify the tools and features I'm looking for, and this seemed a good place for it since "works well with LabVIEW" is a factor.
Whichever system you choose will require a lot of time and effort to implement by the whole team. Don't think that you can simply choose a tool that "feels right" and expect everyone to accept your opinion. I made that mistake and had to rethink my strategy after a disaster of a start (only one of us adopted the new system - me
). You also don't want to be responsible for everything, so it's best to have the majority on your side before you enforce a new system.
Your main focus should be on your workflow and your requirements to decide which tools are right for you.
For example,- do you have small projects or big?
- how many developers work on a single project?
- are your projects deep (multiple projects in separate repositories), wide (multiple projects managed in a single repository), or flat (single repository)?
- do you always have access to your servers when developing?
- do you have a project leader, or is each project managed by a single head-developer?
- who are your stakeholders and which kind of reports, documents, and access rights to they need?
- how are bugs reported to your team?
- do you need to give access to your source code and bug trackers to third-parties (external)?
- what kind of development cycle is used for your projects?
- do you need to integrate additional platforms or tools (i.e. CRM)?
While it is kind of easy to state those questions, the answers are not that simple to give. I still struggle to answer some of those (among other) questions and simply made gut-decisions where necessary.
Also, don't forget to include your team in this!
Simple questions like "Where do you struggle the most?" do wonders if you care to listen.Here is our tooling for reference:
We use- Git for source control,
- Jira for bug tracking, planning, and reporting, and
- Confluence for the wiki.
- Our developers are free to use any client they want (i.e. Sourcetree), as long as they adhere to the commit guidelines.
- We still don't have a working CI/CD solution, so each developer builds their own project (or in case of larger projects, the head-developer). Unfortunately LV is exceptionally slow in this area, especially for large projects. We are actually at the edge of what we consider acceptable.
In the past we used ZIP files, later SVN. I don't think I need to explain why we went away from ZIP files. SVN, however, we discarded because it wasn't the right fit. Occasionally we have to change programs on-site, without server access, and want to be able to commit changes. SVN simply is too much effort for such a workflow. You need to remember to checkout and lock files before you travel and hope that nobody breaks the lock. Lessons learned from using SVN: Don't trust your colleagues 😱
-
1
-
19 hours ago, JB_1592 said:
I'm not saying you are wrong about the CLI being better for some tasks, but this message seems clear enough to me.
Nice, that message did not exist in the version of Sourcetree I used a few years ago. Glad to know they keep improving. Still, some genius decided to make "Yes" the default answer...
-
7 hours ago, Aristos Queue said:
It is because it is the only tool that can manage the full complexity of massive software teams, parallel releases, compression of features, etc, and the folks who use it daily just deal with it and get used to it.
Let's also not forget that Git was originally invented by Linus Torvalds to manage the Linux kernel with thousands of contributors, commits, and branches being done every day. Although my projects are slightly below that complexity, Git does manage (barely)
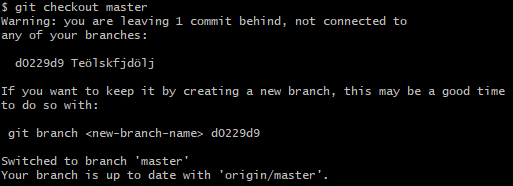
4 hours ago, JKSH said:Yes, Git could be made safer by automatically preserving "detached" branches and requiring the user to manually discard them, rather than automatically hiding them when the user moves away.
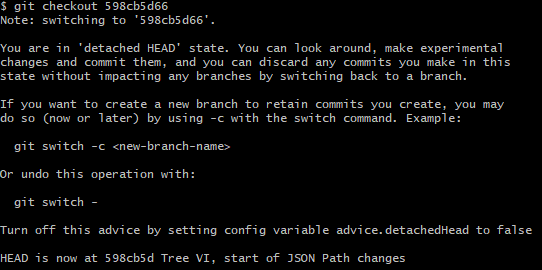
This is the fault of tools like SourceTree. Here is an example of Git moving away from a detached head:
Again, they provide you with the necessary command template to prevent you from loosing track of your changes.
I cannot stress enough how much better the command line interface is compared to any of the tools (at least the ones I have tried). -
- Popular Post
This actually sums it up quite nicely 😋
-
 3
3
-
6 hours ago, drjdpowell said:
What should I read up on to make Git less crap?
Atlassian has comprehensive (and visual appealing) documentation on Git.
- https://www.atlassian.com/git/tutorials
- https://www.atlassian.com/git/tutorials/atlassian-git-cheatsheet
Unfortunately Git has a lot of commands, most of which you'll probably never use. I suggest you play around with it to get used to the workflow and be prepared for your daily job. Just don't do stuff like "git push -f" and you should be fine.
3 hours ago, drjdpowell said:Doubtful. You went from Git from SVN, I'm coming from Hg. In Hg, if you want to go to an earlier commit, you just go to that commit. If you want to make changes, then you make a new branch coming off at that point. If you like those changes, you might merge that offshoot branch with the main one. I have yet to find anything in Git over Hg that is actually useful. I consider the possibility of losing committed work because I didn't realize I was in an "anonymous/unnamed branch" to be a strong negative.
You might find this worth reading: https://sqlite.org/whynotgit.html
5 hours ago, drjdpowell said:The problems I've had have mostly been using SourceTree. I've started to just us TortoiseGit, but it is lacking compared with TortoiseHg that I used to use.
There you have it, your problem is not Git, it's the tools. Have you ever tried the command line?
In my experience, there are many tools that work well with some aspects, but fail miserably at others. They only get you so far before you need some command line Voodoo to fix the "unfixable". Eventually you'll get used to the command line 🤷♂️ (I lost this battle a long time ago)
3 hours ago, Neil Pate said:All I did was roll back to check out some earlier code and my recent changes just "disappeared" from the client. That is very unexpected behaviour. Sure, I was able to get them back by looking up the commits using the reflog because they were not truly missing, but it is really strange behaviour to me.
This is the same reason why I abandoned SourceTree a few years back. Tools like that only give you access to a subset of instructions and they don't even provide ways to undo bad decisions.
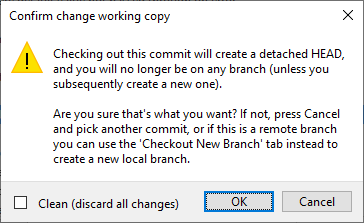
6 hours ago, drjdpowell said:The "detached head" is a good example of the problems with git: confusing terminology for something that has no reason to exist. Why does it even allow commits not on any branch to exist as a possibility, let alone something that is easy to mistakenly do?
To be fair, you do actually get a big warning message (which nobody seems to read, including me):
The command line version of this is much more helpful in my opinion, as it even teaches you some new commands.
There is also no way to mistake it with the normal output.
-
1
-
57 minutes ago, Jim Kring said:
Sorry about that @LogMAN. It should be publicly visible now.
Please try again and let me know:
VIPM KnowledgeBase: Disabling VIPM service (System Tray) startup when LabVIEW starts up
-
1
-
-
11 hours ago, Jim Kring said:
I've gone ahead and posted an official KnowledgeBase entry to make sure people can find this easily, in case the high-level features don't provide enough granularity.
VIPM KnowledgeBase: Disabling VIPM service (System Tray) startup when LabVIEW starts up
I am not authorized to access this page. Senpai? 😢
-
I do actually receive emails from LAVA.
-
 1
1
-
-
8 hours ago, Mads said:
But then so does lots of the lvlib-stuff - seemingly disregarding that is destination is explicitly set to be the executable.
I've never seen this kind of behavior. Only support files like documents, shared libraries and the like are supposed to be placed outside the executable, but I presume you mean VIs. This is very strange.
-
43 minutes ago, Jim Kring said:
Actually, nothing changed with how VIPM installs itself 2020, as compared to 2019 (and older versions). The issue was that the the VIPM 2020.0 (and older) installer framework (e.g. Advanced Installer) needed to be updated for newer versions of Windows. In VIPM 2020.1 (now in beta -- see link above) we've addressed this issue and it should install without issues.
That said, there were some bugs in NI's LabVIEW 2020 installer that causes it to fail to correctly install VIPM 2020, in some cases -- e.g. the issue where it sometimes would fail to start. NI has been working with JKI to fix this.
Wow, this is good news! I'll give it a try.
46 minutes ago, Jim Kring said:Any feedback/issues you have are important, so please do post them and know we're listening. It's hard to keep tabs on conversations that happen in various LAVA threads, so if you'd like to see something improved/resolved, please do post it in the VIPM forum or PM me.
Point taken, I was going to post on the VIPM forum but then this thread happened and I couldn't resist...
48 minutes ago, Jim Kring said:This can be disabled in the VIPM settings file, here:
"C:\ProgramData\JKI\VIPM\Settings.ini"
You can also disable the VIPM Service in the Task Manager under Startup. That said, I would like this to be opt-in or at least opt-out. Maybe on first start or during installation.
-
1
-
-
4 hours ago, Mads said:
build insists on putting the support functions as separate files together with the plugin
You can specify a destination on the Source File Settings page of your build specification. The default is "Same as caller". I assume your plugin is set to a custom destination, but your support files aren't, so they are put in the same folder as the caller.
If you explicitly set the destination for your support files to the application executable, it will place them inside the executable.
-
9 hours ago, Michael Aivaliotis said:
I tried VIPM2020. It was buggy for me. I also didn't like the new login "feature" and the notification taskbar malware. So I reverted to VIPM2019.
I agree, that feature should be opt-in and the logins are a bad joke. Also, the installer creates a task for the Task Scheduler without consent. This is prevented by our IT policies and ultimately fails the installation - silently for NIPM and with an error message for the offline installer.
VIPM 2019 it is 👍
-
- Popular Post
1 hour ago, Neil Pate said:The new colour scheme is growing on me, I quite like the green.
It is growing on me too (with exceptions mentioned before). It actually feels refreshing in some sense, which is probably what they intended.
1 hour ago, Neil Pate said:I think what we are forgetting is that none of this guff is for us... we are already customers and need no reminding of the benefits of spending your whole instrumentation budget on a cRIO! This stuff is to get the next million customers, the young engineers who might have never heard of National Instruments. The slogan is meant to ignite passion in young people, not to excite the already battle hardened. I do think the event was completely overhyped, but this is what marketing is about.
It seems to me that they have totally forgotten about their existing customers. I actually haven't received any invitation, message or notification from NI about any of this (did anyone?). We are the ones that are most excited to use their products now and that doesn't seem to be worth anything. We are also the ones who are passionate about sharing our knowledge and excitement with the next generation of engineers. VIWeek, LAVA, LabVIEW Wiki, OpenG, the Idea Exchange and many more initiatives are prime examples of this. It is very easy for excitement to turn in to frustration if you don't know what is coming next.
Don't get me wrong, I'm a strong supporter of NI, LabVIEW and anything that comes with it and I sincerely hope that I can continue to do so for the next decades. I'm just frustrated that so many exciting new things are "dumped" in a way that make me feel left out.
-
3
-
49 minutes ago, X___ said:
Be so kind as to distill the substance of it in a post here.
- About 35 minutes of people talking about how awesome everybody is (for some reason nobody mentioned me 😢).
- At 35:30 they finally address the new design.
- At 44:00 they talk about a six year commitment for the new roboRIO controller (whatever that is) for the FIRST robotics competition, financial support for students, equality and inclusion - quite important messages these days.
- At 45:56 they announce a campaign to "put a lens on 100 game-changing breakthroughs" (collected via Twitter). They will post the best ones here (one per week).
- The last 5 minutes are NI employees from all over the globe.
Pretty much what you would expect from marketing material 🤷♂️
The new design probably makes green-screen capture easier.
-
1
-
-
8 hours ago, Aristos Queue said:
I liked it in theory, but I'm seeing a bunch of warnings online about Stylish having become malware that is shipping private information to third-party. You might want to investigate.
Thanks for the heads-up. I actually limited access to *.ni.com, specifically, so I should be fine.
-
I would like to end the day with positive (and hopefully constructive) feedback, so here is a list of pros on the new design:
- All the old links still work
- Broken pages (that I knew of) are fixed
- The top navigation bar takes less space (148px to 97px), which gives a bit more space to the page content
- Mobile view works much better than before, at least for general navigation (most of the content didn't change as far as I can tell)
- All the text in header and footer is bigger than before, which makes it much more readable, especially on higher resolution and smaller screens (not zoomed)
- It "feels" slightly faster than before. Not sure if it's me imagining things, but the site seems more responsive than before (perhaps they improved on lazy loading?)
This is certainly something I can get used to (not that I have a choice anyway). However, I strongly suggest to use a different color palette for content pages. Dark green links, different shades of gray, and black text are almost indistinguishable and look very dull. Please give me some eye candy 😢
Other than that, I'm quite okay with most of the changes.
-
2
-
8 minutes ago, Mads said:
If I have to say one positive thing about the new look its that the color palette is probably very very rare....
Well, they probably didn't find the slider for color and thus decided to fix it later (or their monitors have much higher contrast than mine). For now I have installed Stylish to fix my links. Imagine if this was the default 😊
-
1
-
-
Here is one possible solution. So much fun!
-
 2
2
-
 ). You also don't want to be responsible for everything, so it's best to have the majority on your side before you enforce a new system.
). You also don't want to be responsible for everything, so it's best to have the majority on your side before you enforce a new system.







Down-save from 2019 to 2015 crashes
in Development Environment (IDE)
Posted
I just saved from 2019 to 2015 without any problems, including Error Ring. As @Yair suggested, perhaps mass compiling vi.lib fixes it?