Wouter
-
Posts
129 -
Joined
-
Last visited
-
Days Won
1


Wouter's Achievements
")
Newbie (1/14)
11
Reputation
-
Thanks! Totally missed that. So who is currently the creator of OpenG? And is this maybe something I can do myself?
-
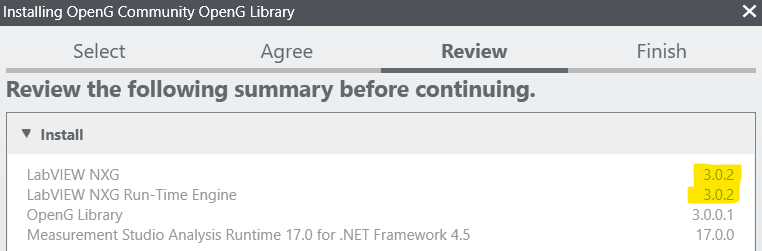
First question, Is OpenG not available for LabVIEW NXG 5.0? When I try to install it via the NI Package Manager I see version 3. Then when I want to install it, I see that the NI Package Manager wants to install LabVIEW NXG 3.0... so I understand that OpenG is only available for LabVIEW NXG 5.0? Second question, (cross post from https://forums.ni.com/t5/LabVIEW/LabVIEW-NXG-Polymorphic-amp-Malleable-VI-s/m-p/4047507#M1160978) How can I create a polymorphic or malleable .giv in LabVIEW NXG? In NXG they are called "overloads" The only information I can find is: https://forums.ni.com/t5/NI-Blog/Designing-LabVIEW-NXG-Configurable-Functions/ba-p/3855200?profile.l... But it does not tell or share how to do this in LabVIEW NXG? Where can I find this information? Or am I just missing something? Images (w.r.t. first question)

-
If you want to know if your data is within population I think it would be best to simply calculate the mean, mean + 3*std and mean - 3std of all datasets and plot those along with your new dataset.
-
Offtopic: You should use randomized data for a fair representation. Maybe the algorithm performs a lot better or a lot worse for certain values. Maybe the functionality posted in the OP functions a lot better for very large values. I would benchmark with random data which represents the full input range that could be expected. Furthermore I would also do the for-loop around 1 instance of the function. Then store the timings in array. Compute the mean, median, variance, standard deviation and show maybe a nice histogram :-) What is also nice to do, is by changing the input size for each iteration, 2^0, 2^1, 2^2, 2^3,... elements and plot it to determine how the computation execution scales.
-
@Steen Schmidt you know that if that is your benchmark setup, that the benchmark is not fair right?
-
Small note: there is a machine learning toolkit available, https://decibel.ni.com/content/docs/DOC-19328
-
Wikipage about this: https://en.wikipedia.org/wiki/Publish%E2%80%93subscribe_pattern Further I was wondering, your current implementation does not support subscription to multiple different publishers (who have a different name) right? That would be a nice feature, another extension would be that you can also publish across a network.
-

Working with arrays of potentially thousands of objects
Wouter replied to Mike Le's topic in Object-Oriented Programming
If it is a 2D array ánd it contains a lot of zero's you should consider using a sparse matrix datastructure. -
What do you mean with LU solver? Do you mean that this solves Ax = b using LU decomposition? Or does it do LU decomposition?
-
Lucky you can't patent software in Europ.
-
offtopic: rather implement multiple inheritance.
-
Good resources for Best OOP Practices?
Wouter replied to Mike Le's topic in Object-Oriented Programming
http://www.planetpdf.com/codecuts/pdfs/ooc.pdf I think this might be a good book. It goes about OOP in ANSI-C. -
Problem with data value reference creation
Wouter replied to DAOL's topic in Object-Oriented Programming
Hmmm... Using 2012 here and today I got the same error as described by the OP. I came to this topic by google. -
Don't the VI's give you the option to create X number of zip files? Each Y Bytes big? Like you see often? filename.rar0, filename.rar1, etc...
-
Need a true source of random numbers for your application?
Wouter replied to Aristos Queue's topic in LabVIEW General
http://www.random.org/ already provides the same functionality for several years. I wrote some VI's to get the random numbers/strings, https://decibel.ni.com/content/docs/DOC-13121