Wouter
-
Posts
129 -
Joined
-
Last visited
-
Days Won
1
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Wouter
-
I thought of something extra aswell. This is nearly the same function as the previous one however this function has a callback as input instead of a list of items. So you can define your own filter function, same terminal type as the wgtk_filterArrayCallback template. Example: now it is not possible to filter all odd elements. If you now build a seperate VI which would check if a element is odd and you give that strict VI ref to the filterArray it will filter all odd elements. wgtk_filterArray (callback).vi wgtk_filterArrayCallback.vit
-
Yes but they aren't wired to the terminal anyhow this is a bit offtopic lets stay ontopic. If you want you can remove them it indeed does not matter.
-
yes but they are not even wired now so as said, and as far as I know LaBVIEW will see it as deadcode and remove it when the code is compiled.
-
Nothing. But i didnt understand why it was build in the first place. Because why would it contain duplicate items? I think its up to the programmer if he wishes to check if the filter list contains duplicates. No because the error inputs are also not used in the terminals. I just put them there because maybe in the future I want to throw a error, then I will wire it. Now LabVIEW will just treat it as deadcode.
-
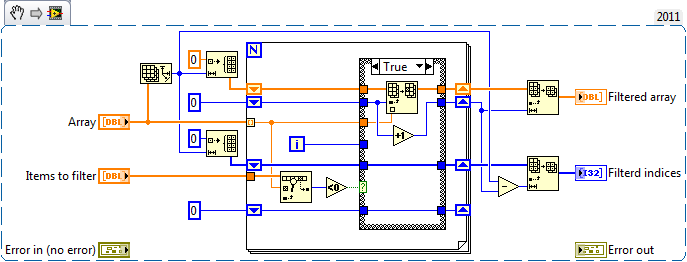
The current implementation is very slow, so I checked if I can do it any faster and well I can :-) al lot also. This is my revised version. Differences: # elements, current array filter, mine implementation array filter 10000 - 30 ms - 0 ms 100000 - 2154 ms - 5 ms 1000000 - after 7 minuts it was still running - 56 ms The code: wgtk_filterArray.vi The only difference is that I do not remove duplicates from the "items to filter". Further in this implementation the "filtered items indices" are returned sorted. Also the code could (theoratically) be even faster by first sorting the "items to filter" and then use a binary search instead of the labview linear search. -edit- small improvement, the second loop iterator for indexing the "filtered items indices" array wasn't necessary. Because it can be calculated by substracting the loop iterator by the iterator for the other array. wgtk_filterArray.vi

-
I get a memory is full error for a size of 1 million Thats because proberbly some intern machine code results are cached.
-
C++ Templates for labview plzzzz
-
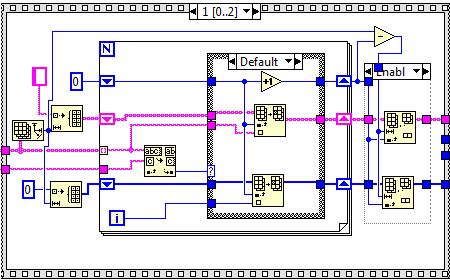
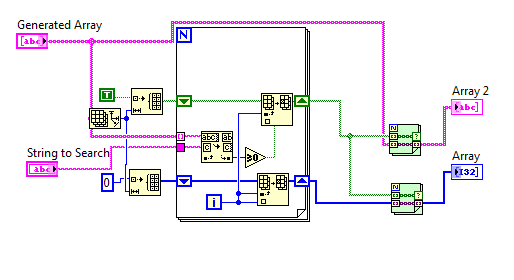
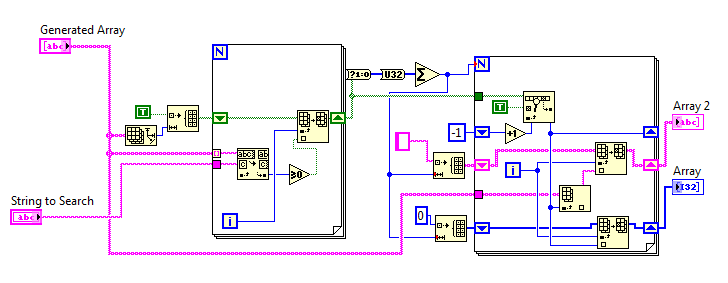
I played with this just now. Let me post my remarks. The tests where done with 1 million elements First off al the first method can be made much more efficient, by just preallocation the data. If the input has 10000 then you should also preallocate a array of 10000 elements for both the string array as the index array. Then after the loop you just split the array and hence remove the elements you didn't use. The first method, (500 ms), is then most times faster then the second method, (550 ms). However of course you can also apply this to the second method. Which makes the second faster by more then 50% (550 ms to 250 ms) (yes the ss is of a subvi, but I did that for other testing purposes after I benchmarked it with the above results, I took the ss of the code when I was finished) I then thought I could optimize it further but my attempt failed. I tried combining the two OpenG VI's into one. You namely do not have to keep track of the indices in the first for loop since they are also recored in the boolean array. The index at which the value is true, is the index of the element that we want to keep. After that you know the exact size of the array you are going to create and you can prealocate that. Then just fill it. However the execution then came back on its original level (+/- 250 ms to 550 ms)
-
meh would rather see time being spend on making templates, like in C++, be made available for LabVIEW.
-

Join me in building a Project Management tool for LabVIEW
Wouter replied to 0_o's topic in Code In-Development
Sorry but imho this is just a example of using the wrong tools for the job. LabVIEW is great but is simply not made for this. You can do this much better and faster in other languages such as indeed php, python, etc...- 4 replies
-
- 1
-

-
- application metrics
- nightly builds
- (and 3 more)
-
Well that is the problem... I already did. But it is in others opinion that only after discussions things can be implemented. And such when there is no discussion there is no implementation xD Imo when you ask me there should be a different protocol. Just post a candidate, if no one objects just implement it. If there are any complaints after the new release we can always change things back.
-
That is very nice! Which ISO version did you use? ISO/IEC 18004:2000 or ISO/IEC 18004:2006? Because I if you google good you can find the first one as a .pdf on the web. The second you can't (or well maybe... but then your google skills are better then mine )
-
Would you maybe want to publish the code on a public source? GIT? Google code? And maybe even a better start question do you even want to share it? (oh and I don't really care if its messy )
-
Please read this http://www.sqlite.org/whentouse.html.
-
Don't support LabVIEW variants. Uhmmm call me stupid but how do you want to support U64/I64 when the variable size is 1 to 8 bytes you can only support till U32/I32 and not I64 or U64, so my opinion would again be don't support U64/I64. Again don't support NaN's. (or use http://www.mail-arch...g/msg68928.html but then again how to handle +Inf, -Inf) Use ISO8601, thus save as text.
-
Proberbly because its classified
-
To bad we don't... http://forums.ni.com/t5/LabVIEW/Arithmetic-mean/td-p/1940343
-
LV OOP Kd-Tree much slower than .Net, brute force
Wouter replied to jkflying's topic in Object-Oriented Programming
@Aristos Queue Maybe he can use your implementation of linkedlist, tree and the other datastructures etc... Can't find the files anymore though. -
That sir. Was totally awesome...
-
oh and I found one error... The while loop in which q* and r* are calculated is set to "stop if true" this should be "continue if true" because "and repeat this test if r* < b" (However this fix does not make the code work yet unfortunatly...
-
Here the full description of the algorithm...
-
That is correct. The loop runs always 1 or 2 times. Further the algorithm is just a schoolbook algorithm when you divide... for example 25 / 32450 \ 1298 (q) _____25 ______74 (r) ______50 ______245 (r) ______225 _______200 (r) _______200 _________0[/CODE] q* is one of the digits of the quotient and r* is the remainder
-
Ton that thing you say is wrong is actually correct. q*.v[n-2] is wired to the y input and r*.b+u[j+n-2] is wired to the x input. And the less then comparison has this operation x < y. So... r*.b+u[j+n-2] < q*.v[n-2] => q*.v[n-2] > r*.b+u[j+n-2] Further the mod function (x mod y) is defined as: if y = 0 then x else x - y * floor(x/y). Thus the same as LabVIEW interpret it. Thus 20 mod 0 = 20.
-
I'm trying to do some simple arithmetic on very large numbers. I already implemented adding, substraction, multiplying, comparison. I only need to do division but I can't seem to get it working. I already tried a few more complex algorithms and now I just use the algorithm provided by Donald Knuth in the art of computer programming volume 2 (see picture below). I have two different division VI's the __uintDivide.vi is partly based on what is described: here; http://kanooth.com/blog/2009/08/implementing-multiple-precision-arithmetic-part-2.html, it is also a description Knuths algo . The otherone is fully based on how Knuths describes it. For some reason however I can't seem to get it working. It works for some numbers. For example I have two large integers, represented in a u8 array, the number 50 = Uint1[0,5], number 20 = Uint[0,2]. The LSB is at index 0, the MSB in the last index. For 50 and 20 the result is correct. Also when 20 is 21, 22, 23, 24. When 25 it is in a infinity loop when calculating q*. When trying 19 you also get the wrong result. I hope someone can help me figuring out what I'm doing wrong? In the book LabVIEW power programming it is implemented as well, I would also be gratefull that if you don't know either what is wrong with my algorithm you could give me some insight in that implementation. LargeNumbers.zip
-
Any suggestions people?