drjdpowell
-
Posts
1,989 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by drjdpowell
-
I don't understand this bit. Are your "steps" source code rather than built?
-
Could you explain a little more what you are doing. I am confused that you are using TCP (something usually used for communication BETWEEN applications) and having namespace conflicts (which happen when you have multiple paths to the same-named thing on the SAME instance). On no condition would I recommend renamespacing the library, as TCP involves flattening the messages to strings, and that uses the class names, which you are changing. The TCP Messengers override the usually LabVIEW flattening for some common messages for reasons of performance, replacing the class names with a much-shorter format using an enum for class type. This is why some messages will still work. But this is strictly limited. I had imagined, when you first brought up Teststand and TCP Messengers, that you were building a separate LabVIEW application, and that Teststand (in a separate application) connects to the first via TCP. That could not have conflicts.
-
Note: if you have a Tools Network package, you can request assigned ranges of error codes for just your library. For example, "SQLite Library" errors start at 402860
-
Exactly. You can even do the case where the types of actor is determined at run time, in which case the caller makes a JSON object like this: {"Actor Class Name":"MyActorX.lvclass","Config":{...}} Then on application load, the caller launches an actor of that class, then sends it the "Config".
-
How does your calling code keep track of the different clones? Match that. If the caller gives them specific names, such as storing the actor addresses in a cluster, then use those names in a JSON object. If, instead, the actor addresses naturally are treated as an array, then store a JSON array.
-
That looks right to me. I don't know why it wouldn't work.
-
Are you sure you are referencing the right clone of your facade vi? A common error I've seen is to get a reference to the master copy of a reentrant vi and not to the actual clone in use. How are you getting your reference.
-

Malleable Buffer (seeing what VIMs can do)
drjdpowell replied to drjdpowell's topic in Code In-Development
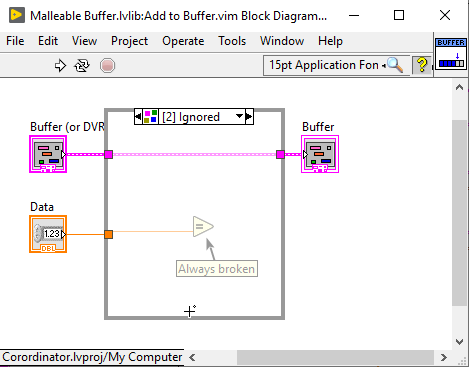
Yes, that is the problem. If I connect a "Buffer" of a certain data type, the "Data" input should adapt to be that datatype. That's how Queues work, but there isn't a way I can identify to make VIMs work that way. Outputs adapt to inputs, but not unconnected inputs. -
Malleable Buffer (seeing what VIMs can do)
drjdpowell replied to drjdpowell's topic in Code In-Development
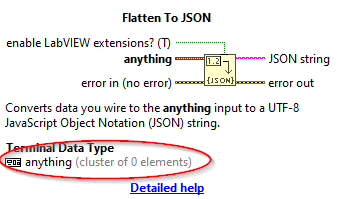
Maybe we need a "placeholder" type, or "Your Type Here". Actually, NI seems to be using an "anything" cluster of zero elements in primitives like "Flatten To String" and "Flatten to JSON". This has never struck me as being flawed.
-
Malleable Buffer (seeing what VIMs can do)
drjdpowell replied to drjdpowell's topic in Code In-Development
BTW, does anyone know of any other "malleable cluster" libraries or work using VIMs? -
Malleable Buffer (seeing what VIMs can do)
drjdpowell replied to drjdpowell's topic in Code In-Development
If you do this, you still end up with a broken buffer wire (you just also get a broken data wire if you choose to incorrectly wire in a scalar). Note that the type of the output wire now matches the input wire now instead of being a DVR. I've now getting the buffer wire to be unbroken when the Data input is unwired, by making the default Data an "undefined type" (a class call "Undefined Type"). I added a case that is unbroken when Data is this "undefined" type, which it is when the User has not wired that input. The error message the User gets in this case is just the one for a required input not being wired, which is much less confusing than a broken "Buffer" wire and an additional error message about type mismatch. AQ, what do you think about an actual "undefined type type in LabVIEW and/or NXG? One thing that could be useful for NXG is a undefined type in a cluster constant, which defines teh name of the item without the type, and allows the type to adapt to that supplied by the first Bundle-by-Name. This would avoid some of my concerns about clusters in NXG. -
Malleable Buffer (seeing what VIMs can do)
drjdpowell replied to drjdpowell's topic in Code In-Development
I'm favouring just freeze the name, as that is simplest for the User to understand, given that it is difficult to diagnose, let alone fix, any problem if the name adaption goes wrong. -
Malleable Buffer (seeing what VIMs can do)
drjdpowell replied to drjdpowell's topic in Code In-Development
Question for AQ: I'm trying to use "Unbundle by name" to access the elements of the cluster (the buffer array and the index integers). This works, but if the User accidently connects a cluster without the right-named elements, the unbundles can get scrambled, and not properly reset to the right names when a proper Buffer cluster is attached. The only solution then is to delete that VIM instance and re-drop it from the pallets. I can't find a solution and may have to switch to an unnamed unbundle, using the positions in the cluster. That is less than ideal, and won't work in NXG (you know my negative opinions on cluster changes made in NXG). -
Malleable Buffer (seeing what VIMs can do)
drjdpowell replied to drjdpowell's topic in Code In-Development
DVRs can be used, but not created or destroyed, inside an inline VI. Not clear to me why that is. Thus this library can handle buffers inside DVRs, but the User has to explicitly create a by-value buffer and put it in a DVR themselves. -
Malleable Buffer (seeing what VIMs can do)
drjdpowell replied to drjdpowell's topic in Code In-Development
Sorry, I don't understand what you're meaning. -
Malleable Buffer (seeing what VIMs can do)
drjdpowell replied to drjdpowell's topic in Code In-Development
I think I can fix this by making the last case of the Type-Specialisation Structure be a case that passes the Buffer input to Buffer Output. I make sure this last case is broken, so it is only used for type propagation when all cases are broken.
-
Malleable Buffer (seeing what VIMs can do)
drjdpowell replied to drjdpowell's topic in Code In-Development
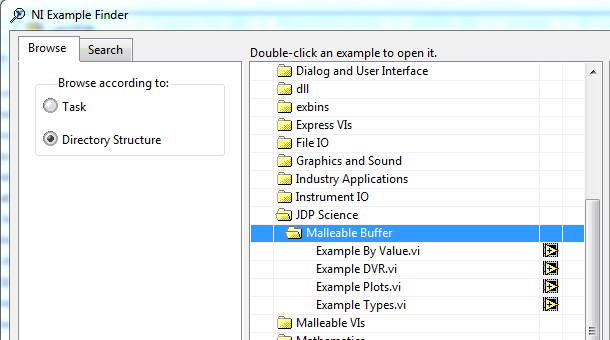
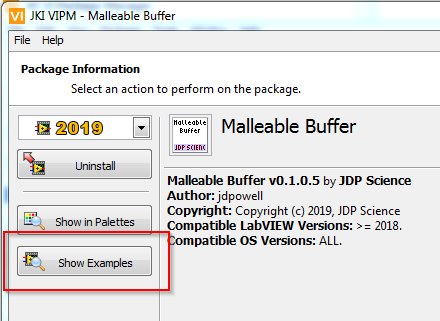
One can also just "Browse" the directory structure (which is what I've learned to do as then you know you can see everything): But the easiest with VIPM packages is to use the "Show Examples" button in VIPM:
-
Malleable Buffer (seeing what VIMs can do)
drjdpowell replied to drjdpowell's topic in Code In-Development
So far I've noticed that it takes a lot of time to figure out why a VIM is broken. Any input being wrong makes everything wrong, with only an unhelpful error message. It's the biggest problem with VIMs that have input's that must have matching datatypes. I'd like to be able to specify somehow that the "Buffer" input's should always be accepted, even if the added data is unspecified, but I'm not sure how to do that (though I've just had an idea I'll try later). -
Malleable Buffer (seeing what VIMs can do)
drjdpowell replied to drjdpowell's topic in Code In-Development
Last thing I did was move the examples into the standard example location. You should be able to find them either from the show examples button in VIPM, or in the Example Finder. I had hoped the menu would update to the new location but I guess not. -
As an experiment in seeing what VIMs can do, here is an all-VIM implementation of a "circular buffer", based on code from a 2D DBL array circular buffer I had previously used. In LabVIEW 2018. Features: Works on any scalar type, giving a 1D array buffer, or any 1D array, giving a 2D array buffer (could be extended to a 3D buffer of 2D arrays) Has VIMs that accept either a by-Value Buffer, or a DVR of a Buffer Package contains simple examples. Comments welcome. jdp_science_lib_malleable_buffer-0.1.0.5.vip
-
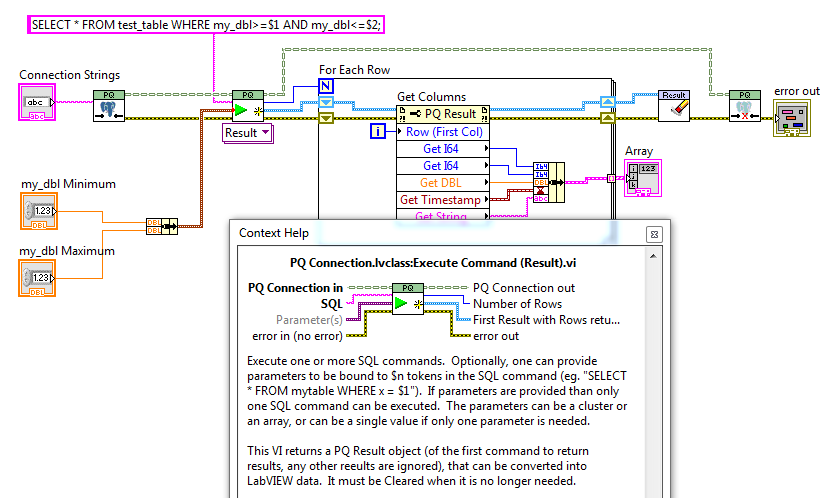
Here is the latest version of the package. To run the examples you will need a Postgres server/database and must modify the connection string to point to it (and have the right user and password, of course). I just tried it with a fresh install of Postgres 10 and it reasonably painless. This is LabVIEW 2015 (but if I developed this library further I would probably go the 2018-9 to access the power of malleable VIs). jdp_science_postgresql-0.1.1.9.vip
-
A while back I posted a beta version of a client library to access Postgresql. The project driving that work was put on hold, and I have not done significant work since. But at least some people have used or have considered using it, so I wanted to see how many people that is. There has also been a desire expressed to me about using it on RT, so I wanted to know if anyone has developed it to do that.
-
You should post a topic on LAVA sometime explaining how you use Teststand and Messenger Library. I have not had the pleasure (or is it torment?) of seriously using Teststand.
-
Note: there is nothing stopping you putting all your code in an actor in one single subvi (which Actor.vi or ActorNR.vi then calls). So you can try this easily.
-
By default, subVI are set to "Same as Caller" execution system, but they can be a specific system instead. I suspect it might be just the subVI that does the TestStand call that needs to be in a different Execution System, not the calling Actor.vi itself. So try just changing the subVI.