drjdpowell
-
Posts
1,989 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by drjdpowell
-
Have a look at the latest version 1.11 release. It adds a "Parameters" input to "Execute", which accepts a cluster of parameters to Bind. The tool you want would use similar Variant techniques. Note, however, that using Variants adds possibly not-insignificant overhead to each row returned, as compared to getting a cluster using the lower-level API, so I would not recommend it where performance really matters.
-
Do you not want to prepare a statement and build your clusters in a loop? Eventually, a VIM could do this in a single VI, but the library is currently in LabVIEW 2013 so no VIMs.
-
 Thanks, guys, I've downgraded to 2019 for now, and made a bug report at JKI.
Thanks, guys, I've downgraded to 2019 for now, and made a bug report at JKI. -
I'm having trouble with VIPM 2020 (the one with the major redesign) . The problem is the main VIPM window doesn't show up on my Windows 7 virtual machine. I would like to downgrade to VIPM 2019, but I cannot find the installer for that anywhere.
-
What do you think of the new NI logo and marketing push?
drjdpowell replied to Michael Aivaliotis's topic in LAVA Lounge
Interesting quote from the ex-NI person posting on Reddit: -
NXG, I am trying to love you but you are making it so difficult
drjdpowell replied to Neil Pate's topic in LabVIEW General
I've pointed out the sluggishness. It's actually the slowness of opening front panels and block diagrams and in opening right-click menus that is a bigger problem, IMO. -
NXG, I am trying to love you but you are making it so difficult
drjdpowell replied to Neil Pate's topic in LabVIEW General
That's more of a Source-Code-Control issue than multiple LabVIEW projects using common code. I have clients where there are multiple projects using common code, but all code is under a single repo. I'm not sure yet about NXG changes here. I have basically two types of reuse. VIPM packages developed usually on an earlier LabVIEW version and used across many projects at many customers (with the main ones being on the Tools Network), and customer common code shared by different sub-projects for a single customer. -
NXG, I am trying to love you but you are making it so difficult
drjdpowell replied to Neil Pate's topic in LabVIEW General
So... did anyone have a 1-on-1 interview with NI? I've spent some time with NXG over the last week and made multiple comments, though in a private NI forum so I can be completely honest. Can't tell if anyone from NI has read these comments. -
NXG, I am trying to love you but you are making it so difficult
drjdpowell replied to Neil Pate's topic in LabVIEW General
Tone of voice doesn't come through on the internet, X__. You need to be more clear or start using emojis 🙂 AQ, I'm thinking about the Project changes, as I had not appreciated how significant the change is. -
NXG, I am trying to love you but you are making it so difficult
drjdpowell replied to Neil Pate's topic in LabVIEW General
I think you need to give the User a choice at step 2 of what to do with the loose files. In my case they are just deprecated VIs that never got deleted (deleting files in Current Gen is very inconvenient). Step 3 need a choice too, as adding the shared files to one of the projects will usually be the right choice. -
NXG, I am trying to love you but you are making it so difficult
drjdpowell replied to Neil Pate's topic in LabVIEW General
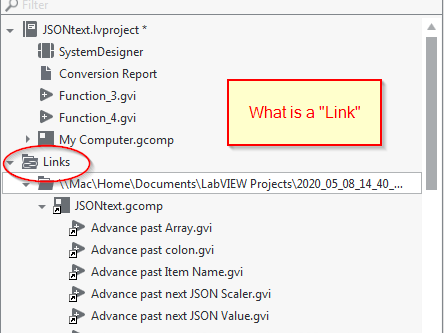
JSONtext was a single project, but for some reason the conversion tool created two projects: "JSONtext" and "LooseFiles_JSONtext for NXG", plus a "Shared" folder, which actually held the JSONtext.gcomp. I fixd the issue by: closing NXG moving the floder with all the JSONtext files into the same "JSONtext" folder as teh JSONtext project reopening the JSONtext project "Excluding" (bad terminology?) the now-broken JSONtext.gcomp "link" (was annoyed there was no way to fix the link by pointing to the new location) "Add file.." to add JSONtext.gcomp from new location (was pleasently surprised that this then fixed all dependencies without LabVIEW CGs endless dialogs) -
NXG, I am trying to love you but you are making it so difficult
drjdpowell replied to Neil Pate's topic in LabVIEW General
So where is a good forum for discussing NXG? Here on LAVA? I'm not one who likes short 1 on 1 private talks nor am I in to "workflows". But I could make lots of feedback on NXG if I have time to craft posts. Right now, for example, I'm trying to make sense of the NXG Project created by the conversion tool from my JSONtext library. I'm completely stuck at not knowing what a "Link" is, and how I can get the JSONtext.gcomp to not be a Link. As a "link", namespaces don't seem to work (I can create a namespace, but not add anything to it) and I suspect this is because a "link" is some kind of leser membership in my project. Maybe. Who knows. I cannot find anything in the NXG help on what a "Link" is, or how to open up the JSONtext.gcomp as not a link. In general, I'm experiencing a lot of "blank stare" moments in trying to figure out this software. Can it really be designed for new users and non-programmers?
-
NXG, I am trying to love you but you are making it so difficult
drjdpowell replied to Neil Pate's topic in LabVIEW General
Conversation dead. -
Broadcast Actor (AF with a touch of DQMH)
drjdpowell replied to jhoehner's topic in Application Design & Architecture
I think you'd get more chance of a response if you posted on the Actor Framework forum. I don't use AF or DQMH, nor have I looked at your code, but is it wise to try and combine different frameworks? Frameworks are designed to support different design philosophies, which are not necessarily mix-and-match. If DQMH makes sense to you while some of the AF stuff doesn't click, why not just use the DQMH? -
NXG, I am trying to love you but you are making it so difficult
drjdpowell replied to Neil Pate's topic in LabVIEW General
JeffP, in the interest of not letting this conversation die, can you present some positive features of NXG that improve over LabVIEW? -
I didn't think NXG had a control editor yet.
-
Why not just use the new buttons, with icons, which you can find in the pallets now that you have installed the package? These buttons are created from the system button, in order to get hover states. System buttons don't support the button colours, unfortunately.
-
That's because SQLite and PQ have different approaches, and I'm closely following how they work. One could think of coming up with a combined API, but that might involve compromises.
-
What version are you using? The latest version in VIPM is 1.9.1.33 Can you post a VI showing the behavior?
-
No, there is no circular references in JSONtext or this library.
-
I'll have a look at your Demo when I get the chance, to see if I can find a work around (other than not putting actors in Libraries). Unfortunately, "Messenger Library" is built on the principle of doing asynchronous things without being blocked by "Root Loop" (a little known but critical flaw of async calls in LabVIEW), and that restricts how I "launch" actors. The NI "Actor Framework" uses the same/similar method; I wonder if it has a similar problem.
-
I'm guessing this is an edge-case builder bug. I realize, though, why I have not seen it; I am hesitant to use LabVIEW Libraries. I don't put typedefs in libraries at all if they are going to be used by a component independently of the other stuff in the library, and I rarely if ever put a Class inside a Library. Libraries should be a good thing, but the "load everything in the dev environment" is a real negative. Here, the bug you are suffering is in the builder code to strip out the useless connection to the unused library elements. That builder code shouldn't even need to exist, as there is no reason to load code that is not used. The fact that your IGOR Library has "Utilities" and "Common Typedefs" tells me you are using LabVIEW Libraries the way they SHOULD work: convenient collections of things that you might use some of. But Libraries are too flawed to be used as they intuitively should be. Hopefully, they will address this in NXG.
-
Question: if you take an actor that has the problem, and remove it from its class (making it an ordinary non-dd vi) does it still not build? I want to know if this is a problem that requires DD and your library typedefs together, or just the typedefs.
-
Have you tried building your actors individually into EXEs? To see which one breaks. Make a new build and make the top level vi only one of your actors and see if it builds. Then swap in a different actor. Hopefully, they will all build but one, which narrows down where the problem is.
-
NXG, I am trying to love you but you are making it so difficult
drjdpowell replied to Neil Pate's topic in LabVIEW General
Jeff, what is a good place for NXG feedback? There is a beta forum here, but it is extremely quiet.