drjdpowell
-
Posts
1,989 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by drjdpowell
-
I’m pretty sure you’ve got some non-UI thread substitutes lying around. I think you posted one once.
-
Changing it programmatically in the "Mouse Down?” event doesn’t work?
-
Theoretically, the not-on-the-pallet VIs in vi.lib\Utility\VariantDataType should blow the OpenG stuff out of the water, as OpenG has to flatten the data to access it (expensive), but my only experience with the VariantDataType Vis is that they are glacially slow.
-
OK, but to me it seems silly for anyone to avoid OpenG yet use this (far, far less tested through experience) third-party open-source software. I’d rather offer the whole package to OpenG. Now, do it with higher performance and you’ll get me interested.
-
Shaun, I am looking at the VIPM package that Ton and I have put together. Shall we divide into two packages, one not dependent on OpenG and one that contains all the Variant stuff? So people who can’t use OpenG can still use the core functions or your extended API? I can do that just be replacing one OpenG function, Trim Whitespace, in the core (can we use your “Fast Trim” instead). Ton, You currently have the package installing under LAVA; don’t we need a LAVA tools approved package before doing that?
-
Ah, I though your “variant arguments” were variant attributes and couldn’t understand how you were doing that.
-
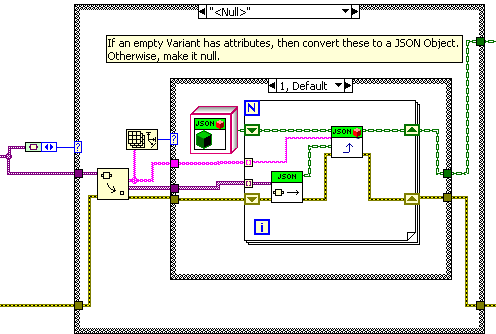
Hi Ton, I cannot, for the life of me, tell how you got this behavior before (where in the code were the attributes extracted?) but it seems like a good idea so I added it to “Variant to Cluster”. Though I made an empty variant with no attributes “null”, rather than an empty object. Note that a non-empty variant will ignore the attributes and convert the contained value instead.

-

Do close primitives that return errors cause memory leaks?
drjdpowell replied to GeorgeG's topic in LabVIEW General
Was it really “half-valid”, or just invalid but non-zero? -
Do close primitives that return errors cause memory leaks?
drjdpowell replied to GeorgeG's topic in LabVIEW General
The close function won’t cause a leak if passed a previously closed or invalid reference. However, if the problem is not that the reference was closed, but instead you lost the correct open reference due to a bug in the code upstream, then that still-open reference could be a leak. So make sure the reference actually was properly cleaned up somewhere else. -
Oh no, definitely not that. I mean what if the User requests: — the string “Hello” as a DBL? Is this NaN, zero, or an error? What about as an Int32? A timestamp? — for that matter, what about a boolean? Should anything other than ‘true’/‘false' be an error? Any non-‘null'/non-‘false' be true (including the JSON strings “null” and false”)? Or any non ‘true' be false (even the JSON string “true”)? — “1.2Hello” as a DBL? Is this 1.2 or an error? — or just “1.2”, a JSON string, not a JSON numeric? Should we (as we are doing) allow this to be converted to 1.2? — a JSON Object as an Array of DBL? A “Not an array” error, or an array of all the Objects items converted to DBL? — a JSON Scalar as an Array of DBL? Error or a single element array? — a JSON Object as a DBL? Could return the first item, but Objects are unordered, so “first” is a bit problematic. And what if the User asks for an item by name from: — an Object that doesn’t have that named item? Currently this is no error, but we have a “found” boolean output that is false. — an Array or Scalar? Could be an Error, or just return false for “found”. Then for the JSON to Variant function there is: — cluster item name not present in the JSON Object: an error or return the default value Personally, I think we should give as much “loose-typing” as possible, but I’m not sure where the line should be drawn for returning errors.
-
I’m talking about errors in the conversion from our “JSON” object into LabVIEW datatypes. There are also errors in the initial interpretation of the JSON string (missing quotes, or whatever); there we will definitely need the throw errors, with meaningful information about where the parsing error occurred in the input JSON string. For debugging type conversion problems, one can use the custom probes to look at the sub-JSON objects fed into the “Get as…”; this will be a subset of the full initial JSON string. BTW, heres the previous example where I’ve introduced an error into the Timestamp format (and probed the value just before the “Get”):
-
Actually, another possible error choice is to basically never throw an error on “Get”; just return a “null” (or zero, NaN, empty string, etc.) if there is no way to convert the input JSON to a meaningful value of that type (this follows the practice of SQLite, which always provides value regardless of a mismatch between requested and stored data type). Then perhaps all “Get” instances should have a “found” boolean output. Ton, Shaun, what do you think?
-
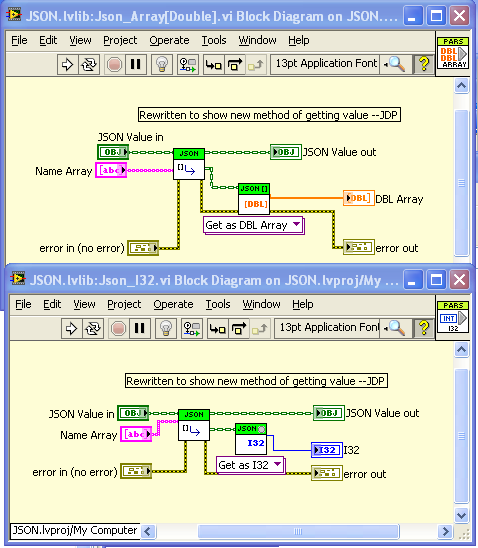
Just added some improvements to the bitbucket repo. Below is the new “Example Extract… V2” example using the polymorphic Get function. Note that there is no object type casting now, as the function do the casting themselves (throwing an error if the input type is invalid). I’ve also been working on meaningful error messages. On issue I’d like comment on is getting an item in a JSON object when the object isn’t found. Currently this is not an error, but just makes the “found” output false. I would rather get rid of the “found” output and make it an error instead. — James
-
I also looked into “public domain” and it seemed problematic. I would be happy to get rid of the requirements on binaries (buried in some readme file that none ever reads). The attribution on source code, read by other developers, seems the only meaningful one, and this also create no burden on customers, since one just leaves the license in the code or documentation.
-
Hi Ton, This is my first use of Hg or bitbucket. I’ve got a bitbucket account, installed TortoiseHg and successfully downloaded the latest JSON version and created a small “change set” ready for “pushing” up to the repository, but my authorization fails. Do you need to add me to your “team”?
-
GOOP Development Suite v4.1 is released
drjdpowell replied to Jan Klasson's topic in Object-Oriented Programming
Haven’t use GOOP, but Daklu’s “Slave Loop” is an example of an active object with queues to and from the process. Actor Framework is another example, but Daklu’s design will be simpler to understand. — James -
String to 1D String Array, painfully slow
drjdpowell replied to Findus's topic in Application Design & Architecture
Your deeper problem is one of abstraction; your taking the “wire branches make copies” abstraction too literally. Actually, the compiler will only make copies when necessary. And even if copies are made, it will take a lot of copies to match the low performance of storing data in UI elements (which mostly comes from necessary thread-switching into the UI thread). A DVR is what you should actually have chosen to avoid copies, although the best choice may have been to just let the compiler worry about about it. -
under review Periodic Trigger: Maintain Phase
drjdpowell replied to Ton Plomp's topic in OpenG Developers
I haven’t used this function, but I’ve done similar timing, and I find that both forms of timing ("since last", and “on schedule”) are both needed. There is no reason to prefer one over the other as default, and thus it would be simpler to stick with the current behavior as default, with the new one as an option. -
First thing we could use are functions to convert between JSON-format strings and regular LabVIEW Text (escaped characters, encoding, add/remove the quotes). I’m weak on regex.
-
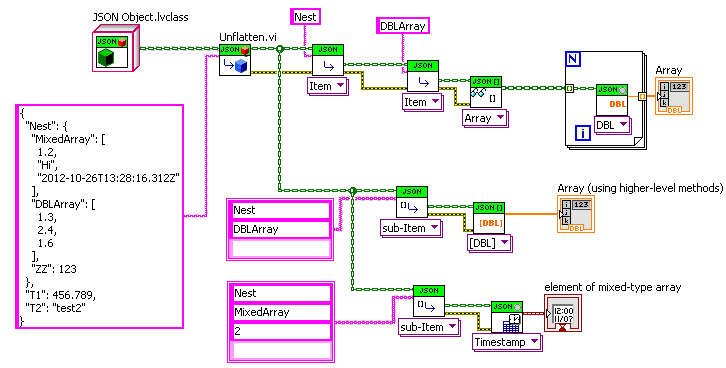
I’ve added a new version to the CR (sorry Ton, I will need to learn how to use Github). I added a JSON to Variant function. Note that I’m trying to introduce as much loose-typing as possible (very natural when going through a string intermediate), so the below example shows conversion between clusters who have many mismatched types, as well as different orders of elements. It would be nice to think about what type conversion should be allowed without throwing an error. And I’ve started on a low-level set of Get/Set polymathic VIs for managing the conversion from JSON Scalers/Arrays to LabVIEW types (very similar to Shaun’s set but without the access by name array). I’ve reformatted two of Shaun’s VIs to be based of the new lower-level ones. The idea is to restrict the conversion logic (which at some point will have to deal with escaped characters, special logic for null (==NaN), Inf, UTF-8 conversion, allowed Timestamp formats, etc.) to be in only one clearly defined place. At some point, I will redo the Variant stuff to work off of these functions rather than relying on the OpenG String Palette as they do now).
-
Could NI legal not just mail us a simple form to sign?
-
Oh, copyright violations. Thought you meant I could be sued for damages due to a very unfortunate manifestation of a bug in Trim Whitespace.
-
Uh, wait, what? Can I be sued for stuff I post on NI.com? Sounds like an argument to not post anything on NI.com. Ties back to my previous point about the NI.com Terms of Use containing disclaimers to protect NI but not posters; do I need to add a legal disclaimer to every post and uploaded sample VI? And if something is adopted into LabVIEW, it becomes NI’s responsibility, surely? That’s why I like the “1 clause BSD”, dropping the binary requirement. The source code requirement is trivially satisfied by placing the license in the FP or BD or hidden away in the documentation. Edit added later: found this link: The Amazing Disappearing BSD License BTW to OpenG developers (JG if he’s reading): does OpenG not have some transfer of copyright to OpenG itself? It will be impossible to change licensing terms on OpenG once some of the authors die. I’d like to propose dropping the binary clause.
-
I like Ton’s idea. And not just for NI; having to compile a list of all licenses to make available in an executable is a pain, especially as no one will ever read them. While providing a license in source code is easy if the license is already on the FP, or BD, or documentation of the VI’s themselves. What about a test case? In OpenG there is a Trim Whitespace function that duplicates the same function in LabVIEW. Due to the work of several programmers, OpenG’s version has considerably higher performance. I don’t believe there is any other difference in function, no “advanced” features or anything, and thus no reason why the OpenG version shouldn’t be adopted as standard. What would it take to do this? — James
-
I could, presumably, post only the core part involving the JSON classes which I wrote, leaving out Shaun’s polymorphic accessors. Or I could get Ton and Shaun’s permission to post the whole thing (maybe; how does that work as only one person can actually post it on NI?).