drjdpowell
-
Posts
1,989 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by drjdpowell
-

Third Party U 64 Control, Used bits 25 most significant
drjdpowell replied to KWaris's topic in LabVIEW General
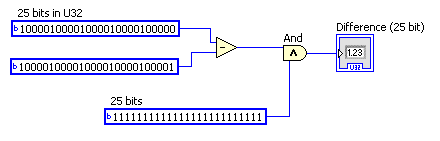
Are you being sure to throw away any bits > 25 when the encoder rolls over? The code below should give the correct U25 difference even though it’s using U32’s: Added later: actually, the fact that the “random values” alternate with the good ones suggests some other problem, unless you are reading the encoder about two times a revolution.
-
Lapdog over the network?
drjdpowell replied to GregSands's topic in Application Design & Architecture
The heartbeat can be built in to your reusable TCP component (I’ve considered adding it to my background processes running the TCP connection). You don’t have to make them part of the actor code itself. -
Lapdog over the network?
drjdpowell replied to GregSands's topic in Application Design & Architecture
I was a reaching a bit with the “any actor” thing. Though my actors tend to be a quite “server” like already, much more than your “SlaveLoops” or the Actor Framework “Actors”. They publish information and/or reply to incoming messages, and don’t have an “output” or “caller” queue or any hardwired 1:1 relationship with an actor at a higher level. They serve clients. The higher-level code that launches them is usually the main, and often only, client, but this isn’t hardcoded in. Thus, they are much more suitable to be sitting behind a TCP server. — James -
Lapdog over the network?
drjdpowell replied to GregSands's topic in Application Design & Architecture
Well, my current TCPMessenger is set up as a TCP Server, and is really only suitable for an Actor that itself acts as a server: an independent process that waits for Clients to connect. A break in the connection throws an error in the client, but the server continues waiting for new connections. This is the behavior I have in the past needed, where I had Real-Time controllers that must continue operating even when the UI computer goes down. However, most of my actors (in non-network, single-app use) are intended to shutdown if their launching code/actor shutdown for any reason. For this I have the communication reference (queue, mostly) be created in the caller, so it goes invalid if the caller quits, which triggers shutdown as in your case 1. Case 2 doesn’t apply in my system as there is no output queue. Now, if I wanted auto-shutdown behavior in a remote actor, then I would probably need to make a different type of TCPMessenger that worked more like Network Streams than a TCP server. So a break in the connection is an error on both ends, and the remote actor is triggered to shutdown. — James -
Lapdog over the network?
drjdpowell replied to GregSands's topic in Application Design & Architecture
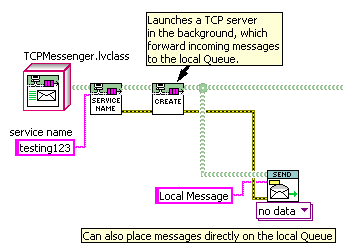
That’s the route I took in adding TCP message communication to my system, with “loop D” being a reusable component dynamically launched in the background. Incoming TCP messages are placed on a local queue, which can also have local messages placed on it directly. Because “TCPMessenger” is a child of “QueueMessenger”, I can substitute it into any pre-existing component that uses QueueMessenger, making that component available on the network without modifying it internally. — James
-
Lapdog over the network?
drjdpowell replied to GregSands's topic in Application Design & Architecture
I use variants mostly for simple values; to avoid having 101 different simple message types. I have four or five polymorphic VIs for simple messages, and having so many different message types would be unmanageable. But for any complex message, I usually have a custom message class. It’s no more complex to make a new message class then make a typedef cluster to go inside a variant message. — James I’m hoping to work up to testing my object messages on an sbRIO next week. I will be sure to run a memory-leak test. -
Lapdog over the network?
drjdpowell replied to GregSands's topic in Application Design & Architecture
My limited testing was mostly functional (and over a slow-uploading home broadband connection) so I can’t answer for throughput. My messages vary in size, but common small ones have at least two objects in them (the message itself and a “reply address” in the message) and so flatten into quite a long string: a “Hello World” message is 75 bytes. I wrote a custom flattening function for the more common classes of message which greatly reduced that size. Also, for larger messages that can involve several objects I found that ZLIB compression (OpenG) works quite well, due to all the repeated characters like “.lvclass” and long strings of mostly zeroes in the class version info. I use “Flatten to String”, which works great communicating between LabVIEW instances. If you need one end to be non-LabVIEW then you’ll want something like XML or JSON. — James -
Lapdog over the network?
drjdpowell replied to GregSands's topic in Application Design & Architecture
I believe AMC uses UDP, instead of TCP, for network communication. Depending on what you are doing, you might require the lossless nature of TCP. You should also have a look at ShaunR’s “Transport” and “Dispatcher” packages in the Code Repository; they do TCP. I’ve done some (limited) testing of sending objects over the network (not Lapdog, but very similar), and the only concern I had was the somewhat verbose nature of flattened objects. I used the OpenG Zip tools to compress my larger messages and that worked quite well. -
An update on the use of the library path in the CLN node: I found through testing that some of my subVIs ran considerably slower than others, and eventually identified that it was do to details of how the class wire (from which the library path is unbundled) is treated. Basically, a subVI in parallel to the CLN node (i.e., not forced by dataflow to occur after it) would cause the slowdown. I suspect some magic in the compiler allows it to identify that the path has not changed as it was passed through several class methods and back through a shift register, and this magic was disturbed by the parallel call. This being a subtle effect, which future modifiers may not be aware off, I’ve rewritten the package to use In-Place-Elements to access the library, thus discouraging parallel use. I’m considering having multiple “Bind Text” versions: "Bind Text (UTF8)”, “Bind Text (UTF16)” (might as well add UTF16 as SQLIte supports it), and “Bind Text (system)” or something like that. And corresponding “Get Column” versions.
-
Encapsulating the UI question
drjdpowell replied to GregFreeman's topic in Object-Oriented Programming
What’s the purpose of your “GUI manager”? Personally, I tend to keep all control manipulation on the block diagram of the VI containing the control. If I want a UI separated from the rest of the program I use messaging between VIs. The messages carry information, not control references. If the “GUI manager” is supposed to provide a loose coupling between program and UI (i.e. if you want to be able to substitute a different UI) then you need to channel all UI actions through it. But you’d also need your UI in a different VI from the main code (so you could swap it out) which would prevent you writing to control terminals or local variables. So I don’t really understand the purpose of “GUI Manager”. -
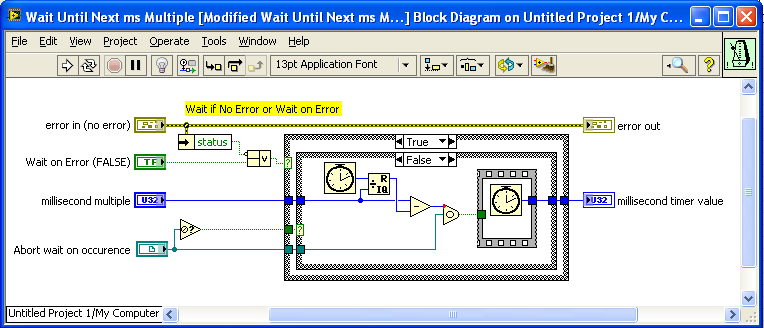
I just noticed that, although the OpenG version of “Wait (ms)” has an optional input for an Occurrence to use to Abort the wait, the complimentary version of "Wait Until Next ms Multiple” does not. I suggest modifying this VI to also accept an optional Abort Occurrence. Here is a modified version I just made: Modified Wait Until Next ms Multiple__ogtk.vi — James
-
Yes, but can I be certain that the string the User provides is actually meant to be interpreted in LabVIEW's standard encoding? Strings can be anything; LabVIEW only really applies an encoding for display purposes. The User could already be working with UTF-8 or any other encoding, and applying the so-called “String-to-UTF8” function would scramble that.
-
Hi Shaun, I agree (which is why I hadn’t spent much time on benchmarking till recently). Getting a working implementation in OpenG is more important, as optimization can happen later. And SQLite is very valuable even when less than 100% optimized; I’ve written a couple of applications with it so far and the speed is not an issue. I’m not sure I want to make that conversion an implicit part of the API. Users may want the full UTF-8 (which I don’t think is recoverable once it goes through "UTF8 to String”). And if they are using regular LabVIEW text (ANSI, I think) then it is a subset of UTF-8. I think it is better to document that the SQLite character encoding is UTF-8 and that ANSI is a subset, and let the User deal with any issues explicitly. Perhaps I should include those conversion primitives in the palettes. — James
-
I’m thinking about interoperability with other programs (admittedly, not the most common use case) that don’t use flattened NaN’s and the like. I’m surprised that would be faster than the MoveBlock method (but I’ve not benchmarked it). Good catch; I don’t know why I didn’t use Byte Array to String there. I think you’re right. I’ll get the error message added. Thanks, — James
-
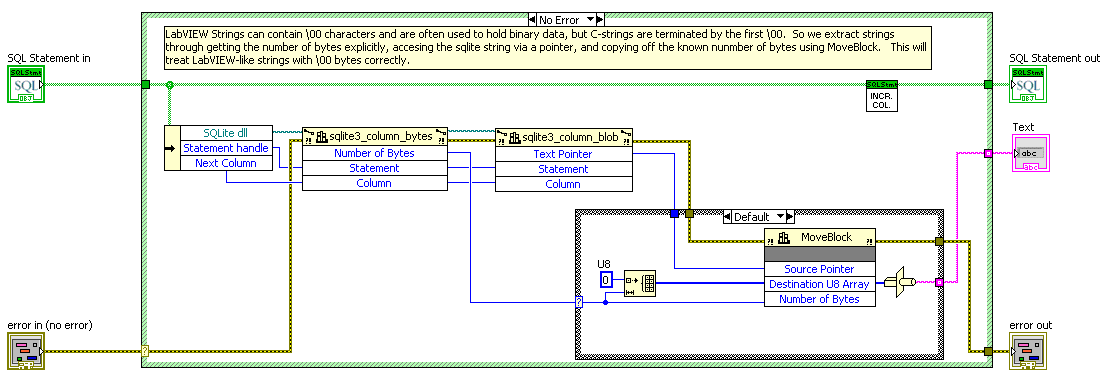
What I mean is, if you take your null variants from variant mode and try to cast them to a number, the “Variant to Data” node will throw an error. Your other two modes specify the type when getting the column, as mine does, allowing SQLite to do the Null conversion. Yeah, but why does SQLite, which is very economical in numbers of types, bother making separate types for TEXT and BLOB? Must make a significant difference somewhere. Remember, I want to remain compatible with non-LabVIEW programs, which may have there own constraints on valid TEXT data. Binary data is NOT valid UTF-8 or UTF-16 data. I do have an eye towards eventually implementing BLOB I/O. Another difference between TEXT and BLOB are the collation functions and sort order. Could you explain this? I don’t see how /0’s have any effect. I extract TEXT or BLOBS as strings with this code, which is unaffected by /0’s: A good point about the Statement, but a User could be running multiple statements from the same connection. I only need to lock the connection from function execution to query of the extended error code in order to be sure I get the correct code. To get in OpenG I have to be 2009 compatible, which means no inlining. And I think OpenG frowns on advanced optimizations (or even turning off debugging) so I may be stuck here. — James
-
If I’m imagining it right, your package goes the route of getting SQLite to serve as a LabVIEW data-type repository. I would guess you could abstract away the details of the SQLite loose typing system from the User entirely, making it simpler to learn. I went a different route of defining an explicit boundary between the two type systems, with the User dealing directly with the SQLite types. So my BIND VIs refer to SQLite3 types (Text, Blob, Real, Integer) while my GET COLUMN VIs refer to LabVIEW types (string, DBL, I64). On the its side of the boundary, I let SQLite store things as it wants, including storing empty strings or NaNs and NULL. This, I think, is an advantage if I were to need to interact with an SQLite Database created by another program; can your package handle reading data from columns where some rows are NULL? How do you handle the fact that LabVIEW strings can represent either ANSI text or binary data? The former maps to SQLite_TEXT, while the later maps to SQLite_BLOB. Do you store all strings as TEXT? Mine is a lower-level approach, I think, which has tradeoffs of greater flexibility but also greater required knowledge to use. Fortunately SQLite has excellent documentation. I need to recheck my benchmark, as 25 ns seems unbelievably fast even to me. I’m trying to get this into OpenG, though, and don’t want rare race conditions. I could get around this issue using DVRs or some other lock, but that’s some effort, so I’m putting it off until I fully understand all issues. I realized a problem in using my Example1 as a benchmark. Fixing that, I’m still slower than Shaun by about 40%. I need to see if I can improve that. — James In the context help for the “Specify path..” checkbox, there is a “Tip” that seems to indicate the ability to unload a path-referenced dll:
-
I’ve been benchmarking it (by just running a “Bind” in a loop), and using the path adds about 25 nanoseconds per CLN. Haven’t figured out yet why my code seems to be slower than Shaun’s (hope it’s not the LVOOP ).
-
A quick test using my “Example1” shows that I can INSERT 100,000 points, each involving 4 calls with a diagram path, in 0.75 seconds (this time does not include the “COMMIT” to disk). That’s less than 2 microseconds per CLN. So the overhead of the diagram path can’t be that much. Though if it is a significant fraction of the 2 microseconds, then it will be good to eventually get rid off it. — James Added later: I had a look at ShaunR’s “SQLite_Speed Example.vi” which INSERTs pairs of strings: he can INSERT 100,000 in 0.36 seconds, half my time. So perhaps I will look into statically specifying the library. Wish I could specify it in one place, though. One thing a User might want to do is have a different SQLite3 version (compiled with different options, for example) for different applications, and statically specifying the library for each CLN makes that problematic. Is there any way to specify the path at runtime, but do it only once? Or at compile time, but specify it in only one place?
-
Hi Matt, thanks for bringing your experience to this. It was my feeling that there is no clean way to directly connect SQLIte3’s loose typing system with LabVIEW variants. One could make a system similar to the OpenG Variant Config VIs, where one inputs a cluster to define the datatypes to read in, but a straight “Get Column as Variant” seems to have too many gotchas to be worth it. If one did want to store arbitrary LabVIEW datatypes in SQLite, one could just flatten the data and store as BLOB, but I thought that option could be left outside the scope of the package. Please do. I have wondered if it is a good idea to make functions like Step or Finalize also available as Property nodes, as that would allow more compact code in many cases (though as these functions aren’t really “properties” that might be confusing). Is that true? I wouldn’t have thought that, but I have never tested it. The advantage of passing the dll path is that one can alter it easily. Do you have an performance data with your system that I could compare to? I realized this after I did it. But I don’t want to introduce “pointers” into any public API function like “Prepare”. I am considering making an alternate, private version of “Prepare” that uses a pointer in this way to allow higher performance in VIs like “Execute SQL". On the “to do” list. Slightly tricky because of the issue of needed mutexes described in the documentation: "When the serialized threading mode is in use, it might be the case that a second error occurs on a separate thread in between the time of the first error and the call to these interfaces. When that happens, the second error will be reported since these interfaces always report the most recent result. To avoid this, each thread can obtain exclusive use of the database connection D by invoking sqlite3_mutex_enter(sqlite3_db_mutex(D)) before beginning to use D and invokingsqlite3_mutex_leave(sqlite3_db_mutex(D)) after all calls to the interfaces listed here are completed." — James
-
View File SQLite Library Introductory video now available on YouTube: Intro to SQLite in LabVIEW SQLite3 is a very light-weight, server-less, database-in-a-file library. See www.SQLite.org. This package is a wrapper of the SQLite3 C library and follows it closely. There are basically two use modes: (1) calling "Execute SQL" on a Connection to run SQL scripts (and optionally return 2D arrays of strings from an SQL statement that returns results); and (2) "Preparing" a single SQL statement and executing it step-by-step explicitly. The advantage of the later is the ability to "Bind" parameters to the statement, and get the column data back in the desired datatype. The "Bind" and "Get Column" VIs are set as properties of the "SQL Statement" object, for convenience in working with large numbers of them. See the original conversation on this here. Hosted on the NI LabVIEW Tools Network. JDP Science Tools group on NI.com. ***Requires VIPM 2017 or later for install.*** Submitter drjdpowell Submitted 06/19/2012 Category Database & File IO LabVIEW Version 2013 License Type BSD (Most common)
-
Congrats. Thought you seemed busy. I have a 5-week old daughter myself. Katy. Only got the one, though; didn’t buy in bulk.
-
Futures - An alternative to synchronous messaging
drjdpowell replied to Daklu's topic in Object-Oriented Programming
I was just going to use the Timeout, which would throw an error message. Simpler to throw the error message downstream to the Consumer. One could add another input for a queue to send the error messages, but I’m thinking of going the simple route. If the Consumer is a standard Actor design of mine, it will publish received error messages, and Requestor can register for error messages if it wants them. I have a “Cancel Future” VI that can be applied to invalidate the future tokens if one needs this. This immediately causes the helper to error out and shutdown, having the same effect as an “Exit” message. If the VI hierarchy that created the futures goes idle, that will also invalidate the queue references inside the futures and shut the helper down. So “Exit” functionality is already there if you want it and there is an automatic exit feature. Otherwise there is the timeout. But the helper is reusable. Once it works, I don’t care how complex it is internally because no-one needs to look inside it. And I only have to write it once; “Requestor” is code that needs to be written for each application. Instead of internal complexity, I care about the clarity and simplicity of the API. I had ment to ask you if your framework supports replies to messages. I would imagine it would if your messages are of the form “Target->Sender…” and can easily be reversed. But can your dispatcher gather replies into ordered groups? -
I like LVOOP and use it all the time, but using a non-reentrant Vi as a gatekeeper on the resource seemed the obvious first choice to me. Rolfk’s FG solution looks quite clear to me. — James
-
Futures - An alternative to synchronous messaging
drjdpowell replied to Daklu's topic in Object-Oriented Programming
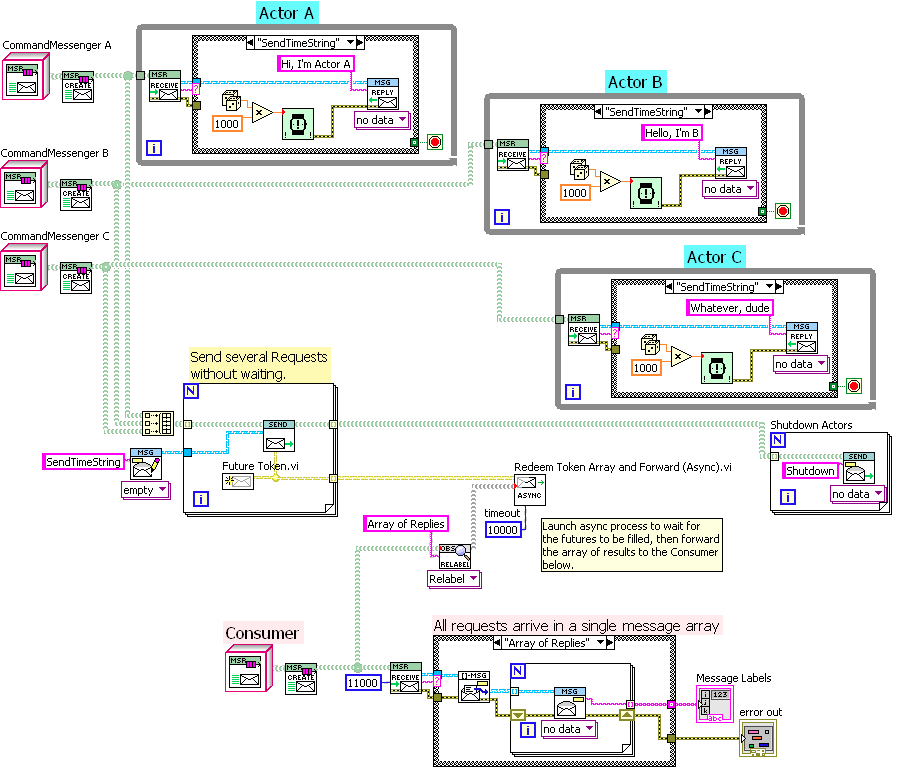
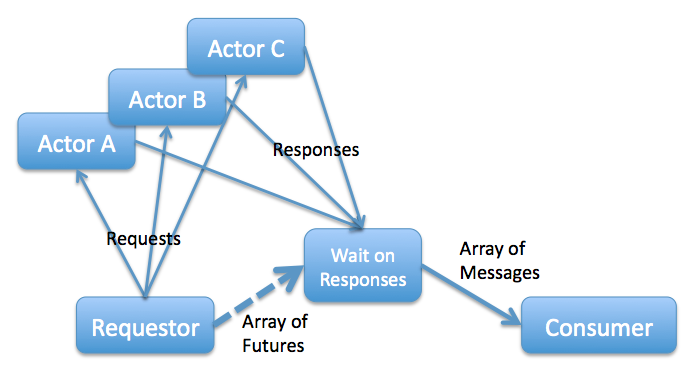
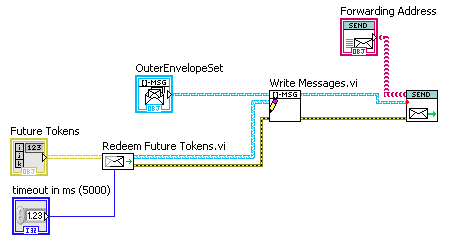
So I took the time to actually do it. Reworked the prototype “Futures” implementation I mentioned at the start of this conversation so that it had a helper actor. The above code implements this diagram (though I didn’t make the “Requestor” a message handler, it could be): Note the random delays in the three Actors; the reply messages are sent in arbitrary order, yet the set of messages received by the Consumer are always ordered A, B, C. The “helper actor” (not really a full actor, just an async subVI) is quite simple (though I have yet to complete error handling): “Redeem Future Tokens.vi” both waits for the futures to be filled, and destroys the Future Token (internally, the Future is a single-element queue). This deliberately makes it impossible to use polling on the Future. — James
-
I was investigating the resources used in loading large numbers of subVI clones a month ago. There were 5 handles opened per clone (for a clone with no meaningful code in it other than a short wait). Edit later: actually it’s 3 handles.