drjdpowell
-
Posts
1,989 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by drjdpowell
-
 My reading agrees with yours. Posting to NI.com gives NI an unrestricted license to do whatever they want with it. Further, I don't see why the authors of a work previously released under BSD can't upload it to NI.com and thus grant NI unrestricted use separate from BSD.
My reading agrees with yours. Posting to NI.com gives NI an unrestricted license to do whatever they want with it. Further, I don't see why the authors of a work previously released under BSD can't upload it to NI.com and thus grant NI unrestricted use separate from BSD. -
My understanding is... that at any moment AQ is going to rightly point out that it is only some lawyer's understanding that actually matters, and there is really no understanding of that. For discussion, what about this unlicense:
-
On looking carefully at the BSD license the "JSON LabVIEW" is under, and at the "Terms of Use" governing posts on NI.com, I see that both have prominent legal liability disclaimers. BSD says that I'm not liable, while the Terms of Use only says that NI is not liable. Should I be concerned by that? Also, I could not see why I, along with any other copyright holders of "JSON LabVIEW" couldn't legally upload the code to NI.com and thus trigger NI's ability to use the code unhindered by the BSD (I also didn't see anything that indicated that posted code is now owned by NI; just that, by posting, I grant them the right to so whatever they want with it).
-
Question: As the author of a work released under BSD or some other license, am I not able to re-release it under another, less restrictive license, such as one waiving any attribution requirements? And can I not make it "public domain" with no licensing restrictions at all? Also, as a side point. if I were a company that did not want to allow open-source code, I would certainly not allow arbitrary code posted to ni.com. That such code is legally owned by NI would be immaterial, as it is not tested or certified by NI. Only if such code became part of LabVIEW would it be acceptable. Added later: I should explain that I always assumed that some companies did not allow Open Source software because of concerns about the quality of that code. But if the real issue is attribution and keeping track of all the licenses that have to be reproduced, then that is different. Personally, I don't really care about personal attribution beyond perhaps a note in the code itself. -- James
-
And I just don't understand them. I picked BSD because it seemed to be to be entirely permissive, except for an acknowledgment. It's not "copy left" which would prevent it from being used in a commercial product. Would making things "public domain" be any better? And though I understand why some companies may shy away from open-source software, preferring all code to come from "approved vendors", how does posting things on NI solve this issue? And for future knowledge, was it posting on the LAVA CR that creates the issue, or was it already tainted once we posted code in a conversation on LAVA? Anyway, this answers a question I've long had: Why does OpenG need a different "Trim Whitespace" VI; why doesn't NI just adopt the higher-performance version as standard LabVIEW? -- James Do you not like VI Package Manger? I think some "JSON" implementations have (perhaps wrongly) allowed these values, so it is probably a good idea to accept things like "Inf", "Infinity", "NaN" when parsing in JSON. When writing JSON, a problem with the 1e5000 idea is that there is no defined size limit for JSON numbers; one could theoretically use it for arbitrarily large numbers. Not that I've ever needed 1e5000 Maybe there should be an input on "Flatten" that selects either strict JSON or allows NaN, Inf and -Inf as valid values. BTW, i'm on vacation without a LabVIEW machine so I'll comment on the excellent code additions when I get back.
-
Added to the CR. But won’t this package be 3rd party/open source? To everyone but us at least. And OpenG is a “Silver Add-on” on the LabVIEW Tools Network (oooh, shiny!).
-
View File JSON LabVIEW JSON is a data interchange format (sometimes compared to XML, but simpler). There are multiple projects to create a JSON package for LabVIEW. This is yet another one motivated by this hijacked conversation originally about a different project to convert JSON into LabVIEW Variants. This project uses a set of LVOOP classes to match the recursive structure of JSON, rather than variants. It allows conversation to and from JSON. All functionality is available through two polymorphic VIs: Set and Get. In addition to Get and Set VIs for common data types, one can also convert directly to or from complex clusters via variant-JSON tools. Copyright 2012-2016 James David Powell, Shaun Rumbell, Ton Plomp and James McNally. [Note: if you are using LabVIEW 2017, please also see the JSONtext library as a an alternative.] Submitter drjdpowell Submitted 10/04/2012 Category General LabVIEW Version
-
Version 1.5.5.41
13,632 downloads
JSON is a data interchange format (sometimes compared to XML, but simpler). There are multiple projects to create a JSON package for LabVIEW. This is yet another one motivated by this hijacked conversation originally about a different project to convert JSON into LabVIEW Variants. This project uses a set of LVOOP classes to match the recursive structure of JSON, rather than variants. It allows conversation to and from JSON. All functionality is available through two polymorphic VIs: Set and Get. In addition to Get and Set VIs for common data types, one can also convert directly to or from complex clusters via variant-JSON tools. Copyright 2012-2016 James David Powell, Shaun Rumbell, Ton Plomp and James McNally. [Note: if you are using LabVIEW 2017, please also see the JSONtext library as a an alternative.] -
Consulting Help to Speed Up a Curve Smoothing VI
drjdpowell replied to alukindo's topic in LabVIEW General
Ah, non-uniform spacing, I see. Greg, My first thought would have been to truncate the weighting calculation and fitting to only a region around the point where the weights are non negligible. Currently, the algorithm uses the entire data set in the calculation of each point even though most of the data has near zero weighting. For very large datasets this will be very significant. — James BTW> Sometimes it can be worth using interpolation to produce a uniform spacing of non-uniform data in order to be able to use more powerful analysis tools. Savitsky-Golay, for example, can be used to determine the first and higher-order derivatives of the data for use in things like peak identification. -
Consulting Help to Speed Up a Curve Smoothing VI
drjdpowell replied to alukindo's topic in LabVIEW General
I would not be able to help you for a few weeks as I’m off on vacation. I can see why your smoothing functions so slow and I’m sure someone could easily improve it’s performance by orders of magnitude on large data sets. However, are you sure you would not be better served by using one of the many “Filter” VIs in LabVIEW? I tend to use the Savitsky-Golay filter, but there are many others that can be used for smoothing. They’ll be much, much faster. -
I don’t mean utility VIs for the User of the API, rather, I mean “utility” for writing the package internally. Conversion to/from valid JSON string format will be required in multiple places. I tend to call subVIs, needed by the class methods, but not themselves using those classes in any way, “Utility” subVIs. There’s a good 30+ VIs in dependancies. Copying all that to support my variant-to-JSON stuff is excessive. Compare it with just changing the one “remove whitespace” subVI to make the rest of the package independent. But as I said, it should be easy to make the variant stuff an optional add-on, for those who don’t mind adding a couple of OpenG packages. Is it OK to put unfinished stuff in the CR, even uncertified? I’m afraid I’m about to go on two weeks vacation, but I could put what we have to this point in the CR and commit some free time finishing it when I get back. Don’t whip up a thousand and one pretty polymorphic instances until we get the core stuff finished. At some point I switched from not using OpenG if possible, to considering it “standard LabVIEW”. VIPM making it so easy probably contributed to this shift.
-
The package needs a pair of utility VIs that convert strings to/from the JSON valid form (in quotes, backslash control characters, possible unicode encoding). The variant-to-JSON stuff could be kept separate as an optional feature that requires OpenG (a lot of work to rewrite that without OpenG). Otherwise, I think I just used the faster version of “Trim Whitespace”, easily replaced.
-
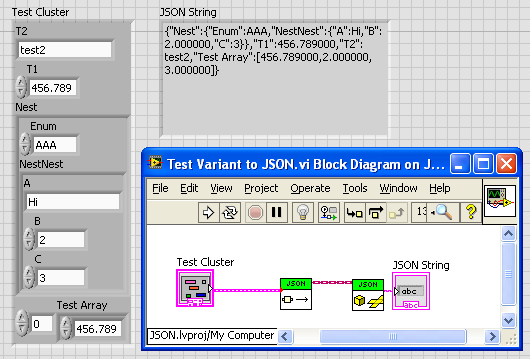
Nicely done! Though I think you didn’t need “To String”, as “Flatten” does the exact same thing. I never thought of using the JSON string form internally to make the outer polymorphic API easier. Great idea. Not sure how many are still reading. Don’t like the OpenG stuff? I love the Variant DataTools. — James
-
Breaks parser: Backslash quotes \” in strings (eg. "And so I said, \"Hello.\””) Sort of breaks: U64 and Extended precision numbers, since you convert numbers to DBL internally. Note that in both my and Shaun’s prototypes, we keep the numbers in string form until the User specifies the format required. Possible issue?: NaN, Inf and -Inf: valid numeric values that aren’t in the JSON standard. Might be an idea to add them as possible JSON values. Or otherwise decide what to do with them when you write code to turn LabVIEW numerics into JSON (eg. NaN would be “Null”). — James
-
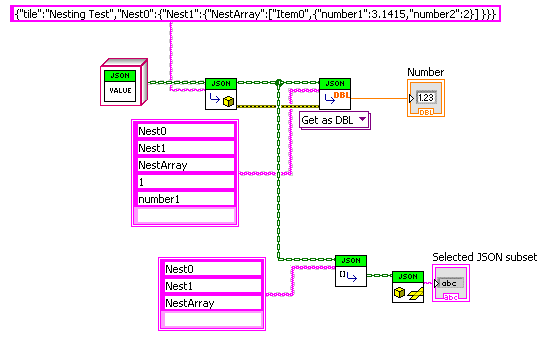
A little free time this morning: Used arrays, but you could use some parsable string format like “->”. The polymorphic VI currently has only one instance of the many, many it would need. The lower part shows selection of a subset of the JSON that can be passed generically to lower code layers. — James JSON drjdpowell V4.zip

-
Rephrase as with respect to the programmer, then; the programmer shouldn't have to understand the entire application and data structure from high-level to low-level at the same time. Sorry, I ment JSON “Objects”, not application-specific LVOOP objects. No custom code needed. One could certainly write a multi-level lookup API on top of what I have already. Should be quite easy (though tedious with all the polymorphic instances). Wasted too many hours on this today, though. I don’t have any projects that actually need JSON. — James
-
What I mean by “abstraction layers” is that no level of code should be handling that many levels of JSON. In your example the same code that knows what a “glossary” is also knows how “GlossSeeAlso” is stored, five levels down deep. For example, imagine an “experiment setup” JSON object that contains a list of “instrument setup” objects corresponding to the different pieces of equipment. The code to setup the experiment could increment over this list and pass the "equipment setup” objects to the corresponding instrument code. The full JSON object could be very complex with many levels, but to the higher-level code it looks simple; just an array of generic things. And each piece of lower-level code is only looking at a subset of the full JSON object. No individual part of the code should be dealing with everything. BTW> I see there is another recent JSON attempt here. They use Variants.
-
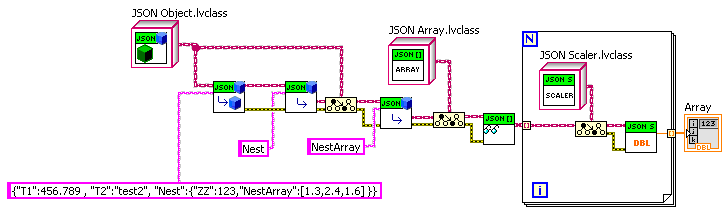
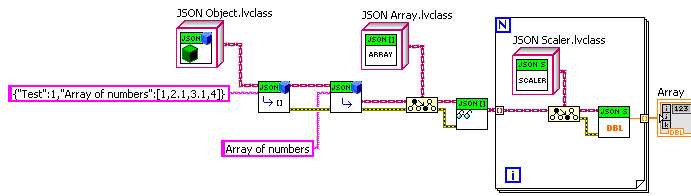
If one does a lot of digging things out multiple object levels deep, then one could build something on top of this base that, say, uses some formatting to specify the levels (e.g. "Nest>>NestArray” as the name). But if one is using abstraction layers in one’s code, one won’t be doing that very often, as to each layer of code the corresponding JSON should appear quite simple. And I think it is more important to build in the inherent recursion of JSON in at the base, rather than a great multi-level lookup ability. Here, for example is another extension: a VI to convert any (OK, many) LabVIEW types into corresponding JSON. It leverages OpenG variant tools. It was very easy to make it work on nested clusters, because it just recursively walks along the cluster hierarchy and builds a corresponding JSON Object hierarchy. —James JSON drjdpowell V3.zip
-
I must code pretty slow. This took me 2-3 whole hours: JSON drjdpowell.zip Reads in or writes out JSON of any type, with nesting. One would still need to write methods to get/set the values or otherwise do what you want with it. And add code to check for invalid JSON input. — James Added later with methods written to allow an example of getting an array of doubles extracted from a JSON Object: JSON drjdpowell V2.zip Rather verbose. But one can wrap it in a “Get Array of DBL by name” method of JSON Object if you want.
-
An advantage of Joe’s Variants, or the LVOOP deign, is that the nesting is pretty trivial (just recursion). I think the LVOOP design would be the simplest. Not that I have any time to prove it — James
-
So’s Joe’s design, now that I look at it. Though your one seems more like his “flattened variant”; how are you going to do the nesting?
-
Thoughts: If I were approaching this problem, I would create a LabVIEW datatype that matched the recursive structure of JSON. Using LVOOP, I would have the following classes: Parent: "JSON Value”: the parent of three other classes (no data items) Child 1: “JSON Scaler”: holds a “scaler” —> string, number, true, false, null (in string form; no need to convert yet) Child 2: “JSON Array”: array of JSON Values Child 3: “JSON Object”: set name/JSON Value pairs (could be a Variant Attribute lookup table or some such) If I’m not missing something, this structure one-to-one matches the JSON format, and JSON Value could have methods to convert to or from JSON text format. Plus methods to add, set, delete, or query its Values. Like Shaun, I would have the user specify the LabVIEW type they want explicitly and never deal in Variants. — James
-
cannot choose another webcam which has same name
drjdpowell replied to lovemachinez's topic in Machine Vision and Imaging
Cameras showed up in MAX no problem, but both MAX names would, if selected, lead to images from only one of the cameras. It’s was driver issue, at a lower level than MAX. -
cannot choose another webcam which has same name
drjdpowell replied to lovemachinez's topic in Machine Vision and Imaging
I think I’ve seen it with NI-IMAQdx. It’s only with some USB cameras, such as webcams. And it is only when using identical models; one can use multiple cameras of different models, because they go into the Registry under their model names. -
It’s adapting to the type of the control it’s connected to, which I did not know it could do.