drjdpowell
-
Posts
1,989 -
Joined
-
Last visited
-
Days Won
183
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by drjdpowell
-

QSM (Producer/Consumer) Template
drjdpowell replied to Kas's topic in Application Design & Architecture
I mostly use subVIs for lower-level operations, with cases for the high-level operations. At the high level I don’t find any advantage to subVIs; a “macro” of JKI commands just becomes a long chain of subVIs. The cases have no reusability like a subVI, but the higher level is application-specific so that doesn’t matter. It is perhaps way too easy to carry on using cases down into the low-level operations that really should be subVIs. I did make that mistake at first. I’m not sure Events are actually quirky, rather than just people mistakenly using the same event registration in more than one event structure. I use the JKI and Events with VIs that have a UI. I tend to use queues for non-UI loops (I assume they have less overhead). And I tend not to use Events as broadcast or one-to-many communication methods. -
Years ago I implemented the algorithm from this link. It’s not that hard to write in LabVIEW. It’s my oldest bit of code still in use (and I would be embarrassed to post it), but I’ve found it very reliable. — James
-
QSM (Producer/Consumer) Template
drjdpowell replied to Kas's topic in Application Design & Architecture
The JKI template follows (or at least allows one to follow) those three good rules. It has one message receiving system and has no need to send messages to itself nor have messages that must be executed in a specific order. It does this by keeping a separate, internal-only, by-value queue for actual operations (actually a string). This makes it a lot better than many/most “QSM” designs. -
Sending 5VDC Signal USB 6009 w/ Macintosh
drjdpowell replied to rob546109's topic in LabVIEW General
Are you aware of the “Measurement and Automation Explorer” or “MAX”? This is a NI application that should install with LabVIEW (I think it should exist on Mac OSX versions). It is used to set up “Tasks” that can be called within LabVIEW (and as asbo points out, there should be examples to help you at that point). -
Sending 5VDC Signal USB 6009 w/ Macintosh
drjdpowell replied to rob546109's topic in LabVIEW General
Only last week I had to diagnose a problem with one of these units in a new application, and the problem was they didn’t read the manual before wiring it up for 5VDC output (it’s TTL current-sink and they wired it as current-source). So I can’t really tell what kind of help the OP needs. -
Sending 5VDC Signal USB 6009 w/ Macintosh
drjdpowell replied to rob546109's topic in LabVIEW General
By reading the manual and trying it out. At least until you can come up with a more specific question. -
QSM (Producer/Consumer) Template
drjdpowell replied to Kas's topic in Application Design & Architecture
My biggest suggestion is to use the JKI template as is. It’s a tested and well-thought-out design. If you need a second process, you can use another JKI SM or a simpler queue-run process. As to your current design: 1) as Daklu mentioned, don’t have two different receiving mechanisms in the same loop; use a User Event to communicate through the event structure. 2) A subtler flaw is that the loops use the same queue for internal operations and for receiving messages from external processes. This can lead to race-condition bugs as various processes queue up sets of messages at the same time. The JKI template uses a separate queue (actually a string) for internal operations. — James Oh, and instead of the functional global, consider using a “Message” system like Daklu’s Lapdog package for getting data between loops. -
Handling a class for listbox items in a flexible way
drjdpowell replied to GregFreeman's topic in Object-Oriented Programming
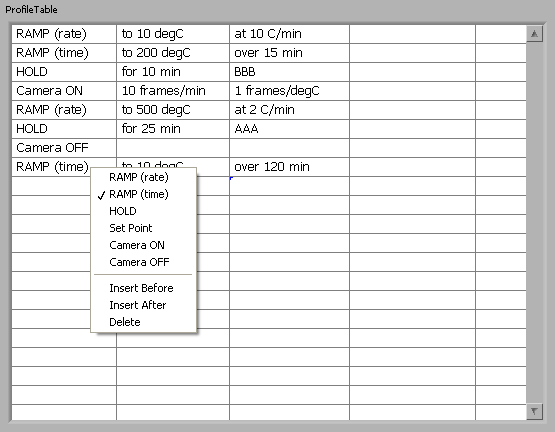
Are you planning on using an Xcontrol? The thing I’ve done that is most similar (I think) to what you are doing is an Xcontrol that allows the User to configure a list of “Actions” that they want the equipment to perform. The “actions” were an array of objects that were the datatype of the Xcontrol. The Xcontrol, containing a Table rather than a Listbox, allowed the user to configure each action via direct data entry or User menus. I’ll attach it in case it gives you any useful ideas. Note that it was never really polished or tested as the project it was for was discontinued. Probably not commented either. Oh, and working with Xcontrols can be a pain. — James ProfileTable.zip
-
Handling a class for listbox items in a flexible way
drjdpowell replied to GregFreeman's topic in Object-Oriented Programming
My first thought is that a listbox is just a UI element for display purposes, and your real classes are “Users” and “Test Info”, which don’t had any obvious reason to inherit from the same parent class. Design them that way, and include a method in each called “Listbox Entries” that returns the necessary info to fill a listbox. -
There are a few LabVIEW examples that might help, including “DateServerUsingStartAsynchronousCall.vi” that shows how to pass off new connections to a dynamically launched VI as ned mentioned.
-
Interface provider inspired by COM
drjdpowell replied to candidus's topic in Object-Oriented Programming
I had wondered about that, once I understood interfaces to have strict rules about private data, as one can’t make an interface the descendant of any class that has any private data. Oh, it was just an idea I threw together in response to this conversation. Anyway, criticism is better than apathy. -
Interface provider inspired by COM
drjdpowell replied to candidus's topic in Object-Oriented Programming
Thanks Daklu, that helps me understand “Interfaces” better. I hadn’t appreciated the fact that interfaces should have no private data themselves, and I see now how your implementation can work with by-value objects (I suggest adding a by-value example if you ever have the time). My design above was motivated by what I perceived as a desire to create some kind of combined object that can simultaneously belong to two independent inheritance trees (complete with the private data of both trees). -
Inheriting default data, confused
drjdpowell replied to MartinMcD's topic in Object-Oriented Programming
Depends how many default values you have. If you’re carrying along a dozen constants you’ll have complex “Create” methods and generic probes which are well nigh unreadable. Note that a custom probe can call the classes methods in order to display the values. I usually put a method called “Text description” in any class hierarchy that gives a clear-english description of only the important information of the object; this makes making custom probes or other debug or logging tools easier. Yes. And that method will work with parameters that don’t have non-physical values (like −1 wheels). -
Inheriting default data, confused
drjdpowell replied to MartinMcD's topic in Object-Oriented Programming
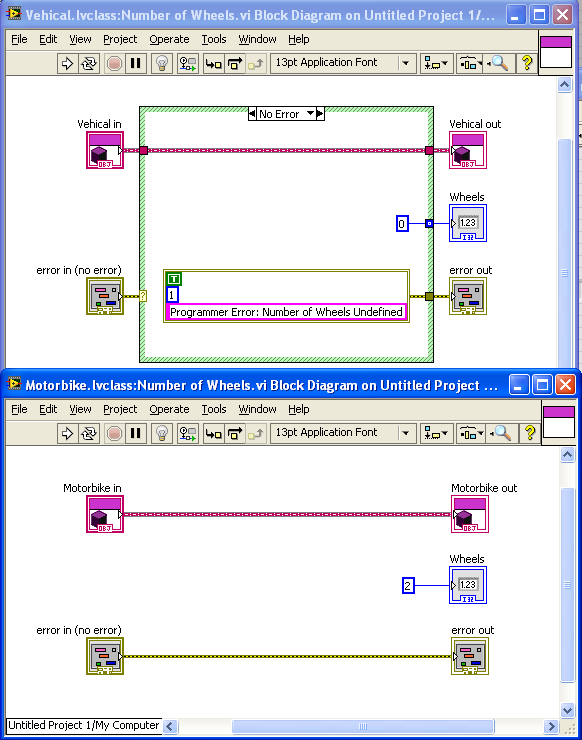
As a different take on it, if “Number of Wheels” is a constant of the class (2 for Motorbike, etc.) then it shouldn’t be a “data” item at all. It should be an overridable method that returns the constant value: Car.lvclass would have a similar override with the constant 4. Use this method wherever you need the number of wheels. — James Added later: if the number of wheels isn’t a constant, you can still have different defaults. Make the default number of wheels “-1”, and have the methods return the default value for the class only if the data item is “-1”. That way you can change the value if you want, but the default exists without needing an “Init” method.
-
Interface provider inspired by COM
drjdpowell replied to candidus's topic in Object-Oriented Programming
Hi Daklu, What do you think of my collection-of-objects-that-can-switch-between-type-identities idea posted above? -
There was a big discussion about this on the 2012 Beta forum at NI.com, with a very strong recommendation from most beta testers that conditional indexing behave like regular indexing. I guess it was too late to make the change for 2012.
-
Command design pattern and composition of functions
drjdpowell replied to 0_o's topic in Object-Oriented Programming
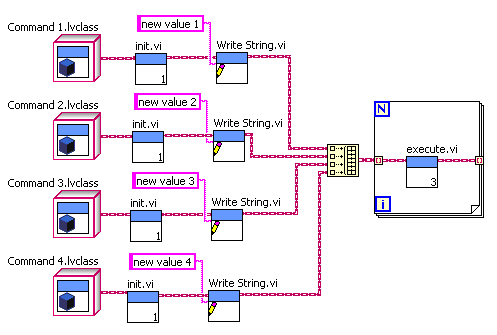
OK, but why do you you call the Init.vi in a loop over an array of objects? Why not take the individual objects, call Init on them, then call the Parameter setting VI, and only then put them in an array. Like this (modifying your “old style” example): Here “Init.vi” can be dynamically dispatched, while “Write String.vi” can be a unique method for each child class. You could even branch the wire and reuse the preinitialized object with different parameters. Basically I don’t understand the reasoning behind your initial example, where you put the objects in a array to call Init in a loop, then strip them all out again to treat them individually, then put them all back in an array again. Seems pointlessly over complicated. — James (sorry for the late reply, I’ve been on holiday without internet access)
-
Variant Hash Table for Aggregate Objects: DVRs by Name
drjdpowell replied to klessm1's topic in Object-Oriented Programming
If you’d like to stay by-value and avoid the DVRs, you can instead keep your objects in an array, and store the object’s array index in the variant attribute look up tables. -
Command design pattern and composition of functions
drjdpowell replied to 0_o's topic in Object-Oriented Programming
Why are you using a dynamically-dispatched “Init” method at all? Why not just have a “Create <commandname>” specific method in each command class that initializes it (with specific parameter inputs) and then send it off to be executed? -
Programmatically changing the value of a "numeric control"?
drjdpowell replied to Stepper's topic in LabVIEW General
He’s using a Property Node: Right-click>>Create>>Property Node>>Value Should exist in 8.0. You could also use a local variable (Right-click>>Create>>Local Variable) -
Other than for TCP and UDP, how many different “Is Valid” methods can you possibly need? Note that you can make a method “protected”, which would allow your base class to call child-class methods without making the methods public. Also note this conversation and consider if you really need an “Is Valid” method.
-
LVClasses in LVLibs: how to organize things
drjdpowell replied to drjdpowell's topic in Object-Oriented Programming
I wish it were easier to change namespacing once code is used in multiple projects. Or if it were possible to define a “display name” and a separate unique identifier that one could leave unchanged. So my “Actor” class could secretly be “47D44584FGHT” or whatever. No collisions then. -
HAL's UML and how to abstract relations
drjdpowell replied to AlexA's topic in Object-Oriented Programming
The actual parent-class data of the object. An object of a child class is a collection of clusters, one for each level of class hierarchy. You can call any parent-class method on any child-class object. Note that I am being careful to call it a “child-class object”, not a “child object”, as the whole “parent/child” metaphor really only applies to classes. No actual object is a “child” of any other object. -
LVClasses in LVLibs: how to organize things
drjdpowell replied to drjdpowell's topic in Object-Oriented Programming
Seven months later and I’m working on getting my reuse messaging code in a VIPM package. And another issue occurs to me. I now have most of my classes outside of any lvlib library, which prevents unnecessary loading. However, that means I have rather generic class names like “ErrorMessage”, “Messenger”, and “Actor” with no further namespacing that I could easily imagine another package using. What do other people do about this potential conflict? — James -
In the end I decided to add a “Text Encoding” property to the "SQL Statement” class, with choices of UTF-8, system (converted to UTF-8 with the primitives Shaun linked to), and UTF-16. System is the default choice. I also added the system-to-UTF-8 conversion primitives on all things like SQL text or database names (thanks Shaun). I also used the sqlite3_errmsg text to give more useful errors (thanks Matt).