ThomasGutzler
-
Posts
205 -
Joined
-
Last visited
-
Days Won
23
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by ThomasGutzler
-

Error 2: Memory is full - but it isn't
ThomasGutzler replied to ThomasGutzler's topic in Object-Oriented Programming
I might want to run the analysis on "any" computer without having to trouble the user to have a DB server installed. Of course, this makes sense. I can just convert my GOOP4 class into a native by-value class, put those directly in my array and the resulting array, if it had 10 class objects in it, would require a block of memory 80 bytes long (on 64-bit). And I checked, I can have more than 2^20 by-value classes Hooray! -
Error 2: Memory is full - but it isn't
ThomasGutzler replied to ThomasGutzler's topic in Object-Oriented Programming
I guess the case study just got a little more comprehensive -
Error 2: Memory is full - but it isn't
ThomasGutzler replied to ThomasGutzler's topic in Object-Oriented Programming
Absolutely, so many times I thought how much easier this would all be if only I had a database... However, it would slow things down a little bit because I'd have to host it on the network. I can see a case study coming -
Error 2: Memory is full - but it isn't
ThomasGutzler replied to ThomasGutzler's topic in Object-Oriented Programming
You're welcome I'm sure it was just a matter of time anyway. I characterise performance of optical devices. To do that I can specify a number of test parameters. Each parameter requires a certain set of measurements. Some measurements are shared between parameters. Some test parameters require data from multiple measurements to calculate their result. Result are calculated in a 2-step process. First all measurements are analysed and the intermediate results are stored in the memory of the test parameter - one object per result. This is where I'm building my array of references to objects. Measurements can be linked to multiple test parameters. If a measurement is linked to two test parameters it gets analysed twice in slightly different ways (that's two objects from one measurement). The final result of a parameter is calculated by finding the worst case of all intermediate results stored in its memory. This many-to-many relationship between measurement data and test results makes it very difficult to split the pool of measurement data in smaller parts without breaking any of the relationships with the test parameters. Time is critical because it's a production environment and it is most efficient to test all parameters in a single run rather than splitting them up into multiple runs. For the same reason (time) I decided to keep all intermediate results in memory rather than loading measurements from file and analysing them as I go along. Being unaware of the 1M reference limit, I couldn't see a problem with this design. My array is an array of GOOP4 objects - not pointers. A GOOP4 object creates a DVR of its attributes and type casts it into a U32, which is stored in a cluster. That's 4 bytes. -
Error 2: Memory is full - but it isn't
ThomasGutzler replied to ThomasGutzler's topic in Object-Oriented Programming
This little snippet will create 1048576 (2^20) DVRs and then error out at "New Data Value Reference". I know I said above that I've successfully created 5 million objects in a loop. I can't reproduce that. What I can reproduce is an out-of-memory error after creating 1048576 GOOP4 objects. So, what's the ini key to increase the number of DVRs you can create in parallel?
-
Error 2: Memory is full - but it isn't
ThomasGutzler replied to ThomasGutzler's topic in Object-Oriented Programming
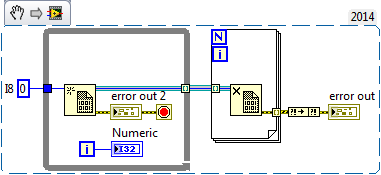
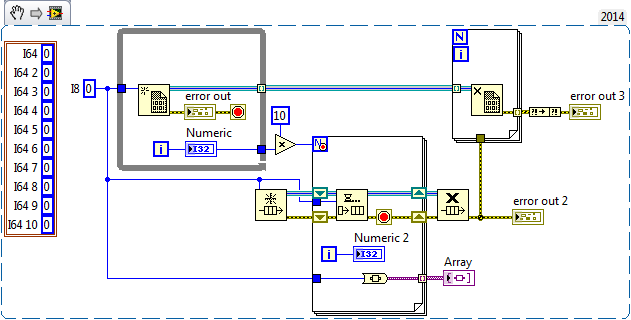
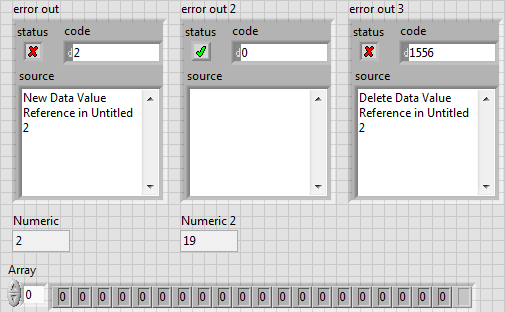
I'm aware of that, and that is why I chose to create an array of references to DVRs containing clusters instead of an array of clusters. In my specific case the out-of-memory error pops up when the array reaches a size of about 1 million. I find it hard to believe that there isn't a single contiguous block of 4MB available - every time I run the program, even on different PCs. (We know that windows suffers from fragmentation issues but it can't be *that* bad ) Also, if I can trust the error message, the source of the error is inside "New Data Value Reference". That is not where the array is being grown. The cluster I'm feeding into "New Data Value Reference" has a size 76 bytes of when it's empty. What could possibly cause that to fail? Edit: I caught my software when the error occurred in the development environment and paused execution. Then I opened a new VI with the following code: It produced this output no matter if I wired the I8 constant or the cluster containing 10x I64 constants: To me that means it's not an obvious memory issue but some soft of DVR related weirdness that only NI engineers with highest security clearance can understand... or is it?
-
Error 2: Memory is full - but it isn't
ThomasGutzler replied to ThomasGutzler's topic in Object-Oriented Programming
I meant that I'm using the 64bit version of LabVIEW to run and build the application. On a 64bit windows. The 2GB memory usage was just coincidental and could as well have been 4GB -
Hi, I've recently run into problems with an application that creates a lot of objects. Half way through it errors out: Error 2 occurred at New Data Value Reference in some.vi Error: 2 (LabVIEW: Memory is full. ========================= NI-488: No Listeners on the GPIB.) This happens both in the dev env and in an executable. I know it's not actually running out of memory because the PC has several GB free when it happens and the application is using less than 2GB and running on 64bit. It's also not talking GPIB. The application goes through a number of measurement files, analyses (and closes) them and creates up to 20 objects of results per file (plus another 20 for the base class). Those are all by-reference objects (GOOP4, DVR). The reason I'm storing my results in by-reference objects is because I have to remember them all in a dynamically growing array and I'd much rather use U32 as a type for that array than a 1kB cluster with the actual results. The point where it falls over is fairly reproducible after having opened around 35800 files. The number of objects created at this time is around 1 million. The first thing I did to debug is open a new vi and create 5 million of those objects in a loop - of course that worked. DETT didn't help much either; got over 200MB of log files just from logging User Events in the two create methods. Now I'm a little bit stuck and out of ideas. With the error occurring in "New Data Value Reference" that eliminates all the traps related to array memory allocation in contiguous blocks that could trigger an out of memory error... Unfortunately, I can't easily share the original code that generates the error. Any suggestions?
-
How to correctly use the outputs of Gaussian Peak Fit?
ThomasGutzler replied to ThomasGutzler's topic in LabVIEW General
Oh, how embarrassing :/ Thanks Darin -
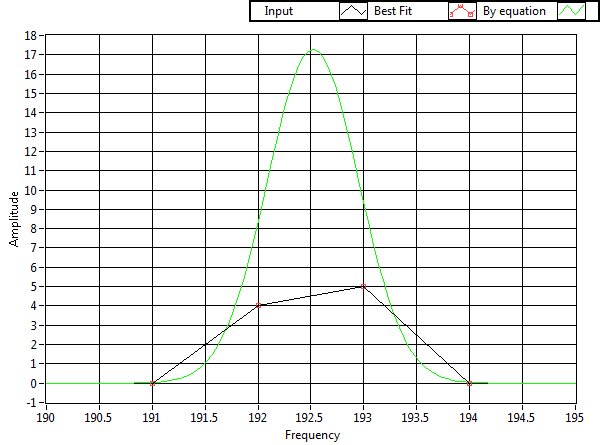
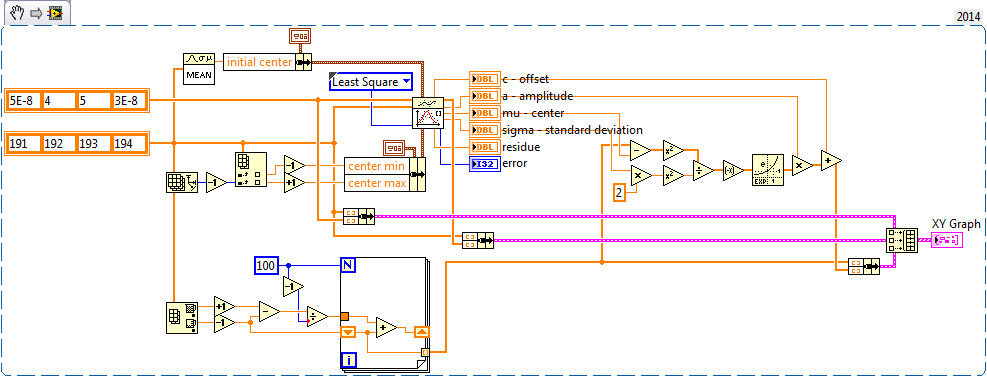
I use the Gaussian Peak Fit.vi on data with very few points. To get an idea of what the fitted curve looks like and to double check how well it performed, I wrote some extra code that is using the outputs of the vi to generate a nice curve with a few more (say 100) points on the x axis. Then I display the original data, the "Best Gaussian Fit" output and the curve calculated from the output parameters on the same graph: I expected the four points of the red curve to be exactly on top of the green curve - but they're not. Here's the block diagram (also attached as LV2012 VI: GaussFit.vi). What am I doing wrong?
-
Just check it into version control and force everyone to use your settings Or, have a utility vi that updates the .ini file in a clever way and have an enum on the FP so that every keen employee can make their own preferred settings
-
Writing .img to a SDcard
ThomasGutzler replied to Bjarne Joergensen's topic in Calling External Code
You might find that specifying the correct block size will speed up your transfer. The default (is it still 512 bytes?) is unlikely the right number -
Use two repositories. One that contains your project and one that contains the instrument drivers and other "shared" resources nicely arranged in a tree structure that makes sense to you. I imagine that tool palette would become very crowded very soon. Instead of having all your instruments and methods in the palette, why not use quick drop with this handy class select plugin. That way you only have methods available of the instruments that you have added to your project.
-
The factory pattern you describe works very well for instruments. I would certainly recommend going down that path if you want to be flexible and avoid rewriting the same code over and over again. It allows you to easily swap instruments between test stations - then all you have to do is replace the configuration and the code does the rest (assuming all methods are supported). The "manufacturer" parent class is probably only worth considering if you have many instrument types with many instruments of the same manufacturer. The problem you might run into here is that you can't encapsulate communication in the child class. You might have to write a separate communication class structure that offers different types (USB, GPIB, TCP/IP, RS232, ...) and then hand an object of that class around so you can do half the communication in the parent and the other half in the specific class without them actually knowing what type of communication they're using. That way, it doesn't matter if your Tektronix scope A is connected via USB and Tektronix scope B is connected via GPIB and they're both trying to send the same command. We are using a very similar architecture with over 40 instrument types - without the "manufacturer" layer. Configuration is done via a single "file" containing a section for each instrument and some global stuff like paths that can be used inside the sections. Some of the sections' properties are handled by the base class (instrument type and model, address, calibration dates, etc) others by the instrument type layer and others by specific classes. The same goes for methods. Init, Reset, Destroy, etc are defined in the base and more specific methods like MeasureFrequency() could appear in the scope subclass. Unfortunately, I don't think our code is allowed to go public.
-
The LabVIEW information menu in the General Account Settings is missing the 2014 option. Michael, since this is a reoccurring thing, maybe you should be looking into automating it
-
MCLB movable column separators and header click events.
ThomasGutzler replied to John Lokanis's topic in User Interface
Use Mouse up for sort and check if you've done a resize since the last mouse down -
VISA write (read) to USB instruments in parallel crashes LabVIEW
ThomasGutzler replied to ThomasGutzler's topic in Hardware
Results! I investigated option 3 (communication via tcp/ip). It's about twice as fast when using six instruments - but only after setting the super secret TCP_NODELAY option on the tcp socket with a call to wsock32.dll After talking to Keysight about the problems I experienced when talking USB, they said they saw something similar but only when using ViBufRead calls, which is the default in VISA. You can also see those calls when running the NI I/O Trace software. From the VISA write help: So, ignoring the warning about the potential performance hit, I switched to synchronous I/O mode and all is well. No more crashes! Hooray -
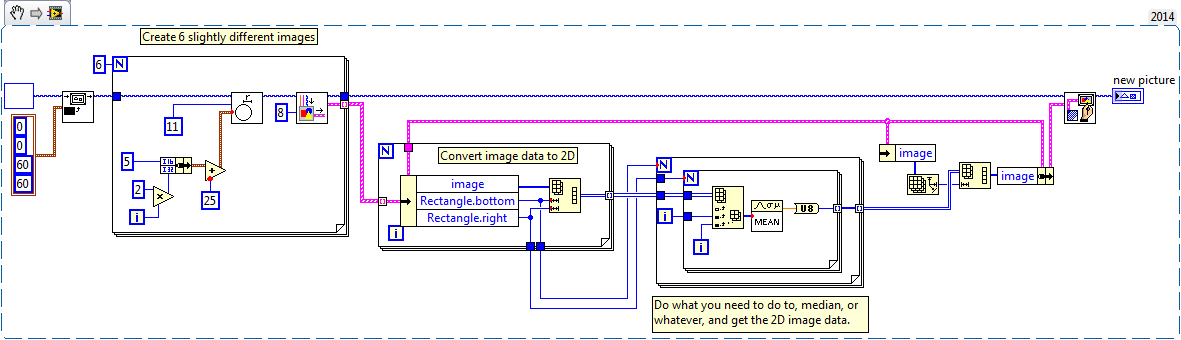
Or, if you're stuck at how to actually do the median filtering, try this Multidimensional image data array TG.vi
-
VISA write (read) to USB instruments in parallel crashes LabVIEW
ThomasGutzler replied to ThomasGutzler's topic in Hardware
Thanks for sharing, everyone. Looks like I have to investigate option 3: Ethernet -
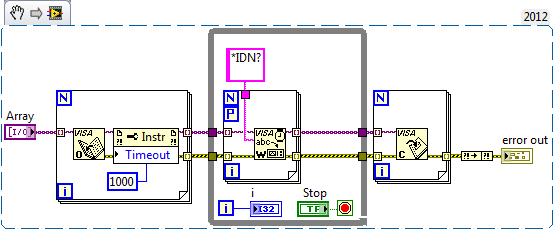
Hi, I have several USB instruments (Agilent/Keysight optical power meters) which I can talk to via USB. To minimise the time "wasted" by transferring data between the instruments and the PC I would like to query them in parallel. Unfortunately, LabVIEW doesn't agree with that strategy and reliably crashes when doing so. It doesn't matter which command I send, so here's a sample snippet, where I just query the instrument ID repeatedly. I don't even have to read the answer back (doing so won't make a difference): This will kill LabVIEW 2012 and 2014, both 64bit without even popping up the "We apologize for the inconvenience" crash reporter dialog. Has anyone had similar experiences? I've seen LabVIEW crash while communicating over RS232 (VISA) but it's much harder to reproduce. Is it outrageous to assume that communication to separate instruments via different VISA references should work in parallel? All my instrument drivers are separate objects. I can ensure that communication to a single type of instrument is done in series by making the vi that does the communication non-reentrant. But I have to communicate with multiple instruments of different types, most of which use some flavour of VISA (RS232, USB, GPIB). Am I just lucky that I haven't had more crashes when I'm talking to a lot of instruments? Could it be a bug specific to the USB part of VISA? I've only recently changed from GPIB to USB on those power meters to get faster data transfer rates. In the past everything went via GPIB, which isn't a parallel communication protocol anyway afaik. Tom
-
NI Stuff takes up too much space on my SSD
ThomasGutzler replied to Neil Pate's topic in Development Environment (IDE)
Oh, you're right. I was looking for the mklink.exe, which doesn't exist because it's built into cmd. And it appears to be working as long as you're admin -
NI Stuff takes up too much space on my SSD
ThomasGutzler replied to Neil Pate's topic in Development Environment (IDE)
Wow, Microsoft finally reinvented the symlink - amazing! Shame it only "Applies To: Windows 8, Windows Server 2008, Windows Server 2012, Windows Vista" Vista? Seriously? -
I'm sorry, I'm unfamiliar with the IMAQ library. Also, without knowledge about your optical setup and your imaging sample, it's impossible to check if your result is correct - other than confirming that what you have is a 2D array (tick).
-
From your recent posts I get the impression that you're working with a digital (Fourier) holography system. Do you, by any chance, work at a university which provides you free access to libraries and scientific journals of your area? In that case, I'd recommend having a look at Books: - Introduction to Fourier Optics - Digital Holography Related Journal Articles by - Schnars and Jueptner - Depeursinge (The dude, who commercialised the holographic microscope) - or anything else that looks remotely interesting in the area of quantitative phase unwrapping in digital holography Long story short, phase unwrapping can act on the phase of a complex image, so you need to extract that first. However, the amplitude information may provide some additional information you might be able to use to guide the phase unwrapping algorithm to perform better.
-
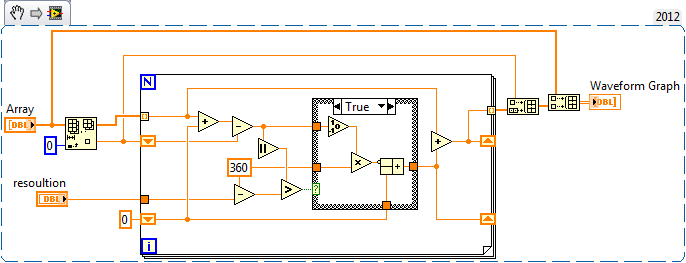
There is no one way to do phase unwrapping. The method depends on the source of your signal and the measurement method. It could be as simple as this, which I hacked together in a few minutes: unwrap.vi