Justin Goeres
-
Posts
691 -
Joined
-
Last visited
-
Days Won
11
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Justin Goeres
-

Unexpected Event Structure Non-Timeout Behavior
Justin Goeres replied to Justin Goeres's topic in LabVIEW Bugs
Yep, that's where I'm falling on this, too, especially after AQ explained some of the technical underpinnings to me. I guess my main frustration with this is that I met at least 4 or 5 CLAs just at the Summit (and that doesn't include everyone else at JKI) who have hit this issue at some point during development, gone half-crazy trying to even understand it, and eventually refactored their code around something they've given up trying to figure out. Why does this happen? Because of the lack of tools at our disposal for monitoring or influencing the Event Structure at runtime. I honestly don't have a strong opinion on whether this is a bug or not (nor have I; mostly I've been bemused by the whole thing ). But what I do have a strong position on is that if I could inspect/flush/otherwise manipulate the queue for an Event Structure I and others would've been able to understand, work around, and even exploit this behavior for better software years ago rather than wasting time cursing at LabVIEW. -
Unexpected Event Structure Non-Timeout Behavior
Justin Goeres replied to Justin Goeres's topic in LabVIEW Bugs
Hey, you stole that from me, in our Skype chat! -
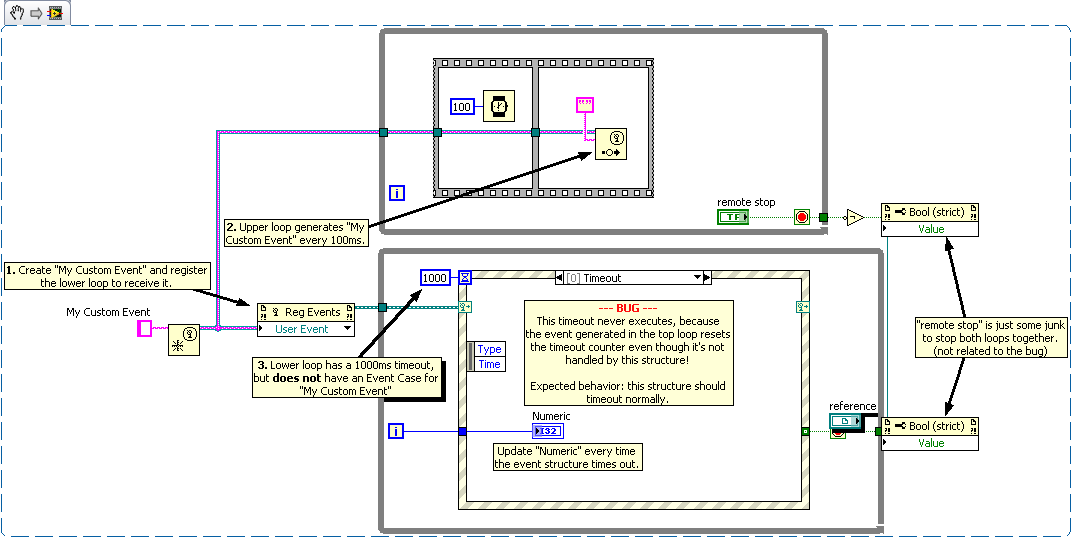
Something finally clicked for me during my CLA Summit presentation last week (thanks, Steen, for triggering my brain!). Here's the issue: Any event for which an event structure is registered, but for which it does not have a case, resets the timeout of that event structure anyway. To put it another way, imagine you have a custom event that's wired to multiple event structures. However, not every event structure actually handles the event (i.e. they don't all have a case for it). When you fire that event, it will reset the timeout counter for all the event structures, even the ones that don't handle the event. This means it's possible to have an event structure in your code that never times out, and also never executes an event handler, even though it's got a non-zero timeout value. This feels like a bug to me for the following reasons: We register for Front Panel events by creating event cases for them, and events that don't have cases don't interrupt the timeout. Why would we not expect User Events to work the same way? It's virtually impossible to detect when this is happening in your code. In the attached example, the event structure looks like it should be timing out, and in a complicated application it's almost impossible to tell why it's not. However, at the CLA Summit there was some room for disagreement about this. LAVA, what do you think? Screencast: http://screencast.com/t/qDIKpn9oQnlD Snippet: (note the snippet creation made those crazy non-static property nodes on the stop logic; that's not me ) Code (LV2009): Event Structure Timeout Bug.vi

-
I remember you . In fact, I was briefly confused by clearlynotexactlytheoneandonlyjim's username! Perhaps we need a limit on the number of North Carolina Jim's.
-
That's my cue . I work for JKI and live in Cary, NC. I frequently wish the LabVIEW community around here was a little more active/vibrant, but I think everyone is just really really busy all the time. There are a couple user groups, though, and I'd strongly suggest checking them out. I try to go to Seneca5's user group (downtown Raleigh) when I can, but unfortunately they've picked a day of the month (first Tuesday) that conflicts with another longstanding recurring meeting so I don't get to go real often. I really like the vibe I've gotten from this group -- they take things really informally, and it's certainly a more independent discussion than I think you tend to get from NI-sponsored groups. Also, the semi-official(?) NI user group meetings I think are usually held at G2 in Apex, but they're infrequent -- either that or I just don't know about them . Anyway, come to one of those! And if you find out about any other LabVIEW clubs around these parts, feel free to PM me.
-
JKI State Machine + UI
Justin Goeres replied to Jordan Kuehn's topic in Application Design & Architecture
That's a great question, and one that comes up frequently. You're absolutely correct -- if the state machine is off processing a long list of queued states that take a long time to execute, it won't poll the Event Structure until those states finish executing. The implication, then, is that if you want your JKISM to stay responsive, the states in your state queue need to always execute quickly. So your observations are dead on . Sometimes, though, you've got operations that just take a long time, right? The way to handle this with the JKISM is to move long operations to a separate loop or refactor them so you can poll the Event Structure frequently. Two examples of how to do this: Data Collection That Takes a While Say you've got a data acquisition operation that takes a few seconds or more. In this case, I'd put the acquisition in a separate loop (it could be another JKISM, or simple asynchronous loop driven by a notifer or something). Then your JKISM's state flow could look like this: DAQ: Start << sends notifier to start acquisition DAQ: Check for Data Ready << checks a return notifier from the asynchronous DAQ loop to see if the acquired data is ready yet. If not, it executes:Idle << go back and poll the Event Structure DAQ: Check for Data Ready << then come back to the same state to check the notifier again This way you're passing the slow work of data acquisition off to an asynchronous loop, while your UI/main logic loop remains responsive. Waiting for a Motor to Move Another common use case is sending a motor on a long move. In this case, we don't need the extra asynchronous loop because the motor itself is probably asynchronous (unless you're unlucky and your motor library is crap ). The state queue in this case still looks similar to the first one: Motor: Start Move << start an asynchronous motor move (assuming your motor supports it) Motor: Check Move Done << read the motor's "In Motion" or "Move Complete" flag (again, assuming it has one) to see if the move is complete. If not, execute:Idle << go back and poll the Event Structure Motor: Check Move Done << then come back to the same state to check the motor again Note that in either of these cases you can also add extra logic so that waiting for the DAQ or the Motor can time out with an error if the operation takes too long, etc. You can even use the Event Structure itself to communicate between the loops -- for instance, in the first example instead of sending data back in a notifier, you could send it back in a User Event. There's a lot of flexibility depending on what the specific application requires. So to get back to your original point -- yes, the JKISM is built with the assumption that states generally execute very quickly. That imposes some requirements on what the states themselves do, and biases your application in general to be very parallel, asynchronous, and event-driven. Hope that helps! -
Speaking personally (not for JKI) as someone who has a great personal interest in various OSS license schemes and has released different bits of software under several different major OSS licenses.... (I'm assuming this is all LabVIEW software) I think you basically have two choices: Release everything as BSD. The LabVIEW world pretty much understands and accepts BSD. There are some organizations that are gun-shy about it, but if they're resistant to BSD then nothing will satisfy them. Release everything as GPL, and offer separate commercial licensing for closed-source uses. This is about as simple as you can make it without either open sourcing or closed sourcing everything. However, if you choose #2, from a practical standpoint no one will use your software because almost no one understands GPL/dual-licensing. Here, too, you'll find exceptions (and if your tool is sufficiently awesome it will be worth the hassle for people) but dual licensing will require a lot of customer education. Many people will never even try your stuff in the first place just because they're terrified of the letters "GPL" for one reason or another. That's not to say it's not viable -- it might be -- but that model comes with a large amount of extra work for you to explain the situation to the world.
-
Factory Pattern FTW!
-
No kidding . And you're right -- from your experience it sounds like it's probably not supported. Oh, well. I'm glad you were able to verify it yourself, and I'm sorry it didn't work!
-
You might be able to convert them with ImageMagick. I don't see ND2 on the list of supported formats, but you never know. If you want to send me a sample ND2 image, PM it to me and I'll be glad to do a quick check for you. If ImageMagick supports ND2, you still wouldn't be able to open them directly in LabVIEW, but you could definitely automate the conversion process either by just writing a bit of System Exec.vi magic or by using my ImageMagick API from a few years ago (which I imagine still works, although I haven't looked at it in a long time ). Good luck!
-
My eyes are bleeding. In all seriousness, though, that's pretty awesome.
-
This is a great point. We've played with Hg a little bit at JKI and I've used it on a couple small projects. We're continuing to evaluate it; even if we never switch over to it ourselves we need to understand it for our customers.
-
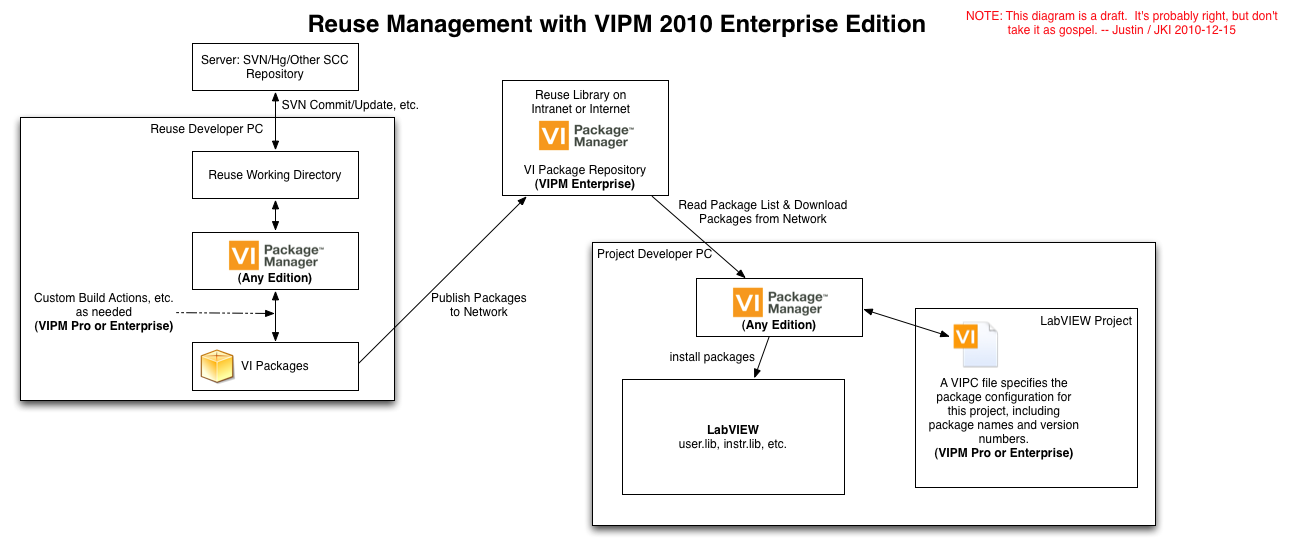
Thanks for the diagram, that makes some things clearer! I hacked up a diagram similar to yours, but showing where VIPM might fit into the system. See attached. Notable differences: Package Building is simpler because VIPM takes care of the hard parts of the OGB/OGPB hassle. Instead of a Network Share, built packages are stored in a VI Package Repository on the network. Note that this is exactly like NI's LabVIEW Tools Network repository, or the VI Package Network repository used by OpenG, but it contains your packages. Instead of manually getting packages from the Network Share, each project developer uses VIPM to download packages from the Package Repository, and creates a VIPC file for each project. This VIPC file specifies exactly which packages are in use on the project. When switching between projects, the developer just "applies" the new project's VIPC file and he/she knows the correct packages will be installed. EDIT: To clarify my 3rd point above... The project-specific VIPC doesn't just allow a single developer to switch projects easily; it also makes it easy for one developer to hand a project off to another developer because in ensures everyone's environment has the correct packages when they start work.
-
Another quick note on this. Depending on what you want to do with the information (see my post above where I don't quite understand what that is ), you might be able to do exactly what you want with VIPM's Custom Actions. You can create special VIs that run at pre-/post-build, pre-/post-install, and pre-/post-uninstall time for each package. This gives you a tremendous amount of flexibility in terms of mangling your VIs or various support files exactly the way you want, in an automated way. Install Actions and Uninstall Actions are available in VIPM Community. Build Actions are available in VIPM Professional and Enterprise. Correct. I'm not a hardcore mercurial user so I can't comment intelligently on exactly how that would happen, but in SVN, if you had a directory of packages under source code control you'd have to delete the old package and then Commit that change. However, this is another advantage of VIPC files. The VIPC file contains a list of packages (and their versions!) so you can never have the duplicate package problem you're describing. You'd handle your package upgrades this way: Build the new package. Open your existing VIPC file for a given project and drag the new package into it (requires VIPM Pro). Save the VIPC. Commit the modified VIPC file to SCC. Use a commit comment like "Upgraded blackpearl_lib_kraken_tracker.vip to 2.0.1." This way you're not "adding" or "removing" files from SCC -- you're just updating the package configuration (VIPC file) that you're already tracking.
-
Felix, I have a few thoughts on your new points, just to give you my perspective as someone who uses VIPM all the time. Maybe I'm sort of misunderstanding your goals, but in my experience it's not necessary to capture the repository revision inside the package itself. What we typically do at JKI is add a tag, or at least a commit comment, to the source repository (we use SVN) when we build a package. The package itself is versioned, of course (1.0, 1.1, 2.0, etc.) and if we want to know what SVN rev it came from we can look that up in the SVN repository itself. We find that's the easiest way to capture the information, since it's basically one of the core features of any SCC system and doesn't require us to write software. This keeps the package format itself lightweight. I guess I'm not sure what need is solved by having the package format be transparent to SCC/diff. Again, the change history of the source for the package is stored in SCC (plus the release notes of the package). If you find yourself needing to actually diff revs of your libraries it seems to me you've got a change control problem that needs to be solved upstream, when you're developing the libraries in the first place. Or am I misunderstanding?
-
Best. 5000th. Post. Evar. Someone get it on a shirt.
-
Hi Felix, As JG pointed out, the reuse/sharing problem you're trying to solve is exactly what VIPM is designed to do. I'm going to point out a few things you might find relevant. If you're interested in investigating it more, please write to me directly or contact us through our website. We can definitely set you up with an evaluation license for VIPM Pro or Enterprise, and would be happy to talk about your needs. First, it's a bummer you're on LV7.1, but you can still download VIPM 3.0 from our website (link is at the bottom of that page). Obviously VIPM 3.0 isn't being maintained anymore, but it might provide a solution for you until the day when you can make the jump to a version of LabVIEW that's still supported by NI . Second, the need to share reuse code among team members and/or with customers is exactly what VIPM Professional & VIPM Enterprise are good for: VIPM Professional lets you create VIPC files (as JG mentioned) that you can use to bundle packages together and manually share them with others. VIPM Enterprise lets you create a networked package repository so that you can publish packages easily for any number of "client" computers. This is what NI uses for their LabVIEW Tools Network package repository; they publish packages and those libraries automatically show up in users' package lists around the world. Obviously it works just as well for smaller teams, too. We have some users who manage their reuse libraries using just VIPM Pro and some VIPC files, while others find that VIPM Enterprise is a lot easier/more flexible/more reliable.
-
PRE-REGISTRATION for the 2010 LAVA/OpenG NI-Week BBQ is NOW CLOSED! If you want a ticket and have not purchased one yet. please find Justin Goeres on the NIWeek floor (JKI / Booth #841) and pay him $30 in person. There are still a small number of tickets left (about 9 as I write this) so you should hurry up.
-
As I mentioned previously, every year we hold a drawing for sweet door prizes at the LAVA/OpenG BBQ. We have a few great items on tap this year but it would be really cool to have more! Prizes can be anything you're comfortable being known as the donor of (unless it's something really, really awesome and you just have to remain anonymous). In the past we've given away everything from desk toys to a Wii! Some companies give away software licenses. Sometimes we even have extremely cool handcrafted one-of-a-kind items! The possibilities are limited only by your imagination! So if you're coming to NIWeek and you have something you'd like to contribute, please contact me via PM. You can also just bring the prize to Austin and let me know before the party, but a heads-up would be nice. My previous offer still stands: In return for your generous support of LAVA, OpenG, and the larger LabVIEW community, I will be happy to do a brief plug for any company/person/product of your choice (well, within reason ). Or I'll make Chris Relf do it. Or you can do it yourself!
-
Ticket sales for this year's LAVA/OpenG NI-Week BBQ have been brisk (unlike the weather in Austin har har), and there are a limited number of seats available for the Bar-B-Q. If you have not yet bought your ticket for the 2010 LAVA/OpenG yet, please consider doing it soon. As of Thursday night 22 July, there are approximately 35 tickets left. If you don't prepay via PayPal, you are more than welcome to track me down at the show or pay at the door. However, if you do that you may run the risk of not getting a ticket at all. And that would make us both sad. So what are you waiting for? Buy your ticket today!
-
Typically I wear long pants & a short-sleeved shirt during the day, but I make sure to bring a light jacket or light pullover or something for if it's really cold in the convention center. At the end of each day (5PM or so when all the presentations are over) I go back to the hotel to change into shorts and some other short-sleeved thing for dinner / after-dinner activities. If you try to wear shorts and/or too light a shirt during the day in the convention center, you might be cold. If you try to wear long pants when you go outside in the afternoon/evening, you will burst into flames and die in agony .
-
How many "User Events" can LabVIEW queued?
Justin Goeres replied to MViControl's topic in Application Design & Architecture
First, this is a great discussion. Keep it going! I just have a couple minor points of clarification to make. Regarding the "state machine" terminology, it is absolutely true that the JKI State Machine is not a state machine in the strictest sense of the word. It's really more of a sequencer. For those of you who have seen JKI's LabVIEW User Group presentation on the JKI SM, you may remember that we usually point this out to head off exactly these discussions . I suppose you can call it a message handler, too, but we don't get hung up on the exact terminology. Besides, rightly or wrongly LabVIEW developers (especially beginning ones) think of a state machine as "a While Loop with an enum in a shift register, which drives a Case Structure." The JKI SM is string-based, but it looks a lot like what they're familiar with and so calling the JKI SM a state machine helps them understand it. The other point I want to make (which might be sort of at odds with the "state machine" terminology issue), is that we don't just treat the JKI SM as a state machine. We use it like a fundamental building block for creating LabVIEW code. It's as much a first-class citizen in the language as a While Loop or a Case Structure, and it's the basis for other, more complicated designs. If you need to build a "real" state machine, you can absolutely do it using the JKI SM as a starting point. Or if you need separate loops for UI handling and asynchronous processing, each of those can be a JKI SM. Part of the reason we love the JKI SM so much is because of its scalability and flexibility. FYI, I'm going to be doing a presentation at NIWeek 2010 with Nancy Hollenback (The G Team) and Norm Kirchner (NI) called "State Machine vs. State Machine," comparing two different SM designs (JKI's and one of Norm's) and discussing how each one approaches different design decisions. It's currently slated for Tuesday morning right after the first keynote, so if you're coming to NIWeek 2010 put it on your calendar . -
So much cooler than outside that it will literally feel like someone is hitting you in the face when you walk through the exit. Also you will spend all the sessions shivering.
-
Thanks for trying. I had already investigated this a while ago and basically received the same answer.
-
One additional item! Every year we hand out tickets and have a drawing to give away awesome stuff contributed by individuals and companies in the LabVIEW community! If you or your company has something you would like to contribute, please contact me privately. In return for supporting LAVA and OpenG, I can offer you an authentic-sounding plug for the company/product/person of your choice, delivered by me, or Chris Relf, or yourself. We don't say nice things about everything every day, so don't miss this opportunity! Seriously, though, if you have anything to offer, we would be elated to help you give it away. Contact me if you have any questions or ideas! It is a bit of a walk, but for various reasons Scholz Garten is the best venue this year. We have faith in the LabVIEW community to get ourselves there.