shoneill
-
Posts
867 -
Joined
-
Last visited
-
Days Won
26
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by shoneill
-
Never mind, I just need to learn to read.
-
Does the sync refer to updates to the WAL or to the DB file itself?
-
I just came to the same conclusion while reading the documentation on WAL mode. Go figure. It seems the WAL file does not operate in synchronous mode at all. I wonder if that affects fobustness at all?
-
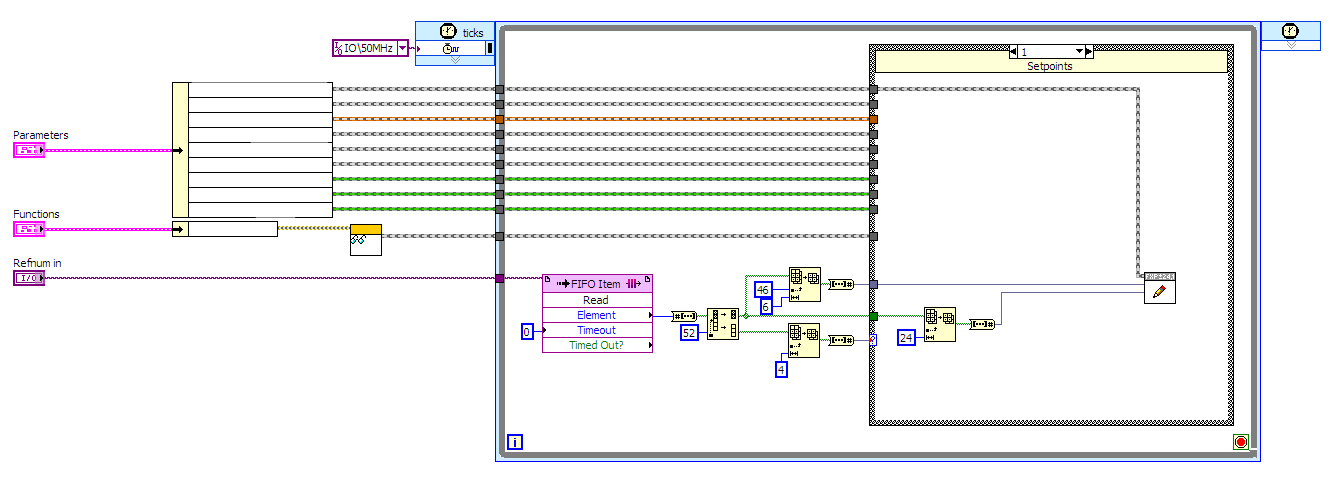
First of all, great toolkit. Thanks. I am re-visiting some benchmarking I had started some time ago and have some observed some unexpected behaviour. After creating a file with an Index, I repeatedly overwrite the existing data with random DBL values (of which there are 500k Rows x 24 Columns). I see an Update rate of approximately 70k Updates per second (Wrapping all 500kx24 Updates in a single transaction). All good so far. Actually, it's 70k Updates where each Update writes 24 distinct Columns so it's actually 1.68M Value updates per second. But 70k Rows. I open the file once, Fill it with zeros (Total number of data points is known from the start - 500kx24 plue 3 Columns for 3D Indexing X,Y and Z), create an Index on the most important columns (X,Y,Z which are NOT overwritten later), prepare a statement for Updating the values and then re-use this statement in a loop for updating. I put all 500k x 24 Updates in a single transaction to maximise speed. Only after the benchmark VI is finished (after looping N times) do I finish the Statement and the SQLite file. All good so far, but now comes the weird part. When I tried investigating the effect of parallel read access I saw no decrease in UPDATE performance. Quite the opposite. When executing a QUERY from a different process (using a different SQLite DLL) whilst writing, the UPDATE speed seemed to INCREASE. The speed of updates went from 70k to approximately 124k per second. On a side note, this is also the speed increase seen when executing the UPDATE with "Synchronous=OFF". Has anyone seen something similar? Can I somehow use this fact to me advantage to generally speed up UPDATE commands? Is the synchronous mode somehow being negated in this situation? The whole thing feels weird to me and I'm sure I'm making a colossal mistake somewhere. I am writing the data in LV, reading using the SQLite DB Browser, so different DLLs and different application spaces are involved. I won't be able to control which SQLite DLL the users have for reading, so this is pretty much real-world for us. File system is NTFS, OS is Win7 64-bit. SQLIte DB Broswer is Version 3.9.1 (64-bit). It uses the V3.11 SQLite DLL as far as I know. I'm using LV 2015 SP1 (32-bit). I've observed this behaviour with both V3.10.0 SQLite DLL and the newest V3.15.2 SQLite DLL. Oh, and I'm writing to a HDD, not an SSD. My PRAGMAS for the UPDATE connection (some are leftovers from investigative benchmarking i.e. threads): PRAGMA threads=0; PRAGMA temp_store=MEMORY; PRAGMA cache_size=-32000; PRAGMA locking_mode=NORMAL; PRAGMA synchronous=NORMAL; PRAGMA journal_mode=WAL; The results are confusing me a little.
-

Futures - An alternative to synchronous messaging
shoneill replied to Daklu's topic in Object-Oriented Programming
Decorator ..... just sayin' -
Futures - An alternative to synchronous messaging
shoneill replied to Daklu's topic in Object-Oriented Programming
For someone against OOP, your posts are really abstract. -
Futures - An alternative to synchronous messaging
shoneill replied to Daklu's topic in Object-Oriented Programming
My dad, your dad? Oh come on. The code is not mine to share. It belongs to the company I work for. You also said for me to "show" you the code, not "give" you the code. I'll at least define elegance for you as I meant it. I call the solution elegant because it simultaneously improves all of these points in our code. Increasing readability (both via logical abstraction and LVOOP wire patterns) - This is always somewhat subjective but the improvement over our old code is massive (for me) Reducing compile times (FPGA compile time - same target same functionality - went from 2:40 to 1:22 - mostly due to readability and the resulting obviousness of certain optimisations) - this is not subjective Lower resource usage - again not subjective and a result of the optimisations enabled by the abstractions - from 37k FF and 36k LUT down to 32k FF and 24k LUT is nothing to sneeze at Increasing code re-use both within and across platforms - this is not subjective Faster overall development - this is not subjective Faster iterative development with regard to changes in performance requirements (clock speed) - this is not subjective That's basically just a rehash of the definition of "turing complete". So your statement is untrue for any language that are not turing complete (Charity or Epigram - thanks wikipedia). It also leaves out efficiency. While you could theoretically completely paint the sydney Opera house with a single hair, it doesn't make it a good idea if time or money restraints are relevant. I mean, implementing VI Server on FPGA could actually theoretically be done, it just won't fit on any FPGA chip out there at the moment..... -
Futures - An alternative to synchronous messaging
shoneill replied to Daklu's topic in Object-Oriented Programming
There isn't a snowball's hope in hell that you're getting the full code, sorry dude. The "classical LabVIEW equivalent" as a case structure simply does NOT cut the mustard because some of the cases (while they will eventually be constant folded out of the equation) lead to broken arrows due to unsupported methods. There's no way to have anything involving DBL in a case structure on FPGA. Using Objects it is possible and the code has a much better re-use value. Nothing forces me to use these objects only on FPGA. I think you end up with an unmaintainable emalgamation of code in order to half-arsedly implement what LVOOP does for us behind the scenes. But bear in mind I HAVE done something similar to this before, but with objects and static calls in order to avoid DD overhead. Performance requirements were silly. Regarding callers having different terminals..... That's a red herring because such functions cannot be exchanged for another, OOP or not. Unless you start going down the "Set Control Value" route which uses OOP methods BTW. My preferred method is front-loading objects with whatever parameters they require and then calling the methods I need without any extra inputs or outputs on the connector pane at all. This way you can re-use accessors as parameters. But to each their own. -
Futures - An alternative to synchronous messaging
shoneill replied to Daklu's topic in Object-Oriented Programming
Note, each and avery object can be defined by the caller VI. Each individual parameter can have a different latency as required. For 10 parameters with 4 possibly latencies, that's aöready a possible million combinations of latencies. -
Futures - An alternative to synchronous messaging
shoneill replied to Daklu's topic in Object-Oriented Programming
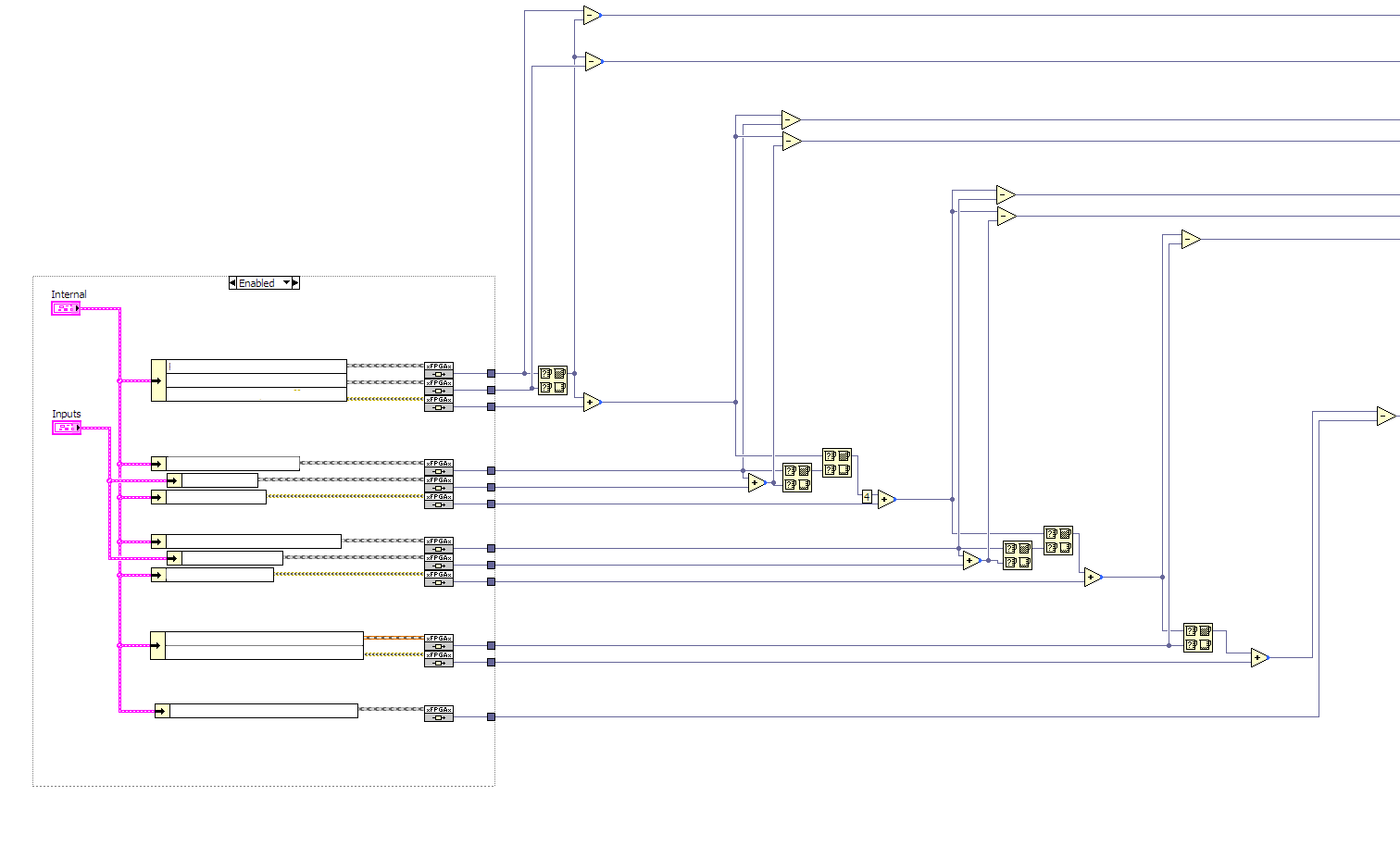
Here are two small examples: H Here I have several sets of parameters I require for a multiplexed Analog Output calculation including Setpoints, Limits, Resolution and so on. Each of the parameters is an object which represents an "Array" of values with corresponding "Read at Index" and "Write at Index" functions. In addition, the base class implements a "Latency" method which returns the latency of the read method. By doing this I can choose a concrete implementation easily from the parent VI. If I need more latency for one parameter, I use my Dual-Clock BRAM interface with minimum latency of 3. If I am just doing a quick test or if latency is really critical, I can use the much more expensive "Register" version with Latency of zero. I might even go insane and write up a version which reads to and writes from existing global variables for each element in the array. Who knows? In this example I am using the base class "Latency" method to actually perform a calculation on the relative delays required for each pathway. By structuring the code properly, this actually all gets constant folded by LabVIEW. The operations are performed at compile time and my various pathways are guaranteed to remain in sync where I need them synced due to this ability. Even the code used to perform calculations such as "Offset correction" can have an abstract class but several concrete implementations which can be chosen at edit time without having to completely re-write the sub-VIs. I can tell my correction algorithm to "Use this offset method" which may be optimised for speed, area or resources. The code knows its own latency and slots in nicely and when compiled, all extra information is constant folded. i just need to make sure the interface is maintained and that the latency values are accurate. How to do this without LVOOP on FPGA? VI Server won't work. Conditional disables are unwieldy at best and to be honest, I'd need hundreds of them.
-
Futures - An alternative to synchronous messaging
shoneill replied to Daklu's topic in Object-Oriented Programming
Oh and BTW, I'm currently programming on FPGA targets with, you guessed it, lots and lots of objects. I certainly don't see how I could be achieving similar flexibility and scaleability without utilising objects. The fact that LabVIEW does a full hierarchy flat compilation of all objects (and thus all Dynamic dispatch calls must be uniquely identifiable) makes some very interesting techniques possible which simply can't be done anywhere NEAR as elegantly without objects. Or is that not OOP in your books? -
Futures - An alternative to synchronous messaging
shoneill replied to Daklu's topic in Object-Oriented Programming
I didn't say that the interfaces may comprise objects but that the systems themselves may, even if their interfaces are Object-free. I suppose the word "contain" is maybe more precise than "comprise". -
Futures - An alternative to synchronous messaging
shoneill replied to Daklu's topic in Object-Oriented Programming
But, like others here, I don't get your point regarding the evils of OOP (Both in general and specifically in connection with this topic). I bet a lot of the windows subsystems you are used to interfacing with may or may not comprise Objects. What difference does this make? -
Futures - An alternative to synchronous messaging
shoneill replied to Daklu's topic in Object-Oriented Programming
Why isnt a VI an Object? It is last time I looked. -
Futures - An alternative to synchronous messaging
shoneill replied to Daklu's topic in Object-Oriented Programming
Interesting discussion. Seeing how I utilise user events for inter-process communication a lot, spawning callbacks dynamically (which then perhaps write to a notifier or whatever method is preferred) means it should be rather simple to implement this feature (I'm hugely in favour of callbacks for this functionality either way due to the ability to properly hide the user event refnum from the listener - a major leak in the otherwise very useful implementation of user event registrations). I might just give it a try at some stage. -
Boolean Tag Channel vs Notifier Performance
shoneill replied to infinitenothing's topic in LabVIEW General
I have vague memory of hearing (or reading) at one stage that one COULD implement a different flavour of the channels if required. I can't remember where or when I came across that information. -
Setting the key focus on an array control programatically
shoneill replied to John Lokanis's topic in User Interface
I really don't like defer front panel updates (unless working with tree controls), so for me that makes it a PITA. -
Setting the key focus on an array control programatically
shoneill replied to John Lokanis's topic in User Interface
There is a PITA way of getting what you want. Set the Array index to the element you want to set focus to. Set the visible size of the Array to a single element (The one you want to set). Set the focus. Set the size of the array back to the original settings. Re-set the Index of the Array (if required). Like I said, PITA. By forcing the array to show only a single element, the control reference to the array element will be forced to the one you want. I haven't tried doing this in advance and then using several array element references, but I think they will all change in unison (as the array element is a property of the Array). -
Boolean Tag Channel vs Notifier Performance
shoneill replied to infinitenothing's topic in LabVIEW General
So one thing I have learned here is that calling a VI by reference is WAY faster than I thought. When did that change. I may have last tested in LV 6.1 -
Boolean Tag Channel vs Notifier Performance
shoneill replied to infinitenothing's topic in LabVIEW General
So questioning my previously-held notions of speed regarding calls by reference I performed a test with several identical VIs called in different ways: 1) DD Method called normally (DD cannot be called by reference) 2) Static class method called by reference 3) Same static method VI called by reference 4) Standard VI (not a class member) called by reference 5) Same standard VI called statically All VIs have the SAME connector pane controls connected, return the same values and are run the same number of times. I do NOT have VI profiler running while they are being benchmarked as this HUGELY changes the results. Debugging is enabled and nothing is inlined. The class used for testing had initially NO private data, but I repeated the tests with a string as private data along with an accessor to write to the string. Of course as the actual size of the object increases as does the overhead (Presumably a copy is being made somewhere). The same trend is observed throughout. I can't attach any images currently, LAVA is giving me errors..... Results were: 1) 0.718us per call (DD) - 1.334us with String length 640 2) 0.842us per call (non-DD, Ref) - 1.458us with String length 640 3) 0.497us per call (non-DD, Static) - 1.075us with String length 640 4) 0.813us per call (Std, Ref) - 1.487us with String length 640 5) 0.504us per call Std, Static) - 1.098us with String length 640 It appears to me that calling a vi by reference versus statically adds approximately 0.3us to the call (nearly doubling the overhead). Given this fact, a single DD call is actually slightly more efficient than calling an equivalent static member by reference. (or a standard VI by reference for that matter). Of course we're at the limit of what we can reliably benchmark here. -
Boolean Tag Channel vs Notifier Performance
shoneill replied to infinitenothing's topic in LabVIEW General
Ah crap, really? I keep forgetting that. Well it was basically a discussion where Stephen Mercer helped me out with benchmarking DD calls anc making apples to apples comparisons. LVOOP non-reentrant : 260ns Overhead LVOOP reentrant : 304ns Overhead LVOOP static inline : 10ns Overhead Standard non-inlined VI : 78ns Overhead Case Structure with specific code instead of DD call : 20.15ns Overhead "manual DD" (Case Structure with non-inlined non-reentrant VIs) : 99ns Overhead A direct apples-to-apples comparison of a DD call vs a case structure witn N VIs within (Manually selecting the version to call) showed that whatever DD is doing, it is three times slower (in Overhead, NOT execution speed in general) than doing the same thing manually. Again, bear in mind this measures the OVERHEAD of the VI call only, the VIs themselves are doing basically nothing. If your code takes even 100us to execute, then the DD overhead is basically negligible. -
Boolean Tag Channel vs Notifier Performance
shoneill replied to infinitenothing's topic in LabVIEW General
Try setting the DD VI to not be reentrant...... The tests I made were with non-reentrant VIs (and with all debugging disabled) and I saw overheads of the region of 1 microsecond per DD call. I have had a long discussion with NI over this over HERE. If DD calls really are by-reference VI calls int ehbackground that would be interesting, but I always thought the overhead of such VI calls were significantly slower than 1us. Maybe I've been misinformed all this time. -
Boolean Tag Channel vs Notifier Performance
shoneill replied to infinitenothing's topic in LabVIEW General
I dont understand what you are trying to show there to be honest..... -
Boolean Tag Channel vs Notifier Performance
shoneill replied to infinitenothing's topic in LabVIEW General
CAVEAT: I can't open the code provided as I don't have LV 2016 installed, so I don't know HOW the OP is calling the VIs by reference. I'm assuming it's over the Connector pane with a strictly-typed VI reference? -
Boolean Tag Channel vs Notifier Performance
shoneill replied to infinitenothing's topic in LabVIEW General
Being someone on the side of "Why is LVOOP so slow" I can't let this stay uncorrected. While DD calls ARE slow, they most certainly do NOT utilise call VI by reference in the background, They're too fast for that. My benchmarks have shown that the overhead for a pure DD call is in the region of 1us per DD call. Note that if a child calls its parent, that's TWO DD calls (and therefore int he region of 2us overhead). Please note this is purely the OVERHEAD of the call, the actual call my take considerably longer. But even if the code does NOTHING (kind of like here), the 1-2 us are pretty much guaranteed. So LVOOP is slower than it should be, but I don't know if I'd equate it with calling VIs by reference. That's way worse I think.