shoneill
-
Posts
867 -
Joined
-
Last visited
-
Days Won
26
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by shoneill
-

Decouple UI and application core - need advice
shoneill replied to candidus's topic in Application Design & Architecture
Yes, the really crappy propagation of registration refnums is perhaps the major obstacle to the 1:1 command:event organisation. That and the Event Structure mixing up the order of events whenever I add another event to the API...... -
Decouple UI and application core - need advice
shoneill replied to candidus's topic in Application Design & Architecture
While I see the pacticality of this, it makes me feel all icky doing it....... -
Decouple UI and application core - need advice
shoneill replied to candidus's topic in Application Design & Architecture
+1 for multiple User Events (why do away with the strict typing of LV) -
That's exactly what I was referring to, but apaprently there are additions coming which will make things even easier.......
-
I believe a LV version coming soon (but not very soon) will not address this directly but may give us tools to allow this kind of operation to be performed. I'm hopeful.
-
There's another way to achieve (almost) memory-mapped files. https://msdn.microsoft.com/en-us/library/windows/desktop/aa364218(v=vs.85).aspx If you read from (or write to) a file, Windows automatically memory-maps that portion of the file as long as RAM is available for it. Although this mapping is not forced (it can be negated by other processes requesting RAM - then disk write and read is via disk and a lot slower) it can still be of great use. If you need very fast write speed or read / write speed, pre-write (or pre-read) the file before your actually important work. Chances are that Windows will already do this in memory but with the added benefit of eventually persisting it to disk. If you want to purposefully AVOID persisting to disk, then just ignore my entire post.
-
I've found adding, subtracting, multiplication and division to be quite useful...... But on a more serious note. I'm sure there are areas of mathematics I don't even know exist which may or may not be helpful. But if you want to go into pure mathematics as opposed to applied mathematics, your chances are greatly different to be able to apply when doing productive work. I studied statistics, calculus and so on at University. I've rarely needed to understand more than the basics. Trigonometry helped a bit due to the fact that we use a lot of modulators and demodulators but the effect was minimal. Also the numerical theory behind filters (Kalman, Butterworth and so on) can be very useful. Beyond this, I'm simply not qualified to answer.
-
The version with a loop won't work in a SCTL on FPGA. The version with Feedback node will AFAIK.
-
This is true. One would think that with proficiency, this problem-trading (old ones replaced with new ones) would shift in our favour. My experience is that the number of problems stays approximately constant but the newer ones become more and more obscure and hard to find. This is a bit of a pessimist (realist?) view I will admit. Truth is that we just keep looking until we find problems. And if we can't find any problems, then we convince ourselves we've missed something.
-
How the DVR is structured, whether the DVR is encapsulated or not is a design choice based on the requirements (one of which could be the parallel operation AQ points out). The DVR is simply a method to remove the awkward requirement of "branch and merge" mentioned in the OP. I've done some similar UI - Model things in the past and I've found using by-ref Objects simply much more elegant than by-val Objects. DVRs are the normal way to get this. Whether we use a DVR of the entire class or the class holds DVRs or it's contents is irrelevant to the point I was trying to make: Instead of branching, modifying and merging, just make sure all instances are operating in the same shared space.
-
Logman, don't forget that immediately after writing a file, Windows will most likely have a complete copy of that file in RAM so your read speed will definitely be affected by that unless you're somehow RAM-limited or are explicitly flushing the cache. Always approach read speed tests with care. Often the first read will take longer than the second and subsequent reads due to OS file caching. Just for completeness.
-
For simple atomic accessor access, splitting up actual objects and merging MAY work but once objects start doing consistency checks (perhaps changing Parameter X in Child due to setting of Parameter Y in Parent) then you can end up with unclear inter-dependencies between your actual objects. When merging, the serialisation of setting the parameters may lead to inconsistent results as the order of operations is no longer known. When working with a DVR, you will always be operating on the same data and the operations are properly serialised. Of course it's of benefit to have some way of at least letting the UUI know that the data in the DVR has changed in order to update the UI appropriately.... but that's a different topic (almost).
-
Instead of splitting and merging actual object data, split and share a DVR of the object to the UI and have both the UI and the caller utilise the DVR instead of the bare object (Yes, IPE everywhere can be annoying). That way you can simply discard all but one (it's only a reference, disposing it is only getting rid of a pointer) and continue with a single DVR (using a Destroy DVR primitive to get the object back) after the UI operation is finished.
-
Tab showing after open, but prior to run
shoneill replied to Gan Uesli Starling's topic in LabVIEW General
right-click the Tab when it's on the correct tab and select "Set Current Value to Default". -
So fine control of the buffer (setting it to 1 or two messages) would force synchronous messaging on the TCP driver level? That's rather useful.
-
I did NOT know that. That's kind of cool.
-
How do you set the TCP buffer, it's typically a driver setting, not a LV setting. At least AFAIK. If it's possible to limit the receive buffer of an ethernet card, I'd be interested to know. My experience (based on others' experience I must admit) is that this can't be controlled from within LV. If you fill the receive or transmit buffer of an ethernet card, you typically lose conenction. We see this sometimes when our host software can't keep up with our RT system sending data at 20kHz. Buffer overflow, lost connections, chaos ensues.
-
I would imagine not flooding the buffer would be one, trying to synchronise sender and receiver is another. If the listener is the "master" then the protocol needs to be implemented this way. So if it can be done with 1 TCP port, even better.
-
You need a different protocol. Have the reader send a "I'm waiting" packet to the writer, and have the writer simply wait until one of these is present in it's receive buffer vefore sending. This is a duplex communication, requires two TCP ports but should throttle as you require.
-
Shaun makes a good point. I remember doing that decades ago when there was no RGB processing available. I did some processing on a mono version of an image but overlayed on a copy of the colour original. Imemdiately my boss asked me "How on earth did you manage to do that" because he assumed I had done the processing on the RGB image. He was kind of surprised to hear of what I did. The human brain automatically correlates the data visible (picture and results) to be a coherent pair even when they are not. I mean, Trump and President. Come on. <\joke>
-
IIRC most cameras have different acquisition modes (mono, 4-bit, 8-bit and speed and so on) but the properties needed to be set are different per camera. You can query the modes available via the IMAQ driver and find the one you need, note the index of the mode and then set that mode. Note that this may be different for each camera type and your predecessor may have set it in code or in MAX.
-
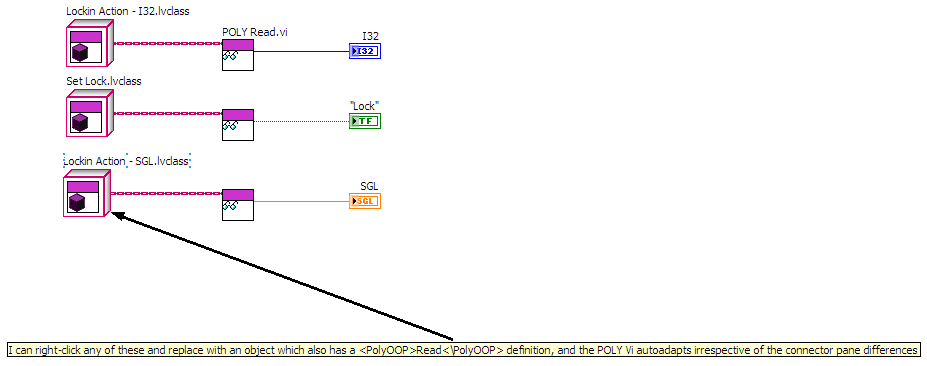
I have been experimenting with using polymorphic VIs with LVOOP. In my specific case, I have a large-ish hierarchy of very similar classes. Each one has a "Read" command. I have a base class which defines SOME of the functionality, but the "Read" method is not defined here since each datatype implements its own "Read", one for SGL, one for I32, one for Boolean and so on. As such, Dynamic Dispatch won't work (and I don't like Variants as inputs). This works OK except for when I want to swap out a SGL datatype with an I32 and the VI "Read" becomes broken because there is no inheritance link between the SGL "Read" and the I32 "Read" even though the two might even have the exact same name. Instead, I can create a Polymorphic VI with all "Read" variations in it (I can do this by scripting, it doesn't need to be manually maintained). Creation of the POLY VI is actually relatively simple. Choose a specific version of the method (file dialog), parse up to the root ancestor, parse back all children which have the same tag and add them to a POLY VI. To do this, I have added a line to the Description of the VIs involved (for example "<POLYOOP>Read</POLYOOP>". Once created, I can simply drop this polymorphic VI instead of a naked "Read" and everything works fine. Of course this means that all of my "Read" need to be static VIs because POLY VIs don't work with Dynamic Dispatch. A small trick is reversing the order of the concrete instances found when adding to the poly VI so that the most specific are listed forst, followed by more generic with the base class as the LAST entry in the Poly VI. This way, autoselection will choose the most specific version available according to the class type at the input. If I need a different version, I can still right-click the VI and choose the specific version I want. This can be used for allowing switching of methods (which may have different names AND different connector panes but which all represent the same action for an object). It allows for autoadaption of differently-named functions for two distinct classes irrespective of connector pane differences It requires a POLY VI to be maintained (Not part of any of the classes as this POLY VI can be project-specific) - automating the POLY VI creation alleviates most of this pain This operates on the visible wire type, not on the actual object type, so care is required to make sure the correct versions are actually being called (In my "Read" case, this is not a big problem) Creating arrays of varied objects will cause all to execute the method associated with the common denominator. This approach is targetted more at cases where we pass a command to a handler and retrieve an object of the same type (by utilising "Preserve Run-Time Class at the output of the handler) and then want to access the returned data. Is there a way to do this without a POLY VI? XNode? UIsing the POLY VI pulls in a lot of classes as dependencies (All which have the <PolyOOP>Read<\PolyOOP> text).... Being able to do the adaptation dynamically would be cool. I have no XNode experience but apparently XNodes and LVOOP don't mix too well? Perhaps most importantly: Is this a completely off-the-wall and stupid idea?

-
I can't access either of the webcasts, I get a timeout connecting to ni.na3.acrobat.com Maybe this is linked to the new NI layout changes? Are there newer links which are still working?
-
I was browing through the actor framework discussions on the NI site yesterday and I came across a statement by AQ. Never inherit a concrete class from another concrete class I had to think about that for a second. The more I think about it, the more I realise that all of the LVOOP software I have been writing more or less adheres to this idea. But I had never seen it stated so succinctly before. Now that may just be down to me being a bit slow and all, but in the muddy and murky world of "correct" in OOP-land, this seems to be a pretty good rult to hold on to. Are there others which can help wannabe plebs like me grasp the correct notions a bit better? How about only ever calling concrete methods from within the owning class, never from without? I'm learning for a long time now, but somehow, my expectations of LVOOP and the reality always seem a little disconnected. AQs statement above helped crystallise out some things which, up to that point, had been a bit nebulous in my mind. Well, I say I'm learning..... I'm certainly using my brain to investigate the subject, whether or not I'm actually LEARNING is a matter for discussion... The older I get, the less sure I am that I've actually properly grasped something. The old grey cells just seem to get more sceptical with time. Maybe that in itself is learning...
-
Random Trivia: Type Cast is also the only way to cast a 32-bit Integer to a SGL and retain the bit pattern. I also had an application on a RT system which wanted to do this and when I realised this was not in-place (it takes approximately 1us for EACH U32-SGL conversion which was WAY too much for us to allow at the time) I had to scrap it and refactor my communications. We should get together and pester NI to offer an in-place bit-preserving method to convert between different 32-bit representations!