shoneill
-
Posts
867 -
Joined
-
Last visited
-
Days Won
26
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by shoneill
-

Subpanels: what are the rules for order of operations?
shoneill replied to Aristos Queue's topic in LabVIEW General
Oh right, Stephen started the thread..... Oops, kind of forgot that in all the "Why" and "how". -
Subpanels: what are the rules for order of operations?
shoneill replied to Aristos Queue's topic in LabVIEW General
Olivier, reading your post made me realise something (it happened magically by reading the words you wrote!). Launching an ABCR requires some mechanism to retain a reference somewhere so that at a later stage we can get the results back using the "collect" functionality (the proxy you refer to). This would indeed seem the most likely candidate why the "Run VI" and "ABCR" are fundamentally different in this regard. -
Subpanels: what are the rules for order of operations?
shoneill replied to Aristos Queue's topic in LabVIEW General
Can you also confirm that the ABCR versions do NOT die when removed? -
Subpanels: what are the rules for order of operations?
shoneill replied to Aristos Queue's topic in LabVIEW General
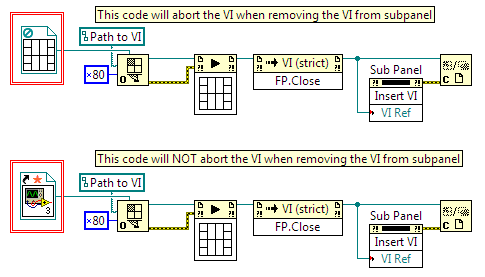
Here are three VIs for testing which show a difference in behaviour between ABCR and Run VI. In the Run VI version, after removing the sub-VI fromt he subpanel, it is aborted. In the ABCR version, the sub-VI keeps running after being removed. In BOTH cases I close the references after inserting into subpanel. You may need to change the path of the control on the FP in order to find the sub-VI. Can anyone else confirm that the ABCR sub-VI still runs after removing whereas the Run VI sub-VI does not? subpanel test ABCR.vi subpanel test RunVI.vi Blinker.vi -
Subpanels: what are the rules for order of operations?
shoneill replied to Aristos Queue's topic in LabVIEW General
I can't reproduce it today either. I don't know what it is I saw last week. I give up. I just ran the same code which gave me clear results last week, and now using the ABCR, both code versions do NOT abort the vi as you say. I still see that not having a static ref to the sub-VI anywhere in memory and using the "Run VI" method always aborts the VI, even if the "Auto dispose" is set to true. So it appears to be a plain "Run VI" vs "ABCR" thing. Note: Even putting the strict reference in a disable structure keeps the reference in memory, you really need to remove it fromt he code altogether. But having said all of that, I could have sworn the results I saw last week were clearly different. Must be getting old. -
Subpanels: what are the rules for order of operations?
shoneill replied to Aristos Queue's topic in LabVIEW General
This is true. By replacing a strict VI reference (Browsing for the path and setting to Strict Typed) with a Generic reference of the same type (Also strict typed, but not linked to any specific position on disk) the VI is again aborted when removed from the subpanel. So even using the ABCR is not a guarantee. It's having the strict reference on the BD that keeps the VI in memory afterwards, so essentially no surprises there.
-
Subpanels: what are the rules for order of operations?
shoneill replied to Aristos Queue's topic in LabVIEW General
@drjdpowell, That I was not aware of. That's quite an interesting tip. I was also unaware that the Run VI with autodispose set to TRUE would actually prevent this behaviour. Edit: The Open Vi Reference followed by "Auto Dispose" TRUE only seems to work if I wire in a strict VI Reference constant with the correct connector pane. If I do a generic "VI Open" without the VI Type being specified, the VI will still auto-abort when leaving the sub panel even if "Autodispose" is set to TRUE. So the method to avoid the VI auto-aborting seems to be linked to the usage of a strict VI reference when opening the reference and less the method used afterwards. Good to know. Testing done in LV 2012 SP1. -
No, of course not. You would need one single VI per datatype you are registering events for. If not everything is a typedef, this tends to not be too many VIs. Of course there would be 80 VIs in memory (callback VIs), but not 80 VIs on disk.
-
Subpanels: what are the rules for order of operations?
shoneill replied to Aristos Queue's topic in LabVIEW General
Just a note of warning depending on what the VI should do when it leaves the subpanel.... Due to the fact that the FP must be closed before entering into the subpanel, if you happen to close the reference you used when inserting, then upon exiting the subpanel, the VI will abort (Closed FP, no managed references in memory). As long as the VI is in the subpanel, the subpanel seems to manage it's own reference to the VI. I suppose this would suggest that yes, the subpanel closes a reference to the sub-VI when the sub-VI exits the subpanel. This can be a bit surprising when you come accross it the first time (and I still think it's not ideal behaviour to be honest). You have to babysit that original reference until the VI has left the subpanel, had its FP set to not closed and then and only then can you close that VI reference. Or you can open a new reference just before removing, set the FP to "hidden" and then close the reference whereupon the VI will continue running. -
I always thought they meant one event structure per loop myself.... But yeah, I believe it is meant as one per Block Diagram.
-
Reminds me of another method I've used in the past where I group lots of functionally similar events and place each group in it's own event structure, blatantly disregarding the general idea to not have move than one event structure in your code.... At least that way I could remove and add new functional groups without having to touch other event structures.
-
The code obfuscation is really an annoying (and very serious and real) part of the implementation. It is enough to stop me applying the idea in a widespread manner because the cost of debugging can be large. The only other thing I could think of woule to implement the callback VIs with LVOOP and have the parent optionally include some debugging information which cen be centrally logged / viewed / sorted. I believe it could be solvable but my 24 hour days don't give me enough time to come close to doing such an idea justice.
-
I too have done different things to better handle this kind of scenario. Recently my interest has beek piqued by the possibility of using callback VIs for registering the Events rather than using the Event structure itself. The advantage of this? You can split the handling of the events among different levels of an object inheritance chain. This method couples well with the command pattern for the receiving end. Advantages: Essentially allows us to split up individual frames of the Event structure into individual (boiler-plate) VIs. Disadvantages: Knowing somehow that the events are being handled somewhere and that the callback VIs themselves run int he root thread.
-
But option B works fine if you make the changes I mention in my post. There's no need for C at all. It answers a completely different question (A good answer I might add, I've no problem with the correctness or quality of the proposed solution, just that it goes way beyond the problem posted.)
-
Yes, from what you have written, I believe we are disagreeing. The OP had a problem with a piece of code from a post which explicitly describes what I'm proposing. There seems to be a simple misunderstanding here since the broken wire the OP has in his code as actually explained and accounted for in the link he himself provides in the first post. While the idea of encapsulated configuration panels is a great one, it shoots WAY beyond the scope of the original question as I read it (YMMV). Explicitly, the following was asked with regard to the OPs broken wire: "My question to you all is, "Am I correct in my understanding or is there a better way to deal with this case?" " My post answers this. And yes, it is a way for a piece of code to EXPLICITLY interact with a specific type of object from a mixed object array. Because that was the question posed.
-
-
-
From the album: Attachments
-
I have to reluctantly disagree with drjdpowell, You can create a sub-VI. Connectors are 1) An Array of parent objects INPUT 2) a single parent object INPUT 3) a single parent OUTPUT In this VI, you can check all of the objects int he input array until you find one which fits (choose your own method, either preserve runt ime class or your own method depoending on whether you want to allow EXACT matches or whether you also want to allow ancestors to be returned). Output this one from your loop and before writing it to the output terminal, run it again through a "preserve run-time class" with the Input terminal as the upper middle input. Now, when using this VI in the IDE, if you wire a Felidae to the input, it will output the first class which is compatible with this type (felidae or ancestor) but the output will be THE SAME TYPE as the INPUT to the VI (Strictly typed). And of course when I say "the same type" I meant he same WIRE type since obviousloy the exact object type can only be determined at run-time. I was amazed to come across this functionality years ago but have used it on many occasions since. It's like outputting a parent object and then running "preserve run-time class" on it, but the IDE is clever enough to realise that the sub-VI is already doing this, thus saving duplicate code. This kind of auto-adapting of object type is relatively unknown in LabVIEW but it's a really cool thing, the subVI thusly produced almost acts like an XNode.
-
Gah, problem time. Our data requires the ability to pass back a running average at any time. This is proving to be a bit difficult. I'm able to save all of our "static" data into a TDMS at really good speeds with no fragmentation, so far so good. I want to maintain a runninng average somewhere in the file and I thought I could pre-allocate a group for this and fill it with dummy data and then update (overwrite) by setting the file write pointer as required and overwriting the already written data with newly calculated data (Read, modify, write). Problem is, setting the file pointer requires the file to have been opened via the advanced Open primitive. If I do this, the "normal" functions don't seem to work. We need a running average because some of our measurements last several hours and giving no feedback during this time is not cool. As it is, generating the average when the full dataset is present is no problem, it's the running average I have trouble with. The data required for this running average could run into several hundred megabytes, we're dealing with potentially very large datasets here. I know this mixed-mode behaviour isn't what TDMS is supposed to do but does anyone have any smart ideas how to do this without having to utilise a temporary external file (and copy the results over when finished. This requires my routine to get the data to be aware of this extra file and pull in the current averaged data when required. More work that I was hoping for.....
-
Hmm, my initial testing seemed not to bode too well for TDMS. I was getting miserable write speeds..... I was iterating through the data I wanted to write and appending new channels as required, creating new groups as required and writing point for point. This yields terrible results. I have since found the all-important "TDMS Set Channel Information" function which allows me to tell the TDMS function what I'm going to be writing which actually allows it to write in the most efficient way. Seems to be the very important missing piece of my puzzle. It's a much more involved thing than I was expecting and I find resources for really explaining how to get the best out of any given situation (how your data is received versus how you want it saved) rather lacking on the internet. I suppose I'll have to just get my hands dirty and experiment. I think I have a much better grasp of how to optimise things now. Shane
-
I'm less worried about file fragmentation, I should be able to write the data in more or less sensible chunks. I'm more worried about how to get the data back I want. I want to be able to request data for display by specifying which channel(s) and whether I want X vs Y or Y vs Z or Z vs X and so on. Coupled with the display scale (max-min X) I want to be able to do a memory-efficient processing of the raw data before passing it back to be displayed. This should help significantly reduce the memory footprint when dealing with large datasets (and large means up to 1GB). We never need to display so much data so the actual decimation in this approach will be significant (although I'd prefer a max-min decimation). My worry is how to manage reading from file to get the data into my decimation algorithm as efficiently as possible (both speed-wise and memory footprint-wise). I'll have to benchmark them I suppose. I looked at SQLite before and because I have very limited SQL experience, it's the queries and proper data structure I'm unsure about there. Especially when dealing with custom data reading schemes, I have the feeling a SQL-like approach offers signifant benefits.
-
One other point to consider is if SQLite wouldn't be a better idea taking the high level of flexibility and efficiency we would be trying to achieve when visualising the data.
-
I'm currently investigating using TDMS as a data storage for a new measurement method. In our routine, we sweep up to 3 outputs (with X, Y and Z points each) and record up to 24 channels so we have XxYxZx24 datapoints. We create the following: Up to X data points for 24 channels of data interleaved in the first dimension (multichannel 1D) Up to Y times this first dimension (making the data multichannel 2D) Up to Z times this second dimension (making the data multichannel 3D) So in a sense, we create 4D data. Trying to use our old method of storing the data in memory fails quickly when the number of steps in each dimension increases. So we want to store them in TDMS files. But looking at the files and trying to imagine what read speed will be like, I'm unsure how to best store this data. DO I need multiple TDMS files? A single file? How to map the channels / dimensions to theinternal TDMS structure? In a further step to my efforts, I would be investigating having the routine for retrieving any sub-set of this data (1D or 2D slices from any combination of dimensions but almost always one channel at a time. Can anyone with more experience with TDMS files give some input and help a TDMS noob out?
-
In my build spec, I define a target directory, tell it to store it in an LLB and then just put the lvlib (and all lvlib files) in there. Seems to work fine. OH, and LV 2012 SP1
-
I just offloaded a portion of our main application code into lvlibs and when building the executable, placed them outside the exe itself. Where did I put them? In an LLB. The LLB contains only the library and it's members. Isn't that (more or less) your point 4) ? I use normal lvlibs in development but the application builder slaps them into an LLB for our application (and automatically re-links to the LLB of course).