Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-
I'd be willing to bet the total number CLADs >> the total number of crelfs. Ergo, your "excessive" use of sub vis is insufficient to counteract the collective impact of CLADs (and uncertified users) who do not use enough sub vis.
-
My initial reaction is no, it doesn't make much sense, but if anyone proposes a valid use case then I could be persuaded. Off the top of my head there are a couple issues with this idea: 1. The receiver has to monitor several queues simultaneously. This is possible (the Priority Queue in Mercer's Actor Framework is the first implementation that does it well) but it does add unnecessary complexity in most cases. In most cases each actor/loop should only be listening to a single queue. 2. Type safety on the sending side doesn't gain you anything. All the different queue types will be going to the same receiver, so having to pick the correct queue from the collection is just a hassle. 3. Type safety on the receiving side doesn't gain you anything either. After you pass the message out of your dequeue sub vi you'll still need to downcast to a specific class to get any information from the message itself. Type safety is helpful in detecting programming errors, but sometimes it requires an inordinate amount of extra effort to maintain type safety while a non-type safe solution will be faster to implement and easier to understand. Tell me again why you're developing all your own stuff instead of joining LapDog?
-
I actually have a class laying around somewhere I prototyped a couple years ago specifically to send periodic messages to slaves. It's one of those things I've been meaning to add to LapDog....
-
FWIW most of my block diagrams do fit on a single screen. Often vis with continuous loops will not. That includes actor ExecutionLoop vis, non-trivial UIs, etc. Well, since you posted it.... If I were king for a day I'd change the last sentence to, If the diagram becomes larger than one screen, review it and look for opportunities to improve readability and reduce size by inserting appropriate abstractions. It puts the emphasis where it should be--on the readability. (Which, by its nature, is entirely subjective and resists definition by objective rules.)
-
I've seen a few implementations over the years have the dequeue timeout on a shift register, but I've never quite trusted them--probably because I didn't spend enough time investigating them. That implementation looks pretty clean. I like it better than putting a message at the front of the queue, which was the other thing I thought about. Do you keep the timestamp of the last flush in an internal shift register? I assume Do.vi is a no-op if the queue timed out? What should we call this implementation? Timeout shifting? Variable timeout? Heartbeat and Timeout Shifting are two ways to get an actor (i.e. slave loop) to perform relatively short process at regular intervals. Intuitively I think the DVR is more suitable when the process is more or less continuous. I noticed a couple other things about Timeout Shifting compared to the Heartbeat. (Not to be down on your solution...) -I believe the temporal separation of the dequeue timeout occurance and the next timeout being calculated will cause the absolute error to grow over time with Timeout Shifting. If you have something that has to execute every 5 seconds, it may start by executing at 0, 5, 10, etc., but after 10 minutes it may be executing at 1, 6, 11, etc. -I don't think Timeout Shifting will scale as well as a Heartbeat. To add multiple periodic task on different intervals to a slave using a Heartbeat, just drop another loop with the message and interval. To do it with Timeout Shifting requires more internal shift registers and logic to make sure only the task to execute next passes its time to the timeout terminal. More importantly, with each additional periodic task to perform, not only does that sub vi get called more frequently, but the percentage of wasted processing time with each execution increases, making the scheme less and less efficient. For practical purposes this may not matter. But as long as the developer understands these consequences I don't think there's anything wrong with them. Thanks for sharing!
-
Not inherently it doesn't. It doesn't surprise me that it does that for you; you're an experienced developer who knows how to make code readable and how to modularize a system. You use the size constraints as a code smell--a trigger to indicate you might want to take another look at the design or layout. Readability is all about creating appropriate abstractions and managing interactions between the abstractions to help the developer understand the software model. Wrapping code in a sub vi is only one kind of abstraction. Norm's TLB template is an example of spatial abstraction. A QSM states are another form of abstraction. For the typical LV user bumping up against the size limit means dumping a bunch of "big stuff" in a sub vi. They don't typically think too much about how to design that sub vi to fit in with the rest of the application's api. If you're lucky they will give some passing thought to making it reusable. Their primary concern is to save space on the block diagram so it won't be too big. A 'single screen bd' application with poorly chosen abstractions is much harder for me to follow than an equivalent application that is larger than a single screen. I agree really large block diagrams often reflect poor designs. But telling a user the bd should fit on one screen doesn't improve their design skills. It just makes more abstraction you or I have to sift through to figure out what's going on. Also, restricting the block diagram to a specific size almost always requires inserting abstractions for the sole purpose of saving space, not because the abstraction makes sense from a software design point of view. This further complicates things. If the goal is readability and modularity, then make readability and modularity the goal instead of instituting an artificial proxy requirement. You misunderstand. I'm not asserting people "shouldn't keep all code on one screen." I'm asserting the claim that "code larger than a single screen isn't good code" is passe and misses the target. I think it's essentially the same as your view, except I don't go to great lengths to make sure users only need to scroll in one direction. (i.e. I might have multiple loops stacked vertically with initialization and clean-up code before and after each loop. Vertical and horizontal scrolling might be necessary to see all the code, but it is organized and clear what each section is for.)
-
I agree. I believe the "single screen" standard probably started with good intentions--creating code that is easy to read--but somewhere along the way the standard became more important than goal and readability/clarity is often sacrificed for the sake of fitting it all on one screen. My goal is to write clear code. The block diagram will be as large as it needs to be acomplish that goal. (Yes, sometimes they'll even require scrolling in two directions.) Sacred cows make the best hamburgers, and the "good code fits on a single screen" cow needs to be slaughtered. (I've carved off a chunk and I have to say it's mighty tasty.)
-
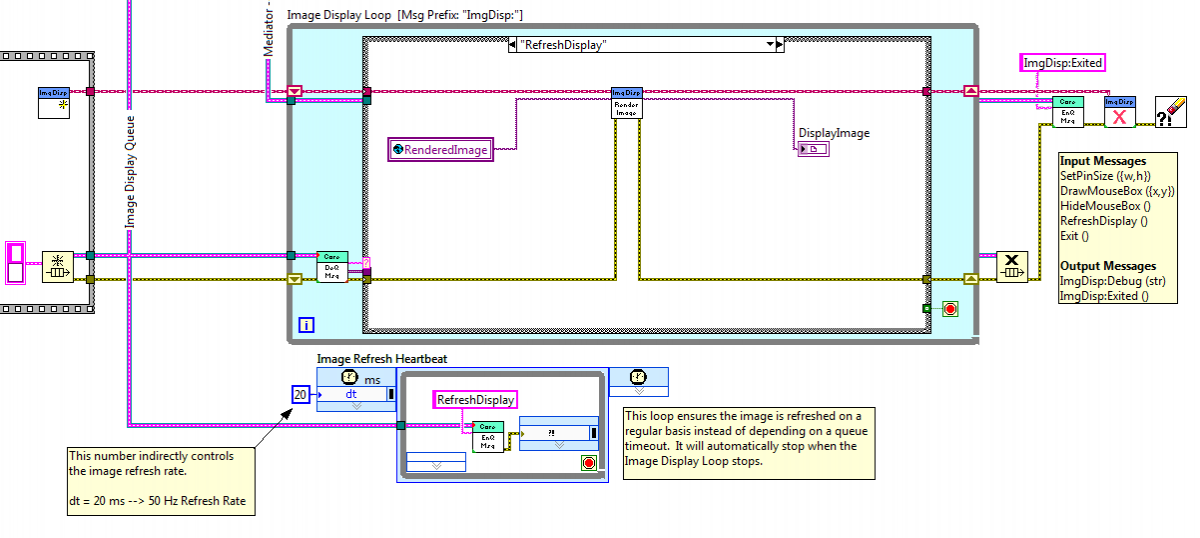
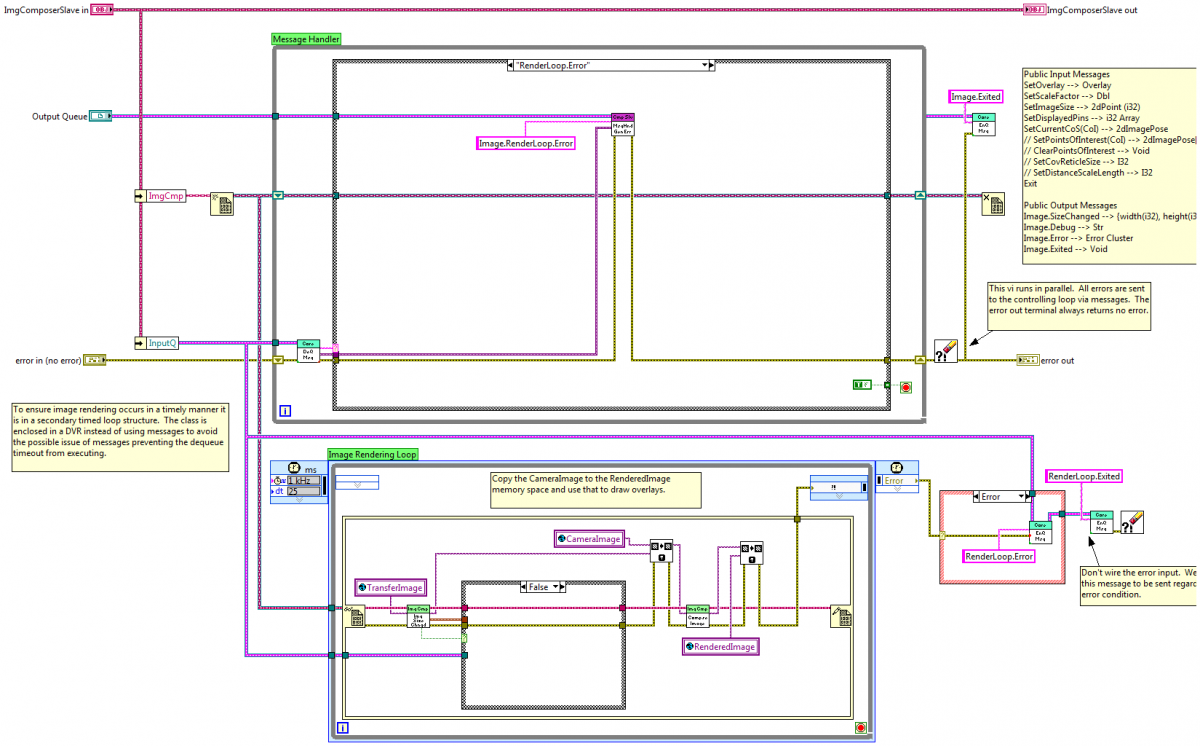
Sorry Alex, I completely forgot about this! Three questions, three answers. Close & Reopen The simplest implementation doesn't allow exiting and restarting a slave loop. Since most slaves are idle unless they are handling a message, this design is adequate for many situations. If you have a continuous-process slave that consumes a lot of resources and want to be able to shut it down when it's not being used, I'd build an internal state machine with "Active" and "Standby" states. In the Standby state the slave simply monitors messages. In the Active state it's monitoring messages and doing the resource consuming processes. OOP Run VI There is no "OOP equivalent." If you want to dynamically launch a slave loop you still need to use that function. (Or the Call Async VI function introduced in 2011.) When I wrap a slave loop in a class, the class usually has three methods: Create MySlave, ExecutionLoop, and Destroy. If I need dynamic launching I'll add a fourth method, Launch. Launch simply loads the ExecutionLoop vi and launches it using the mechanism of your choice. (Note: Dynamic launching adds complexity to the code, so I'll only use it if I need a large or unknown number of identical slave loops.) Plug-ins To me, a "plug-in" is the ability to add functionality to an application without recompiling any of the original source code. When the application starts, it searches the plug-in directory, finds the installed plug-ins, and hooks into them. If that's what you're looking for, then you'd probably need to launch each plug-in slave loop dynamically unless there's a known upper limit on the number of plug-ins that will be running at any one time. I've never done plug-ins with slave loops so I'm not sure what issues you'll run into, but it seems like it'd be fairly straightforward. I occasionally use a queue timeout case for very simple situations, but I consider it code debt because there's no way to guarantee the timeout case will ever be called. I'll usually refactor it into something more robust the next time I'm adding functionality to that loop. There are two ways I've dealt with "continuous process" slaves in the past: Heartbeats and DVRs. Using Heartbeats for Continuous Slave Loops A heartbeat is a simple timer that sends out a single message at specific intervals. (I've also called them "watchdogs," "timers," and in a fit of lyrical excessiveness, "single task producers.") In the example below, every 20 ms the heartbeat loop sends a RefreshDisplay message to the Image Display Loop, ensuring the display will be refreshed regularly regardless of the timing of other messages it might receive. However, it's still possible for the timing to get out of whack if the queue were backed up. [in this example the image display slave loop is not wrapped in an ExecutionLoop vi--it's on the main UI block diagram with several other slave loops and a mediator loop to handle message routing. A heartbeat can be put on a slave's ExecutionLoop block diagram if it is an inherent part of the slave's functionality, but usually setting up the heartbeat on the calling vi is more flexible. Either way the heartbeat is set up to automatically exit when the slave loop exits.] Using DVRs for Continuous Slave Loops When a simple heartbeat isn't an adequate solution, I'll refactor to use a DVR instead. This is the ExecutionLoop of an ImageComposerSlave class. In this particular case the SetOverlay message comes in bursts--a few seconds of high volume messages followed by relatively long periods of no messages, so there was a risk of the message queue getting backed up and throwing the timing off. The ImgCmp object (containing all the relevant information needed to compose an image) is unbundled from the ImgComposerSlave object and immediately put into a DVR. The DVR is branched, with one branch going to the message handling loop and the other going to the image rendering loop. When the message handling loop receives a message that changes a value related to image rendering, it locks the DVR, changes the value in the ImgCmp object, and unlocks it again. The image rendering loop executes at regular intervals, ensuring the rendered image gets produced on time. In principle the rendering loop can block for an excessive time waiting for the message handling loop to release the DVR. However, because the DVR never leaves this block diagram it is easy for me to verify there are no lengthy processes locking the DVR. Does that help? -Dave

-
 Microsoft's new Task-based Asynchronous Pattern. C# async and await keywords in Visual Studio 2011. I agree. Just last weekend I was discussing those keywords with someone who writes MSDN documentation. I left with the distinct impression that it's much harder to reason about the possible code sequences (and potential bugs) when there's no data flow to control it. One thing that wasn't clear to me was what are valid conditions for the async method to resume? Does execution jump out of whatever is currently executing to finish the async method? The person I was talking to didn't know the answer... The other thing about these new keywords I didn't understand until ~45 minutes into our discussion is they are a way to bring asynchronous behavior to a single-threaded application. They are an improvement, but they don't really help with multithreading at all.
Microsoft's new Task-based Asynchronous Pattern. C# async and await keywords in Visual Studio 2011. I agree. Just last weekend I was discussing those keywords with someone who writes MSDN documentation. I left with the distinct impression that it's much harder to reason about the possible code sequences (and potential bugs) when there's no data flow to control it. One thing that wasn't clear to me was what are valid conditions for the async method to resume? Does execution jump out of whatever is currently executing to finish the async method? The person I was talking to didn't know the answer... The other thing about these new keywords I didn't understand until ~45 minutes into our discussion is they are a way to bring asynchronous behavior to a single-threaded application. They are an improvement, but they don't really help with multithreading at all. -
Thanks for all the suggestions everybody. I haven't finalized a decision yet but GovBob's suggestion for Netduino led me to Gadgeteer and the FEZ Spider Starter Kit. At $250 it's not cheap, but the combination of lots of hardware modules and a familiar dev environment (C#) is pretty compelling.
-
[CR] GPower toolsets package
Daklu replied to Steen Schmidt's topic in Code Repository (Uncertified)
I agree with "launch." It's also keeps the lingo consistent with the Actor Framework terminology. -
Many free online repositories require you to grant the host varying degrees of license to your code. Be sure read the fine print.
-
Thanks for the responses... Primarily because ARMs are so widely used. I figure if I'm going to be spending so much time learning a 32-bit micro I might as well learn the most commonly used one. I also would prefer to go with something that is a little more open-source so I'm not tied into one vendor. I think you are confusing the Due with the Duemilanove. The Due is a 32-bit controller. The Duemilanove (and it's replacement, the Uno) are 8-bit controllers. An 8 bit controller won't cut it for my intended application.
-
I have an idea for a home project that's been floating around in my brain for a while involving some relatively simple image pattern recognition. I've done assembly on the 68HC11 and AVR 8-bit micros in years past, but for this one I'm thinking of trying my hand at ARM development. Although it sounds like NI has some promising products on the way I'm guessing it will be too expensive for the hobby market. I've researched a few options and they are all lacking in some way... Raspberry Pi - Hard to beat $25 for all the features this comes with. Unfortunately it's not available yet and I suspect it will take some time for self-learning material to develop... and to be honest my ventures into linux environments haven't been particularly fruitful. Arduino Due - Arduino is a fairly mature platform with lots of available content to draw from. The Due is the first 32-bit ARM processor released for Arduino. Unfortunately, following a surge of post-maker faire publicity last fall the Due seems to have fallen off the planet. I couldn't even find references to it on Arduino's web site. mbed - Another interesting dev platform. Though it is a little more expensive at $60 it has the advantage of actually being able to purchase it. The downside? It uses a web-based dev environment. Thanks, I'll pass. Other tools I've found are positioned (and priced) as business tools, not hobbyist tools. Has anyone had particularly good experiences with an inexpensive ARM devkit and toolchain?
-
Developing OpenG while working for a company
Daklu replied to crossrulz's topic in OpenG General Discussions
All IP or just software IP? (I'm generally in favor of IP laws, though I do think software patents have gotten out of control.) Of course, changing the clause to "employer property" renders my argument moot... -
Short answer: Change the extension to vip. Long answer: It turns out vip files are stored in zip file format. You can open, browse, and unpack them using your favorite zip software. I'm guessing some software (recent versions of Internet Explorer in particular) recognizes the zip file format and changes the extension automatically. The file itself is still intact, so you can change it back to vip and it'll work.
-
Developing OpenG while working for a company
Daklu replied to crossrulz's topic in OpenG General Discussions
The company's goal of purchasing a license is so employees can create a product. Whether or not employees ever use the software is irrelevant as far the license is concerned. The license itself gives the company permission to *use* the software. (Sometimes licenses give permission to *install* the software.) Is "permission" a company-owned resource? Resources are generally limited in some way. Using a resource consumes it. A company owned automobile is clearly a resource--using it consumes its useful life. Furthermore, taking the company car home prevents somebody else from using it. Neither of these conditions apply when someone uses a LV home license on their personal equipment. The license doesn't wear out. The company can't reassign the license to a different employee during the night while you sleep. (Home licenses are only valid for named-user VLM or single seat licenses.) Using it at home or not using it at home has no impact on the company whatsoever, so I don't see the justification for calling it a "resource." I understand that argument, and if that's the defining question then yes, it does appear to be pretty airtight. To my not-a-laywer way of thinking, that's not the question at all. My counterargument would be, "show me the marginal costs associated with the resources I consumed by using the license at home." It doesn't even have to be dollars and cents costs, just costs in general. Like I said, I suspect my argument would be rejected, but it would be interesting to see in play out in court. (Or at least have a lawyer chime in on the legal definition of "company resource.") -
Developing OpenG while working for a company
Daklu replied to crossrulz's topic in OpenG General Discussions
Yeah, I've wondered how the "employer's resource" clause combined with Labview's licensing terms would play out in court over an open source claim. If the company had to purchase an extra license for me to use at home, then yeah, it makes sense to me. But the company purchases the license to use at work, and NI's eula says, "by the way, you can use it at home too." Does the company own the license? Absolutely. Is a home license necessarily an "employer resource?" I'm not so sure... (Though I expect a court would rule against me.) -
Developing OpenG while working for a company
Daklu replied to crossrulz's topic in OpenG General Discussions
Having read through the link Shaun provided I can see I'm wrong. Fortunately, I live in a state that doesn't allow those kinds of employment agreements. There's a post in the DIY Labview group that quotes the EULA and pretty much sums up my view on the matter. The relevant part is: the use of the SOFTWARE on such home computer is limited to work performed in the scope of such person′s employment with you I don't think it necessarily means any work done with the license is for the owner of the license. If I'm working through training material or practicing for a certification exam, none of the code I'm producing is "for" the license owner but it is with the scope of my employment. I don't think NI's intent is to prevent people from doing those kinds of exercises at home. I suspect it is more to prevent an employee from using a home license to do for-profit work outside of the scope of his employment. (i.e. If I want to sell the stuff I produce at home I have to buy another license.) -
Developing OpenG while working for a company
Daklu replied to crossrulz's topic in OpenG General Discussions
Depends on where you live but I don't think a company has the ability to claim ownership of work you do on you own time and on your own pc. NI's licensing allows you to install LV on a home comp... frankly I'd encourage employees to do that and work on side projects in their spare time. It improves their skills and doesn't cost the company anything. -
[CR] GPower toolsets package
Daklu replied to Steen Schmidt's topic in Code Repository (Uncertified)
You might consider changing the name of your dynamic dispatch toolset to avoid confusion with LVOOP dynamic dispatching. -
A word that should be used more commonly by LV users/tech writers
Daklu replied to Aristos Queue's topic in LAVA Lounge
I didn't know the eagle has a name... -
The LapDog.Messaging framework has been updated to version 2.1. This release should be fully backwards compatible with version 2.0 while introducing a few new features to support unique developer needs. Improvements include: -Two new native message types supporting Double and Variant types. -A new companion library includes I32Array, DoubleArray, StringArray, 2dStringArray, PathArray, BooleanArray, and LVObjectArray messages. -A new type of queue, PrefixQueue, makes it easy to universally assign a prefix to all messages sent on a specific branch. This is useful when the message receiver needs to distinguish between identical messages from different senders. -The package includes a "Fundamentals" example illustrating some of the core concepts of the LD.M framework. (I have not prepared the example for the Example Finder yet, so use VIPM's info window to get to find it.) -VI documentation has been improved. All VIs on the palettes now include documentation. This package works with Labview 2009-2011. Go here to download the latest release and give it a try. -Dave
-
The root of your problem is your scope abstraction layer api is too specific. Your main application code shouldn't be setting specific configuration options. You need to break it down into larger steps as described in the Hardware Abstraction Layer white paper Ian linked to.
-
Best Practices in LabVIEW
Daklu replied to John Lokanis's topic in Application Design & Architecture
To be honest my first thought was, "I hope he doesn't over-specify the 'acceptable' way to write code." My second thought is some of the items you listed do fall under coding guidelines, some might be coding conventions, and some are more about your internal software development process. More thoughts on specific topics posted for the sake of discussion... Style - I define style fairly narrowly as the non-functional aspects of the vi--stuff the compiler doesn't care about. Things like fp/bd layout, using fp control terminals or icons on the bd, whether comments have a green background, etc. Blume's style book goes far beyond basic style. A lot of it is about really about convention, processes, and good code. The book is an excellent starting point and required reading for new LV developers. At the same time, I can't imagine working at a company where all those rules were enforced--or even just the high priority rules. I'd spend more time worrying about checking off the style requirements than the customer's requirements. Happy developers are productive developers. Overly specific style rules = unhappy developer. The whole point of good style is to make it easier for other developers to read and understand your code. As experienced developers, I think it is our responsibility to adapt to reasonable style variations, not enforce one particular set of rules as the "correct" way to write code. There are many style rules commonly accepted as the "right" way to code I have happily chucked out the window, and I think my code is more readable as a result. (The most obvious one is "never route wires behind a structure.") Commenting - Helpful comments are good. I've seen suggestions that every vi should have a comment block. That smells of over-specification. Do we really need to add a comment block to every class accessor method? Good commenting is a learned skill. If a block diagram is insufficiently commented that can be pointed out in a peer review or code review meeting. One thing to be aware of... I know my tendency is to write comments about what the code does, because that's what I'm thinking about during development. In general it is more useful to comment on why the code does what it does. Unit Testing - Targeted unit testing is very useful. Comprehensive unit testing is burdensome. Omar hit the nail on the head with his earlier post, If you're using LVOOP and want to unit test, JKI's VI Tester is your friend. So is dependency injection. So is the book xUnit Test Patterns. Unit testing is not the same as integration testing, but you can use a unit test framework to do some integration testing if you want. Organization of source code on disk and in projects - Traditional LV thought is disk hierarchy and project hierarchy should match. This is another "best practice" I've discarded as unhelpful. During active development I'm constantly rearranging code in my project. I don't want to have to move them disk every time as well. I use lvlibs to define each major component in my application, with each component consisting of several classes. On disk I'll have a directory for each lvlib and a subdirectory for each class. This lets me easily grab an entire component and copy it somewhere else if I want to. I don't partition them any further on disk, though I usually do in the project explorer. Occasionally I'll have to move stuff around on disk, but not too frequently. I saw a post from AQ recently where he indicated he uses an even flatter disk structure than that. In his main project directory he'll have a subdirectory for each class. That's it. When the project is near completion he reorganizes the project on disk to reflect the final design. I may give that a go. Code reuse - If you have reusable code, deploy it to your developers using vipm. Don't link to the source code. Personally I don't worry about implementing reusable code on the vi level. It's usually not worth the effort for me. I focus on reusable components. I've mentioned this several times before, but I prefer to let my reuse code evolve into existence rather than trying to design it up front. Trying to support poorly designed reusable code is worse than not having reusable code, and the initial design is never right. using required inputs on subvis where appropriate instead of leaving as recommended - Yeah, but the question is where is it appropriate? Usually I make it required if the default value is not a valid input--like if I'm creating object A that requires a pre-configured object B. The CreateClassA method will have a required ClassB terminal because a default ClassB object is non-functional. Ultimately it's a decision for the api designer. I have a hard time imagining there is a universally acceptable rule that should go on a style checklist. removing the default from a case structure - Depends on what's wired into the case selector. Often I will remove the default case if an enum is connected. On the other hand, if I'm casing out on a string the default case is where I post debug messages telling me about an unhandled string. One thing I try to avoid is putting important functional code in the default case.