Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-
 Like so many things in programming, the word interface has multiple meanings. Here are the rough definitions I use: interface (little "i") - A general term to indicate the set of inputs and outputs a component exposes to the outside world. Most of the time in LV discussions this is the kind of interface being referred to. Interface (big "I") - A language construct that helps work around some of the limitations of single inheritance languages. These must be natively supported by the language. (Labview doesn't support them, so unless you've been poking around with the Interface framework I posted several years ago it's unlikely you'd unknowingly use them.) Most of the time when you encounter Interfaces in programming literature this is what they're talking about. For an example of what Interfaces can do, suppose I have two unrelated classes, Baby and CellPhone, both of which have a Sleep method. I have an application where I want to call Baby.Sleep or CellPhone.Sleep without knowing whether the runtime object is a Baby or a CellPhone. So I define an ISleepable interface and give it a Sleep method. I also change the source code of the two classes so they properly implement the ISleepable interface. Since both classes implement a common Interface, I can cast the objects into an Interface and treat them as though they both inherit from ISleepable, even though they have unrelated class hierarchies. IMO the ability to treat an arbitrary set of objects as though they all inherit from a single parent class, even though they are not related by inheritance, is the defining feature of an Interface. If you can't do it, it's not an Interface. (No disrespect to Paul or Mike intended, but imo what they are doing is using a class to formalize an interface, not create an Interface construct.) ------------ Typically abstract classes cannot be instantiated. Attempting to do so will result in a compiler error. In Labview there's no way to prevent someone from instantiating a class, so they don't exist in same sense as they do in text languages. I agree with Paul on what it means for a Labview class to be abstract--it's a regular class that is not intended to be instantiated at runtime. How you communicate that to other developers is up to you.
Like so many things in programming, the word interface has multiple meanings. Here are the rough definitions I use: interface (little "i") - A general term to indicate the set of inputs and outputs a component exposes to the outside world. Most of the time in LV discussions this is the kind of interface being referred to. Interface (big "I") - A language construct that helps work around some of the limitations of single inheritance languages. These must be natively supported by the language. (Labview doesn't support them, so unless you've been poking around with the Interface framework I posted several years ago it's unlikely you'd unknowingly use them.) Most of the time when you encounter Interfaces in programming literature this is what they're talking about. For an example of what Interfaces can do, suppose I have two unrelated classes, Baby and CellPhone, both of which have a Sleep method. I have an application where I want to call Baby.Sleep or CellPhone.Sleep without knowing whether the runtime object is a Baby or a CellPhone. So I define an ISleepable interface and give it a Sleep method. I also change the source code of the two classes so they properly implement the ISleepable interface. Since both classes implement a common Interface, I can cast the objects into an Interface and treat them as though they both inherit from ISleepable, even though they have unrelated class hierarchies. IMO the ability to treat an arbitrary set of objects as though they all inherit from a single parent class, even though they are not related by inheritance, is the defining feature of an Interface. If you can't do it, it's not an Interface. (No disrespect to Paul or Mike intended, but imo what they are doing is using a class to formalize an interface, not create an Interface construct.) ------------ Typically abstract classes cannot be instantiated. Attempting to do so will result in a compiler error. In Labview there's no way to prevent someone from instantiating a class, so they don't exist in same sense as they do in text languages. I agree with Paul on what it means for a Labview class to be abstract--it's a regular class that is not intended to be instantiated at runtime. How you communicate that to other developers is up to you. -
Let me start by saying my development practices have changed a lot in the 1.5 years since I started this thread. I still use slave loops (although I don't call them that any more) and my apps are still based on hierarchical messaging, but I don't put nearly as much effort into enforcing type safety. I can easily add type safety if I think I need it (like if I'm exposing a public api to other developers or building an app allowing plugins) but most of the time it's just extra work that doesn't provide me with any benefit. Yeah, it probably would be safer. If you want to spend the time wrapping all the master messages in methods you certainly can--I won't tell you you're wrong for doing so. However, there are significant consequences of doing that. Having the slave loop call methods defined by the master loop makes the slave loop statically dependent on the master loop. Since the master already depends on the slave you now have a circular dependency in your design. That's usually bad. Managing dependencies is the single most important thing I need to do to keep my apps sustainable. Unfortunately it's rarely discussed. Probably because it's not as sexy as actors and design patterns. I am curious why you're so interested in safety. Type safety is fine, but it costs development time to implement. Furthermore, the more safety you build into your app the more time it will take you to change the app when requirements change. Too much type safety will soon have you pulling your hair out every time your customer says, "I was thinking it would be cool if we could..." I've never benchmarked examples. I got the runtime efficiency information from AQ and he's in a better position to know than I am.
-
Yep, you will. Whether or not your project is better off by using OOP remains to be seen. Learning good OOP design takes a long time and a lot of trial and error. You will make mistakes. I second what James said. If you put off learning OOP design until you need it, you've waited too long.
-
Command pattern messages (Do.vi) are arguably a more OOPish design, they are more efficient at runtime, and yes, they eliminate the risk of typos in the case structure. Name/Data messages (whether they are LVOOP or not) centralize the message handling code, are more familiar to most LV developers, support better natural decoupling, and (imo) require less work to refactor. Theoretically command pattern messages are "safer." However, in practice I've found typos to be a non-issue. I write my message handlers so the default case handles any unexpected messages (such as from a typo) and generates an "Unhandled Message" notice for me. On rare occasions when I do make a mistake it is quickly discovered. Neither is inherently better than the other. Name/data messages support my workflow and design requirements better. I'll use the command pattern only when I need it. Others swear by command pattern messages.
-
Good news! I found the relevant code and my substates do indeed have entry and exit actions. Bad news! My state is used to manage the UI, so it isn't designed to automatically jump from D to F in a single step like you do above. Each transition (D to B, B to A, A to C, and C to F) requires explicit user input each step of the way. I have some thoughts about potential paths to explore to find a solution to your problem, but they are just vague ideas right now. Separating the message handler classes from the state classes is the first thing that comes to mind... As an aside, suppose you had an action assigned to the D to F transition. When is the right time for that action to execute? In a flat state machine it always executes after leaving the previous state and before entering the next state. Intuitively I would want to execute the transition action after exiting B and before entering C, but I make no claim that is the correct place for it to execute.
-
I'm sorry I missed your session. It was one of the few I had inked into my schedule (as opposed to penciled.) Hierarchical state machines (HSM) are the next step up in state machine models once you get used to flat state machines with entry, do, exit, and transition actions. I've implemented them on a limited scale... not enough to claim it's a good way to do it, but enough that the relatively simple requirements were satisfied. Unfortunately I don't remember the details at the moment nor do I have documentation or examples suitable for sharing with the community. I *think* my substates differed primarily in their do actions. I don't recall needing the exit and entry actions to execute in the same way you do. I'm travelling on Tuesday but I'll try to take another look at that code sometime this week.
-
Yes, you can usually put something like that in checked baggage, but checking bags is a pain both at departure and arrival. Most business travellers in the US don't bother. Plus many airlines charge extra for checking bags.
-
HAL's UML and how to abstract relations
Daklu replied to AlexA's topic in Object-Oriented Programming
Absolutely. It's the primary reason I'm going to NI Week. I noticed that, and that your TestSystem actor maintains an array of Instrument objects. I guess I don't see any point in creating a parent instrument class as a standard development pattern. The point of an Instrument base class is that it allows you to treat any specific instrument class generically. But your Instrument base class doesn't have any methods to control the instruments. You're still going to have to downcast to a specific abstract class in order to call any instrument methods in your application code. The one thing the Instrument base class does allow you to do is store all the instrument objects in a single array. Whether or not the value in that ability is worth the contraints and extra code required for doing it is a subjective evaluation. In my projects it hasn't been worth it. It's much cleaner and easier for me to put separate VisionCamera, PowerSupply, and TemperatureChamber abstract class constants (or arrays of constants if multiple instances of an instrument type are needed) in the TestSystem class. I understand why someone would use a factory class, but I don't understand why that factory would be a parent to the classes it's creating. @Alex Your UML diagram shows a few methods that presumably all instruments will implement: Initialize and Shutdown. This does allow one to iterate through an array of arbitrary instrument objects and initialize them or shut them down. From a practical perspective I haven't found that a particularly compelling reason to impose an inheritance relationship on the classes in my projects. Both operations are sufficiently rare that any advantages gained by the ease of calling either of those two methods is outweighed by the hassle of calling all the other instrument methods. YMMV. Also, for the Initialize method, each specifc object needs to be configured with all the appropriate information prior to calling the Initialize method. If I have to make instrument specific calls to set up each instrument object, is there an advantage to building an array and invoking Instrument.Initialize on the array (which then dynamically dispatches to each instrument's Initialize method) instead of just calling the instrument's Initialize method when setting it up with the correct configuration. Perhaps sometimes*, but in my experience not usually. Again, YMMV. In general, I have found my apis for classes that actually implement functionality (as opposed interface classes that delegate work to other classes) are much more readable when the instrument's Initialize method has connector pane inputs for all the arguments related to initializing the instrument. Obviously each instrument is going to have different kinds of parameters for the Initialize method, which prevents you from creating an Initialize method in the base Instrument class.** The way you have your class hierarchy set up will likely lead you down the path of putting application specific code in your instrument classes, which makes it harder to reuse them somewhere else. Or maybe you'll be tempted to create abstract methods in the base class that are only applicable to some of the child classes. Both options violate OO design principles and if you find yourself doing them it may be worth your while to investigate other solutions. -Dave (*The one time I can think of off the top of my head where having a Initialize method in a single Instrument parent class might be beneficial is if you have lots of different instrument types and need to reinitialize them frequently. For example, on a test sequencer where you want all the instruments to have factory default values at the start of every test.) (**You can overcome this problem to some extent by adding a LVObject constant to the Initialize conpane and labelling it "Configuration," but you have to do run time downcasting to use the specific config object and you lose compile time type checking.) -
Interesting. Seeing as how Sacha Baron Cohen retired the Borat character in 2006 I do wonder who is behind it.
-
HAL's UML and how to abstract relations
Daklu replied to AlexA's topic in Object-Oriented Programming
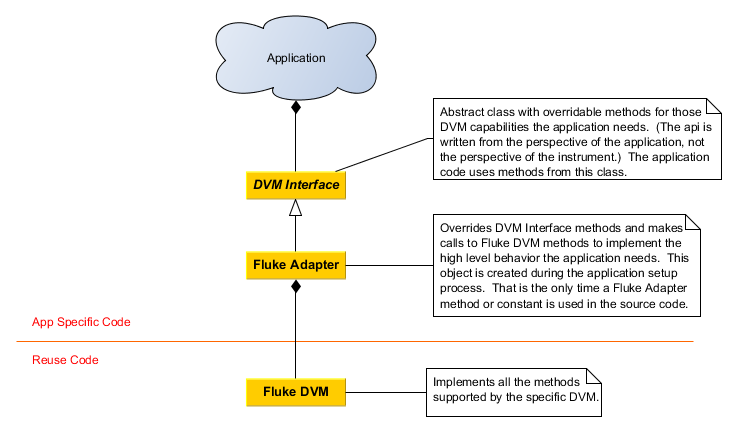
Is there a particular reason you have an instrument base class? It's not really providing much of an advantage for you and inheritance relationships are relatively restrictive and inflexible compared to aggregation. This is how I implement a HAL using aggregation and adapters. (It's similar to what Mikael does, except I eliminate the instrument base class.)
-
HAL's UML and how to abstract relations
Daklu replied to AlexA's topic in Object-Oriented Programming
Actually, anyone who has gone through the process of learning object-oriented design understands exactly what you're going through. Don't get discouraged. Learning all the ins and outs of OOP takes time, and the best way to learn it is to write code and then figure out why it doesn't quite allow you to do all the things you thought it would. It took me at least a year of using LVOOP almost exclusivly before I felt like I was more effecient using it than traditional LV. There is much more information and help available now than there was three years ago so hopefully it will not take you as long. -
LVClasses in LVLibs: how to organize things
Daklu replied to drjdpowell's topic in Object-Oriented Programming
Not quite the same thing, but see this and this. -
Rolls Royce - large corporation Aircraft Engines - highly regulated product I'd be willing to bet spending 8 weeks building a lego engine is the most satisfying thing those four engineers have done in years. It sure beats pushing paperwork and fighting red tape.
-
That's true. If the TCPMessenger loses the heartbeat it can always create an Exit message for the receiving actor.
-
Yes, but you I wouldn't want to use a heartbeat to keep all your my actors alive just in case you I ever decide to use it over a network.
-
I see. I took your statement to mean you can take an arbitrary actor, replace the QueueMessenger with a TCPMessenger, and all of a sudden have an actor suitable for network communication. I think that would be a tough trick to pull off without adding a lot of potentially unnecessary code to every actor.
-
How do you write your components so they terminate in the case of unusual conditions? For example, if a bug in a governing (master) actor exits incorrectly due to a bug, how do the sub (slave) actors know they should exit? Typically my actors will execute an emergency self termination under two conditions: 1. The actor's input queue is dead. This can occur if another actor improperly releases this actor's input queue. Regardless, nobody can send messages to the actor anymore so it shuts down. 2. The actor's output queue is dead. An actor's output queue is how it sends its output messages to its governing actor. In fact, a sub actor's output queue is the same as its governing actor's input queue. If the output queue is dead, then the actor can no longer send messages up the chain of command and it shuts down. This scheme works remarkably well for queues, but I don't think it would be suitable for other transports like TCP. What logic do you put in place to make sure an actor will shut down appropriately if the messaging system fails regardless of which transport is used?
-
I used network streams for the first time a couple months ago and didn't realize they did not accept classes. I'd have to play around with different implementations to see what worked. If the app is simple my first instinct is to flatten the message object to a string and send that. On the receiving end you could (I think) unflatten it to a Message object, read the message name, and then downcast it to the correct message class. That does present problems if the app isn't deployed to all targets at once. Close. You are correct the MessageQueue class is not intended to be subclassed for different transport mechanisms. The methods it exposes are specific to dealing with queues, not message transports in general. If you wanted to create a class that completely abstracts whether the transport is a queue or a stream, I'd start by creating a MessageStream class that closely mimics all the functionality of the MessageStream functions. Then I'd create a high level abstract MessageTransfer class with simplified Send and Receive methods. Finally, I'd create QueueTransfer and StreamTransfer classes that override the MessageTransfer methods. These overriding methods would in turn call the MessageQueue and MessageStream objects contained within the QueueTransfer and StreamTransfer objects. (The MessageQueue and MessageStream objects are passed in as part of the Transfer object's Create method.) I'm thinking of something like this... Would this work? I have no idea. I'd have to implement it to find out. Personally I'm not convinced creating a generalized MessageTransfer class is worth the effort. You don't want to read from multiple transports in the same loop anyway (except perhaps in very specific situations.) For example, suppose I have loop A that needs to be aware of messages from loop B (via queue) AND from loop C on another target (via streams,) rather than trying to route messages directly from loop C to loop A I'd create loop D, whose job it is to get messages from the stream and put them on loop A's queue. This also gives me someplace to put all the network connection management code if I need that without cluttering up the loop A with lots of extra stuff. My impression is that it applied to all RT targets. The person was working specifically with an sbRIO device though, and for all I know it was limited to that hardware model. Again, this is an unverified rumor I heard through the grapevine. I don't want to cause NI unnecessary troubles, but with object-based messaging gaining in popularity I wanted people to be aware of the possiblity of there being an issue so they can test for it. Any chance you could write some simple test code that creates and releases thousands of random number objects per second? I'd be a bit surprised that revealed the leak but it's the first step I'd take.
-
My first trip to NI Week wouldn't be complete without attending the Lava BBQ. I'm in.
-
I haven't used LapDog for communicating with RT targets. For several years I've had it in mind to wrap the network stream functions in a class similar to how the queues are wrapped up, but I haven't actually done it yet. Mostly because I don't get to do many cRIO apps so I haven't had enough time to explore good implementations. However, I have heard unconfirmed reports from a CLA I know and trust that there is a small memory leak in RT targets when using objects. The issue has to do with LV not releasing all the memory when an object was destroyed. It wouldn't be a problem for a system with objects that are supposed to persist through the application's execution time, but it could be an issue if objects are frequently created and released (like with an object-based messaging system.) Like I said, this is an unconfirmed report. The person I heard it from got the information from someone at NI who should be in a position to know, but AQ hasn't heard anything about it. (Or at least he hasn't admitted to it. ) Maybe it's a miscommunication. Once I get the name of the NI contact I'll let AQ know who it is and hopefully we'll get it cleared up. In the meantime, I'm choosing not to use LapDog on RT targets. --- Edit --- I added variant messages to support James' request for values with units attached to them and to give users the ability to use variants if they want to. In general creating custom message classes for different data types will give you better performance by skipping the variant conversion.
-
I only came to this thread and read it after having trouble posting on NI's site, so I haven't fully absorbed all the information here. But yes, using strings as an intermediate representation made the most sense to me for the same reasons you mentioned--they can all do it and we have to convert to a string anyway. The format itself may be locale agnostic, but the data within the format is not. Culture is to convert certain kinds of data into the expected format. It is only used with human readable formats. For example, suppose I want to serialize a class containing a date to an .ini file. The .ini file will contain, Date=07/01/12[/CODE] What date is that referring to? July 1, 2012? Jan 7, 2012? Jan 12, 2007? We don't know unless we look at the serializer's documentation to see how it formats dates. The harder question is what date format [i]should[/i] the serializer use? Answer: Because the format is intended to be read by humans it should use the format the user wants it to use. (Calling Serialize.Flatten does not "save" the data. It just converts it into a string. What you do with the string is up to you.) There are several ways one can go about converting a class to a string, each with advantages and disadvantages. AQ identified two of them in the document. What I call "batch" processing converts all the class data into an intermediate format, then converts the intermediate format into the serialized format. For most users this will be sufficient. "Inline" (perhaps "pipelined" would have been a better word) processing converts each data element to the intermediate format then immediately into the serialized format. This will be faster and use less memory when serializing large data sets. There are other strategies end users could potentially need. Maybe I've got a large array that needs to be serialized and I want to take advantage of multi-core parallelism. Or maybe I've got a *huge* data set and a cluster of computers ready to help me serialize the data. (Ok, that's not a common scenario but roll with me...) The Strategy interface is where I implement the code defining the overall serialization process. In the existing design the Serializer class implements both the format and the strategy. I'd have to create a new subclass for each format/strategy combination. BinaryBatch, BinaryParallel, XmlBatch, XmlParallel, etc. That's (potentially) n*m subclasses. Separating the Strategy and Format into different classes only requires n+m subclasses. It also makes it easier to reuse and share formats and strategies. I only know the XML model from a high level and I know less about JSON, so much of this is speculation. XML and JSON are typically used to describe an entire hierarchical data structure. As AQ mentioned, this presents difficulties if you want to pipeline the serialization or deserialization of a large data set. You need the enitre document before you can understand how any single element fits into the structure. I pulled this JSON example from wikipedia. [CODE] { "firstName": "John", "lastName" : "Smith", "age" : 25, "address" : { "streetAddress": "21 2nd Street", "city" : "New York", "state" : "NY", "postalCode" : "10021" }, "phoneNumber": [ { "type" : "home", "number": "212 555-1234" }, { "type" : "fax", "number": "646 555-4567" } ] } [/CODE] Suppose a class serialized itself to the above JSON code. Now take an arbitrary data string, [i]"number" : "646 555-4564". [/i]As far as the software knows it's just a string like any other string. It doesn't have any meaning. Scenario 1: For whatever reason you need to change the way the phone number is represented on disk. Maybe instead of "xxx xxx-xxxx" you need to format it like "xxx.xxx.xxxx." The formatter needs to identify this particular string as a phone number so it can apply the formatting changes. How does it do that? Scenario 2: Instead of saving the data in JSON format, you want to save it in an .ini file. You can't write "number=646 555-4564" because each phone number in the list will have the same key. The serializer needs to know the context of the number in order to give it an appropriate key and/or put it in the correct section. Unfortunately the data string doesn't provide any context information. What do we do? SIF (and AQ's intermediate representation) describe each data element and include contextual information about the element. Instead of just receiving "number : xxx xxx-xxx," SIF could describe the data using a structure something like this: Name - "JohnSmith.PhoneNumbers[1].number" Value - "646 555-4564" Type - "Phone Number" more...? In this example the name provides the context describing where the information fits in the class' private data. I think AQ's representation only had Name and Value, but if users can extend the structure and add type (or other) information we'll have an additional level of flexibility that otherwise would not be available.
-
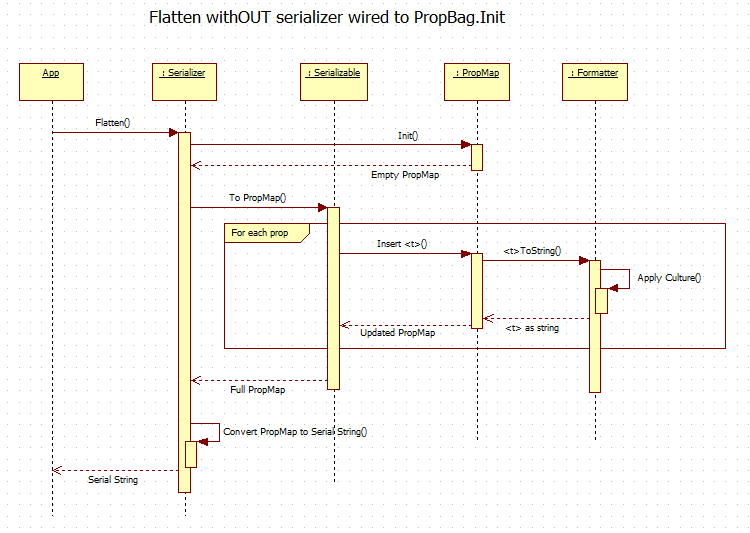
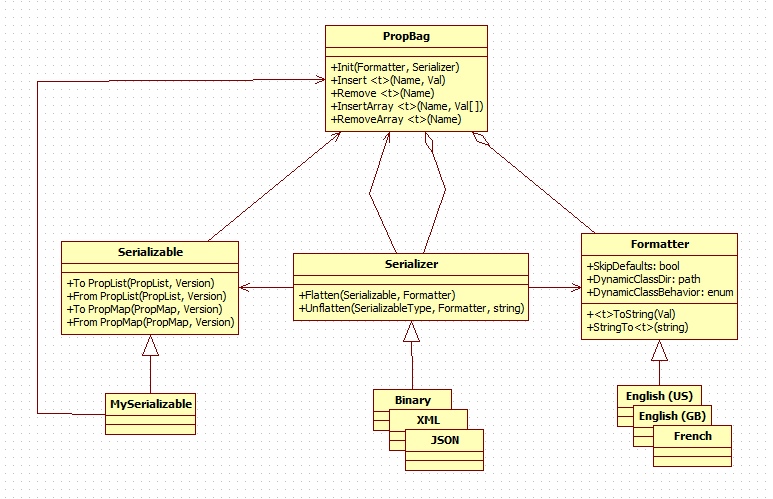
(I tried posting over on NI's site, but I was unable to upload images and I got tired of fighting with it.) I've been studying the document and building mock-ups trying to understand how the pieces interact. I have some concerns over the amount of flexibility it provides and the division of responsibilities, but I'm not sure I'm interpreting the design correctly. I created a class diagram and two sequence diagrams (for "flatten with serializer" and "flatten without serializer") based on what I've been able to extract from the document. Am I on the right track with these? The document describes class relationships with two sets of circular dependencies. Circular dependencies aren't inherently bad, but when they exist I do sit up and take notice simply because they can be so troublesome. 1: Serializer <-> PropBag 2: Serializer -> Serializable -> PropBag -> Serializer (For simplicity on the diagram I combined the two Property Bag classes into a single class, even though they do not share a common parent. The following diagrams refer to "PropMap" (PropBag with names) and "PropList" (PropBag without names) because it requires less thinking on my part when the name of the abstract data type is part of the class name.) This shows my interpretation of the object interactions when a serializer implements Flatten without connecting to PropertyBag.Initialize. This seems to be a fairly straightforward batch-style process. However, how does the serializer get the properties from the PropertyMap so it can apply the metaformatting? The remove methods require a key (ie. name) to retrieve the value, and the serializer doesn't know them. Even if the serializer does know all the property names, my gut says property names and values aren't sufficient. An xml serializer might need to include type information or other metadata along with the name and value. I don't see how this sequence supports that... unless the expectation is users will write XmlEnglish(US), XmlEnglish(GB), etc. classes. I realized the diagram is wrong while I was typing this up. Specifically, the diagram shows Formatter calling Serializer.<type>ToString. That should be named something like "SerializeProperty" and accept a string. (The document doesn't mention this method by name but alludes to its existence.) The diagram also shows the serialized property being returned back through the call chain to the serializable object. Page 11 is ambiguous about which class actually maintains the serial string while it's being built. I don't think that's an important detail at the moment. My concern is in the very different ways a specific serializer is implemented. If a serializer enables in-line serialization by not connecting the PropertyBag.Initialize Serializer terminal, then it will need to override SerializeProperty. If the PropBag.Initi Serializer terminal is connected, then SerializeProperty never gets called and devs don't need to override it. I think this is more confusing than it needs to be. ------ I'm thrilled Stephen is spending brain cycles thinking about this problem. My overall impression is the library is trying to compress too much functionality into too few classes in an attempt to make it "easy" for users and the classes end up relatively tightly coupled. One clue comes from the description of the Serializer class on page 4: "Serializer – A class that defines a particular file format and manages transforming Serializable objects to and from that format." Having "and" in the description is often an indicator the class should be split. Perhaps a SerialFormat class would help? Another indicator is how a serializer's Flatten/Unflatten behavior changes based on the inputs to PropBag.Initialize. Serialization is the kind of thing that could need any number of custom behaviors. Instead of restricting us to the two designed behaviors, why not implement a SerializationStrategy interface that allows users to easily define their own custom behaviors? This is a class diagram I put together to illustrate the kind of flexibility I'd like to see. I haven't put anywhere near enough thought into this to claim it is a good design or meets all the use cases Stephen identified. I can already see errors in it, so don't take it too literally. It's just a way to show how the different responsibilities are divided up among the classes in the library. I don't think it's that much different from Stephen's design. The main differences are: - Serializer is purely an api class. All functionality is delegated to implementation classes. Serialization behavior is changed by configuring the implementation classes and injecting them into the Serializer object instead of using option switches. - The serialization process is implemented by Strategy subclasses, not by Serializer subclasses. The hope is this will decouple the serialized format from the computational process of obtaining the serialized string. They have orthogonal considerations and constraints. Separating them provides more flexibility. - The intermediate format defined by the PropBag classes is wrapped up in a single "Serialization Intermediate Format," or "SIF." This class can be replaced with child classes if the default SIF doesn't meet a user's needs. (Allowing users to serialize to a custom XML schema seems particularly tricky.) If you ask me to explain the details of how something works I'll respond by waving my hands and mumbling incoherently. The primary idea is to allow more flexibility in mixing and matching different capabilities to get the exact behavior I need.
-
So I'm finally going to NI Week this year. I didn't know the fun wrapped up mid-day Thursday, so my return flight isn't until Friday evening. Hanging out in my hotel room for a day is boring, not to mention a wasted opportunity. I'd much rather talk programming with other developers. Is anyone else going to be around on the Friday after NI Week? I'm thinking we can stake a claim somewhere and spend the day chewing on whatever topics come up.
-
(See sig.) My comments were based on my experiences in the late 90's and early 00's developing custom controls in VB6 and C#. It wasn't perfect, but it wasn't bad either. Labview's control customization features feel anemic in comparison. I didn't mean to imply it would be an easy task. In fact, I expect it would be fairly significant undertaking and while I won't claim it would be simple to implement, I believe it could be done without forcing developers to directly interact with the c++ api. When creating custom controls there are typically two areas we are interested in customizing: appearance and behavior. I'll start with the appearance since it's a little easier to visualize. We can address this using composition. Let's take your typical vertical scrollbar. It has four visual elements: the up button, down button, scroll handle, and background. The scrollbar as a whole is a composition of those four elements interacting in a specific way. For the purposes of this discussion I'll use the word "frame" to refer to an independent visual element. Each of the four elements is a frame. The scrollbar as a whole is also a frame composed of the four subframes. Suppose I want to change the appearance of scrollbar in a Listbox. Currently I have to create a customized a listbox control. If I want to keep that same scrollbar appearance in non-listbox controls I have to create customized versions of each one. Depending on the level of customization, that could turn into a huge amount of work. Furthermore, current controls don't provide the same level of scrollbar customization. I can change the width or position of the scrollbar in a listbox. I cannot do that with a legend scrollbar. The inconsistency is understandable, but it makes LV more difficult to work with than it should be. Now let's assume each frame has some behavior associated with it. Since these are UI elements the behaviors are implemented in the form of event handlers. A frame and it's behaviors combine to create a control--a front panel element we can drag and drop onto our vis. Changing a control's built-in behavior is addressed using dependency injection. Define an interface of those event handlers the control handles internally. Create a class implementing the default behavior, with one method for each event handler. Let devs create a child class and override the event handling methods for the events whose behavior they want to change. Provide a way to bind the dev's event handler class to the control. (i.e. Perhaps a "Set EventHandler" property node for block diagrams and right click option for front panels.) So my question is, why are scrollbars (and all control sub elements) tied so tightly to the controls they're associated with? Why aren't they an independent control with their own events? Why can't I customize a listbox, select the vertical scrollbar, and open another control customization panel to customize it? (And then in turn choose to customize one of the four frames of the scrollbar?) LV developers are already familiar with the idea of composition via OOP and clusters. This wouldn't be an intellectual stretch. This might even be possible using xcontrols--I've never tried composing an xcontrol from other xcontrols or delegating the event handlers to a public interface class. I know AQ has talked about integrating xcontrols and LV classes in the past, but I don't remember if his use case addressed these specific issues. If it is possible, why isn't NI doing it? If it isn't possible, it should be. Controls could still behave largely as they do today with the addition of accessor methods for the subcontrols. Developers only need to dig into the details if the default controls don't meet their needs. We'd have a lot more flexibility if the controls were exposed to us as hierarchy of controls instead of as an opaque, shrink-wrapped package. One potential difficulty I can see is in how Labview blurs the line between edit-time and run-time. That still throws me for a loop now and then. (Such as the unexpected edit time behavior of the chart control.) If I wire my custom event handler to a control, should that custom behavior persist when the vi is not executing? Personally I wouldn't expect it to, but I don't speak for NI's customer base. (I'd also prefer a dev environment that better separates the "tool" aspect of LV from the "programming" aspect of LV. Maybe "GView" to emphasize it's programming language orientation.) I'm sure there are numerous other difficulties I haven't thought of. I'm also sure there are valid historical reasons why LV controls didn't evolve in this way. I don't have a problem with that. I do hope that something like this is at least on NI's radar and they have concrete plans to move in that direction. I've grown to really enjoy dataflow programming; it suits my thought processes well. At the same time, Labview seems to continuously be 15 years behind other programming languages and as I grow as a programmer it seems like Labview is struggling to keep up.
-
Incidentally, "this statement is false" is known as the Liar Paradox and many people much smarter than me have proposed solutions to it.