Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-

How many "User Events" can LabVIEW queued?
Daklu replied to MViControl's topic in Application Design & Architecture
It'll take me some time to absorb this post, but I do have a few quick comments. "You" was intended as a general term to indicate the QSM user, not you--Jon--specifically. I did a very poor job of making that clear. This is one of the main points where I've not quite been understanding where you've been coming from. The way I've seen the QSM used and my main point of contention with it is using it as a top level vi within a module and expecting it to provide some sort of structure to the module. It sounds like you've got some other architecture in mind already and are just using the QSM as a way to implement the architecture? -
"Authentic cowboy boots?" What makes a cowboy boot authentic? Has it been pre-worn by an authentic cowboy? Does it come complete with cow dung stains?
-
Illegal default values for DVR classes
Daklu replied to MikaelH's topic in Object-Oriented Programming
Suppose you had class S with an I32 and an instance of itself. What would happen when you dropped an object constant on the block diagram? Memory would be allocated for the I32 and for another instance S, which has its own I32 and another instance of S, which has its own I32 and another instance of S, etc. You'll fill all the available memory with instances of S. Using LVObject (or some other parent class) breaks the recursion in the class definition. Not true. You can implement the composition pattern. It is perfectly legal for an object to contain instances of itself at runtime. You just can't define a class with a self-reference. Use LVObject as a container and do the downcasting as part of the accessor methods. I'd have to look more closely at the rest of your post before answering the other questions. No time right now... -
Illegal default values for DVR classes
Daklu replied to MikaelH's topic in Object-Oriented Programming
That's what I do as well. It works very well. -
How many "User Events" can LabVIEW queued?
Daklu replied to MViControl's topic in Application Design & Architecture
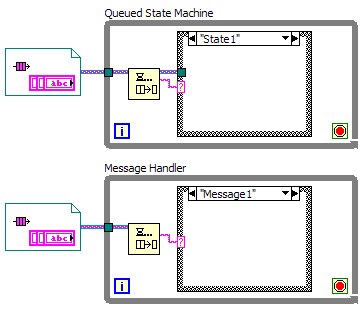
I suppose "great" depends on what you're trying to accomplish and what kind of architecture your application has. The solution to that specific problem depends on the particulars. Who (meaning which part of the application) knows how to validate the entry? Who owns the help content? Who is responsible for the way the content is displayed? etc. If the answer to all these questions is "the dialog box," then a QSM will work, but hopefully you'll be aware of the limitations of the decision and can communicate those to your customer. If you haven't even asked those questions then I'll argue you haven't thought out your application's architecture well enough. Your question appears to assume I use single vis for my dialog boxes. I don't do that. My dialog boxes are classes. Why? Classes allow me to decouple the app's user interface from its functionality. Sometimes dialog boxes need to be shown in response to a user action, such as pushing a button. Sometimes they need to be shown because of something happening in the application, such as getting invalid measurement data. Using QSM dialog boxes scatters user interface code all over the functional code. Consider this: Suppose you've created an automated test app that has all sorts of dialogs for status updates, warnings, prompts for locations to save files, etc. It's just what the customer asked for. A month later he comes back and says, "You know what? We need an option that allows advanced users to disable the status update and warning dialog boxes." How do you apply this change? Probably by creating a UserType {Beginner | Advanced} enum and adding it to a supercluster of data that is carried through your app. Dialog boxes are shown or not shown during execution based on the enum. Kind of a pain, but not insurmountable. Probably the kind of change you expect to do as a developer. Then he comes back and says, "We need an option to run in unattended mode. Status updates and warnings should be saved to a log file. In this mode data will be saved on the network share." Okay, now we have UserType {Beginner | Advanced | Unattended}, probably add a LogFileDirectory to the supercluster, and we change around the functional code to deal with the new requirements. Unfortunately the requests keep coming... "Sometimes the network is down. The data needs to be saved locally if that happens." "We want the option to save data in text format or as an .xls report." "One of our operators can't see very well. Can you create a 'High Contrast' option?" Q: What do all these requests have in common? A: None of them affect the test execution logic in any way, yet will likely require changes to your test execution code in order to implement. I have a hard time considering an implementation "great" if it includes these limitations. I have no idea what that means, but it sounds disgusting. So if it's a sequencer, what is it you're sequencing? I've said it before, but I think the terminology is extremely important. Message handlers, sequencers, and state machines all have very different purposes and are not interchangable. Failing to distinguish between them creates a lot of confusion about what role that bit of code is supposed to fulfill. In my opinion this diagram illustrates the key difference between a QSM and message handler. Not extending the message queue past the dequeue prim makes all the difference in the world. A message handler can't send messages to itself because there's no reason for it to do so. If I end up in a situation where the message handler needs to send a message to itself then there's a flaw in my design that needs to be addressed. Calling something a "first-class citizen" in a language usually means you can pass it as a parameter or assign it to a variable. So, while technically you are correct (while loops and case structures aren't first class citizens either) I'm pretty sure that's not what you meant. I'm open (but skeptical) to the idea of using a QSM as a fundamental building block, as long as it is very restricted in the scope of what it is asked to do. What I have seen most often is people attempting to use the QSM as an application architecture, a task it is entirely unsuitable for. But in order to convince me QSMs make good building blocks you'd need to start by answering the question I asked Jon earlier--How do you decide if a piece of functionality should be a case or a sub vi? More generally, how do you go from a flow chart (like the one from Ben I posted above) to a QSM implementation? I see these claims being made all the time about QSMs. Are they flexible? You bet! Jello is flexible too--that doesn't make it a good building material. Good building materials offer the right balance between flexibility and structure. QSMs are too flexible. There's no inherent structure helping to guide design decisions. Without structure it can't be scalable. You won't get far building a Jello house before it collapses under its own weight.
-
Very cool. Haven't read it yet, but you get kudos just for taking the time to write a 24 page document for the rest of us. -------------- Okay, I've read through it a couple times and really like it. I'm going to forward it on to our other developers and suggest they read it. To my eyes it looks sound. Of course, maybe that's just because I agree with all the important points you brought up. Unfortunately, as you pointed out that solution does appear to be fairly heavily reliant on the DSC module. Without the free events the DSC module provides everything becomes more complicated. (I think... I have no experience with shared variables or the DSC module.) Nevertheless, the principles you describe can be applied without shared variables. Good job! I ended up almost in the same place as you did with my recent state machine soapbox. The principles are the same (using references/shared variables to access the SM inputs and unique classes for each state) but my implementation is a bit different. I think there might be one key difference between our implementations, but I want to take some time to write up my idea correctly. I'll try to post it soon. I despise action engines but accept FGs as a valid way to share data. I don't quite follow your critique of AE's though. On page 20 you said, "We can implement this 'action engine' simultaneously in other applications, and each of these can change the state." AE's are still restricted in scope to the specific application aren't they? If you're running from source code it will execute in that project's context. If you've compiled an executable the OS executes it in it's own app space. Am I missing something?
-
Understanding a sub vi's error handling at a glance?
Daklu replied to Daklu's topic in LabVIEW General
Taken straight out of the "nobody cares but me but I'll bore y'all with it anyway" book, I tried asbo's suggestion of using the '?!' symbol to indicate error handling. I found that they took up too much room and made my icons, well... ugly. The idea is a good one though, so I just recycled some adornments I used in the past for specifying accessors and had discarded as unnecessary. A green flag over the error in terminal tells me wiring this terminal is optional. In other words, having an error on the wire doesn't affect the vi's execution. If the flag is missing, then I know something in the sub vi will behave differently when an error is input. A green flag over the error out terminal tells me wiring this terminal is optional. In other words, the error out terminal is simply a copy of the error in terminal--this sub vi will not generate its own errors. If the flag is missing then the sub vi may raise an error. I also have red flags if there's something really unusual about the way a sub vi handles errors. I've only used it on the error out terminal for a couple vis that clear the error from the error in terminal and always send 'no error' on the output terminal. Red and green are about the worst colors I could pick for color blind people (sorry asbo) but they are the most distinctive colors on the palette. Based on the combination of flags on a sub vi I know at a glance when I can skip connecting the error terminals. It also the unexpected benefit that I am becoming more willing to not wrap every sub vi in an error structure.
-
Maybe they will tape the 'State Machine vs State Machine' session. (nudge nudge)
-
How many "User Events" can LabVIEW queued?
Daklu replied to MViControl's topic in Application Design & Architecture
Quick update: I am currently working on an app in which I ripped out the active object implementation (it was getting too cumbersome) and replaced it with a more "pure" state machine idea I have, based in part on the GOF's state pattern. My initial impression is that it requires far fewer states than the equivalent QSM and is much easier to understand and extend. I'll see if I can get something posted in the next couple days and the rest of you can take a gander. Oh man I wish I could see this. (Yeah, I'd keep my mouth shut and just listen. ) Anyone know if Norm has made his state machine model public, or is he using NI's standard template? -
Event registration is destroyed too fast
Daklu replied to Ton Plomp's topic in Application Design & Architecture
I hope yours is easier to understand. Naw... I use a second, external monitor set up to the right of my laptop and do all my main dev work on that. I don't know if it's Labview or Windows that repositions the windows, but I see that too when I'm working without the external monitor. [Edit - I realized I also see this when I'm working on stuff at home, where my second monitor is to the left of my primary monitor. It's kind of annoying, but not nearly as annoying as having the VIs open up entirely off screen.] -
Funny you should mention that. Back in Windows 98 days I replaced the Windows warning dong with that sound clip. It was pretty funny to see people's reactions when my computer talked to me. After a while when I got bored I would repeatedly do illegal clicks in rapid succession. It was my own personal remix sample. "I I I I I I I I'm sorry Dave. I'm sorry Dave. I'm sorry Dave. I'm afraid I can't do that."
-
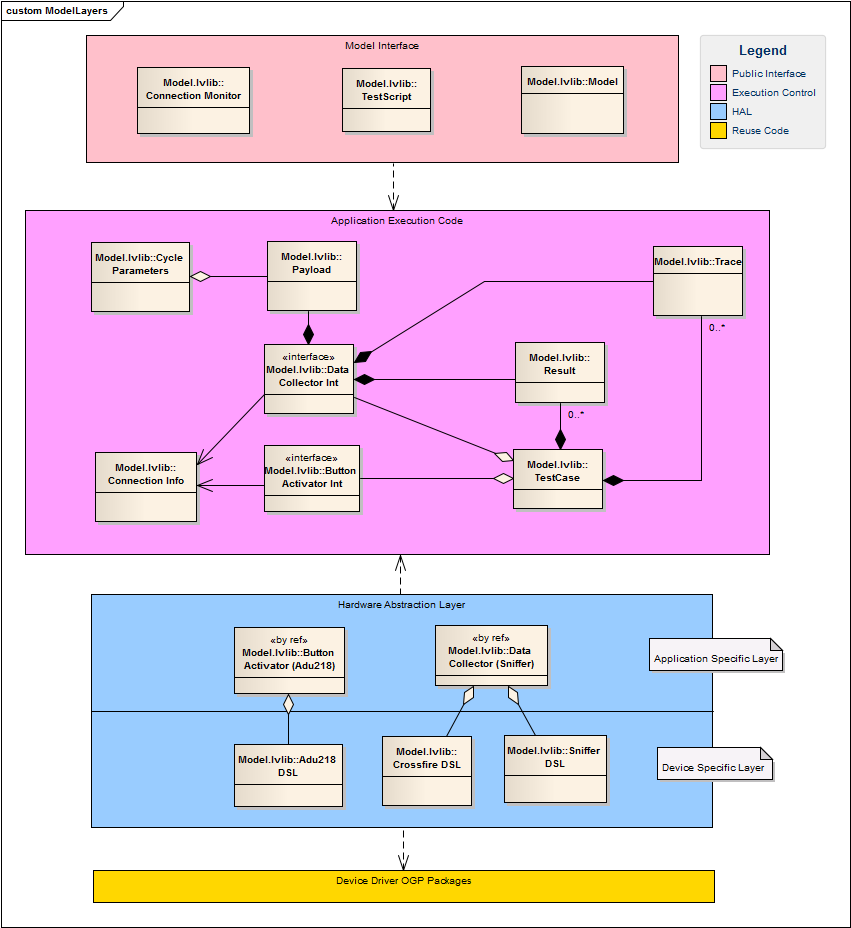
I thought I had replied to this message. I know I typed something up--wonder what happened to it? Maybe I never submitted it... Depending on how you're planning on using your CAN classes in your applications, what you're describing is part of your reuse library, not the HAL. They belong to the Instrument Driver layer on Figure 1 of that document. The HAL is written specifically for each application. It isn't intended to be used across different projects; it's intended to make it easier for you to use different modules from your Instrument Driver layer within a single application. (Or maybe that's just my own narrow view of a HAL.) Here's a class diagram of a project I'm currently working on that illustrates how I implemented a HAL. The yellow layer on the bottom contains the reusable device driver libraries and classes. The purple layer contains the business logic and is completely independent of any specific device drivers. I can work on that code without having the device drivers even installed on the computer. (This was handy since the device drivers hadn't been written.) The blue layer in between them is the HAL. It is responsible for translating high level application requests into low level device specific commands. This diagram doesn't show it very well, so I'll explain the calling hierarchy for one set of application functionality--the Data Collector. (Note: Following Elijah's terminology the DataCollector(Sniffer) class is part of the device specific software plugin (DSSP) layer and the DataCollectorInt class is in the application separation layer (ASL.) I couldn't diagram that very well in my UML tool while keeping my classes in their correct libraries, so I use slightly different terminology. It's essentially the same thing though.) DataCollectorInt is a class that is part of the application execution layer in purple. It has only a few high level abstract methods related to collecting data: Connect, Disconnect, IsConnected, StartCapture, StopCapture, etc. Any method inputs are either native LV types or other objects within this layer. i.e. The Connect method takes a ConnectionInfo object as an input parameter. StopCapture returns a Result object and a Trace object. DataCollector(Sniffer) is a child of DataCollectorInt and implements the abstract methods of its parent. This class is an instrument specific implementation for our Crossfire and Sniffer instruments. If I change the instruments used to collect data I'll derive a new class from DataCollectorInt and implement new device specific code for each of the higher level DataCollectorInt methods. Note that this class uses composition, not inheritance, for its lower level functionality. CrossfireDSL is the device specific layer for one of our instruments. It turns out this class is only a wrapper for the Crossfire class in the device driver layer. I'm not sure there's any immediate advantage to having this class in the design. There could be a long term benefit if we ever replace our current Crossfire instrument with a new version that requires a different Crossfire device driver. I'll be able to derive a new class from CrossfireDSL that uses the new Crossfire device driver and easily plug it in. SnifferDSL is another class in the device specific layer. In this case it made a lot more sense than it did for the Crossfiire. The Sniffer library in the device driver layer contains 7 classes. (The library and classes are a simple wrapper for a third party .Net api.) I was very unfamiliar with the Sniffer api, so I used SnifferDSL to learn the api while at the same time abstracting away all the details (and 7 classes) of the Sniffer api and giving me a few higher level Sniffer control methods. Both CrossfireDSL and SnifferDSL also use composition and delegation instead of inheritance to get the functionality of the classes from the device driver layer. In fact, the only inheritance relationship is between DataCollectorInt and DataCollector(Sniffer). I did this specifically because I wanted to invert the dependency between the application execution layer and the HAL. (In fact, inverting dependencies is one of the few reasons for creating abstract classes in Labview.) If the dependencies don't matter you could skip DataCollectorInt altogether and link directly to DataCollector(Sniffer). That is simpler and more in line with what Elijah's paper describes. ---------------------------- I don't know anything about CAN or the devices you're describing, but I'd be very cautious if you're planning on making BaseCAN part of your reuse library. I tried that and abandoned it. IMO instruments change too much for this kind of hierarchy to work well over the long term. Each instruments' idiosychrocies and slightly different command sets can make it impossible to maintain a coherent generic interface while providing the low level functionality you might need for your next application. These days my reusable instrument drivers are very thin wrappers that exposes each of the instrument's commands. Higher level abstractions are application specific code built on an as-needed basis.
-
If I'm understanding correctly, your top-level vi is an event based producer consumer which sends messages to device-specific vis running in their own threads, each of which is implemented as a QSM-PC. Furthermore, each device may generate its own events the top level vi needs to react to. Is that correct? Assuming that's correct, one option is to insert a Mediator class between the UI class and all the device classes. (After you refactor you device-specific vis into classes. ) Your UI and device classes communicate with the mediator instead of directly with each other. The purpose of the mediator is to sit around waiting for a message. When one arrives it forwards the message to the appropriate destination class. Each class can subscribe or unsubscribe to events/messages by notifying the mediator, which keeps a master subscription list.
-
Event registration is destroyed too fast
Daklu replied to Ton Plomp's topic in Application Design & Architecture
Why do you need to destroy the event refnum right away? "Listener framework" == Observable/Observer? Another approach is to wrap Beta.vi in an active object class, keep the queue internal, and create public vis for each message Beta.vi can process. This has the nice advantage of eliminating the possibility of run-time type conflicts between Alpha.vi and Beta.vi when the message data is unflattened and (imo) makes the code much easier to read and test. It also avoids the problem of somebody accidentally destroying the queue when Alpha_2, Alpha_3, or Alpha_n, is created and linked to Beta.vi, a potential bug which must otherwise be checked for via testing or inspection whenever code changes are made. As always, the additional protection comes at the cost of additional complexity, so it may not make sense in all situations. Still, I prefer frameworks to be object-based as it allows more and better options for building app specific code on it. I've attached my version of an Observable Active Object Template, based on SciWare's active object framework posted several months ago. Take a peek. Maybe there's something in there that is useful for you. (Like how not to do it. ) Feel free to post a critique (assuming you can make any sense of it. ) This is an open invitation to all. ActiveObjectTemplate.zip [Disclaimer: This code drop is ~2 months old, is highly experimental, and is constantly evolving. My goal has been to create a very robust and flexible Observable framework, then go back and simplify it for situations where all the flexibility isn't needed. This code is the start of the simplification process. It's not for the faint of heart--I wrote it and I still get confused by it sometimes. It's not intuitive code either. There is a (woefully inadequate) text document describing the framework, but there currently aren't enough details to guide anyone other than me through the process of building their own Observable Active Object from the template. The whole event managment mechanism can be particularly confusing.] -
Were they allowed to look up the tests to see what is checked? I don't think I could name more than 5 of them from memory.
-
Tip #1 - Attend. (This is where I experience what my 13 yo daughter terms an "epic failure.") Once again I am forced to live vicariously through the rest of you. As always, there's a ton of sessions I would have attended had I been able to go... - Thursday's Keynote with Dr. Michio Kaku. (I love his book Physics of the Impossible.) - LabVIEW Classes: The State of the Art (Stephen) - State Machine versus State Machine (Norm, Nancy, & Justin) - Beyond the Basics: LabVIEW Debugging Techniques - Hardware Abstraction Layers Using LabVIEW Object-Oriented Programming - Achieve Hardware Independence with an Object-Oriented HAL - LabVIEW Object-Oriented Programming Design Patterns for Large Systems (Jim & Tomi) - Reduce Test System Obsolescence and Long-Term Maintenance with the ATML Standard - LabVIEW Design Patterns and SMoReS (Norm) - Development and Deployment of Large LabVIEW Applications
-
For as long as I can remember ROI has meant "Return On Investment." What does it mean in image processing?
-
I love encapsulation. Can't help you with your lost two days, but think about how bad it could have been had you not been able to hide the way you stored the refnum.
-
Two probably useless thoughts... 1. The vi name "AB_Build_Invoke.vi.ProxyCaller" seems rather peculiar. Is the AB_Application.lvclass one of the classes in your application? Maybe it's a dynamically class created by the build engine? 2. You try removing the old top level diagram from the project, creating a new blank top level diagram, and adding in bits of functionality and checking if you can build it.
-
LabVIEWs response time during editing becomes so long
Daklu replied to MikaelH's topic in LabVIEW General
Floating this thread to find out if anyone has been able to narrow down a cause or find a resolution. -
Nearly all marketing is deceptive to some extent. Take your average beer commercial on tv. When was the last time you walked into a bar and had supermodels flock to you because you ordered a Bud Light? Marketing isn't about truth--it's about persuading people to use your product. (Which is why I failed miserably at the one sales job I had. Our service was inferior to the competition and I was too tied to the truth.) When releasing new products marketing needs to get the word out to potential customers. They need to explain what the product is and how it can help the customer achieve their goal. Posting a fake question can be embarrassing if caught, but as you pointed out it's not illegal. I'd even hesitate to call it unethical. It's simply another way to get the message out to the people. (Personally I think a FAQ might have been more appropriate for the target audience.) If they created multiple fake identities and spammed glowing "user" reviews across the forums, then yeah, I'd consider that unethical. QFT.
-
Are you are referring to removing them from Labview's Tools menu? Tools menu add-ons are located in C:\Program Files\National Instruments\LabVIEW x.x\project. Go there and delete the OpenG .llb's and .vi's. Restart Labview and they won't show up on your tools menu anymore. You may have OpenG remnants left over in other directorys, but they shouldn't interfere with anything.
-
passed the CLD and is feeling relieved.
- Show previous comments 2 more
-

Way to go!
-
@jcarmody - I am planning on taking the CLA, mostly because I want to attend the annual summit. It will have to wait until next year when I get another discount coupon from Dev Days.
-

Congrats
-
Jason is right. The best solution is to implement a hardware abstraction layer. His link is broken for me, but here's another example and lengthy explanation you can study to figure out how to do it. If the 715 and 620 have very similar behavior, you can accomplish what you want by (for instance) creating a CEI-715 class driver. Then derive a CEI-620 class from it and override only those operations that are different. I have done this in the past when there is very little difference between instrument models and needed a fast solution. (Warning - This is NOT a solution that lends itself to further evolution or extension. It is a short term patch to a problem that should be addressed using a HAL.)
-
How many "User Events" can LabVIEW queued?
Daklu replied to MViControl's topic in Application Design & Architecture
I'd love to respond to this comment right now. In fact I had a lengthy response (do I have any other kind?) half complete. Alas, I ran out of time and I'll be off the grid for the next week, so I'll have to pick up this thread later.