Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-
Yep, you are correct. I've been pwnd.
-
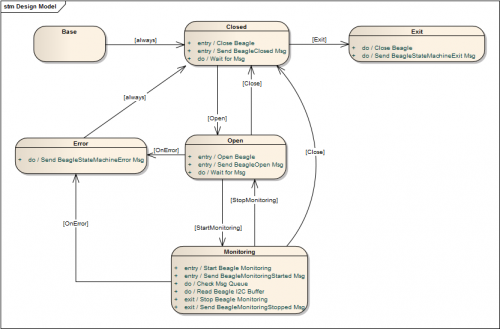
There's been a lot of discussion about state machine patterns the last couple months. Admittedly a good part of it is because I'm so vocal in my dislike for the QSM, but Paul posted an excellent document recently and Justin and Norm pimped the JKI state machine and the TLB state machines respectively at NI Week. Last night I posted a broken example of an object-based state machine. This morning I was feeling guilty about it, so here's a version without the missing libraries. To reiterate from last night's post... ------------------------------ Here's a state machine for a Total Phase Beagle I2C monitor I recently put together using the pattern I described on Paul's other thread and Felix mentioned here. The benefit of having separate sections of code for entry, do/execution, exit, and transition actions can't (IMO) be overstated. It's way easier for me to understand and extend than any flavor of QSM. QSMs are further limited by the restriction of only performing entry actions and must repeatedly exit and reenter the same state. Notes: - Project code is available for LV 2009 or LV 2010. They are otherwise identical. - The project is dependent on the attached vip. Install it using VIPM before opening the project. - The attached vip is currently intended for LapDog developer use. Obviously you are free to use it, but it may not be compatible with future versions. It's an updated version of the library I posted here. (Please pay no mind to the really lame LapDog palette icon. I'm hoping someone comes up with something better.) - I replaced the original Beagle library with a ghost "BeagleApi" library. The vis in the ghost library are there simply for their connector panes--there's nothing in them. - There's not much documentation... I didn't expect to be sharing it yet. - The BeagleStateMachine class is the main public api. It contains the data required for the state machine to operate and shared accessors to that data for the state objects. - Each state is a separate class that derives from BaseState. - TestBeagleStateMachineLibrary is an example of how to use this state machine. Or you can build an Actor class around it. - The state diagram below is also on the bd of BeagleStateMachine:Execute. - If I ever get tempted to use a QSM again for anything non-trivial... please shoot me. The pain isn't worth it. [Edit 9-12] Uploaded a new copy of the 2010 version. The previous version was still attempting to link to a different MessageLibrary. lapdog_lib_message_library-0.7.0.1.vip BeagleStateMachine2009.zip BeagleStateMachine2010.zip

-

packed project libraries
Daklu replied to PaulL's topic in Application Builder, Installers and code distribution
Haven't tried them out yet. Absolutely. All my code is in a library of some sort... either a lvlib or a class. Usually a class inside a library. - Use lvlibs to divvy up your application into modules; it helps keep your code organized. As an added bonus libraries make it a little easier for multiple developers to work on the same project. Much less fighting over who gets to checkout the .lvproj file. - Make liberal use of privately scoped classes inside a lvlib. Typically a module has too much functionality to fit inside a single class. Break the module's functionality into separate classes and make them private. Expose the needed higher level functionality through a few public api classes. Your modules will be much easier to use. - Tight coupling within a module = good. Tight coupling between modules = bad (usually.) - If you persist your classes objects to disk, don't change their namespace... ever. That resets all the internal mutation data. - Give your libraries descriptive names. Letters are cheap... don't be a scrooge. - Always, always, always be aware of your dependencies between modules. Avoid cyclic dependencies. -
Functionally I don't think it's any different, but there's a HUGE difference in readability. I suspect Norm has been spending a lot of time looking at customer's code lately. (Personally I really dislike nested case structures. The logic is too hard to understand at a glance. If I can I'll usually execute all the logic tests, put the results in a boolean array, convert it to a number, and wire that into the case structure. Then I drop a comment explaining the logic. It's much easier for me to check the code that way.) Oh, and without going back and watching the videos again, what was the first word Norm said on all four of the videos?
-
Except it's not a UI issue. The UI is perfectly capable of dispatching multiple Value Change messages in rapid succession. The issue is with your furnace's inability to handle messages as quickly as they can be sent. The solution code belongs where the issue exists, not necessarily where the issue is seen. What happens when someone asks for an automated furnace controller to run arbitrary temp profiles defined by the user? You'll have to reimplement the same code to make sure the user's profile isn't sending messages too quickly. Write it once as part of your furnace's Set Temp method and be done with it. If you need a really quick and easy solution, do what Cat suggested and remove the Increment/Decrement buttons. That's why I asked the question.
-
I agree that those who don't create tools have zero direct use for scripting. I disagree its release is only useful for tool developers. Having scripting released means tool developers get better support. Better support for tools means better tools are developed. Better tools makes for more efficient programmers. That's to everyone's benefit.
-
I gotta ask... Why is sending a message for each increment or decrement undesireable?
-
Not having experimented with xnodes I can't be *with* you, but I would certainly find it helpful if better documentation and examples were available. (As an aside, I thought xnodes were only available in 8.2 and earlier?)
-
True, but unless the person has programmed in LV for a while and understands dataflow programming that will appear to be a perfectly valid question. Or worse, they will think the answer to your question is "variables."
-
Question on AQ's ancient linked list implementation
Daklu replied to Daklu's topic in Object-Oriented Programming
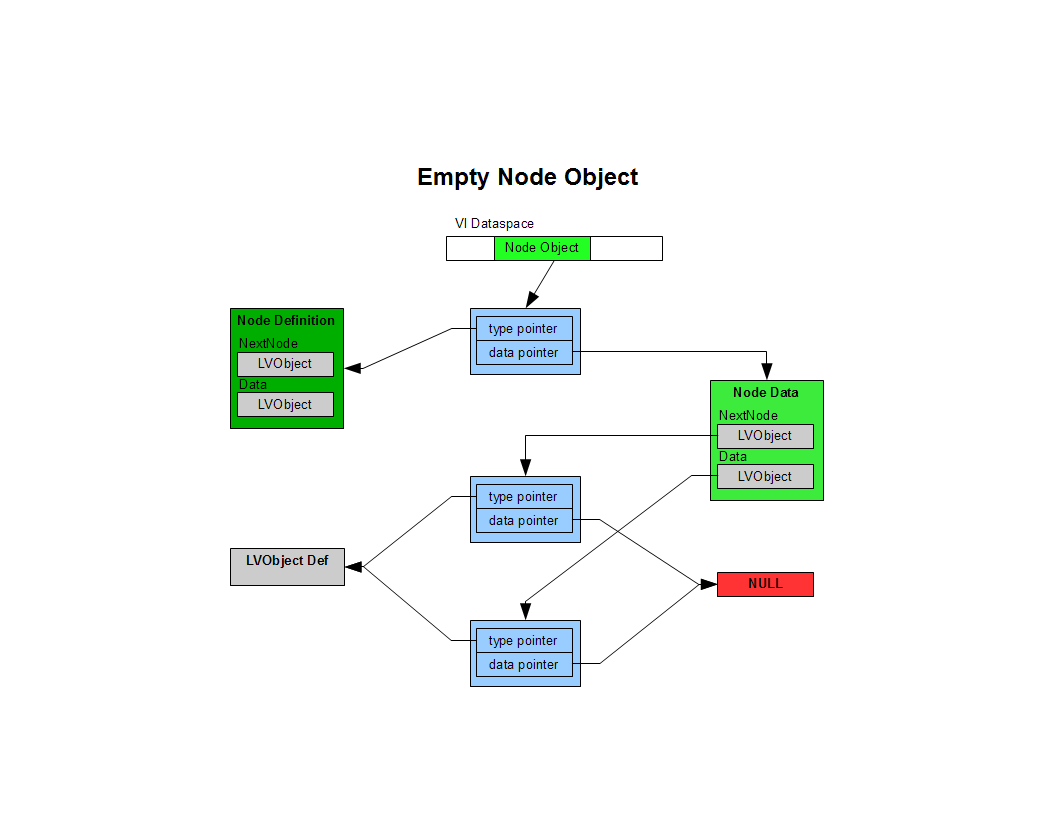
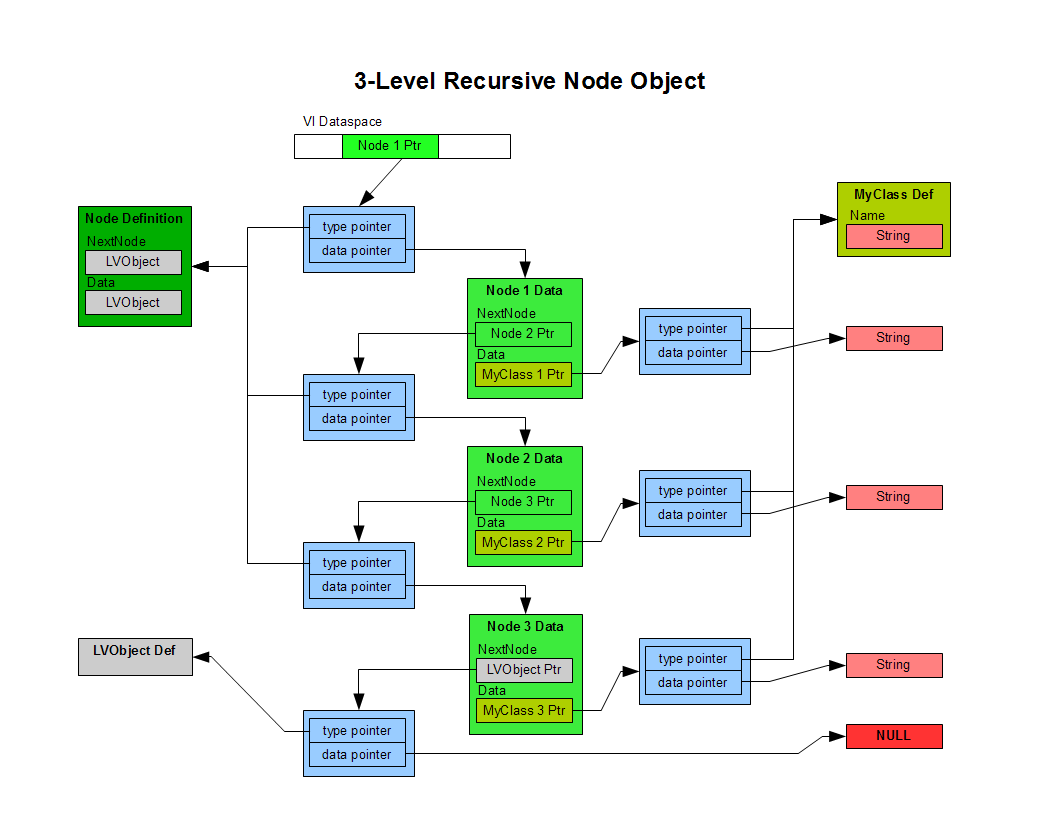
I spent a couple hours instrumenting your code and profiling memory use with the DETT. Assuming I'm interpreting the trace correctly (that's a big assumption) it looks like your code is also creating copies during the Node:InsertAtIndex method and the Node:DumpToString method. I'm guessing it's because those VIs are essentially recursive? [see the diagrams below for my guess at how memory is allocated at runtime for object composition. I extrapolated from the diagram in The Decisions Behind the Design.] If that's the case, there are still some things I don't quite understand. When classes are used in a vi, the vi dataspace contains a class pointer, not the class object. Even if an entirely new VI dataspace is created, it doesn't necessarily mean the entire data tree needs to be duplicated. The "Recursive Node Object" diagram shows the memory during the initial call to a recursive VI ("WalkList.vi"), which was passed the Node 1 object. If we execute a GetNextNode (retrieving Node 2) and recursively pass that into WalkList, wouldn't the dataspace for the new clone simply contain a duplicate of the Node 2 pointer rather than duplicating the entire data hierarchy starting with Node 2? And additional recursive calls contain copies of Node pointers at each level until the GetNextNode call returns a LVObject, at which point the recursion rolls back up. No?
-
Question on AQ's ancient linked list implementation
Daklu replied to Daklu's topic in Object-Oriented Programming
I wasn't very clear with my question. Someday I'll learn not to post when I'm tired. (He says, noticing it's after 10 pm...) I understand why classes are not able to include themselves as part of the definition. My question was intended to contrast your implementation with an implementation that replaces your Root class with LVObject in the Node class definition. In my LVObject implementation the Node object will still contain another Node object, the same as it does in your version. The difference is that mine is held in a LVObject field and yours is held in a Root field. I'm not understanding why your version doesn't make data copies and mine does when functionally they are the same. -
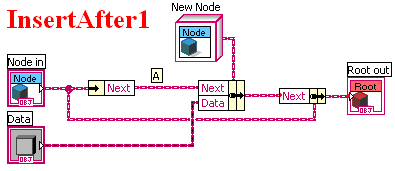
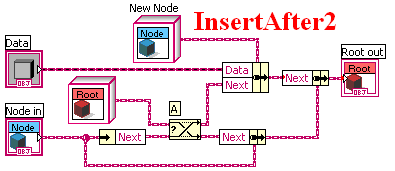
I've been exploring data structure implementations lately. At the same time I've been trying to reduce my use of references and maintain data flow as much as possible. Using Brian's Linked List code as a starting point I hacked around for a while until I got something that works but takes far too much memory to traverse the list. Turns out I was following a path AQ blazed 3 years ago. (You can get his source code from there.) Except I didn't think of using the Swap Values prim and have struggled for quite some time trying to eliminate the data copies. This is the relevant part of AQ's post explaining the code: ---------------------------- This is a linear list of data, where it is easy to append to the start of the list without ever reallocating all the existing entries. To access items in the list, you have to traverse down the list -- there is no direct access the way there is with an array. I've gone with a very flat hierarchy for implementing this example so that the bare minimum number of VIs exist. Just as with the Map, the key bit of magic is a child class that uses its parent class in the private data cluster. In this case, the parent class is Root and the child class is Node. There are only four operations currently defined on the list: "Dump to string" allows the list to be shown as a string for debugging (so you can evaluate whether it is working right or not) "Insert at front 1" is one implementation of inserting at the front of the list "Insert at front 2" is a second implementation of inserting at the front of the list; compare the two implementations "Insert at index" walks down the list to a given index and performs an insert at that point If you open Demo.vi you will see two link lists, one being inserted using version 1, the other being inserted using version 2. Ok... so let me try to deal with a long list of questions that have been raised by the Map class. To begin with, the Swap block. Here are the block diagrams for LinkedList.lvlib:Node.lvclass:InsertAfter1.vi and LinkedList.lvlib:Node.lvclass:InsertAfter2.vi. (I used red text so you could see there was actually a difference in those two long names!) [see images below. I can't attach them inline. -Dak] In each picture, there's a point marked "A". In version 1, at point A, we make a full copy of the entire list. The information in the cluster is being moved out of one cluster and into another cluster. So LV decides there has to be a copy made so that the two clusters aren't sharing the same data. This defeats the purpose of the LinkedList which is supposed to do inserts without duplicating the list. In version 2, at point A, we use the Swap primitive, new in LV8.5. We take a default Root object and swap it with the contents of Next. Now the contents of the Unbundle are free to be put into a new cluster without duplicating all that data. ------------------------- My question has to do with "the key bit of magic" AQ was referring to. Why does there need to be two node classes? Was it simply a way to trick Labview into doing recursion before recursion was available? Now that recursion is available, shouldn't I be able to replace the Root constant with a Node constant and remove the Root class entirely? I've attached code where I've done that but Process Explorer and the Desktop Execution Trace Toolkit are both telling me my Insert routines are creating copies. Any ideas? DataStructure-LinkedList.zip
-
And it forces you to consider the api of each module.
-
That might be good. I never post images to websites that only accept links because it is such a hassle. I'm glad Lava allows direct uploads. CCT does snippets? I'll have to look for that. Phew, I'm glad I never had to deal with that. It sounds manageable, except for the "drop one VI inside another" step.
-
Package Name Standardisation
Daklu replied to jgcode's topic in Application Builder, Installers and code distribution
Seeing as how it's your site I believe your vote is the only one that counts. Any thoughts on subcategorizing the palette, or just leave that up to individual developers? -
CCT >> snippets (Admittedly they serve slightly different purposes. CCT's "auto-save in the temp directory and copy the path to the clipboard" feature is probably the best feature I've ever encountered that I didn't know I wanted.)
-
So if I don't apply a password to my community and friended components, it's possible for someone to swap in new functionality under the guise of friendship?
-
True, but it doesn't sound like that's what they are doing. I was wondering how (and if) you prevented that from happening. I take it this strict relationship is enforced even if the library isn't password protected?
-
Package Name Standardisation
Daklu replied to jgcode's topic in Application Builder, Installers and code distribution
+1 for a Lava repository. Found the palette icon I created.
-
[Discuss] TLB - Top-Level Baseline
Daklu replied to Norm Kirchner's topic in Code Repository (Uncertified)
QFT. -
Package Name Standardisation
Daklu replied to jgcode's topic in Application Builder, Installers and code distribution
Honest guys, it was just an idle question. I didn't mean to stir up the dust... I agree tagging, searching, and allowing the user to set up a custom package organization (similar to virtual folders in the project window) in the way that makes sense to them will be more valuable than a standardized (but still cryptic) file name. Another feature that would help me is an info pane on the main window that would show at least the description. Having a modal info dialog is inconvenient. It's been a year since I've submitted anything to the Lava CR. Is there a document explaining suggested install locations and resources? (I created a LAVA palette icon that I think I built into my Interface Framework package. I'll have to see if I can dig it out...) -
Can you describe the route you went down and what seemed awkward about it?
-
Protected Folders In LabVIEW Project Library
Daklu replied to jgcode's topic in Object-Oriented Programming
Does a protection library function behave just like a private function? -
Been a while since I've been able to spend any significant time on the forum... Sure you can. Right click the library, Properties -> Friends -> Add Friend. Navigate to the VI you want to declare as a friend and click OK. Whether or not that will solve your problem is another question... I agree modularity is good. Independent modules are far better than dependent modules. I disagree. Sometimes duplicating code is a better solution than creating dependencies. Duplicating source code can easily cause problems. Duplicating deployed code in user.lib or vi.lib? Meh... as long as you do it smartly it's really not that big of a deal and avoids a lot of issues, especially if the duplicated code is private to the library that contains it. I don't think the technique you want to use is going to be very secure. Just remember, if you can create a library that becomes a friend of a library you've already developed and deployed, so can others. Those 'hidden' vis won't remain hidden for very long. If you're serious about protecting your IP create a single project with two builds: one for API.lvlib and one for xAPI.lvlib. Sure, at least I'm not aware of restrictions that prevent this, though I haven't tried it directly. Suppose ObjA friends ObjB, which in turn friends ObjC. ObjC will not be able to use ObjA's community methods directly. ObjB will have to wrap ObjA's community method in it's own community-scoped method. ObjC then uses ObjB:CommunityScopedMethod on its block diagrams. Usually via inheritance or composition. (Neither of which apply to .lvlibs... sorry.) Community scoped methods already are pseudo-private. Only very specific vis are allowed to use them. You and Ton are trying to make them more accessable than they already are. Maybe it is possible to deploy friend libraries after the fact. My gut sense is that it will create unexpected problems down the road.
-
[Discuss] TLB - Top-Level Baseline
Daklu replied to Norm Kirchner's topic in Code Repository (Uncertified)
This might be a stupid request, but is there any chance of giving the package a meaningful name? I'm not likely to remember what 'tlb' means when scanning 75+ package names. (VIPM 2010 can give the package a meaningful name in VIPM while leaving the package file name unchanged.) Just out of curiosity, is there any sort of package naming standardization in the works internally at NI? Currently I have ni_util_packagename, nise_packagename, nise_util_packagename, nise_lib_packagename, etc.