Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-
Yeah, they are often used interchangably, especially by those of us who don't regularly do low level programming. Since that post I have come to understand what AQ was talking about. My confusion was based on mixing grammar. I used "pointer" and "reference" as adjectives, calling anything that points to something else a pointer, and anything that "refers to" something else a reference. "Points to" and "refers to" are mostly synonomous (afaik) in programming, so it follows that "pointer" and "reference" are synonomous. AQ was using "pointer" as a noun, and it has a more concrete meaning in programming than what I was using. Some of the subtle differences between them are: *All pointers are references. Not all references are pointers. *A pointer is a data structure that contains a memory address. They generally allow much lower level control over the contents of memory. For example, pointer arithmatic can be used to access memory registers near the one the pointer actually points to. *A reference is an abstraction that doesn't have any meaning in and of itself. It could be a memory address, it could be a key in lookup table, it could be an array index, etc. Because a reference has no inherent meaning, reference arithmatic is equally meaningless. *References often have additional protections built into them that aren't available to pointers, such as reference counting to prevent the memory from being deallocated or semaphores to lock a value during read-modify-write operations. So when AQ said, "We fully support references. We do not support pointers at all." I now know what he meant. My initial post used incorrect terminology.
-
Hey Mikael, In general I prefer not using wizards when I develop code; however, implemeting interfaces can be tricky if one isn't used to it so I can probably make an exception for this. I like that your implementation doesn't require a base Interfaceable class. That makes the framework somewhat less intrusive than mine. It does have the tradeoff in that you can't interate through a collection of objects that all implement the same interface--you have to get the interfaces from each object first and iterate through the interfaces. Does it matter? I dunno... I like the idea of being able to get an interface without knowing about the specific object (using Interfaceable:Get Interface), but to be honest I'm not sure there's a use case for it. Unless I'm misunderstanding your code, I believe there are some flaws in your interface scheme with respect to how it handles by value classes: 1. As part of the class definition, ByValueClass contains 'I ByValueClassRef,' an instance of it's implemented interface, ByValueClass_MyInterface. You are initializing 'I ByValueClassRef' in the ByValueClass:Init method. This means ByValueClass is carrying around a copy of itself, potentially doubling your memory use. It also adds in the complication of forcing the class developer to implement code to keep the data in both copies synchronized. Why not ditch 'I ByValueClassRef' altogether and insert the copy of ByValueClass in ByValueClass_MyInterface as part of ByValueClass:GetI_MyInterface? 2. The interface object returned by ByValueClass:GetI_MyInterface is a copy of the ByValueClass object. It works okay in your example code because it is just showing a dialog box. What if the interface actually changes one of the object's values? The original object doesn't reflect the change. If I'm getting an interface to an object, I'm intuitively expecting the interface to operate on *that* object, not a copy of that object. 3. After using an interface to change the value of an object, there's no way to change the interface object back into the original object. This essentially makes all interfaces read-only operations. -Dave The funny thing is the night I posted that comment I actually dreamed she was still in diapers.
-
Variables don't exist in dataflow. Even wires aren't variables; once a value has been "sent down a wire" that value doesn't change... ever. It is more accurate to think of everything as a constant. See this conversation I had with Evil AQ last September. (Constants aren't the scam... variables are. )
-
Welcome to the forum Stobber! Absolutely. By-ref classes bring a different element into Labview programming. If users don't know a class is by-ref they can easily end up getting into a lot of trouble in their code. You can see from the methods for those two classes that I chose to use the same "bent corner" icon adornment that NI uses for their references (assuming the code I'm looking at is the same version as what is in the CR.) It's not a perfect solution, but it's works pretty well once you get used to it. Interfaces work equally well with vanilla by-value classes. It just makes for somewhat less interesting demo code. He understood it? I'm always a bit shocked when anyone can make sense out of these things I throw out there. Last summer when DVRs were first released there was a lot of discussion on whether the DVR should be internal or external to the class. I think most people primarily use them internally now, but there isn't really a right answer. If I have a class that sometimes needs by-val instances and sometimes needs by-ref instances, then I create the class itself as by-val and put it in a DVR when necessary. If the class always needs by-ref data then I use a private DVR to define the class as by-ref. You are more than welcome to if you want. Let me know how it goes. Right about the time I released the initial version I discovered that I didn't need Interfaces to solve the problem I had created them for. Implementing a HAL was a better solution for me. In fact, I have yet to run across a situation where I have needed Interfaces. I think they can be useful, especially in creating and using certain reusable LVOOP frameworks, but in application code I haven't needed it. Heh, I haven't been revered since my teenage daughter graduated from diapers. Truthfully, I'm nowhere near the most knowledgable programmer that posts to Lava. I have far less LV experience than most and like you I don't have the CS background of a traditional programmer. (I was a Mech Eng in my previous life.) One thing I do have going for me is I'm not afraid of looking foolish, so I'll post whatever wacky idea or failed experiment is on my mind at the moment. So while I'm always happy to learn I've created something useful for others, please save the reverence for someone more deserving. I'd much rather have others critique my code/ideas and look for improvements than accept them as the "right" way to do something. I'm learning as I go along, just like everyone else. What I posted last year, last month, and possibly even last week may not be inline with my thinking today.
-
-
Good catch Ton. (I missed the "it doesn't need to run" part.)
-
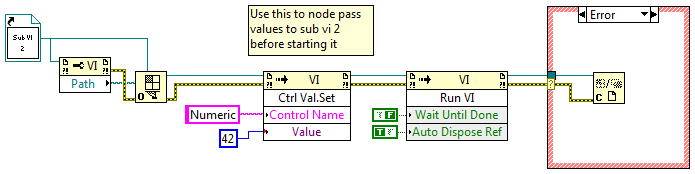
Nope, reentrancy won't get you there. What you need to do is dynamically load and execute sub vi 2 at runtime. That makes it execute in a separate thread. Try this...

-
Sounds like we're pretty much on the same page. It's nice to know I'm not straying too far from the beaten path. (I do wish events were easier to deal with in LV though.) Give me a shout if you want to take a look at my EventManagerLibrary and I'll post a link. I'd be interested in any feedback--positive or negative.
-

Need a small font for icons or other details?
Daklu replied to Aristos Queue's topic in User Interface
Not just recognizable, but meaningful. The glyphs provided in the editor are a great start, but more often than not I still revert to text for clarity. It's hard to find a combination of glyphs that accurately convey what the vi does. ------------ I propose we map each word in the english language to a 2 pixel combination. Each pixel has 256 possible values. We'll knock it down to 200 to remove those colors that are too hard to differentiate. That still leaves us with 40,000 combinations, more than enough to cover most people's known words. Each icon has an internal area of 30x30, or 900 pixels. That gives us 450 words to describe what the vi does. Should do the trick, doncha think? -
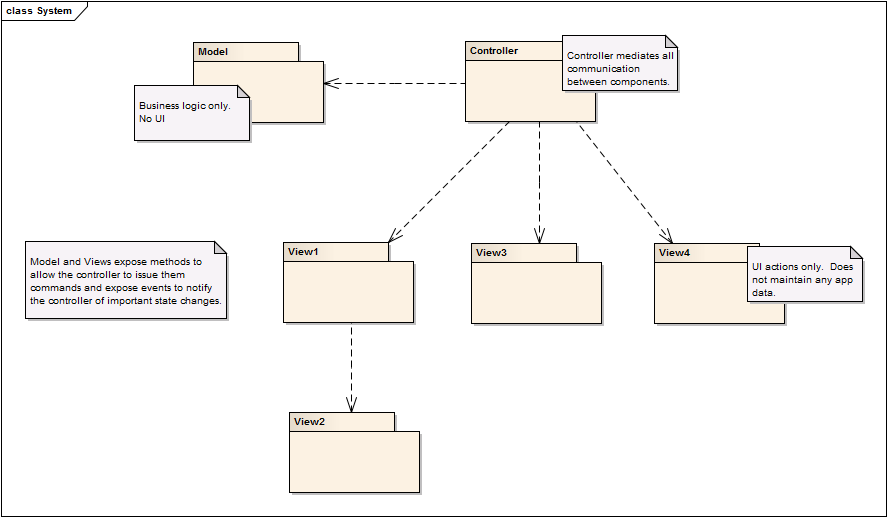
I can explain things I've done to address a similar situation. I know it's not what you're looking for but maybe it will give you some ideas. Grab a cup of coffee and pull up a chair--I'm about to get long-winded again. (I've explained this in more detail than you need for the benefit of future readers.) I'm really bad at UI design. Fortunately there are other developers in my group who are quite good at it; however, since requirements change so frequently during development it doesn't make sense to put in the time to create a polished UI when it's going to have to change next week. I tried to figure out a way I could develop the application functionality using a prototype UI while allowing us to easily drop in a polished UI without editing the functional source code. I ended up using a slightly altered MVC architecture that allows for a somewhat service-based design. The Model contains all the functional logic and processes needed to execute the test. The Views are solely responsible for interacting with the user. The Model and each View are independent services the controller instantiates and monitors. When a service raises an event, the controller catches it, figures out what needs to be done, and uses methods provided by each service to issue the appropriate command. My Views do not maintain any information about the state of the Model. For example, if I have a Start Test button and a Test Running indicator, my first instinct is to set the indicator to True when the button is pushed and issue a StartTest command to the Model. This can lead to synchronization problems with multiple views. Instead a view will expose a StartButtonPushed event and a Set TestRunningIndicator method. The View tells the controller the button was pushed and waits for the controller to tell it when to set the indicator value. The Model exposes a StartTest method and a TestStarted event. The execution sequence goes something like this... User clicks StartTest... causes... View:StartButtonPressedEvent triggers... Controller:StartButtonPressedEventHandler calls... Model:StartTest() calls... Model:RaiseTestStartedEvent() [alternatively calls... Model:RaiseTestStartedErrorEvent()] triggers... Controller:TestStartedEventHandler calls... View:Set TestRunningIndicator() This lets me implement an arbitrary number of view displaying an arbitrary subset of functionality without worrying too much about keeping all the views synchronized with the latest state of the model. As long as the controller sends the correct messages to the views in its event handlers everything's good. Commands issued from one view will automatically update the model's status in all other views. This architecture doesn't allow for view plugins. View code is built into the controller at edit time. You can solve that by implementing an abstract ViewBase class in the controller module and let the View modules implement concrete child classes. It also doesn't address your original problem: How do I make the Model stop and wait for a user response without hard coding it in place? Well, I didn't. Not like you want anyway. I ended up having the Model expose the process in small enough incremental methods that the Controller could trap the errors and wait for a user response before calling the next step in the Model's process. I don't really like that solution. Next time I'll probably try putting an abstract ErrorHandler class in the Model and let the Controller define and inject a concrete implementation at runtime. I did implement synchronous events in some Model-View interactions by sending a notifier along as part of the event's data object and it worked okay. I posted this thread a couple months ago speculating on using the Chain of Command pattern to address the problem of not being able to wait on a user response when a low level sub vi generates an error. I really have no idea what the end result would look like but it's something I've wanted to experiment with. It sounds like you're asking for overridable events here. ViewB doesn't handle the event so you want to move up the inheritance hierarchy until something does handle the event. However, you don't necessarily want ViewB to be a child of ViewA. I use an EventManagerLibrary that could give you the ability to override events. The EventManager class exposes a method for each event that can be raised. You could drop the library in your Application and create a child EventManager class in ViewA and a grandchild EventManager class in ViewB, each one overriding the events it knows how to handle. (As you said, making it synchronous requires passing a notifier along with the event.) On the other hand I thought you also needed to be able to make an event synchronous when multiple clients will all handle the event. For example, if you have multiple views connected to the application and the app raises an event all views need to respond to. Did I misunderstand this part?
-
What in the world could be more super crazy awesome than advanced data structures!? I'm afraid you'll have to hand in your Labview Geek membership card.
-
LVOOP constant with non-default parent values?
Daklu replied to shoneill's topic in Object-Oriented Programming
I'm assuming you want different parent class values for each child class because you have parent class methods that need to do slightly different things depending on which child class instance is on the wire at runtime. Here's a similar option I've done that also eliminates the constructor... Since the color constant is consistent across all instances of the class, use the Must Override option to "hook" into the constant for each child class. Give the parent class a dyn disp Get Color method and mark it as Must Override, but don't create a Color field in the parent class. In the child class, you can either: a) Put the color constant directly on the overridden Get Color method, or b) Make the color constant a class field and use a regular accessor method. I've done it both ways. B is easier to maintain if you have several constant hooks as all the constant values are centralized. I don't know if it makes a difference in execution. I used this technique in a situation where I had a fairly complex process that had only slight variations, such as the name of a table to store the end result. I ended up creating a unique child class for storing data in each table--about 20 in all. Looking back I think this made the code more complicated than it needed to be. Faced with the same situation today I would use a parent class constructor that took all the immutable data (such as table name) as inputs, create the necessary object at run time, and scrap the child classes completely. (Edit - This technique is kind of along the lines of the Template pattern, except instead of replacing algorithm steps you're just replacing algorithm constants.) -
LVOOP constant with non-default parent values?
Daklu replied to shoneill's topic in Object-Oriented Programming
Heh heh... "fructarted." That still made me laugh. (I needed that today. Thanks Ben!) Interesting you should bring this up. I've kind of waffled back and forth between including and not including a class input terminal on my constructors. I had finally settled on not including it in the last month or two. Last week I ran into a situation where I *had* to have a dyn disp input on my constructor. I've been meaning to write it up and post it to get feedback from the experts. -
Very cool Brian! I'll add your presentation to the list of sessions I would have attended if I had been able to go. I've been talking to Jon (jgcode) about LapDog the last couple days. We've both been really busy the last couple months but our schedules are easing up a bit. If you can donate the code to LapDog go ahead and add it to our SourceForge repository. (Create a subdirectory with your logon name under the users folder and drop it in there. We'll copy it into a package-specific directory when we start working on it as a package.) Your data structures actually fit in very nicely with my initial plans. One of the first packages I want to release is a set of collection classes that can be used with interchangable data structures underlying them. Having another package with data structures available for developers will go a long ways toward increasing it's usefulness.
-
LVOOP constant with non-default parent values?
Daklu replied to shoneill's topic in Object-Oriented Programming
I agree with Paul. I've used non-default object constants in the past and in the end I thought they were more trouble than they were worth. My question is, why do you want the child to have non-default values and how are those values determined? If the values are fixed at edit time, you might be able to change your structure in a way that allows child classes to use default values. -
I think we are using the word "event" in slightly different contexts. I was thinking about an "event" along the lines of how it is used in physics and separating the instantaneous event itself from the bits that process the event in software. Sometimes this kind of thinking helps lead me to solutions. This time... not so much. Can I ask what kind of things you're doing that require synchronous events? Off the top of my head I think my initial reaction to your problem would have been to try and change the design so synchronous events wouldn't be needed. Clearly using synchronous events is a better route to take. I'd like to get some understanding of what use cases people encounter where they are used. Cool trick Norm! I thought Register Event Callback was only for ActiveX/.Net objects. In fact, I went and checked the help file to see if I had missed anything and found this: "Use this function to register .NET and ActiveX events only." Any idea what nasties might be lurking under the covers? How old is this horse? I can't remember ever hearing about this and google didn't turn up anything. Is anything published that provides more information about it?
-
<thinking out loud> Events, by definition, are instantaneous. They don't have a duration so the concept of synchronicity as applied to events is meaningless. The event handling structure is synchronous in the same way every other structure is synchronous. Ton has pointed out elsewhere that there may be multiple event queues: one for front panel event and one for user events. Enabling the "lock front panel" option appears to simply hide additional elements in the front panel event queue from the event structures until the "locked" frame has finished. The timeout case (and presumably user events) will still execute in a parallel event structure. (Personally I'm not sure what the purpose is of the "lock front panel" option. It doesn't prevent front panel events from occurring; it just stores them in a pre-buffer so the user isn't aware that his button click was captured.) </thinking out loud> Any chance you come from a C# background? A couple months ago I discovered that in C# event handlers run in the same thread as the event. (Don't know if that's true for other languages as well.) If there are multiple event handlers for a single event then they execute synchronously instead of in parallel. I saw a post from one user explaining this and then asking, "why would you want event handlers running in a separate thread?" There's some cognitive dissonance going on here because I could only think, "why wouldn't you want event handlers running in a separate thread?" I think events in general are the wrong tool to use if you're trying to achieve synchronization. My feeling is having subscribers register callbacks with the publisher is a more appropriate technique to use. That said, you might be able to get there by sending notifiers along with the event data and counting the number of notifications you receive. I think this is inherently unsafe though. Events are broadcasted. They might be picked up by 100 subscribers; they might be picked up by 0. The event producer has no way of knowing if the event consumer is actually registered to receive the event.
-
I can't give an authoritative 'yes,' but that's my take on it. Each class provides a specific function. For example, I use collection classes fairly frequently. Its sole purpose is to manage a group of arbitrary objects at runtime. It has a few very basic methods: Add Item, Remove Item, Get Item, etc. I'll use a collection class as part of a set of classes (often grouped in an lvlib) to provide some higher level of functionality. I have an EventManagerLibrary I can drop into an observable software component that provides a relatively easy way for that component to manage and raise events from multiple observers. The other classes in the EventManagerLibrary use the collection class' methods and as a result are very tightly coupled to it. That's okay, because the EventManagerLibrary is used as a whole, not broken up into separate parts. (I don't want software outside the library depending on the collection class though, so it's a private member of the library.) For better or worse, I spend a lot of my design time figuring out and maintaining dependencies and between modules. Somewhere in my reading I saw that described as "managing the seams" and I think that's an good way to phrase it. Once I figure out what my dependency tree should look like from a high-level application view, then I can figure out how to implement it using (when appropriate) various design patterns. Paul gave some good examples of managing the seam between the Model and the View. In his XML app the Model directly updates the View's fp control. This couples them together to some extent. (Though I believe it's a relatively weak coupling since it's using a native LV type to cross the 'seam.') Lately I've been keeping the Model and View completely decoupled by having them both send and receive messages from the Controller, which acts as a mediator. Is one method right and the other wrong? Nope, it all depends on what you're trying to accomplish. Paul understands the consequences associated with each approach and made a decision based on the requirements. Where it gets dangerous is when decisions are made without understanding the consequences. Actually, the Entry and Exit actions are overridable BaseState methods and are part of the state machine. Each state has the ability to execute arbitrary actions when entering the state, while in the state, and when leaving the state. Moore state machines only allow entry actions. Mealy state machines don't allow any of those, instead opting to associate actions with a specific transition. Decomposing a problem into states using Entry, Input, and Exit actions for each state reduces the number of states required and makes the system as a whole easier to understand and modify. (That's my hypothesis anyway.) [Note: QSM's are most closely related to Moore state machines, except instead of executing an entry action and then waiting in that state for the next transition like a "real" state machine, in a QSM a state is continuously reentered until the next transition occurs.] Functionally I think our two approaches are identical. It is possible in your model for the Execute method to have equivalent Entry and Exit operations surrounding a loop that polls the shared variable. I created unique Entry and Exit methods in the BaseState to help guide the way the developer thinks about states in their application. Without understanding the idea of Entry, Input, and Exit actions a developer is more likely going to lapse into bad habits learned from the QSM. The BaseState class contains a private LVObject labelled NextState. When a state has enough information to determine what the next state should be, it puts an instance of that state in the NextState variable. This most correctly occurs in the InputActions method, but technically could happen in any of the three methods. StateTransition is a static dispatch BaseState method that simply gets the next state object from the private data, copies the existing BaseState data into the next state object, and puts the next state object on the shift register wire. I'll try to put together a simple example that I can post online. However, it is the weekend and the sun is out (rare enough in the Pacific Northwest) so no promises on when I'll get it up...
-
Note to self -- Follow the links before asking questions. (It's really easy...)
-
Thanks for the info Darren. Since we have almost twice as much time to do the coding, are we expected to produce a more complete application?
-
Not so good for some of us. I was counting on the written portion helping me overcome my generally slow coding. I haven't checked out the sample exam yet but I'm a bit nervous about the requirements tracking bit, not having been exposed to the Requirements Gateway at all.
-
If I can add a bit to what Paul said... Any two components that collaborate to achieve some goal are going to be dependent on (coupled to) each other somehow. Some types of coupling are strong; others are weak. (See here for a list of coupling types.) At the very least they have to agree on the shared data schema. What's it look like? How is it formatted? What does it mean? How you solve the problem depends on your goal for that particular component. If a component is application-specific, typedefs are an okay solution. (I generally avoid them though.) Since all the code that uses the typedef will be in memory any time the typedef changes you're pretty safe. If the component is intended for general reuse, you're probably better off passing data using native types--arrays of strings, numbers, etc. Sometimes I don't want the two components (CompA and CompB) to directly depend on each other at all. In those cases I have a few options: Mediator - I create CompC that acts as a go-between for CompA and CompB, controlling the flow of information. It doesn't matter if CompA and CompB use the same data schema; CompC simply translates one schema to the other and passes along the data. CompC block diagrams use CompA and CompB methods, so it is dependent on them. A and B can easily be reused in other apps, but C must take A and B along with it for reuse. Dependency Injection - In this case CompC provides a common interface and I "inject" it into CompA and CompB at runtime. CompC could be a TestData class, providing Set Data, Get Data, and SaveData methods. This makes CompA and CompB dependent on CompC as CompA and CompB block diagrams use CompC methods. C can easily be reused in other applications; A and B must take C with them if they are reused. Which one you use depends on several factors. If A and B have already been created and tested then using a Mediator is the better solution. You don't want to make a habit of rewriting completed code. If you're creating them all from scratch then you can decide what you want your dependency graph to look like and design around it. FWIW, I often implement a TestData class and use it with both a Mediator and/or Dependency Injection, depending on the module that needs the data. In my case the BaseState class holds the shared information and exposes protected static dispatch accessors allowing the child classes to read and write the data. It may or may not be a good solution... I haven't worked with that state machine model enough to decide. Your questions sound like the same questions I was asking not too long ago. I'll make the huge assumption that your designs and way of thinking are similar to where I was at that point. My apologies if my assumption is wrong. When literature refers to cohesion and coupling, they usually refer to it in the context of a specific class. It is certainly important there, but I found that focusing on each class as a separate entity in my applications often resulted in bad code. I ended up trying to make each class do too much.* I believe my code became much clearer and much more flexible when I started concentrating on decoupling modules instead of classes. I typically use project libraries to organize a group of classes into a module that provides some useful functionality. Since none of those classes are going to be reused independently, it's okay for them to be relatively tightly coupled to each other. To limit the incoming dependencies and preserve module decoupling I'll often make all the tightly coupled classes private and provide one or more public classes as the module's interface. *As an example, just yesterday I was tracking down .Net memory leaks in a class I had written to control an RF sniffer. The instrument hardware captures data in a queue and 8 ms "frames" of data (each one a .Net reference) are read one at a time. I need to keep all the capture frames in memory so they can be post processed, but I didn't want .Net references running all over my application. The RfSniffer class' evolution resulted in the class maintaining a history of captured frames, to preserve encapsulation. This class not only provided hardware control (Open, StartCapture, ReadFrame, etc.) but also had to provide data analysis methods. (FindTriggerFrame, GetFrameTimestamp, etc.) The api for the class was a little confusing, but not terribly so. I thought it was a reasonably good design. (This was just last week...) Had I not discovered the .Net reference leak I would have left it as it was. As it turns out, the RfSniffer class wasn't properly releasing all the captured frames in memory when a new capture was started. Furthermore, because of the overall application design there wasn't a good way to introduce a ReleaseFrameReference methods without violating my layering and creating a ripple effect up through the app. The solution I decided on was to refactor the RfSniffer class into two classes**: RfSniffer for instrument control and RfSnifferData to store and perform operations on captured frames. It's obvious to me now the new design is cleaner, easier to use, and more flexible. I hadn't really realized it at the time, but I was struggling with how to implement the requirements into the RfSniffer class. It's easy to chide myself for not realizing the problem and figuring out the solution earlier, especially because I often create TestData classes and I'm familiar with the strategy. In retrospect I was so focused on trying to get the product released (it was supposed to be out the door on Tuesday) I made a series of "quick and easy" changes rather than step back and look at the bigger picture. If my design had been correct from the start I could have avoided the reference leak and released on time. [**I don't always encapsulate modules in libraries. For trivial cases such as this I'll define sub-modules using virtual folders and the project window hierarchy.] Meh... I don't know that any of us are terribly qualified for this. I consider all the LVOOP discussions 'group learning.' The more people contribute--regardless of qualifications--the better we all learn.
-
How many "User Events" can LabVIEW queued?
Daklu replied to MViControl's topic in Application Design & Architecture
FYI, I posted a screen shot of the state machine implementation I mentioned above on Paul's thread here. -
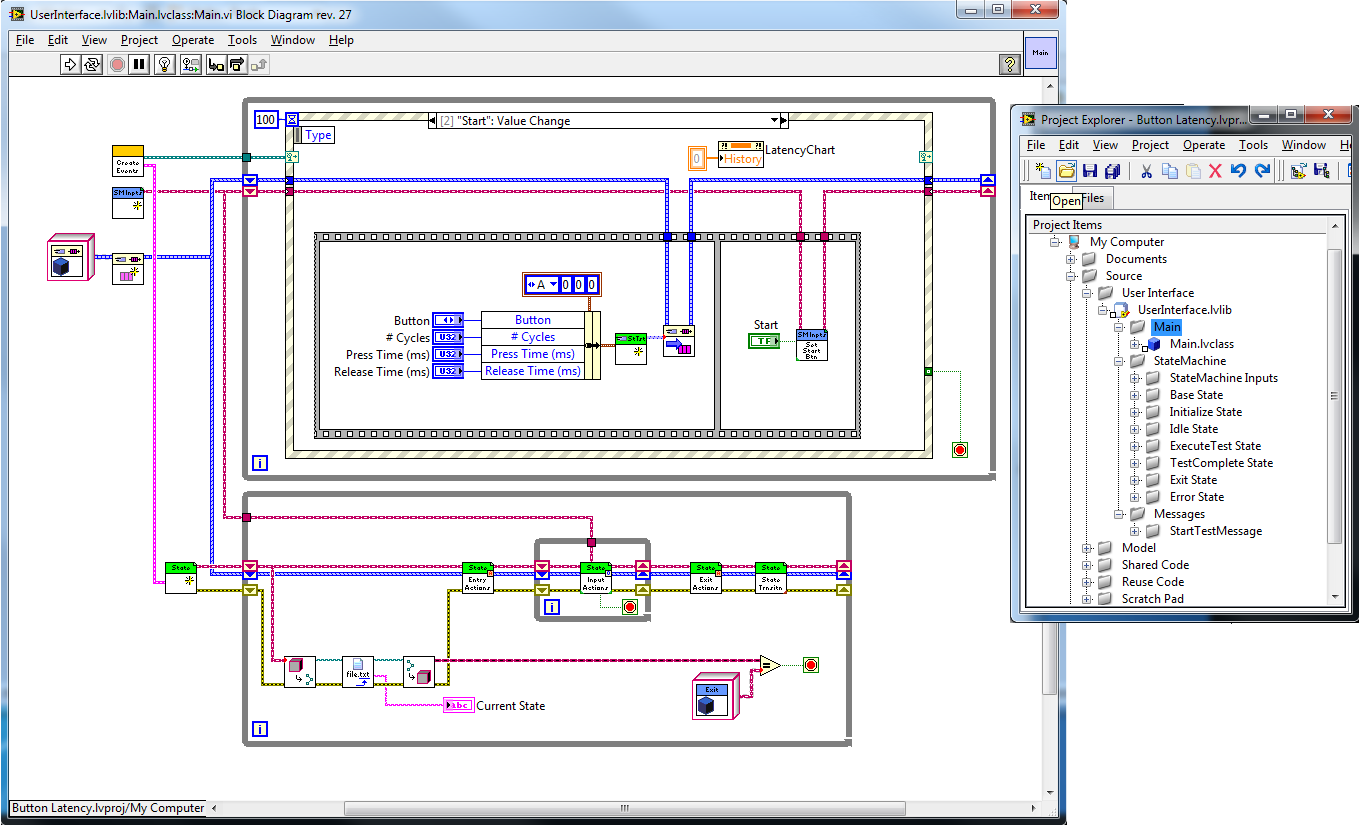
This is how I implemented a state machine without shared variable events. Like you, I have each state defined as a separate class. Since I don't have shared variable events, I need a different mechanism for getting the input (control) signals to the state machine. StateMachineInputs is a by-ref class that encapsulates those signals. In this case it is just 3 booleans for the Start, Abort, and Exit signals. I also have 3 separately defined sections for each state: Entry Actions, Input Actions, and Exit Actions. Entry Actions are things that happen once every time the state is entered. Input Actions are those things that happen continuously while the state machine is in a given state. This method monitors the state machine input signals for the right set of conditions that prompt a state transition. Exit Actions are things that happen once every time the state is exited. Splitting the state's actions into three categories helps me decompose the problem into an implementable solution. Wrapping the Input Actions in their own loop avoids the QSM's inherent problem of continuously reentering the same state, which makes entry and exit actions somewhat cumbersome to implement. I could get the same behavior using a single Execute.vi and coding the entry and exit actions inside that method. I like to explicitly define entry and exit action because it helps me make sure my states are cohesive. At this point I'd consider the difference a matter of personal preference.
-
Illegal default values for DVR classes
Daklu replied to MikaelH's topic in Object-Oriented Programming
Interesting comment. I take it R&D and Usability spend a lot of time trying to get things to work using syntax a novice user is likely to try? (This is one of those dev team considerations that I, as an end user, don't fully appreciate when I'm griping about Labview.) Roughly how much faster are we talking about? This is one of those optimizations I probably wouldn't bother implementing unless the design called for a parent class anyway or I was looking for performance gains. Of course, by the time I run into an app where I'll need that performance gain I'll have completely forgotten about this trick. Someday I'll need to put together a list of optimizations... Huh. My first reaction was, "That's an interesting way to use a collection." In my code collections are separate entities with their own hierarchy and having a collection inherit from the Graphic class seemed odd. I went back and referenced GOF and realized the example's Collection class is the same as GOF's Picture class. Graphics.lvproj implements GOF's example almost exactly. Nice! Now it just needs to be tagged with a "composition" keyword.