Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-
Sorry, no helpful advice other than put off that goal for another couple years, or maybe forever if you can. (It is a noble goal--it just doesn't look very achievable right now)
-
Thanks Jon... <dreamy eyed adulation> you're my hero. I had hoped to separate the data collecting code from the data saving code, but this appears to be the easiest way to accomplish the main goal. Couple other questions: How do people manage tasks/channels/scales between the project and the executable on the target computer? My idea was to provide a known good measurement and let the engineers develop and use new tasks, channels, and scales in NI Max as needed. When testing it out on the target computer Max gave me a licensing notice that, since the target computer doesn't have a Labview license, you can use max to modify those things but not create them.
-
So... having been using Labview heavily over the past 4 years I am now, for the first time, writing an app that significantly uses DAQmx. Yep, I'm a total noob when it comes to doing those things that have historically been Labview's bread and butter. Background: Right now I have a state machine running in a parallel loop continuously reading (using a PCI-6143) analog signals from an accelerometer and gyroscope. This data collection loop posts the data on a queue as an array of waveforms. A data processing loop get the data, updates the front panel, and streams the data to a TDMS file. I have a task setup with all 6 channels and a scale for each channel that converts the analog signal to g's and deg/sec. Since the sensors have multiple sensitivity settings, the user will (I think) be able to create new scales and apply them to the channels via NI Max when they change a setting. All good so far. Each point of the waveform data gets sent to my data processing loop as a DBL, using 8 bytes of space. The PCI-6143 has 16-bit ADC's. I can cut the storage requirements by 75% by converting the DBL to an I16. If I knew the possible range of the waveform I could multiply each point by 2^15 and round it off. As near as I can tell the waveform data comes to me post-scaled and without any scaling information. Question: How do I go about showing the post-scaled data to the user while saving unscaled data and scale information to disk?
-
Active Content? Is that the same as Unread Content?
-
I don't speak for the admins, but personally I don't mind reposts here. I don't have a list of blogs & boards I keep up with on a regular basis. Lava and the occasional visit to the NI forums are where I get the bulk of my spontaneous programming information. And of course, it *is* the lounge, where presumably (mostly) anything goes.
-
You're my hero...
-
I've never worked for a systems integrator, but I understand why fit and finish is a very high priority for them and their customers. Not only does the fit and finish directly influence the company's reputation, but support isn't always immediately available and likely costs the customer more money. In the past I've built manufaturing test equipment and fit and finish was important since downtime was costly. In my current position with strictly internal customers... not so much. They want fit and finish and we give it to them when we can, it's just not always possible given schedule constraints.
-
Chris Relf... a man whose wisdom runs so deep he quotes himself!
-
Huh? Config data? I don't understand the question... I write test tools for internal product development teams. Application fit and finish--like storing default values and other user customizable information--is pretty low on the priority list. Flexibility is the name of the game here. Most of my requests are something like, "I want to combine the wireless protocol sniffer from the Foo tool and the robot controller from the Bar tool to create test cases for a new product." It's really bad mojo if product development is held up because the test tools aren't ready, so I sit down with the test engineer and "reset their expectations" by filtering out the features that improve usability and focus on collecting the data they need. Once we get all the data collection systems nailed down, then I'll go back and work on making it easier to use, faster, more automated, etc. Lots of times I simply don't have much time to work on that, or the test engineer decides fit and finish isn't worth the hit to their budget. (For some reason they think all the stuff they ask for can be implemented with just a couple clicks...) We've had an ongoing large project for the last year and a half that uses text config files, but it was implemented before I got here and it's not object-based. If I ever need/get to implement a config file, creating an AppConfig class is certainly the way I'd do it.
-
Like Francois said, the downcast prim is based on wire type, not object type. Try using the Preserve Run Time Class prim to get the behavior you expect.
-
Do you mind if I ask what's included in your instrument hierarchy? I ask only because I have found that creating an inheritance tree of instruments restricts their reusability. (I'll spare the thread the long explanation of why that is. PM me or start a new thread if you're interested.) Do you want users to be able to see and edit the class details? If so, ini files are as good as anything. If not, saving to a binary format would probably be wiser. (Users have an annoying habit of messing with things that are better left alone.) This is exactly what the Interface Framework does. (How rude of me to mention another repository package on Francois' thread!) In the back of my head sits the idea of making an IPersistable interface for the Interface Framework. Persisting objects to disk is one of those requirements that is just begging for native interfaces. When class mutation works, it works well. When it breaks, it breaks hard. I haven't had to persist object data in my apps very often (uh... ever?) so I haven't got around to doing it yet, but I'm sure it could be done. You'll still have to write and update the mutation code every time the class changes. Interfaces give you a common api for dealing with all persistable objects so your application level code doesn't have to change. [Edit - Sorry Francois]
-
Off the top of my head I would say steps 1-5 are possible, though I'm not a script monkey so that's just a guess. jgcode is one of the alpha apes around here when it comes to scripting; maybe he'll chime in. Whether doing steps 1-5 will accomplish goals 6-9 is a question I can't comment on. I know less about FPGA programming than about scripting.
-
Thanks Jon. Exposing non-standard features using VIPM is very helpful. Note to users: NI's policy is that vis in vi.lib are not for public use unless they are on the default palettes. Functionality is subject to change in future versions and forward compatibility is not guaranteed or implied. This isn't to discourage anyone from using them, just be aware of the potential consequences.
-
Nice job Jon! LVOOP Assistant is now my second favorite user contributed tool. (Hard to dethrone CCT, though I will definitely use this more than CCT.) "Link to your own Static/Dynamic method (.vit) templates Create your own Virtual Folder names etc..." Both of these occurred to me while watching the videos. Being able to set my own templates would be more useful for me than defining custom virtual folder names. I tend to create virtual folders on an as needed basis depending on the class requirements rather than use a pre-defined set of folders. "Public Service Announcement" Since LabVIEW is a contracronym is the first place, shouldn't it be LVIEWOOP? Or just LOOP?
-

Apply Icon Changes to Child Implementations
Daklu replied to mje's topic in LabVIEW Feature Suggestions
I agree. I've thought about creating a small tool that would apply glyphs to an arbitrary set of vis, but thus far it has gone the same way as many of my ideas... nowhere. Let me know when you whip one up. -
for both Jon and Joe.
-
Really? I hadn't noticed. ('Course, I don't go there very often...) Yeah, me neither. Actually I agree with their reasons for not opening up feature planning. I just wish it was different. And since "world peace" ideas get no love, there's little motivation to post them. (In spite of that, hope overrode logic once again and I posted another world peace idea I've been lobbying AQ for.)
-
I know. That's why I still have faith some of the grander ideas may still come to fruition. As a Labview end-user I often have a hard time explaining what my *goal* is and tend to focus on asking for a *specific implementation.* Maybe it's a problem all users have. My customers are always telling me *how* to do something that they think will meet their goal, only to find out afterwards that it doesn't quite work out the way they thought it would. Ironically, I'm pretty good at drilling down and figuring out customer requirements when I'm the developer... I just suck at it when I'm the customer. That doesn't surpise me at all, but I'm glad to hear it anyway. You're programmers so you understand what we're asking for and why it doesn't get more support on the IE. Here's the questions I'm wondering about: - Does R&D have the authority to put language features on the map that add new functionality when marketing wanks are crying that an Express vi to randomize the front panel color scheme just hit #10 on the IE? (Yep, my biases are showing... sorry.) - Which department owns the IE? It's a device to solicit customer feedback so my guess is marketing or product planners, but maybe not. I suspect neither of those groups are particularly concerned about the minority of advanced programmers who see a need for major feature additions. And when it comes down to deciding between the random color Express VI with 78 gazillion kudos and interfaces with 9 kudos, are interfaces even going to show up as an option on the slide deck. Old ideas drop off the community radar and don't get any action. Do they stay on NI's radar? Sure it provides a one-stop shop, but if product planning is just dashing in to grab the latest sugar-coated idea featured on the end cap, the old ideas will forever sit in the back gathering dust. There will always be ideas with way more than 9 kudos. How often is the entire list scoured and evaluated? I don't mean this to be a rant against the IE. I really do think it's a good idea and NI's commitment to focusing on the customer is admirable. It's just frustrating as a user to see relatively minor changes shoot to the top of the chart while the ideas that truly expand what we can do with the language go nowhere. You have the advantage of knowing how seriously an idea is being considered. As far as the rest of us are concerned, we often don't have any insight into what effect (if any) the idea is having on the direction the language is going. (Unless it happens to be one of the few ideas that gets picked up by NI.)
-
Please, do whatever it takes to get them to stop. I thought it was just me that didn't like it... Yep, you did. And I deserved that for taking the bait. What is the "Lithium system?" They rot on the vine, never having received the loving attention of the community or an NI sponser. (Except for configurable quick drop shortcuts, which Darren kindly took care of.) Out of 17 ideas I've posted, only 4 have received more than 10 kudos and none received more than 20. (Not that all of them deserved kudos...) I've given up on posting any significant language advancement ideas on the IE, simply because I know it won't get any kudos and that will give management leverage not to implement it. If I lobby for it on Lava or NI's forums it might get someone's attention at NI and they can rally internal support for it while avoiding the dreaded IE mark of death. That's my hope anyway...
-
Yep. Time is a limited resource. An increase in one area requires a decrease in another. Granted in this particular case where the code is already done there is less of a hit. To merge it into the main branch probably requires someone to develop tests, probably a code review, and maybe someone to act as PM to manage the process. Less time to be sure, but still time that they could have spent working on stability. I'd like to see some new features, but I'd like more to not have LV crash on me half a dozen times every day. If NI decides they need to devote all their dev time to stability issues, I'm okay with that. Whenever I have a customer tell me their change request should be simple the alarms go off. The request might be simple, but implementing the request often isn't. As a rule they get to tell me what they want; I get to tell them how long it will take to implement. (Sometimes when I give them an estimate they decide they don't really need that feature after all.) Absolutely! Here's hoping Mercer and Nattinger can "market" the idea successfully. (Though in reality I'm sure NI already has some method for combining similar ideas.)
-
Object-Based State Machine Pattern
Daklu replied to Daklu's topic in Application Design & Architecture
I learn something new every day. Thanks for correcting my misunderstanding. I do think in general language (if not in uml syntax) inheritance and dependencies are specific types of associations. At least that's how I use it. In the early phases of a model I'll use an association to link two classifiers that need to collaborate in some unknown way to achieve a goal. Later on as the model and software takes shape I'll usually replace it with something more specific. Are my models wrong? Possibly, but since I'm the primary customer of my implementation models and I understand my intent, I'm okay with playing a little loose with uml syntax. (I'd happily use more correct syntax if 1: I knew what the correct syntax was, and 2: I could use the correct syntax without addition cost in time.) If by meta-model you mean the relationships between components in the uml spec, I think not at all. My impression is that the uml spec is primarily for people implementing uml modelling software, perhaps as a way to make models interchangable. It doesn't tell you how to use uml to model the software or how to implement the model. For example, when I'm working with new technologies or processes I'm not familiar with I'll model the problem domain using uml. The point of this model is to make sure I understand the customer's requirements and give us a common reference for communicating. I'll use classifiers to identify components of the customer's system: DUT, Test Station, Operator, Network, etc. Sometimes these classifiers become software components, sometimes they don't. (Rarely do they become a single class.) I'm not even thinking about software design at this point so I don't really care. I think that's a question that has to be answered by each programmer considering the environment they work in and the goal of the uml model. Highly regulated industries may have very strict rules regarding uml models. For me, the purpose of modelling isn't to create a model or even to document the code. It's to work through design issues and create software that meets the customer's requirements. -
Object-Based State Machine Pattern
Daklu replied to Daklu's topic in Application Design & Architecture
Thanks for the heads up. I hadn't correctly redirected all the prior MessageLibrary links in the 2010 version. A mass compile would correct the problem but it was still annoying. I've recompiled and uploaded the 2010 version again. -
Object-Based State Machine Pattern
Daklu replied to Daklu's topic in Application Design & Architecture
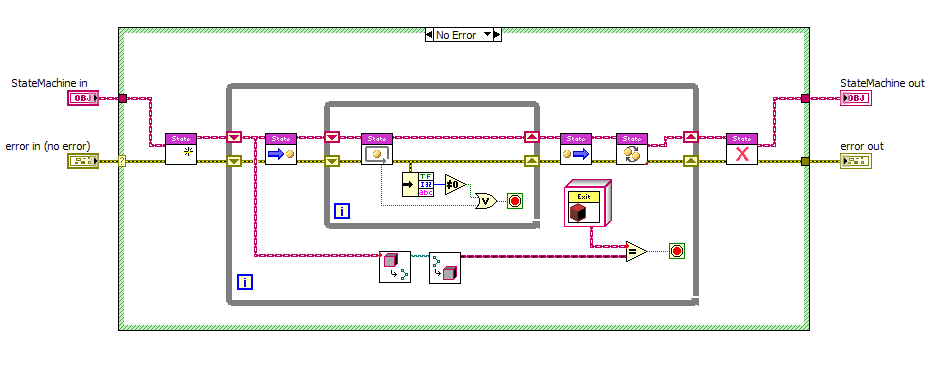
[Copied Paul's question from another thread to try and keep discussion contained.] Just to make sure we're all on the same page, here's how I use the various terms: Entry Action - Executes one time every time the state is entered, regardless of the previous state. Execution* Action - Executes continuously until the state decides it's done. Exit Action - Executes one time every time the state is exited, regardless of the next state. Transition Action - Executes after exiting one state but before entering the next state. Each transition action is associated with one arrow on the state diagram. (*Also known as "Do Actions" or "Input Actions," depending on the literature.) You're thinking in QSM terms where each case is a state. That's a flawed approach. It requires you to repeatedly exit and re-enter the state so you can monitor the queue for new messages. As you said, you have to somehow keep track of whether we're re-entering this state or entering it from another state to be able to handle entry actions. I skip all that confusion and use separate vis for EntryActions, ExecutionActions, ExitActions, and StateTransition methods. The action sequencing is done by the StateMachine:Execute method, as shown below. The outer loop executes only one time for each state. The inner loop continues executing the state's ExecutionActions method until the state receives a combination of input signals the state understands as a trigger to transition to a new state.
-
Object-Based State Machine Pattern
Daklu replied to Daklu's topic in Application Design & Architecture
An association (as I understand it) is a more general link betweeen classes on the UML diagram. It could be composition, dependency, delegation, inheritance, etc. I can have an association between two classes without either class definition containing an instance of the other. For example, if ClassA:Method1 has a ClassB input terminal, ClassA is dependent on ClassB without necessarily containing ClassB. At the same time ClassB:Method2 can have ClassA as an input terminal. This is a bi-directional association and allowed in Labview. Labview disallows bi-directional composition of classes. No cycles allowed in class definitions. That's where LVObject (or some other parent class) comes into play. Yes, you are reading the code correctly. Since the BaseState definition contains the BeagleStateMachine class, the BeagleStateMachine definition cannot contain BaseSate in the NextState field, so I used LVObject. Note the BeagleStateMachine's NextState accessor methods do use BaseState as input/output terminals, so there is a bi-directional dependency between the two classes. Yep, functionally it is a more well-defined variation of the Standard State Machine template provided with LV. My intent has been to find a better alternative to the QSM, not necessarily a more defined variation of the Standard State Machine template. That that's what I ended up with speaks to NI's foresight in including that template in the first place. Too bad it's not more widely used. In my experience OO programs are almost always harder to understand than procedural programs by just reading the code. It takes a lot of work to understand the relationships and responsibilities of the objects. However, once you understand those relationships OO code is easier to understand and easier to modify. I've done a lot of UML modelling on whiteboards. I also use pencil and paper when a whiteboard isn't handy. The primary goal of my modelling is to figure out a design that will meet the requirements, not create a complete, formally-accurate UML representation of the program. I try to include enough documentation to help others understand the relationships. Usually that means a class diagram and some sequence diagrams for the more complex operations. Recently I've taken a suggestion from Ben and started including documentation bitmaps on the block diagrams. This is one of the key differences between a state machine and the QSM. A QSM has a command queue; a state machine does not. In a QSM the queue controls state sequencing. In a state machine the state machine controls sequencing. In "real" state machines the machine monitors input signals and acts based on those input signals. Nothing tells the machine to make a transition; it decides when to make the transition based on the input signals. In earlier implementations of this pattern I used a DVR of a boolean cluster to represent the state machine's input signals. In this implementation I switched over to a message queue for transmitting input signals since all my input signals are essentially requests to go to a new state. In a nutshell this is one of the major problems of the QSM. The queue in a QSM is issuing commands the state loop must follow. In this model the queue is for issuing requests to switch states. It is a subtle difference, but the consequences are huge. [Edit] On re-reading I think you're saying the state machine should have access to the input signals, but the states should not. Is that correct? This was an implementation compromise. I've considered a more pure model where the state object would invoke a transition object, which in turn would execute its actions and prepare the next state object. I haven't run across a state machine where I needed a lot of independent transition actions, so the additional complexity isn't worth it. If actions need to be performed on a specific transition when exiting a state, you can override the StateTransition method, query NextState to determine which transition is taking place, and drop the transition code in a case structure. As I understand it, UML specs define model behavior not implementation details. The modelling rules and objects may or may not translate directly into code. I'd have to see a very clear benefit to justify the additional complexity of an implementation that matches UML behavior. (That's not to say it isn't there... just that I don't see enough payback yet.) Dunno yet. Probably, but I'd want to let the design age a while first. Yep. Imagine the code in the Test vi (but written for a different state machine) being in one of the of the state's Execute method. Yep. I wrapped the above state machine in AQ's Actor Framework so it will spawn a parallel thread. As long as the state machines are written with the appropriate input and output signals there's no reason it can't be done. -
packed project libraries
Daklu replied to PaulL's topic in Application Builder, Installers and code distribution
You're commenting on a different problem than the one I intended to highlight. You're talking (I think) about dev environment behavior. I'm talking about run-time behavior. There's another thread on the topic here. I should have said, "if you persist your objects to disk." QSMs are standard practice too and you know what I think of THAT convention. I do generally keep my libraries in directories of the same name. However, the library's directory tree doesn't reflect the class hierarchy. Each class directory is a direct subdirectory of the library directory regardless of where it falls in the library's code structure. Also, each class directory is flat--I don't create subdirectories to separate the sub vis. I've found a flat directory structure makes it easier to refactor my code since I don't have to move files around on disk as roles change. I've never run into the problem of having a path that is too long.