Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-
I agree, dealing with all the position/configuration information would be a pain. When I'm diffing VIs 98% of the time I don't care about block diagram positions; I just want to what functional changes have occurred. I've been idly wondering about ways to get a text-based diff engine to ignore certain elements, like position tags. It's interesting you mentioned Graphviz. Occasionally I wish I had an editor that allowed me to write certain parts of my applications using text code. Over there (*waves vaguely in the direction of the NI forums*) I suggested opening the compile chain to provide developers with a way to compile code from DFIR instead of from G source. Then the other day I found out you can use Graphviz to view DFIR. Even though it does me no good to write or modify DFIR files directly, perhaps diffing them would be useful? I think I'll have to spend some time looking into that... Yeah, I've heard good things about Erlang. It's one of the long list of languages I'd like to learn, along with Haskell, F#, XAML, Ruby, Lua, Smalltalk, x86 asm, etc. My next language (other than Python, which I'm learning with my daughter over the summer) will probably be Oz. I find the idea of supporting many different programming paradigms intriguing.
-
Do all messages include the address of the sender automatically, or is it only for the subset of messages that are intended to be request/reply?
-

Dealing with State in Message Handlers
Daklu replied to AlexA's topic in Application Design & Architecture
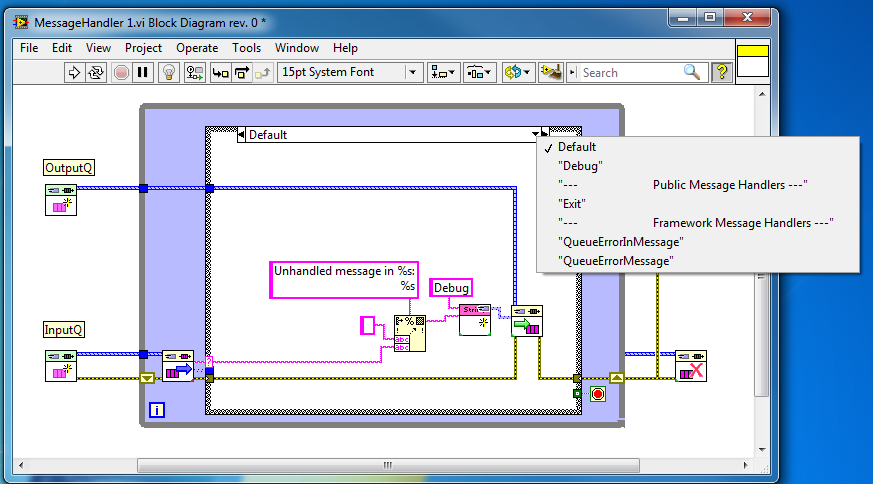
First off, let me say that I believe using state/message or message/state isn't that important a decision. Functionally they both do the exact same thing, though, as AQ pointed out, the decision affects how much code you need to change to add new functionality. Second, I'm surprised so many people favor message/state. State diagrams have a natural state/message relationship so I don't understand why people would want to go through the mental gymnastics to convert the state/message state model into message/state code. With rare exceptions, in my state machines all states have messages handlers, so there is no requirement to be in a certain state to dequeue messages. Messages and states are inherently independent regardless of which paradigm is chosen--both of them choose a specific message handler based on the current state and the message received. Ahh... so if a message is handled the same way across multiple states you combine several states into a single frame. I can see how that would be easier when messages do the exact same thing in many states. As I said earlier, I don't run into that very often, and when I do there are other ways of dealing with it. (As a matter of style, I tend to not group multiple case structure input values into a single frame. I don't think Labview does a very good job displaying them.) I design my state machines so messages that aren't handled in the current state are discarded.* Often my state machines will broadcast state changes so any callers are aware of what state it is in and can react accordingly. I dislike actors sending messages to themselves, so I wouldn't use 1 or 2. Previewing queues leads to all sorts of trouble, so don't do 3 either. (*Whenever a message is discarded I generate an "Unhandled message in <actor loop>:<message name>" debug message. This helps me identify errors during development.) In fact, asking about messages "I don't want to handle in the current state but do want to handle when I'm ready" doesn't make any sense in the way my state machines work. Doing anything with a message--other than discarding it--is handling it. It's not unusual for my state machines to handle messages differently depending on what state I'm in. To answer the intent of your question, if the state machine were to receive a message that indicates it should execute some action in the future, I'd probably set an internal flag to trigger the action at the appropriate time rather than mess around with resending messages. In general I try to avoid 'do something in the future' behavior. ------------------ Here's a copy of my message handling loop template. Essentially I drop this entire loop in each case frame that defines a state. The default case is for unhandled messages. MessageHandler.vit
-
None of those have the same multi-threading or message passing semantics as Labview.
-
Dealing with State in Message Handlers
Daklu replied to AlexA's topic in Application Design & Architecture
Funny. I could use every one of those arguments as reasons why I prefer message handlers inside states. (Perhaps with the exception of #2, 'cause I'm not sure what you mean.) Earlier AQ said he suspects most messages will behave the same in all states. Oddly, I don't find that to be the case at all. Usually each message is only recognized in 1 or 2 states. I suspect the difference has something to do with how I think about and create state machines. Noooooooo...... *cry* Say it ain't so, Greg. ("When a man is in despair, it means that he still believes in something.") State machines don't have the concept of state queues. In fact, you'll notice Alex's state enum isn't on a queue. Sub VIs are one way to deal with a multiple states handling the same message in the same way. Another way that works in some situations is to create a vi containing a message handling case structure for all your common messages and drop that in the default case of the message handling case structures of your states that have a few extra unique message handlers. If the message isn't one of the unique ones, the common handler will process it. Functionally doing that is the same as creating a MessageHandler class and subclassing it for each state. I've done that too, but there's not much advantage to using a single-method class for each state's message handler. -
Actually I was thinking about using vi names for target ID in combination with onion routing. There would be too many long dependency chains for me to have confidence I'm making all the corrections that are necessary. It wasn't a question, just comments on what I initially had some trouble figuring out. I meant the TCP listening loop. I'll try to gin up some diagrams to show how I think about the problem. Regarding the inverted dependency... In LapDog.Messaging, the MessageQueue class depends on the Message class, but not the other way around. Slide #3 of your presentation shows the Msg class having a dependency on the Send class. Originally I though you were implementing MyMsg.Send methods similar to some of the early AF prototypes. However, if I understand correctly that dependency exists only because you built the ability to reply into the your base Msg class.
-
That would be nice to have. It would certainly simplify diffing and merging. Not too long ago I speculated someone who knows scripting well could write a utility to save VIs in an xml format. What you're be doing is creating a text-based version of Labview. Once we can save VIs as text, there's no reason to prevent us from writing VIs using text. I think that'd be an interesting experience. Which current text languages do you think most closely mimic what Labview presents users?
-
Dealing with State in Message Handlers
Daklu replied to AlexA's topic in Application Design & Architecture
I almost always use the second example; that is, I prefer to have the message handlers inside the state rather than the state inside the message handlers. It more naturally reflects how I think about the systems and makes it easier to inspect the code. It has the added bonus that it's dirt simple to add Entry and Exit actions for any state. I've found using Entry/Exit actions greatly simplifies my state machines. -
If you open Get String.vi and replace the StringMessage input control with a Message control (which you must do if you want the downcast to be inside Get String,) you'll end up with an error: LabVIEW Object 'Message in': Dynamic terminal must be of the same class as owner of VI. Since Get String.vi is a member of the StringMessage class, if I want to allow people to override the method it has to have a StringMessage input terminal, not a Message input terminal. Changing the terminal to a Message control breaks dynamic dispatching because the compiler has no way of guaranteeing the object going into the terminal at runtime is a StringMessage object or one of its children. I could add a DowncastAndGet<Payload> to each of the message classes while preserving the ability to override Get<Payload>, but that adds complexity to the api and makes it less approachable for new users. Furthermore, if I did that then DowncastAndGetxxx and Getxxx would have overlapping functionality, and I prefer to avoid that in my apis. Given my own druthers and assuming I had the time and motivation, I would probably write a single vi that downcasts and calls Getxxx for each message type, put them in a separate library, and tie them all together with a polymorphic vi. That way users could easily do 99% of their message payload retrieval using a single vi. (See attached project for example and sample polymorphic vi.) Sure. Suppose I am serializing large amounts of data to send over a network. I can, if I think it is necessary, create a CompressedString class or an EncryptedString class that is completely transparent to the actor that receives the message. I have also, on occasion, created native message subclasses as unit test mocks so I can detect what is happening internally in a component I am interested in. LapDog GetPayload Example.zip
-
Yeah, stateless functions do make using it much easier. I noticed how your TCP vi opens a connection every time a message needed to be sent instead of having an open and closed state. What the overhead associated with that? How frequently would you have to send messages before you would consider having a stateful TCP vi? (Of course, the tradeoff of having stateless functions is that you have to pass *everything* as arguments, which in this case tends to pull the code towards onioning and structural dependencies.) As long as the strings are relatively simple like that I could probably handle it. There were a few things that left me scratching my head until I traced through the code several times: UI.vi claims the message format is TARGET->CMD->PAYLOAD, but the Msg Send function actually converts it to SENDER->CMD->PAYLOAD. Kind of a loose interpretation of the word "target," huh? For the longest time I assumed the Msg Send name terminal was for the target's name instead of the sender's name. (Using the vi name to identify named queues for the message targets would never work for me; I rename stuff all the time during active development and that would wreck havoc on my code.) Mostly due to number 2, I couldn't figure out how you were getting messages from the TCP listening loop to the TCP display loop. Steve Chandler asked me the same thing way back when I first released LapDog. Let's use the StringMessage class as an example. Currently the Get String.vi has input and output terminals for the StringMessage class on the conpane. If I want to do the downcasting inside Get String.vi, the class input terminal has to be of the Message class. However, doing that eliminates the ability to override Get String.vi in a StringMessage child class. In my opinion, that's the kind of feature that is intended to help users (and may in fact help many of them) but ultimately ends up sacrificing power and limits the api's usefulness to expected use cases. I'd fully support anybody who wanted to create a package of add-on vis that do that, but the base api needs remain flexible. I'll try to figure out another way to express what I'm trying to say. I don't think we're on the same page yet. On which part? 100% visible/invisible? Overriding Send? Inverting the Message/Transport dependency?
-
Huh. I thought it was interesting too, but The Oatmeal's response came across to me as really defensive, full of straw men, and guilty of the very things (and to a greater extent) he is accusing the Forbes author of. I fully agree with The Oatmeal's point that Tesla's contributions to modern technology are underappreciated. However, he doesn't have to bend the truth glorifying Tesla or smearing Edison to raise the public's appreciation of Tesla's work. Let his achievements stand on their own merits. After reading both I'm left feeling like The Oatmeal's comic (and response) is the work of someone with an axe to grind and the Forbes article is closer to the truth. I hate it when people attempt to manipulate my opinion by bending the truth, and when I catch them doing it I tend to discount any information I might have obtained from them. So thanks for taking the time to respond to that article The Oatmeal; it gave me a valuable glimpse into your motivations and provided me with the information I need to determine the value of your original comic.
-
Thanks Shaun. It looks like you use a similar technique as the JKI state machine. It's much easier for me to understand when I separate the message ID and payload. Packing everything in a single string hurts my brain too much. Do you use the vi name to name queues as a matter of convention? Uh uh. A SendButDontForward method, not message. Earlier you said, "Other methods of RemoteTCPMessenger can send alternate messages to TCP Client to control it." If the RemoteTCPMessenger.Send method wraps all incoming messages in a SendViaTCP message so the TCP actor will automatically forward them through the network, RemoteTCPMessenger needs other methods to send messages to the TCP actor without wrapping it in SendViaTCP. Either a general purpose RemoteTCPMessenger.SendButDontForward method or unique methods for each public call. (RemoteTCPMessenger.SetPortNumber, RemoteTCPMessenger.Close, etc.) If this means what I said above about making the network layer either 100% visible or 100% invisible to your main app, then I agree. I don't think overriding Send is the best way to get you there though. (Your system inverts the message/transport dependency from what I'm used to, so I may not be fully understanding how the elements are used.)
-
@James I read through what I assume was your presentation from the Euro CLA. There are some things in there I really like and will probably incorporate into my own messaging systems. One thing in particular I am leaning towards is a generalized MessageTransport class. On the other hand, I also found it pretty confusing trying to understand it all just from the slides and some of the terminology is very odd to me. For example, I assume Send.Send method is equivalent to MsgQueue.Enqueue? RemoteTCPMessenger is the message transport for other actors to send messages to the RemoteTCP actor, correct? And in addition to a Send method, which wraps the original message in a SendViaTCP message, you also have another method with a name something like 'SendButDontForward' if the message is intended for the RemoteTCP actor itself? I agree--a TCP connection is too complex to be left to a passive object. You still want a TCP Send and TCP Receive loop, along with some way to monitor what they are doing. My point was that if all your messages are automatically onioned in a SendViaTCP message by RemoteTCPMessenger.Send, you could accomplish the same thing by not onioning the message and instead feeding it directly from the sender to the TCP Send loop. Of course, if you do that then the RemoteTCP actor become 100% transparent, blindly forwarding all messages to the network, which you probably don't want. So to enable sending messages intended for the RemoteTCP actor itself, you added a SendButDontForward message to the transport. Now I not only have to make sure I'm sending the correct messages, but I have to make sure each message is using the correct 'Send' method depending on whether the message is stopping at the TCP actor or going across the network. There are more details the developer needs to keep track of, the api for using the TCP actor is more complicated, and there are more opportunities to make mistakes. What's the upside? If you'll forgive me for saying so, in my opinion the necessity of a SendButDontForward method is a code smell that points directly at the root problem. Creating RemoteTCPMessenger and overriding the Send method to wrap the messages in a SendViaTCP message is a mistake. I think it is more clear to either fully acknowledge the existence of the TCP actor by explicitly wrapping messages destined for the network client in a TCP.Send message on the same block diagram that is sending the message, or completely ignoring the TCP actor's existence by creating a proxy of the network client with an identical interface. (The proxy would handle all the TCP details internally.) Your mix of sort-of-acknowledging it and sort-of-ignoring it is confusing for me and my little brain.
-
No apology necessary. I think there's a lot of value in showing both OO and non-OO ways to accomplish things. (However, I admit to skipping your posts where you just rant about LVOOP. ) You are correct that LapDog.Messaging is a very lightweight wrapper around queues. I've always intended for it to be used as a base for building more complex systems, like the AF or DBL, with specific features each user needs. Arguably, the only unique thing I did with LDM is in the Dequeue method where I converted timeouts and errors into messages, and even that isn't some radical departure from the norm. What? I have to register? Bleh...
-
Long ago I read that if you want to communicate effectively, you should use the vocabulary of an 8th grader. Avoid using obscure words as much as reasonably possible. Even if the reader encounters unfamiliar words, the can infer what they mean from the context. The principle applies to writing code as well.
-
Fair enough. Though I like "onion routing" better. My comment was directed at systems using stepwise routing, not onion routing. You are correct the PrefixQueue overrides the Send method in the same way you are suggesting, but the use case is different. I use the PrefixQueue to send messages from subactors up to managing actors so the managing actor can identify the sender. The managing actor sets the prefix for the branch of its own input queue prior to instantiating the subactor and giving it the queue. If you apply what you are describing to Alex's diagram, you are wrapping messages sent from the managing actor to the subactor--the reverse of what I do with the PrefixQueue. Overriding Send to wrap all messages in a SendViaTCP message is functionally the same as not having a message handler in the TCP actor and automatically sending all the messages over the network. The wrapping serves no purpose. Furthermore, if you automatically forward all messages over the network you give up the ability to send messages to the TCP actor itself. When you do want to send a message to the TCP actor, you have to put conditionals in the Send method to only wrap those messages that should be sent over the network. Now your TCP actor has a MessageQueue subclass customized only for itself. Combining onion routing with dynamic dispatching the Send method adds complexity that, imo, is usually unnecessary. I'm not saying it isn't useful sometimes, just that it seems to use dynamic dispatching because it can instead of basing the decision on the value it adds to the codebase. (Of course, I likely value certain code characteristics differently than you.) Until something requires slightly changing the structure of the application, such as combining functional components into a subsystem and inserting a managing actor. Then you have to revisit everything that sends a message there and change it to reflect the new structure. That can be impossible in some deployment situations. With stepwise routing all the changes are localized. I understand the appeal of onion routing--it is very easy to send messages through the message tree without modifying any code in the tree. When you write a piece of functionality it has to be coupled to *something* for it to be useful. Onion routing couples the functionality to the destination component and every component along the route. I want to restrict the coupling to code that is nearby. To achieve that, you need to use stepwise routing. yED. It's not great, but it's free.
-
Why are LVOOP classes not specified in G?
Daklu replied to jzoller's topic in Object-Oriented Programming
Can you elaborate? I asked someone at NI (who doesn't participate in the forums) about getting DFIR representations of my code but was stonewalled. -
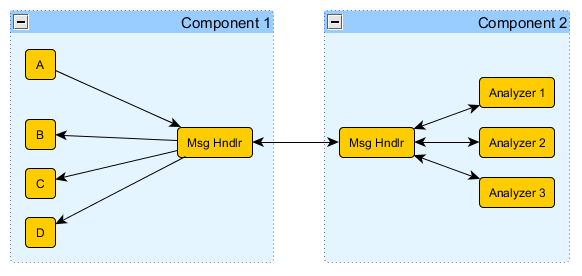
Having to insert a TCP layer into an existing application isn't something I've needed to do much, so I don't spend too much effort considering that particular change request. My customers usually know up front what kind of network support is needed. That said, the TCP layer is one place where I will often use a simple Send message instead of implementing custom messages for the receiver. (In fact my diagram above shows the TCP layer receiving a Send message instead of an EnableMotor message.) It just depends on how the app is structured, what the dependency graph looks like, and what I'm trying to accomplish. When a TCP actor exposes a Send message, other parts of the application have explicit knowledge of the TCP actor by virtue of having to use the Send message. When a TCP actor exposes receiver-specific messages is has a more transparent proxy-like interface. The message sender can send the message without knowing or caring whether the receiver is local or across the network. If the link between the sender and receiver will always be over the network, I often use explicit ('Send' message) TCP actors. If the receiver may or may not be over the network (i.e. unit testing) I'm more likely to build the TCP layer as a proxy and implement receiver-specific messages. Nope, no reason you can't do that. Using a single message dispatcher gives you a star messaging topology. Alex is already using a tree topology, so my answer is oriented towards that. Personally I prefer a tree topology over a star topology because it more clearly defines subsystems and (imo) it is easier to verify the subsystems are not being improperly accessed by other actors. My understanding of the intent of Outer Envelopes is: A sends a message to B in an outer envelope. B does some data processing and sticks the results in the inner envelope. B sends the inner envelope to C, as previously defined by the inner envelope. With the onion routing Alex is doing there isn't (presumably) any processing done at B. It just removes the outermost layer and sends the message on its way. Structurally onion routing and outer envelopes are the same, but according to my understanding the intent is a little bit different. The main advantage to onion routing is you can easily figure out who the receiver is without inspecting the code at each hop. If any of the hops do their own processing then you've just lost that advantage. A new developer is going to have to inspect the code at each hop anyway to figure out what is happening, so all you've done is extend the dependencies through the system. There are very few situations where I might use an outer envelope. Here's one: In this example Comp1.A collects data for analysis. Comp1 sends the data to Comp2 for analysis. After analysis is complete Comp2 sends the results back to Comp1, which then sends the results to B, C, or D. I would consider an outer envelope if all of the following conditions are true: The ultimate destination (B, C, or D) is known prior to sending the data to Comp2 for analysis. Data analysis takes longer than data collection. In other words, it is possible for multiple data packets to be analyzed at the same time. (If only one data packet can be analyzed at a time, I'd likely just use a field in Comp1.MsgHndlr to identify the final destination.) The originator is already dependent on the final destination. I don't want to create dependencies between A and B, C, or D where none existed previously. I want to keep Comp2 free from dependencies on Comp1.
-
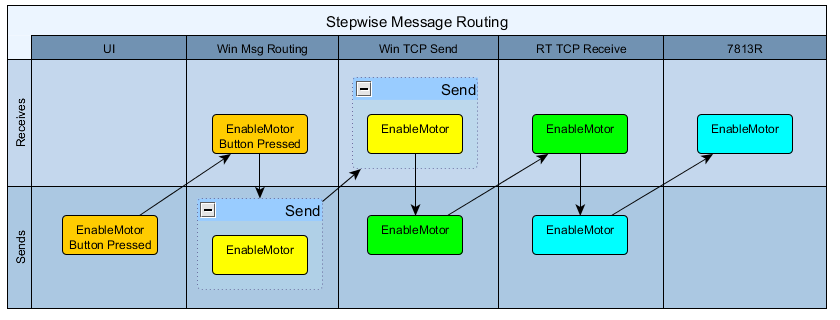
Yep, it's a tradeoff and the "right" decision depends on the value you assign to various factors. My development process is very organic and iterative, so I place a high value on practices that let me refactor easily. Limiting dependencies goes a long ways towards meeting that requirement. Those using a different dev process will probably weight the factors differently. Onion routing does the same thing. The message still has to be "handled" at every step in the chain--you still need a RouteTo7813R message handling case in your RT TCP Receive loop. Functionally, the only difference between onion and stepwise routing is in where the message transformations are defined. In onion routing they are defined by the message sender. In stepwise routing they are defined at each step. In fact, your topology seems to mix onion routing with stepwise routing. Specifically, the WinMsgRouting element adds a wrapper message around the data (SendViaTcp) instead of just peeling off a layer and processing what's left. If I were a new developer on the project, this inconsistency would make it harder for me to figure out how I should implement a new feature. How much onion routing should I use? Where should I use stepwise routing instead? I'd encourage you to use one or the other, but avoid arbitrarily mixing them. ------- As an aside to onion vs stepwise routing, I'll point out that your choice of message names naturally limits your ability to easily replace components. For example, the message RouteTo7813R defines the exact hardware that the software uses. What if you wanted to replace the 7813R with the new and improved 7814R? Is there a way you can rename the message to reflect the destination's functionality instead of hardware model? (RouteToDIO?)
-
I'm not sure I'm following your message topology. Here's a diagram showing what I think you're saying. Is it close? It's only "bad" coupling if it prevents you from easily extending the application in ways that you want to. If the app design fits your current and reasonably expected future needs, call it good and be happy. However, there is value in knowing how to break the structural dependencies you've created by using onion routing. Instead of encoding the entire message route when the message is created as you have done, I prefer to have each loop only know the next step in the message's route: Here, the UI sends a EnableMotorBtnPressed message to the Windows Message Routing loop. The WMR loop knows that when it receives an EnableMotorBtnPressed message, it should send an EnableMotor message to the TCP Send loop. It has no idea (nor cares) what the TCP Send loop does with the message. Using this pattern with each loop along the route to eliminates the structural dependencies. In addition to eliminating the structural dependencies, in my opinion stepwise routing is easier to understand and maintain compared to onion routing. Here are a few examples: 1. I have an app that uses a cRIO 9237 load cell bridge modules. This module uses a 30+ element typedeffed enum to set the sample rate, which is something users need to be able to do. With onion routing the UI component will be statically coupled to that enum. With stepwise routing it is easier to send SetSampleRate messages as DoubleMessage objects and convert it to the enum in the final loop. In diagram 2 above, even though the messages have the same name, the different color indicate they can be unique message objects instantiated from different message classes. 2. Sometimes UI events trigger actions that need data from various other components in order to execute. With onion routing, the tendency is to get all that data to the UI loop so the message can be created and wrapped up. It doesn't matter that the data doesn't have anything to do with the UI, the UI needs it before it can send the message. With stepwise routing each loop along the way can add the data it is responsible for to the message before sending it along to the next loop. As always, there are tradeoffs. The disadvantage of stepwise routing is that it is usually a bit harder to trace a message from source to destination because you have to visit every step along the way. (Search for text is your friend.) With onion routing you can figure out the destination by unwrapping the layers where the original message is created.
-
Nope--I haven't used it yet. I had already defined the FPGA resources for each target in the project and the code was complete when I posted my original questions. If it ain't broke...
-
To follow up some of my earlier questions for future readers: I used to keep copies of all VIs under both targets, but it was a pain keeping them synchronized. On top of that the classes would end up locked because it was being loaded on multiple targets. Now I keep all the RT code under one target and copy the top level VIs to the other target when I need to run the code on that target. It seems to be working quite well. Currently I have my entire FPGA code fully listed under both targets, but I'm pretty much done with that and just haven't bothered cleaning it up. It doesn't have the same problem with locking VIs so there's no motivation to mess with it right now. I suspect I could just copy the top level FPGA VIs to each target and it would work fine. Each FPGA target does maintain its own project-defined resources and build specs. I had thought all symbols were defined in the project and the built-in symbols did some magic behind the scenes. Turns out it is much simpler than that. I discovered each RT and FPGA target has its own list of conditional disable symbols. Setting symbols for each target means I don't have to remember to switch symbol values every time I run the code on a different target. The FPGA_TARGET_CLASS symbol lists the platform model, such as CRIO_9074 and SBRIO_9636. Very handy.
-
I tend to treat the vi description as notes for other developers who are using the vis on their own block diagrams. The connection you're making feels like a stretch. That said, I don't have any strong objections to your proposal. A vi is just a generic container with some built-in features. How you choose to use those features is up to you.
-
<The light flickers on.> I get it. I'm so used to using FPGA resources directly I didn't realize the vi-defined resources have an output terminal. I think making that switch will make things *much* easier. Thanks! The natural follow up question: Am I giving up anything by using vi-defined resources instead of project-defined resources?
-
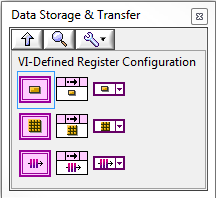
Thanks for the response. I assume you're referring to the "VI Defined Registers?" The problem with these is (as far as I know) they only apply to a single VI. I'm using registers to send triggers between parallel FPGA components and each component is in its own VI. Hmm... I just realized the FPGA resource functions have inputs for the resource name. Using those in my components instead of hard coding the name in the function call might help. The top level vi could inject the correct resource names into each component. Would I need a different top level vi for each target, since each target has to define its own resources?