Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-
Before the summit started I was not the least bit interested in obtaining any certifications. It's fair to say the summit was the only reason I did pursue my CLA. (Though now that I have my own business there are other reasons to maintain it.) What kind of "sponsorship" are you referring to? If it's just someone to pay the fee, I took all of my certification exams free of charge. They were offering CLAD exams free at a local Dev Days, and my local reps comp'd me the CLD and CLA exams for doing user group presentations. Seriously... Architectural Summit >> NI Week.
-

[Ask LAVA] Must Override exists; could Must Implement?
Daklu replied to JackDunaway's topic in Object-Oriented Programming
Yeah. There are a few of us around who keep hoping Generics (and Interfaces) show up in Labview, but not enough to push the idea up far enough on the idea exchange. It's a little discouraging... LVOOP has been stable since 2009, and here we are 3.5 years later with no significant additional object-oriented capabilities. I don't fault NI for choosing their business priorities based on user feedback, but it's still discouraging. That's exactly what I had in mind. Instead of using inheritance to create my StringList class, use composition. Have the StringList methods do the boxing and unboxing and delegate the rest of the functionality to the String class. I fully agree with your judgement that being able to insert objects into a string list will likely lead to problems, and that having that ability does not make for a good api. Using the language from my previous post, it's clear I wanted StringList to modify the behavior of the List class, but in reality it's extending the behavior to work with a different Item type. This is also apparent once you realize there are no non-trivial implementations where a StringList object would run on a List wire, due to the different Item type. (Child object on parent wire = modifying behavior. Child object needs its own wire = extending behavior.) I've considered creating a thin library of native type objects. The problem is that they require too much boxing/unboxing to use with Labview's built-in functions. I'd also have to build object-based versions of all the string functions, all the math functions, etc. Thanks, but I'll pass. I'd like to see NI implement objects for native types, but I won't hold my breath. (To be honest sometimes when I need an objectified native type I'll cheat and just use a message object from LapDog.Messaging.) It's been on there in a couple different variations since 2009. But since it's an advanced feature relatively few LV developers want, it doesn't get the votes to push it up the priority list. I know R&D is aware of the issue and I know it is a hard problem to solve. I don't know if the lack of a solution to date is because it is too difficult or just because it hasn't been prioritized. I've mentioned this on other threads before, but it's very common for new OO developers to overuse inheritance. (I did it alot when I first started and obviously I still fall into that trap sometimes.) It's not surprising why that happens. Pretty much all "Intro to OO Programming" material ever written focuses heavily on inheritance. It leaves the impression that inheritance is what OO programming is all about. I built plenty of bad class hierarchies before I realized the parent-child relationship is actually a fairly restrictive one and my goals were usually better served by using composition. -
[Ask LAVA] Must Override exists; could Must Implement?
Daklu replied to JackDunaway's topic in Object-Oriented Programming
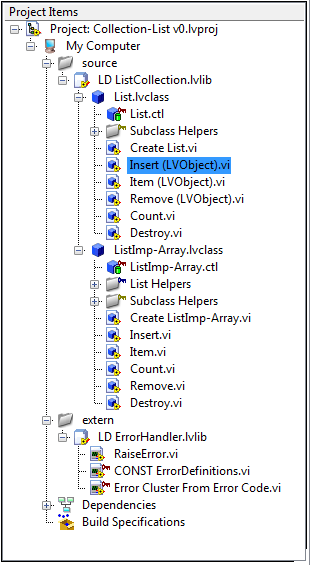
Okay, I found some code from a couple years back we can pick apart. It contains some extra complexities, but it's real code--I wrote it originally intending to eventually release it--so maybe it will give us some more insight into the issue with Must Implement. I'll let you decided if it's close enough to your use case to be worth discussing. The attached project (LV 2009) contains one of my early exploratory attempts at creating a List collection for LapDog. Lists behave similarly to arrays, but they don't allow or require the same level of detailed control so they can be easier to work with. The goal was to permit end users to customize both the implementation (to improve run-time performance) and the interface (to permit strong typechecking) independently of each other. The List class (and its future subclasses) is the interface the client code would use. The default data type for Items in the list is LVObject. I had hoped to be able to subclass the List class to support different native data types so client code wouldn't get cluttered up with boxing and unboxing. The ListImp class (and its future subclasses) contain the actual data structures and implementation code. The default implementation class, ListImp-Array, uses a simple array as its data structure. Subclasses could implement a buffered array, a queue, a hash, binary tree, or whatever data structure necessary to fit the specific requirements. Users select which implementation they want to use when the List collection is created. (Dependency injection FTW.) I don't think the ListImp class is terribly relevant to this discussion. (FYI, List and ListImp do not have a parent-child relationship.) I was aiming for a high degree of flexibility--I wanted users to be able to mix and match an arbitrary type-specific List subclass with an arbitrary implementation-specific ListImp subclass. You can see a few of the List method names have "(LVObject)" appended to them. That's an indicator that those methods either accept or return an Item. These methods are type-specific. Suppose I create a List-String subclass designed to handle string Items instead of LVObject Items. Obviously List-String.Insert cannot override List.Insert because it will have a different conpane. I adopted that naming convention so child classes could create a non-overriding Insert method that won't have a name collision with the parent class. ("List-String.Insert(String)" or something like that.) Does that work? Mechanically, yeah, it works. Does it gain anything? **shrug** I don't think it's a very good solution, but I guess that's what we're discussing. How would you use Must Implement to solve this problem, and are there any better solutions you can think of? (I do have a redesign plan in mind, but I'd like to see what other people come up with.) Collection-List v0.zip [Note: This code is not intended for production use. While I hope to add collections to LapDog someday, the attached project is exploratory code and is not be supported.]
-
To make a parent class, or not to?
Daklu replied to GregFreeman's topic in Object-Oriented Programming
Heh heh... having developed software test tools in a consumer electronics development test lab, I know your pain. For better or worse it is a fairly unique environment most software developers never experience. Churning out test tools that can accomodate both legacy products as well as the latest changes dreamed up by the product engineers is extremely challenging. Throw in the lack of a product spec and test engineers who show up at your door every day asking for "just a simple change," and you either learn to encapsulate everything with even the smallest chance of changing in the future, or you go postal. (Or you create buggy QSM code...) I spent so long *in* that environment I didn't realize just how chaotic and reactionary it was until I left. So while I agree "more code" is the better solution given the business requirements in your situation, in this case I agree with Jack and strongly suspect the OP isn't operating with the same set of requirements you have. -
Okay, that lowers them a little bit, but not completely. There are a few things I'd look into to see if there are potential issues in the design. (Note I'm not claiming your design is bad. Rather these things *may* indicate future trouble spots. They are simply things to consider, not reasons to change the design. Alternatively, if I were in a design review these are the questions I'd ask.) It sounds like your functions may have a large degree of fan-out. (Fan-out in this context = the number of unique sub vis called by the vi.) High fan-out isn't inherently bad, but it may be indicative of a problem. Functions with high fanout are harder to describe and understand. Furthermore, they are more succeptable to requiring changes in the future simply by virtue of having a lot of dependencies. (A change to any of the dependencies may necessitate a change in the caller.) I take it each function in your library has a mostly unique set of static dependencies? (Otherwise the additional overhead to load the unused functions would be imperceptable.) Given that, do these functions really belong in the same library? Labview lacks good support for namespacing independent of library membership, so sometimes I bundle things in a library for the namespacing benefit, even if they would be better off in separate libraries. Still, it's worthwhile to ask the question and understand why they are in the same library. And to be crystal clear, whether or not you can answer these questions to my satisfaction is irrelevant. What's important is that you can answer them to your satisfaction.
-
To make a parent class, or not to?
Daklu replied to GregFreeman's topic in Object-Oriented Programming
I agree with neil, with one minor caveat. Even if you don't implement code for unknown future requirements, it's good to think about them and guesstimate how much refactoring it will take to accomodate them. Minor changes to your original design can sometimes make future refactorings much easier. In your case it is very easy to replace a concrete class with an abstract parent class. (Subclass the concrete class, create empty vis for all the dynamic dispatch methods, change the inheritance hierarchy so the subclass is now the parent class.) Since this refactoring is so easy I don't see that you gain anything by implementing it now. I'll choose a developer who asks those questions over one who doesn't any day of the week. Those questions *need* to be asked. I believe the tendency to overengineer is a natural part of learning the craft of software development. It will decrease as you learn the costs and benefits of various designs. Eventually instead of asking "should I implement x to allow future flexibility" you'll be asking "how hard will it be to refactor to x to allow future flexibility." -
I'm not discounting your experience, but this comment does raise flags. Exactly how big is your library that it would take seconds to load the entire thing?
-
[Ask LAVA] Must Override exists; could Must Implement?
Daklu replied to JackDunaway's topic in Object-Oriented Programming
I know you struck out this comment while you take time to read over the material in the link, but I'll speak to it anyway because I think it raises a couple important points. 1. One of the mantras of OOD is, "encapsulate the things that change." In other words, if it changes, put it in a class. In your NotifyUser example (and presumably the ProbeDisplay example, but you didn't identify any methods so I'm not sure) you are not doing that. Specifically, the method's input types change. If you want to be able to change those inputs, they should be a class instead of a raw data type. 2. What do you mean by, "it's desireable to reuse these abilities through inheritance?" Do you mean you want to reuse those abilities through the inheritance tree, or do you mean you're using inheritance as a mechanism for enabling code reuse? IMO, the former is a natural desire arising from good design. It is reasonable to assume child classes will need to do much of the same VI Server work the parent class does. In these situations I lean towards implementing helpers as protected parent class methods. (Obviously it depends a lot on the specific situation.) The latter, using inheritance solely as a mechanism for enabling code reuse is possible, but (again IMO) far more error-prone. It lures unsuspecting developers into creating child classes simply to gain the benefit of reuse when delegation is the correct solution. When is it okay to subclass for the sole purpose of reusing code? **shrug** Honestly, I haven't articulated a set of rules to follow.[**] A lot of it is just what feels right. But here are some things to think about... Describing two classes as having a parent-child relationship doesn't adequately describe their roles. There are many reasons one would want to create a child class, however, all child class methods can be categorized as one of two things: a) The method modifies the behavior of the parent class by overriding a parent method. We're all familiar with examples of this. (Command pattern, unit test fakes, etc.) b) The method extends the behavior of the parent class by adding a new method. If I have a Dog class with all the usual suspects (Sit, Bark, etc.) I might create a Chihuahua class and add a ShakeUncontrollably method to account for behavior it should have but does not apply to all dogs. If a child class only implements modifying methods, then there is no reason to call child class methods directly, or even do anything with the child class on the block diagram other than create it. You can interact with it entirely through the parent class methods. If the child class implements extension methods the expectation is at some point the child object will move to its own wire to call those extended methods. (Those extended methods cannot be used on the parent's wire, and if you're not going to call them why create them in the first place?) In other words, child classes that modify the parent's behavior are usually accessed through the parent's methods, while child classes that extend the parent's behavior are usually accessed through the child's methods. Is the NotifyUser-Bool class (and the DisplayMessage method) intended to modify or extend the behavior of the NotifyUser class? Your posts aren't completely clear. On the one hand, the method's name and your use cases indicate an intent to modify the parent class. On the other hand, you've clearly indicated you want this feature to apply to non-dynamic dispatch methods, indicating an intent to extend the parent class. And while a child class can both extend and modify the parent class, any given child method can only do one or the other. You've given us examples of how NotifyUser is implemented. Could you perhaps give example code showing how you would like to use the NotifyUser classes? [**Edit] Having thought about it a bit more, my rule of thumb is to reuse code via inheritance only when I need dynamic dispatching. In other words, if I expect the new class to run on the original class' wire, then I subclass. Otherwise I use composition and delegation. It will come as no surprise to anyone that I'm more than happy to talk endlessly about architectural designs. I don't have any examples where I've wanted to change the overriding method's conpane at hand... and any that I dig up I'd be unable to share on a public forum. We'd have to dig into the code details enough for me to be uncomfortable with breaking client confidentiality. I'm willing to do a design review on Shaun's code (assuming he's able to share,) or NotifyUser, or ProbeDisplay, or anything else you can come up with (time permitting of course.) If you want to take it offline and review production code that led to this request we can do that too. And FWIW, often the "correct" solution *is* too burdensome to implement. The benefit of knowing the correct solution is you can confidently pick an appropriate less correct solution for the given situation, and more importantly, you can tell when your implemented solution is going to become a hinderance and refactor it into the correct solution. -
[Ask LAVA] Must Override exists; could Must Implement?
Daklu replied to JackDunaway's topic in Object-Oriented Programming
<off topic> Was it naive implementations of templates, or naive use of the feature? If that was your experience I won't claim otherwise, but it still doesn't make sense to me. First, it will only occur for those classes that are instantiated from templates. I expect relatively few classes would come from templates. (Something less than 100% of them anyways.) Second, if I understood correctly class duplication only occurs when separate modules are invoking the same template with the same data type. It stands to reason that not all modules will create classes from the same template. Third, even 5 copies of a concrete collection class (the most obvious use for generics) in memory is likely to be much smaller in size that the many objects that the collection object contains. I'm not quite sure what you mean by "chained" template, but it did occur to me that these instantiated classes do not have any representation on the file system. The template will, but not the classes created from the template. It's not clear to me how users *should* interact with template-created classes. Should the instantiated class appear in the project explorer? (My gut says no.) Should users be able to override or extend instantiated classes? (Again, my gut says no.) I image instantiated classes would behave similarly to dynamic dispatch method. If I replace a child class on the block diagram with the parent class, all the dynamic dispatch methods change as well. In the same way the wire of an instantiated class would carry information about what to replace the void controls with in each method. When the original instantiated class is replaced with a different one (created from the same template) all the void controls are updated to reflect the data type the new class supports. Anyway, I was just wondering if the prototyped edit-time behavior was anything like that. Now you only have a bijillion-1 issues. Rats. I keep hoping NI is working on them (actually traits rather than interfaces) but if templates are easier to implement it makes sense to tackle them first. (Given the lack of enthusiasm for interfaces at least year's summit I might never see them in Labview.) </off topic> -
[Ask LAVA] Must Override exists; could Must Implement?
Daklu replied to JackDunaway's topic in Object-Oriented Programming
I think it's pretty clear from my post above that I think your problems stem from incorrect class design. But you asked for links, so here is one... Principles of Object Oriented Design In particular, your NotifyUser child classes seem to violate the Single Responsibility Principle (they convert data to a string AND display a message box for the user) and the Liskov Substitution Principle (child objects can replace parent objects without breaking the program's behavior.) Suppose you had a program that used the NotifyUser.DisplayMessage method, and at some point you decided to replace it with NotifyUser-Bool.DisplayMessage. What changes do you have to make? In a properly constructed class hierarchy you can simply replace the class constructor method (and arguments as needed) and everything else will work correctly. But with your NotifyUser design you'll have to go in and change the client code everywhere the DisplayMessage method is called because the message is coming from a different source. (As it must since the original message source is a string.) Now, if your intent is not to replace the NotifyUser object with a NotifyUser-Bool object at runtime, there's no reason to make NotifyUser-Bool inherit from NotifyUser and we circle around to AQ's question: Why have you established a parent-child relationship between these two classes? -
[Ask LAVA] Must Override exists; could Must Implement?
Daklu replied to JackDunaway's topic in Object-Oriented Programming
I fully agree SetMessage followed by DisplayMessage is a less than optimal design path. In this particular case I think the problem is related to your class design and naming. First, NotifyUser implies gaining the user's attention somehow and optionally providing them with information to act on. Currently is has a single method, DisplayMessage, which displays a message box. Presumably a NotifyUser object could have different methods to notify the user in different ways, such as ApplyElectricShock or PlayAudioFile. These methods would have different inputs appropriate for what the method needs. Creating a child class named NotifyUser-Bool causes problems--ApplyElectricShock and PlayAudioFile have no meaning in a boolean-titled subclass created to override the DisplayMessage method. Sure, NotifyUser-Bool can simply not override those methods and use the default parent class behavior. The point is calling a PlayAudioFile method on an object named NotifyUser-Bool is incoherent. It doesn't make semantic sense. If you want to make child classes for each of the possible data types, then DisplayMessage (or other string-based notifications) is really the only method you *can* have in the class. And if that's the case then the NotifyUser class is misnamed. It's not a generalized object for notifying users; it is in fact a very specific way of notifying users. It should be called something like SingleButtonDialogBox. Now, if we have a class SingleButtonDialogBox with a single method DisplayMessage requiring a string input, it makes sense that all subclasses implementing DisplayMessage will also have a string input. After all, they are all going to be (or should be) some sort of dialog box, and dialog boxes require string inputs. Maybe you create a TimedSingleButtonDialogBox class that dismisses the dialog box after a fixed amount of time. But it's still going to require a string input to display something to the user. In short, the class name NotifyUser implies a high-level object that is able to notify an arbitrary user in an arbitrary way with an arbitrary notice. It creates the developer expectation that this object is responsible for any kind of user notification. On the other hand, the DisplayMessage method is too specific. The functionality implied by its name is too far removed from the general functionality implied by the class' name. I suspect it's this gap in functionality and unclarity in what the class is actually responsible for that is causing you difficulty. In particular, you are making NotifyUser (and it's subclasses) responsible for transforming an arbitrary data type into a string, and that responsibility is (imo) better left to someone else. (Such as giving the data object a ToString method.) (I realize NotifyUser is simply an example meant to illustrate the issue, but any example I come up with illustrating this problem leads back to questions about the design.) I fully agree with this. Many of my classes have little, if any, mutable data, and I have found it makes multi-threaded programming much easier. However, I don't think your suggested solution is the right path to take the G language. In my eyes it enables incorrect designs with no appreciable benefit for advanced users. Minimizing mutable state is entirely possible using good programming practices with existing versions of Labview. It's not clear to me how adding a Must Immplement flag on non-existing vis moves towards the goal of minimizing mutability. (As an aside, in the past I've openly wondered how closely related dataflow programming is to functional programming. It's apparent there are similarities, but I don't have enough experience with functional programming to give a fair assessment. It appears you've discovered the same similarities. ) Hmm... I guess my thought is simply the need to flag "Must Implement" is, by definition, an indication the design is flawed. I'm open to being convinced otherwise if you can show me an example of a good design that needs the Must Implement feature. (And to clarify, by "break the behavior of the class" I mean situations where a reasonable developer would have to dig into the parent's source code to discover why the child object is not behaving the way he expects given what he has implemented. I specifically do not mean that the child object will do everything "correctly" as a fully implemented child class would.) Have I ever wished I could change the conpane of overriding methods? Yep. Have I ever created child classes for a specific data type? I'm pretty sure I have. But these were driven by a desire for expediency, not because they were the correct design decisions. -
[Ask LAVA] Must Override exists; could Must Implement?
Daklu replied to JackDunaway's topic in Object-Oriented Programming
I really, *really* want templates for my collections. Boxing/unboxing works, but it's awfully cumbersome and feels entirely unnecessary. Can you tell us what they looked like/how they worked? Were they more along the lines of C# generics or C++ templates? (Just curious.) Doesn't a text language IDE know about the concrete class prior to compiling? For example, if I create an int collection in C# and attempt to put a string in it, the IDE tells me there is an error before compiling. (Come to think of it, I suppose that's just part of the type checking...) Really? Seems like having a few extra copies of a concrete class hanging around in memory would be nearly unnoticable in a desktop Labview app. The program doesn't do anything with those classes. The total number of objects created from those classes is going to be the same regardless of whether you have 1 copy or 5 copies of the concrete class. Isn't a void wire a wire whose type isn't known? -
I know what you mean. Their by-ref nature is kind of a PITA in Labview. In my IMAQ app I had to pipeline the image processing and I ended up copying the image from one buffer to the next for each stage.
-
Eliminating unnecessary wire bends is important, but I'd like to call attention to something on Hoovahh's block diagram that really helps readability. Notice how all the file I/O vis are (mostly) aligned horizontally and the sound vis are (mostly) aligned horizontally at a different height. IMO spatially separating the vi "families" like this goes a long ways towards helping me quickly understand what is happening in the vi.
-
Another LAVA member joining the CLA club!
Daklu replied to Roderic's topic in Certification and Training
-
Like Todd said, if you're not branching the HAL wire at all putting that info in a DVR doesn't save you any memory. All that HAL data still needs to be stored in memory somewhere. Having a 4-byte reference instead of a multi-kb data structure on the wire only saves you memory if copies are created. If you are branching the HAL wire there are times when LV will make copies of the data. However, *even if* you are creating data copies, 200 i/o channels with associated scaling and calibration info isn't that much data for a modern computer to copy. I'd be surprised if it was noticable.
-
This is by design. In Labview, child classes *never* extend the private data of the parent class--they have their own private data. Parents can make their private data available to children via accessors, but there is no way for a child class to change the set of data types the parent class contains in its private cluster. If you want the child classes to be by-ref also, the child class should have its own DVR refnum in its private cluster to maintain the child class' data. FWIW, I almost never build classes with built-in by-ref behavior. I've found I have much more flexibility if the classes are by-value, then if I need to interact with one in a by-ref way, I let the application code put the object in a DVR and pass that around.
-
I agree with Mikael and Stephen; there's nothing wrong with putting an object in a DVR inside another object. However, I also agree with Todd and James; based on what you've told us I don't see how adding the DVR uses less memory and the action engine example you posted should work fine without the DVR (assuming your vi is set to non-reentrant.)
-
[Ask LAVA] Must Override exists; could Must Implement?
Daklu replied to JackDunaway's topic in Object-Oriented Programming
Read the thread. Didn't follow everything, such as... Can you explain what you mean by "These concrete instances fundamentally represent functional programming...?" And do you really mean *functional* programming, or do you mean procedural and/or imperative programming? -------------- Overall I agree with MJE and Rolf in that I don't really see the point of a must-implement flag. Or at the very least, I'm not convinced the benefits of having it are worth the extra restrictions it imposes. It seems like an overly-clunky way to communicate intent to other developers, and borders on defining style over function. Taking the initialize() example, why do you want to impose a compile time requirement that subclasses implement some sort of constructor method? Wouldn't a class with pre-defined default values for its fields be functionally indistinguishable than a class constructor that takes those same values as input parameters? How is forcing a developer to implement an initialize() method when one isn't needed beneficial? The serialize() example is a little confusing to me. You say Logger expects its children to serialize, but where does this expectation come from? It's not a functional requirement--Logger can't call child_serializer.vi because it doesn't exist and it's not accessable through dynamic dispatching. Therefore, they are not really Logger's expectations; they are the Logger developer's expectations as to what other developers might want to accomplish by subclassing Logger. I can't even predict all the reasons I might want to create a subclass, much less predict why others might want to create a subclass. I used to include all sorts of protections to "help" others do things the right way, but for the most part I don't do that anymore. IMO it gets in the way far more than it helps. I rarely use Must Implement, and even more rarely use Must Call Parent. I try to restrict their use to situations where not using them will break the behavior of class, not just because that's how I think the subclass should be implemented. Setting aside for the moment your desire to use language constructs to impose your expectations on class users, you've already pinpointed the issue behind all of these problems. Regrettably Labview doesn't allow classes in the same ancestoral line to have methods with identical names unless they are dynamic dispatch.** If NI can fix that (and I really hope they do) I think it would relieve a lot of the issues you are describing. <minor tangent> **This bug feature characteristic of Labview actually has significant impact on my ability as a reuse code developer to guarantee backwards compatibility of my packages. We all know there are certain things you shouldn't do to the publicly available methods of a reuse library if you want to maximize compatibility. You don't remove or reorder items on the conpane, you don't change fully qualified names, etc. Here's another one to add to the list I discovered last year while I was trying to get people to understand the risks of VI package conflicts: Don't add any (public or private) methods to an existing class that is, or has descendents that are, publicly available to end users. Why? Consider LapDog Messaging. It's been out for a couple years now and a few people have used it in projects. Suppose I do a minor refactoring and move some of the code in the ObtainQueue method into a new, private _initQueue method. I haven't changed the API's public or protected interface at all, just done some refactoring to improve sustainability. It will pass all my unit tests and any unit tests others choose to run on the class to verify behavior. However, if a user happens to have used a previous version of LapDog Messaging, subclassed MessageQueue, and implemented a method named _initQueue, then any code that uses that subclass won't compile until the naming collision is resolved. Unfortunately name collisions aren't always resolvable and I'm left without any good solutions. </tangent> I'll go out on a limb here and claim this is a mistake. Must Override and Must Call Parent are requirements that only have meaning in the context of overriding a method. It makes no sense to flag a static dispatch method with Must Override, and it's equally nonsensical to flag a child method with Must Call Parent when there's no parent method to call. My guess is if you find yourself wanting to enforce Must Override or Must Call Parent rules on non-dynamic dispatch methods, something in your design isn't right. -
Sequencing alternatives to the QSM
Daklu replied to PHarris's topic in Application Design & Architecture
Ahh... my reputation preceeds me. I do often use a true state machine (I call them "behavioral state machines" to help differentiate from the QSM) in places where others would reach for a QSM, but that's mostly a matter of personal preference and situational considerations. I'm not sure I would use a BSM for a general purpose sequencer in that situation. An interruptable BSM still follows the same basic sequence loop (BSL) and there are other BSL implementations that are lighter weight. Several years ago I did prototype a general purpose sequencer based on the composition pattern. The idea was to mimic Test Stand in that each step in the sequence could be a single fine-grained step or it could be a subsequence that contained several steps and/or additional subsequences. I don't remember where I left it. At the time I was building lots of sequencers. Since then... not so much. -
Sequencing alternatives to the QSM
Daklu replied to PHarris's topic in Application Design & Architecture
Apologies for the late response. I've been neck deep in real life stuff (like keeping customers happy so I can pay the bills) and haven't been on LAVA much the past several months. Interrupts don't exist in labview, or as near as I can tell, in any data flow language. However, modern event driven user interfaces require some sort of mechanism for interrupting a process the user wants to cancel. All solutions essentially boil down to the same thing... Basic Sequence Loop 1. Execute a functional step. 2. If user requested interrupt, exit. 3. Else, goto 1. The one exception is Shaun's method, which pretty much just executes (in the criminal justice sense, not the computer science sense) the running vi when it's no longer needed. Depending on what your process is doing, that may not be a safe thing to do. Also, assuming you only need one instance of the process, dynamic launching and using VI server (Control Value:Set) to interrupt execution doesn't buy you anything over just setting up a parallel loop in the original vi. It's still using an execute-check loop. All you're doing is add complexity and latency. There are lots of way you can implement the basic sequence loop. If you look you can see the example you linked to on the other thread and ned's example are just different implementations of the basic sequence loop. The details are different but conceptually they are the same. In general, the process I use for interruptable sequences plays out something like this: 1. User clicks button to execute sequence ABCD. 2. Controller receives message from UI to start sequence ABCD. 3. Controller sends "Do A" message to execution loop. 4. Execution engine does step A and sends "A complete" message to controller. 5. Controller sends "Do B" message to execution loop. 6. Execution engine does step B and sends "B complete" message to controller. 7. Controller sends "Do C" message to execution loop. 8. Execution loop starts doing step C. 9. Controller receives "User Interrupted" message from UI. 10. Execution loop finishes and sends "C complete" message to controller. 11. Controller, understanding that the user interrupt takes precendence over the remainder of the sequence, doesn't send the "Do D" message, effectively interrupting the sequence. The responsiveness of the application to the user's interrupt is directly related to how fine-grained each functional step is. If you have a functional step that takes 5 seconds to execute, then the use might have to wait 5 seconds after hitting the cancel button before control is returned to him. Usually I have several levels of abstraction between the UI and the steps that are executed. That allows me to keep the high level code coarsely grained without imposing extended waits on cancel operations. [Edit] BTW, I don't *think* I've said I wouldn't ever use a QSM... at least not since '08 or whenever I first started ranting about QSMs. The QSM design is exceptionally good at one thing in particular: time to implement. If you want to test some sort of functionality while spending as little time on it as possible, the QSM is probably your guy. I just make it very clear to the customer that this is prototype code and it will be thrown away when the prototype is complete. It is not the start of the application and we will not be adding new features to it.- 17 replies
-
- 1
-

-
- qsm
- queued state machine
- (and 2 more)
-
So I'm asking... suppose you could write a method of a class and in that method declare "this is data that is local to this VI but it becomes part of the state data of the object overall such that if the wire forks, this data would fork too." Nope, haven't ever run into a situation where I wanted that functionality. Can't think of one either. I strongly suspect that any situation where I would want that kind of functionality would be better solved by refactoring that method into it's own class. That lead me in the direction of "What if data is not static on a wire? Suppose it were actually doing something as it traveled down the wire?" In other words, package up a still running state machine and send it, as it is running, down a wire to be transformed. Passing around code components *is* something I have wished for before. I don't remember the context that led me to want it, but I'm pretty sure I was wanting to send an entire executing component over a queue. We can send a running state machine down a wire right now to some extent using vi references, but it requires more framework and coordination than I've ever felt like writing. Still, I think you would have to be very careful how this is presented conceptually. Changing the "data on a wire is immutable" axiom opens the door for all sorts of confusion. Adding more language elements (vi, while loop, .lvlib, etc.) to the list of first class objects Labview supports is somewhat less confusing.
-
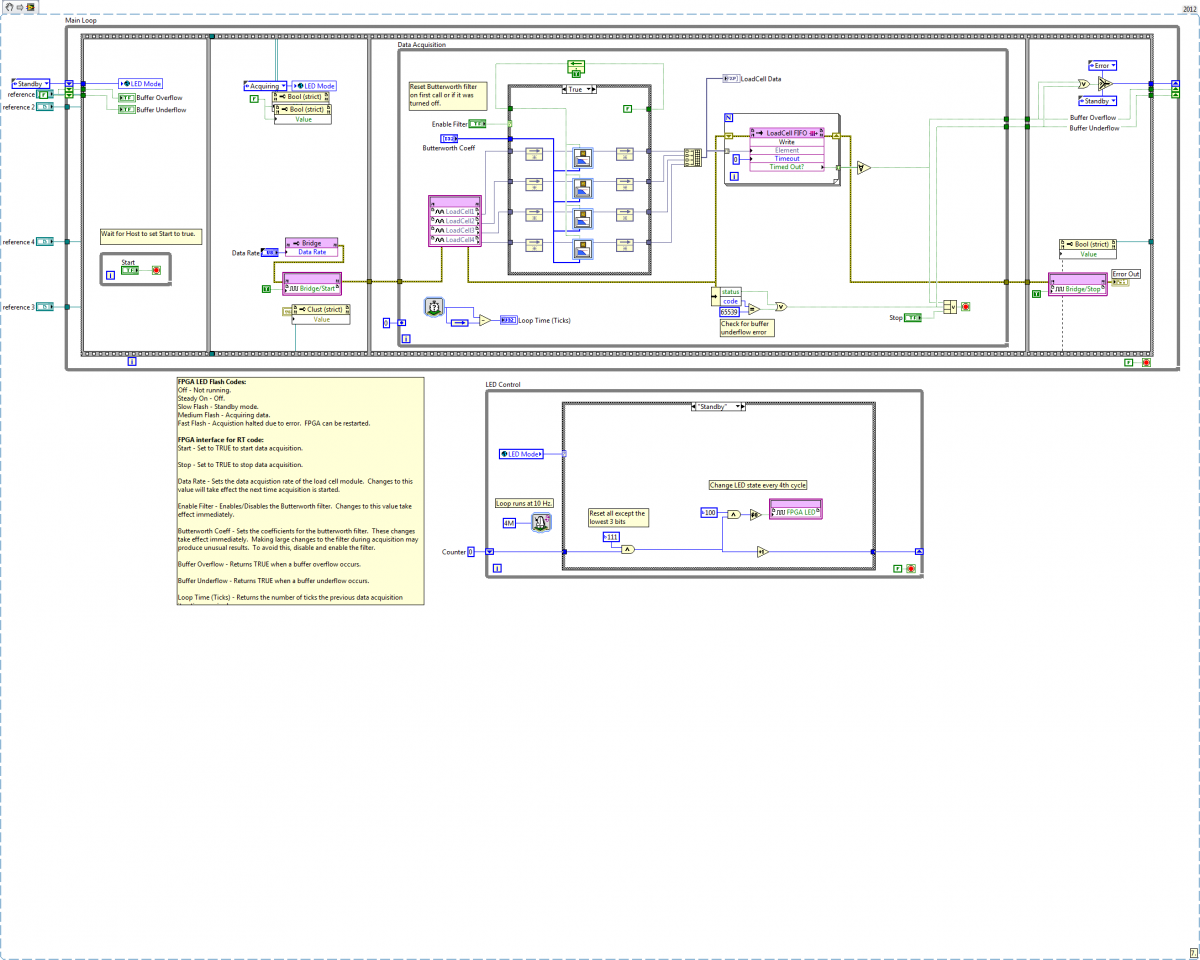
Sorry for the delayed response. I was out of town for two weeks and returned home to a self-induced pc meltdown. Thanks for the tips James and Ryan--it was a big help in getting the fpga to behave consistently. Neil is correct, the image and attached vi are of the fpga vi.
-
[Posted to NI's forums yesterday, but no response yet. Cross-posting here to expand the audience--this is time critical.] I have the attached fpga code (cRIO 9074) that works as intended... most of the time. (Open the png in a new browser window to view it.) Sometimes I'll start up an rt vi written to interact with the fpga vi and the fpga vi just doesn't respond. Specifically, setting the value of the Start button from the rt side doesn't do anything. I suspect it's something I'm doing wrong rather than a bug in Labview. It's apparent the deployment relationship between fpga and rt code doesn't work the way I think it works, but I'm not sure where the model I've mentally created differs from what it really does. Questions: 1. I've written the fpga vi with the idea that it runs continuously and the rt code can connect to it dynamically. My intent is to load the fpga vi onto the crio, and have different rt vis interacting with it depending on what I need. We're still in the R&D phase, so when I need to use a different rt vi I stop the previous one and click the run button in the new one and it gets deployed to the crio. Sometimes this works fine, other times the fpga Start button doesn't seem to be working and I'm stuck in Standby mode. Is this kind of dynamic connection a valid way to use fpga vis? 2. The fpga vi is written so the fpga led on the crio flashes anytime it is running. Sometimes when I stop the rt vi the led stops flashing, indicating the fpga vi was stopped. I don't understand why this is happening. 3. The Open FPGA Reference vi has three different linking options. You can link to the build spec, the vi, or the bitfile. It's not clear to me exactly how, or even if, these options change the runtime behavior of the vi. Do I need to write my code differently depending on which of those three options I select, or are they options designed to allow developers to use the edit-time workflow that suits them best? (i.e. If I link to a build spec, I can change the top level vi in the build spec, whereas if I link directly to a vi I need to change the Open FPGA Reference configuration--a source code change.) 4. I've read that the Open FPGA Reference vi includes the bitfile in its saved data, and the bitfile is deployed to the fpga when that vi executes. Does that happen regardless of which of the 3 linking options you select? 5. If 4 is true, that implies there is no way to start an rt vi that interacts with an fpga vi that is already running, since the Open FPGA Reference vi will overwrite the fpga code currently executing. Is that correct? 6. There are several places where one can choose to "Run FPGA vi when loaded." The build spec, the Open FPGA Ref configuration, and the fgpa vi's properties ("Run when opened" option) are three I can think of off the top of my head. When those setting conflict, how do I know which setting will take precedence? 7. How do the reentrancy options on a top level fpga vi affect it? Help files mention rt vis, but not fpga vis. Intuitively it doesn't seem like it should do anything since the vi is only being called once. I have lots of other questions too, but they're somewhat dependent on the answers to these questions, so I'll stop for now. TIA, Dave FPGA Main (DMA).vi
-
From the comments on this thread, it sounds like NI doesn't want to include any user-written vis as part of LV unless NI owns the copyright. All the common licenses currently used are inadequate. Giving NI ownership implies transferring the copyright and is a different legal issue than granting someone a license. We know dual licensing is possible. What about dual copyrights? I own the copyright to LapDog simply because I wrote it. Can I also grant those same LapDog copyrights to NI while maintaining them for myself, or would we have to enter into some kind of partnership? I dunno... Another aspect is liability. If NI were to start shipping vis I wrote as part of base Labview, I sure as heck don't want to be legally responsible for them. As long as I own the copyright on the code distributed by NI, my gut sense is I will be exposed (however slightly) to lawsuits by third parties claiming damages. Whether or not they win is beside the point--I don't want to get dragged into a lawsuit at all. That's a battle I'm not interested in fighting.