Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-

Actor-Queue Relationship in the Actor Framework
Daklu replied to mje's topic in Object-Oriented Programming
Because (I believe) Stephen's focus was to create a framework that prevented users from making common mistakes he's seen, like having someone other than the actor close its queue. I'm not criticizing his decision to go that route, but the consequences are that end users are limited in the kind of customizations they're able to easily do. Lack of extendability and customizability. More generally, it forces me to adapt how I work to fit the tool instead of letting me adapt the tool to fit how I work. It encourages a lot of static coupling. Requires excessive indirection to keep actors loosely coupled. Somewhat steep learning curve. There's a lot of added complexity that isn't necessary to do actor oriented programming. It uses features and patterns that are completely foreign to many LV developers. Ditto. I've talked to several advanced developers who express similar frustrations. This is typically only an issue when your message handling loop also does all the processing required when the message is received. Unfortunately the command pattern kind of encourages that type of design. I think you can get around it but it's a pain. My designs use option 5, 5. Delegate longer tasks to worker loops, which may or may not be subactors, so the queue doesn't back up. The need for a priority queues is a carryover from the QSM mindset of queueing up a bunch of future actions. I think that's a mistake. Design your actor in a way that anyone sending messages to it can safely assume it starts being processed instantly. Agreed, though I'd generalize it a bit and say an actor should be able to specify it's message transport whether or not it is a queue. I'd do it by creating a messaging system and building up actors manually according to the specific needs. (Oh wait, I already do that. ) That kind of customization perhaps should be available to the developer for special situations, but I'd heavily question any actor that has a timeout on the dequeue. Actors shouldn't need a dequeue timeout to function correctly. -
[Ask LAVA] Must Override exists; could Must Implement?
Daklu replied to JackDunaway's topic in Object-Oriented Programming
The implication of this statement worries me. To reiterate some of the things I said in posts 78 and 81, asserting that it's always better for an error to be found at compile time instead of runtime ignores the cost (in terms of language flexibility, ease of use, etc.) of actually making the error detectable by the compiler. As a thought experiment, imagine a language in which every error is a compiler error. Is it safe? Does it help prevent users from making mistakes? Yes on both counts. Is it a "better" language? That's a subjective evaluation, but I think most people would get frustrated with it very quickly and switch to a language with more flexibility. (For the sake of moving the discussion forward, I'll assume you agree at least sometimes it is preferable to defer error checking to runtime, even if it is possible to change the language to eliminate that runtime error. I trust you'll let me know if you disagree.) The question is one of cost vs benefit. How much value are we giving up to get compile time checking and how much value are we gaining? Based on statement above, it appears you are assigning a very high value to the benefit of making this a compiler checked feature. I think you are over-valuing it. Let me explain... First, I don't think categorizing a contract violation as a runtime error or compile time error is completely accurate. It's really a load time error. In principle, with caller declared contracts the error can be detected as soon as the code declaring the contract (the caller) and the code under contract (the sub vi or child classes) are loaded into memory at the same time. There's no need to write extensive test code executing all the code paths. Depending on the structure of the application, the error could be discovered during editing, building, or execution. In most real world use cases the error will be discovered at edit time because most users have their entire code base already loaded into memory. Second, the use cases where the error isn't discovered until execution are advanced architectures--modular applications that dynamically link to dlls or vis, like this: Advanced architectures are built by advanced developers. These are not the people you need to worry about shooting themselves in the foot. That's not to say we don't do it occasionally, but we're typically looking for more flexibility, not more protection. Seems to me advanced developers are the ones most likely to get frustrated by those restrictions. So what benefit does parent declared contracts bring to the table that caller declared contracts don't offer? Guaranteed edit time contractual errors isn't the ideal NI should be shooting for when the additional use cases captured by that guarantee (compared to the non-guaranteed version) are few in number, used by advanced developers, and may not be wanted in the first place. Does guaranteed edit time contractual errors save months of runtime errors? Only in the rare case where a developer creates and releases a plugin without even loading it into the application it's designed for. That's not a bug, that's negligence. If NI is trying to protect that developer from himself I'll really get worried about Labview's future direction. (I assume in v2.0 the requirements have tightened since all the child classes would still work fine if the requirements were loosened.) In this scenario you're still not gaining much (if anything) by having parent declared contracts. Come to think of it, parent declared contracts don't prevent runtime contract violations from occurring. The violation can't be detected until each child class is loaded, and in the case of dynamically called child classes it's possible the child class was never loaded into the dev environment after editing the parent class' contract. Oops, runtime error. You can't turn that into a guaranteed edit time error unless you're willing to make parent classes automatically load all children. If you're really hell-bent on throwing edit time errors for the plugin developers in the pattern above, I could get behind an implementation that uses a separate xml or text file to publish the contractual terms the parent class offers to its caller. Call it something like PlugIn.lvcontract, put it in the same directory as the class, and load it when the class is loaded. Maybe each child class has their own .lvcontract file and they are checked against the parent's .lvcontract file to make sure the child offers terms that are compatible. Advanced users get the flexibility of choosing whether or not they want to enforce the same requirements the original developer thought were necessary, and casual users get the reassurance of edit time errors. Win win.
-
FYI, Sunday is March 3, not March 4. (I should know... March 4 is my birthday.)
-
[Ask LAVA] Must Override exists; could Must Implement?
Daklu replied to JackDunaway's topic in Object-Oriented Programming
There is no clear line separating "too much contract" from "not enough contract." Any contract preventing a class user from doing what they want to do is too much, and from that user's perspective the parent class designer was overzealous. -
[Ask LAVA] Must Override exists; could Must Implement?
Daklu replied to JackDunaway's topic in Object-Oriented Programming
The only advantage to having the restrictions in the parent instead of the calling code is that it guarantees a compile error instead of a runtime error. In every other way it makes more sense to put the restrictions in the code that actually requires the restrictions--the calling code. Is gaining compile time checking worth unnaturally twisting around the requirements so they flow up the dependency tree instead of down? Personally I don't think so. It comes across as a shortsighted solution to an immediate problem rather than a well-planned new feature. -
[Ask LAVA] Must Override exists; could Must Implement?
Daklu replied to JackDunaway's topic in Object-Oriented Programming
I still don't understand why you want to impose a must implement requirement on Construct. Why does your parent care if n child object was created in a Construct vi or with an object cube and a bunch of setters? Either way is valid. Using a Construct vi is entirely a stylistic decision. -
[Ask LAVA] Must Override exists; could Must Implement?
Daklu replied to JackDunaway's topic in Object-Oriented Programming
I'm not sure you're understanding what I'm trying to say, so let me try to explain it another way... I think you're saying having the ability for the parent class to dictate arbitrary requirements to the child classes is necessary and this ability is intended to be used in situations the parent class acts purely as an interface for child class implementations and the context in which the parent class is used is known. i.e. I'm writing the parent class *and* the only code that will ever call the parent or child classes. Now, suppose those arbitrary requirements were declared in the calling code instead of the parent class. What functionality has been lost? Since the calling code defines the restrictions for all methods that are executed and none of the child methods will be executed outside of the calling code, any violations in child method implementations will be caught. I expect many times the calling code and child methods will be in memory at the same time while editing, so it's conceivable that users will not even lose much in the way of compile time checking. If calling code declarations provide the same protection capabilities as parent class declarations, but also provide more flexibility, why is that not a preferred solution? Earlier you mentioned your goal is related to Liskov but not to DbC. Theoretically I can see there may be value in providing a way to enforce LSP. However, the functionally you're proposing is an incomplete and limited form of DbC. If you're going to start down the path of DbC, why not design it in a way that makes sense from a DbC perspective? (In some ways this feels like the the ability to inline sub vis. Currently the only option for inlining rests with the author of the sub vi. That implementation feels backwards to me. I'd much rather the calling code be able to dictate which sub vis it wants to inline. I'm often frustrated during LapDog development because I'm being forced to make design decisions that are better left to my users.) See, intuitively that doesn't make sense to me. It's certainly not the way I think about things. No class (or sub vi) ever declares what it is to be used for. It only declares what it does, and it does that in code. What it is used for, or how it is used, is entirely up to the person writing the calling code, not the person designing the class. There's a correlation between the two, but I don't think they are identical. LOL. If you want to say I'm wrong that's okay. I've been wrong in the past and I'll be wrong in the future. Consensus appears to be I'm wrong about this. I may very well be wrong, but I haven't seen anybody address my point. I don't think I claimed contracts made the library "harder" to use. I did say it's less "usable," but I meant usable in terms of flexibility and places it can be used successfully, not usable in terms of how easy it is to use the API. That is an interesting take on it. Unsurprisingly I don't fully agree with it. IMO the best interfaces are those that are easy to use and easy to extend to work in scenarios the developer did not originally anticipate. The second to last paragraph contains an extremely important idea: The best way to prevent incorrect use is to make such use impossible. If users keep wanting to undo an irrevocable action, try to make the action revocable. If they keep passing the wrong value to an API, do your best to modify the API to take the values that users want to pass. They state you should make incorrect use "impossible," but notice how they make it impossible. It's not by imposing restrictions on the interface user and forcing them to conform to your way of thinking, it's by changing your interface to allow the user to use it in the way they want to. -
[Ask LAVA] Must Override exists; could Must Implement?
Daklu replied to JackDunaway's topic in Object-Oriented Programming
I wasn't clear enough. If a guarantee is explicitly declared in the parent class, then yes, child classes should have to adhere to it. I'm questioning the (perceived) assumption that the guarantee belongs in the parent class in the first place. You've been phrasing it in terms of "the parent class providing guarantees to the caller." I agree there are certain times that ability may be useful--i.e. plug-in systems. More generally you're talking about "the callee providing guarantees to the caller." Guarantees are a first step towards contracts. But whereas guarantees give callers a choice to "take it or leave it," a contract system where the calling code defines its requirements and the parent class (and subclasses) tell the calling code whether or not they meet that requirement is more of a "let's negotiate at see if we can work it out" arrangement. Historically NI has been pretty good at putting out features that works well for 80% of the developers. Unfortunately, often the feature is useless for the remaining 20% of us because there's no way to tailor it to meet our specific needs. I'm concerned your emphasis on guarantees will lead to another 80/20 feature whose flexibility is permanently limited by backwards compatibility concerns. I know what I am suggesting is much larger in scope than what you are talking about and Labview may never support a contract-based programming. I'm just saying if you're going to go from A to B, make sure the path continues on to C. We users are a fickle bunch. When a new feature comes out we like, we tend to want to use it in ways NI didn't expect. -
[Ask LAVA] Must Override exists; could Must Implement?
Daklu replied to JackDunaway's topic in Object-Oriented Programming
[Grrr... -1 for web-based editors. ] Give a guy a chance to respond to respond to a cross-post, wouldja? Besides, we want you at the summit, not in the hospital recovering from a stroke. Yes, I agree that is the difference in viewpoint. I thought I made myself clear in my post originally challenging you, 1. This is probably true in situations where the child class is written with the intent of replacing the parent class in a fully functional system. 2. Also probably true as long as the child is intended to replace the parent in a fully functional application. as well as here, I can't think of a single case where [using] either of those flags... is appropriate for all potential subclass situations. and here. [*Assuming the goal is to replace the parent object with the child object at runtime. If that is not the intent, there's no reason to mimic the parent's behavior.] ... Does it sometimes make sense to be able to strictly define some set of arbitrary requirements? Probably... On the other hand, as flintstone pointed out strictly defining the number of clock cycles it is allowed to consume eliminates the possibliity of creating a child class and using it in a system with different requirements. ... What if I want to use STL in a system that doesn't have those performance requirements? My persistence was because I was trying to understand why you continued to appear to claim it is universally better for the parent class to impose restrictions on child classes when (imo) that clearly isn't the case. Composition works sometimes, but not always. Suppose your application supports plugins that adds two integers and truncates the sum to 0-10, so you define that requirement as part of the parent class. Users can create whatever child classes implementing the functionality in any way they like as long as they adhere to that requirement. Now I'm building an application and I really like that feature, but my app needs the sum truncated to 0-20. Creating a new class composed of one of the child classes doesn't help me much. If the inputs are 7 and 2 I can delegate to the child class and all is good. If the inputs are 7 and 6 I cannot. I have to write code to detect whether or not I can use the child class on the inputs, AND I have to duplicate much of the code in the child class to handle situations where the sum equals 11-20. That's what I meant when I said more restrictions equals fewer places it can be used. An interface that declares "I will return the value of Pi in < 100 ms" will always be useful in fewer places than an interface that declares "I will return the value of Pi" without giving a timing specfication, because the developer using that interface can create an implementation that meets their specific timing requirements if one isn't readily available. Of course there's always a tradeoff between flexibility and specificity. I could create a "Function" interface with two variant inputs and a single variant output, and then create subclasses for every operation from Add to Concatinate String. Clearly that's moving too far in that direction. From my perspective the next big productivity jumps are going to come when NI implements things like Interfaces/Traits and Generics/Templates. Implementing the ability for a parent class to impose an arbitrary requirement on a child class strikes me as an interesting idea with somewhat limited real-world benefit. -
[Ask LAVA] Must Override exists; could Must Implement?
Daklu replied to JackDunaway's topic in Object-Oriented Programming
[Edit - cross-posted with AQ] Perhaps. If so, I apologize. I assumed a computed Pi function's execution time would be normally distributed and somewhat predictable, but longer than the constant Pi function's execution time. Are you assuming the execution time is unbounded and/or entirely unpredictable? Agreed, but I'm not following how this relates back to the Pi function's execution time. Agreed. This function is clearly violating the contract of returning Pi and it is going to cause problems for users. If there were a compiler enforcable contract to "only return the value of Pi" that potential error would be quickly found. However, if I'm writing a Pi function for others to use, is there significant value in the ability to specify an enforcable contract that states, "this function will execute in < n ms and only returns the value 3.14159...?" **shrug** Obviously I'm skeptical. We're talking about code fulfilling a contract as if they are separate things. They're not. If I'm building a library and want to make certain guarantees to the calling code, how do I decide what guarantees I should publish? Say I publish an "execute time < n ms" guarantee. Okay, that's helpful for those who need an execution time guarantee, but it doesn't help those who need a memory use guarantee. So I publish that guarantee too. Where does it stop? Eventually I publish so many guarantees I've effectively defined the implementation. Ultimately the implemented code *is* the contract, it's just a question of which parts of the contract I'm going to publish to the caller. In order for the library to supply the caller with meaningful contractual guarantees beyond the conpane, I have to know details about what guarantees the calling code is interested in. I can't predict that--it's going to be different for every user and every app. Every guarantee I publish that the calling code author doesn't need imposes unnecessary restrictions on that person's ability to create subclasses for their specfic situation. In the abstract I can see how allowing a parent class to impose arbitrary contractual requirements on itself and its subclasses might be necessary in one specific situation--when an app calls unknown and possibly hostile sub vis. (i.e. Apps that allows third party plugins and defines a parent class as the interface for the plugins.) The app author wants to make sure the plugins do not break the app. Is that the best way to achieve the goal? I dunno... I'm still skeptical. Off the top of my head I think it would be better to structure the app in a way that sufficiently segregates the plugins. (i.e. Launch a killable actor to host each plugin and validate the plugin's return values if there's reason for concern.) I generally prefer static typing as well, but as a general statement this is (imo) taking it too far. Most vis I write have some limited set of values that is strictly smaller than the set of all possible values of the native datatype. In other words, if there's a string indicator on an output terminal my vis don't usually have the ability to return every possible combination of string characters. They are only able to return some subset of them. There is clearly a restriction on the return value, should it be a unique data type? If every unique subset of the native data types is a new data type in itself you'll either end up buried in type conversion code or you'll rarely be able to reuse code. More types does not necessarily equate to a better language. Can you explain this a little more? If you are creating a framework for other developers to use, why do you need to specify "Do not return something outside the range m-n?" You implemented the framework code, surely you know what values your code is able to return? -
[Ask LAVA] Must Override exists; could Must Implement?
Daklu replied to JackDunaway's topic in Object-Oriented Programming
Another thought that occurred to me towards the end of the lengthy editing session but for which I didn't want to go back and rewrite the entire post: Somehow I think the idea of using a parent class as an interface fits into this discussion. Is allowing an interface to declare performance requirements the best solution? Instinctively I don't think it is. Suppose I publish an interface ("FastMath") that guarantees via compiler checking every method will execute in less than 100 ms. Lots of child classes are built using different implementation strategies and with different tradeoffs, but they all meet the <100 ms execution time requirement. A developer realizes he could use FastMath, but he requires 50 ms execution time. 100 ms is too long. It turns out that several of the newer FastMath child classes published do in fact meet his timing requirements. Unfortunately he cannot use the FastClass interface because it doesn't exclude the slower implementations. He *can* create a new ReallyFastMath interface class, create a new subclass for each of the FastMath subclasses that meet his performance requirements, and use delegation. That is how we would do that using existing LV technology. What if we had a solution that allows the interface user (calling code) to declare the performance requirement and the interface implementations (child classes) to publish their performance parameters? The compiler can compare the requirement against the parameters and throw an error if they don't match. It doesn't change all errors into compiler errors--dynamically loaded classes would generate an error until loaded. But it does get closer to the goal of avoiding errors without sacrificing flexibility. -
[Ask LAVA] Must Override exists; could Must Implement?
Daklu replied to JackDunaway's topic in Object-Oriented Programming
[Preface for readers: As always, my goal from these discussions is to increase my own knowledge and understanding. I have found the best way to do that is to explain my beliefs and the reasons for those beliefs and hope those with conflicting beliefs do the same. If any of my comments (on any thread, here or on NI's forums) come across as overly aggressive or combative, I apologize. It is not my intent to beat my beliefs into others.] Okay, I can accept that. Based on some of the information I read earlier, I interpret Identity as a property (usually not explicitly declared in LV) that is unique to each object. Two objects of the same class have different identitites. This seems to agree with that interpretation. In light of that, I don't see how a child class can ever hope to "match its parent's Identity." For State I refer back to my earlier question. Yes, every object has an internal data State. Why does the child's State need to match the parent's State for it to be "effectively used in a framework?" It seems like an obvious violation of encapsulation. I think of Behavior as a more abstract concept than that definition appears to advocate. To my way of thinking, a class' behavior is the simplest model that explains to users how the class works well enough for them to understand how to use it. Methods are part of that model, but they don't describe the entirety of a class' behavior. For example, a file i/o class may present itself to users as having two behavioral states: file open and file closed. The class may be written so internally it only has one behavioral state, or it could be written so it has ten behavioral states. It's irrelevant. What's important is that the class presents itself publicly as having two behavioral states. It's this public behavior that the child classes should match.* [*Assuming the goal is to replace the parent object with the child object at runtime. If that is not the intent, there's no reason to mimic the parent's behavior.] Oh I fully agree they are still requirements; I'm not disputing that. Every time I use a sub vi or primitive I'm using it with the assumption that it meets the set of precondition and postcondition requirements I've imagined for it. Some of those, like the data types it accepts and returns, are explicit. Other, like the execution time, are implicit. Implicit requirements are generally understood but not strictly enforced by the language or compiler. I'm disputing the apparent suggestion that requirements should be moved from the implicit realm to the explicit realm. Does it sometimes make sense to be able to strictly define some set of arbitrary requirements? Probably. I can see how it would be useful in your FPGA example. On the other hand, as flintstone pointed out strictly defining the number of clock cycles it is allowed to consume eliminates the possibliity of creating a child class and using it in a system with different requirements. Taken to the other extreme, every output should be a unique type that strictly defines all values that sub vi will return. Every string constant, every integer field with unique range restrictions, etc. should be a unique type so you can guarantee a runtime error won't occur. I think we can agree both extremes lead us away from a productive and usable language. If we use LV's existing type system as a starting point, adding the ability for a parent method to define the allowable range of an integer output terminal is roughly analagous to creating a new data subtype. Sure it might look like an Int32, but I can't connect any Int32 to it. I have to coerce my Int32 into an Int32Range0-10 subtype before I can pass it out. As a thought exercise, imagine replacing the Int32Range0-10 output terminal with an enum typedef that simply lists the numbers 0-10. Functionally it's nearly the same thing. What are the long term consequences of doing that? Let's pretend an egg packaging factory has a vision system in place for counting the number of eggs in a box just prior to final packaging to ensure all egg cartons are full. For the sake of the example we'll assume all their cartons hold 10 eggs. The developer recognizes that the only valid values returned from the Vision.EggCount method are the integers 0-10, so he defines an Int32Range0-10 output terminal and is confident his system will work correctly. Lo and behold marketing discovers many customers prefer purchasing eggs by the dozen, so the factory sets up a new packaging line for 12 egg cartons. The vision system is identical in every way, except on the new line Vision.EggCount can validly return the integers 0-12. What choices does the developer who used an Int32Range0-10 have? 1. Fork the original code and maintain a separate code base for each packaging line. Generally considered a poor solution. 2. Edit the parent method and switch it to an Int32Range0-12. Then edit the calling code to add bounds checking and a configurable upper limit. Conversely, the developer who implemented Vision.EggCount using a simple Int32 (or U8, or whatever) has already implemented bounds checking in code. If the bounds checking is in the calling code he'll have to add a configurable upper limit but his system is already designed to deal with the possibility of an error, so he has far less work to do. If the bounds checking is in the Vision.EggCount method he can implement a new limit by subclassing (possibly accompanied by some simple refactorings.) I respectfully disagree. A function that returns the constant Pi can only be used in those places where Pi is needed. A function that returns the constants Pi, e, g, and c can be used in more places than either the constant function Pi or the computed function Pi. Now I'm not saying I think all constants should be rolled into one function. It's just an illustration of how lessening restrictions makes it easier to use a piece of code in more situations. You comment about how the constant function Pi can be used in more places than the computed function Pi raises some interesting questions. Is that universally and necessarily true? I don't think so. It's only true in those situations where reduced computation time to get Pi is desireable. Granted, that is usually the case so I don't dispute this specific example, but I question the ability to draw a general conclusion from it. I've mostly been thinking about functional requirements, not performance requirements. To be honest I'm not sure how to merge them. Maybe in trying to simplify things we're both wrong. After all, I can just as easily put a minimum execution time requirement on the Pi function as a maximum execution time requirement. If I define the minimum execution time as 16 seconds, is that function more usable that a Pi function with no explicit performance requirement but is shown to execute in 10 ms? It seems to me that in order to know if a given restriction is increasing its application space or decreasing its application space, one must know the size of the application spaces being gained and lost as a result of the restriction. As those application spaces includes future code not yet written, any computation is necessarily subjective and the decision is constrained by the author's imagination. This illustrates (albeit imperfectly) what I was trying to communicate earlier. Imposing this performance requirement assumes anyone implementing this interface will be using it in a system where those performance requirements are necessary. What if I want to use STL in a system that doesn't have those performance requirements? If the performance requirement is strictly defined and inviolate, I no longer have the ability to create an STL implementation that meets my needs. On the other hand, if they are simply documented requirements then I am free to violate them at my own risk. Does making the STL performance requirement documented rather than enforced make the STL less usable across systems? I don't think so, though it may be slightly less "usable" from the developer's point of view since they must understand the performance characteristics of any implementation they want to use instead of being able to haphazardly plug in a random implementation. I agree many programmers do not adequately test their code and I agree compiler errors are easier to find and fix than runtime errors. I disagree that NI should try to create (or move towards) a language which maximizes compiler errors to compensate for inadequate testing by developers. I'll speculate that the reason they are the key to most every library you've released is because one of your primary concerns is to prevent people from shooting themselves in the foot. I understand why that is and I'm not disputing that it is a valid goal to work towards. But it's not the only valid goal and it's not everybody's goal. In particular, it's not my goal. My goal is to release libraries that allow users to extend them as needed to fit their specific work flow and requirements. Is there more opportunity to blow off a couple toes? Yep. But they can also point that gun at the racoons rummaging through the trashcan and the cougar stalking the dog. They're not limited to plinking at the rusted truck body on blocks in the backyard. How did using those flags make the difference between a workable system and a non-workable system? What situation did they prevent that could not have been detected equally well by decent error handling and testing? (I can't help but relate our goals to political ideologies, but I'll spare the thread that particular rabbit hole.) That's certainly possible seeing as how the author was me. All I can say is every single time I can think of right now where I've used either of those flags, I have encountered or been able to think of situations where imposing that requirement on a child class didn't make sense. -
Yes, you can. I've done that in the past. IIRC there is a significant performance hit with the Get LV Class Path vi. It's probably a non-issue for the occasional comparison but could be noticable if you're doing a lot of comparisons. ------------ [Edit] Alternatively, if you're working with a predefined set of classes you can give each class a constant identifier and compare those. It's not as useful as a generalized class comparison vi but it can be used in a pinch.
-
I nominate Yair as the Lava historian. He seems to remember every discussion ever had and comes up with links to them.
-
[Ask LAVA] Must Override exists; could Must Implement?
Daklu replied to JackDunaway's topic in Object-Oriented Programming
Hmm... I don't understand how LSP can apply but DbC does not. Everything I've read indicates LSP and DbC emphasize the same thing--establishing preconditions and postconditions for each method. I've seen it phrased a few different ways, but the general idea is an overriding method should require no more and provide no less than the parent method. Or to put it another way, the child's precondition must be no stronger and its postcondition must be no weaker than those of the parent method. Some authors appear to consider LSP and DbC equivalent. ------------------ I agree with everything you said. I didn't understand your reference to "Identity, State, and Behavior" so I turned to Google to see if I could find a context for it. I think I understand what you meant by "behavior" now and it appears to align with my interpretation of behavior, but I'm still not following the reference to "identity" or "state." ------------------ I understand where you're coming from. I've occasionally implemented informal contracts by documenting pre- and postconditions and slightly more formal contracts by using assertions. Your post appears to be advocating additional language constructs to enforce expectations. I have a couple concerns about this: 1. In the example you gave, the parent method has no way of ensuring a child method outputs values within the expected range. It can't control what shows up on the child method's output terminals. I'm not sure how one would go about declaring that requirement. You can't do it in code. The only thing I can think of is some sort of property dialog box, like maybe setting up the indicator with the same kind of range property as the numeric control. I'm not fond of requirements that aren't explicitly spelled out in code--I think it significantly hinders readability--but I don't see any way to implement this kind of requirement in code. 2. Even if the parent method can impose that requirement, my personal opinion is that's not the best place for it. If the caller is going to invoke unknown code (from an unknown child class method) and it has restrictions on what it can accept from the sub vi, it should be validating the values returned from the method. Yes, there are distinct advantages to to having the compiler find bugs, and that ability is lost when the postconditions are verified by the calling code. But the overall goal isn't (I hope) to push as much error detection into the compiler as possible. The goal is to give us a tool we can use to quickly create what we need to create. The more a language forces potential errors into the compiler the less flexible code written in that language becomes. Every restriction put on a piece of code reduces the possible places where that code can be used. It seems very analagous to the strict typing vs dynamic typing debate. Even the Must Override and Must Call Parent flags are nothing more than reminders for child class developers. I can't think of a single case where either of those flags guarantee the child class will be implemented correctly, or where using them is appropriate for all potential subclass situations. Maybe there are some, I just can't think of any. But I've run into lots of situations where they got in the way of what I was trying to do. -
I don't pretend to understand LV's memory management, so take this with a grain of salt. In the Same Runtime Class vi instead of branching the input wires I wired a LVObject to the top connector on the PRTC prim. It still used twice as much memory as I expected. I interpret that as pointing to something inside the PRTC prim. I reverted that change, made a few other changes, and built an executable. Monitoring memory consumption while running the executable revealed this: Assuming 100 MB per class, 1. If the input classes are the same 400 MB are used. 2. If the input classes are siblings 200 MB are used. 3. If one input class is Vehicle and another is a child, 300 MB are used. It appears the PRTC prim allocates memory for a copy of the input object in cases where the preserve operation is successful. Same Class_Dak.zip
-
[Ask LAVA] Must Override exists; could Must Implement?
Daklu replied to JackDunaway's topic in Object-Oriented Programming
I have to challenge you on these points: 1. This is probably true in situations where the child class is written with the intent of replacing the parent class in a fully functional system. I frequently create subclasses as unit test doubles and these almost always do something I didn't expect when writing the parent class. 2. Also probably true as long as the child is intended to replace the parent in a fully functional application. In my experience these restrictions get in the way of things I try to do in the future, like automated testing. In fact, unit testing is one of the reasons I rarely use any of the current restrictions available to us. 3 & 4. Possibly true, depending on how you define Identity, State, and Behavior. But as it is I'm not quite following. If Identity is defined as an individual object why should the child class identity match the parent class identity? (Data) state is defined by all the internal data fields... those same private fields that Labview doesn't allow anyone else to know about. Why does it matter if the child's state matches the parent's state, or for that matter, why does the internal state matter at all? Behavior is defined by what the object does when a given method is called and controlled by the object's state and the method's input parameters. If the child's behavior matches the parent's behavior there's little reason to create the child in the first place. One of the reasons to create a child class in to change the behavior. Is what you're getting at is more along the lines of the Liskov Substitution Principle or Design by Contract? -
I guess that explains why it only accepts a DVR wrapped double and no other wrapped data types. Count me lucky then. I don't think LV ever immediately crashed, though it always did end up crashing at some point. For all I know your dev team is looking over the crash logs at this moment and wondering what the heck I was doing...
-
[Ask LAVA] Must Override exists; could Must Implement?
Daklu replied to JackDunaway's topic in Object-Oriented Programming
I read it more as a Java criticism than an OO criticism. -
Perhaps. From all I've heard about the CLA-R I think the 4-hour exam is better at establishing whether a developer is at CLA level, but I still don't think it's a particularly good exam for that. (I've written at length about my experiences, so I'll spare you the details here.) Quadruple the pain for a marginal increase in the test's power. I'd be in favor of an essay or short answer type of recertification exam. 90% of architecture is about defining the interfaces and interactions between components. I can better communicate system architecture in a word document with accompanying hand drawn sketches then I can in LV code or on a multiple choice quiz. I'm taking my CLA-R at the summit next month. Given the feedback of those who are far more experienced with Labview than me, I don't expect to pass.
-
I've made a preview of the LapDog.Collections.Lists namespace available for download. Read the full announcement here.
-
I'm neither a camera expert nor familiar with that camera model, and without seeing images it's hard to say for sure, but here are some ideas: -The black lines could be due to a defective camera. Over the last year I've built a dozen systems using the Basler avA series cameras and two of them had to be returned. I'd call Basler and see about getting a replacement. -The green tint might be correctable by changing the camera's firmware settings. Basler has utilities for adjusting the camera firmware. I use "Pylon" with the avA cameras. I don't know if that's the right utility for your camera. -Vignetting is purely a function of the lens. Different lenses will produce different amounts of vignetting. -We can't suggest a specific lens without knowing a lot more about your application--there are far too many tradeoffs to consider. The best thing you can do is call a reseller and discuss your requirements with them. They'll be able to help you select an appropriate lens.
-
[Ask LAVA] Must Override exists; could Must Implement?
Daklu replied to JackDunaway's topic in Object-Oriented Programming
Here's a rewrite of the List Collections using the design I described earlier. There are no UML diagrams or external docs describing the code, so to give a little overview, there are three projects in the zip: ListsCollections.v0.Lists.lvproj Source code for the libraries that make up the LapDog.Collections.v0.Lists namespace. The libraries are: LapDog.Collections.v0.Lists - This is the main library for all list collections and contains the root interface class (List) and the root implementation class (ListImp.) LapDog.Collections.v0.Lists.Implementations - Optional List implementations subclassed from ListImp that can be injected to meet specific performance requirements. Currently only contains one alternate implementation, BufferedArray. This library depends on the Lists library. LapDog.Collections.v0.Lists.Interfaces - Optional List interfaces that can be used to enforce type safety. Currently contains only one alternate interface, StringList. This library depends on the Lists library. ListsexamplesList Examples.lvproj Currently this project only contains two vis I created for benchmarking; however, you can look at them and see how easy it is to swap out a different implementation if you need to fine tune performance characteristics. This buffered array implementation works really well on tail inserts, but head inserts are absolutely atrocious. ListsdevtestListTesting.lvproj This project contains the unit tests for the LapDog.Collections.v0.Lists namespace. You're free to look at them--just make sure you have JKI's VI Tester installed. Lists.zip -
Yes, I have that effect on a lot of people. I choose to believe it's due to the overwhelming impact of my awesome. (What most separates humans from the rest of the animal kingdom? Our capacity for self-deception.) Thank you and likewise. I'm looking forward to another couple days of great discussions next month.
-
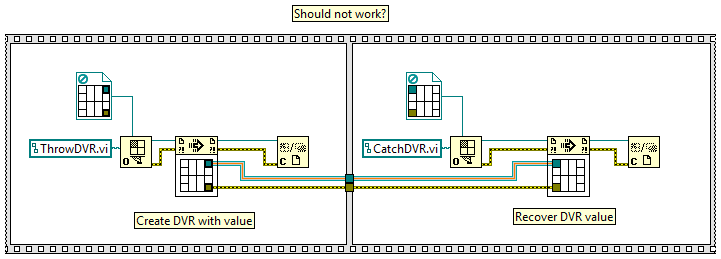
For kicks and grins I poked around a bit (2012) and found a pair of vis that looks interesting... My first thought was that it would be useful for situations where one dynamically launched vi creates a DVR and sends it to a second dynamically launched vi. When I put together a few quick tests to see play around with it I was surprised the DVR didn't automatically deallocate when the reference to the first vi was closed. (Nope, I don't dynamically call stuff very often.) As I recall, we're told references are automatically deallocated when the vi that created it "goes idle." I've always interpreted "idle" as meaning the vi is not locked because another vi is running. So, either I'm wrong about what it means to go idle or the DVR already has the functionality of these prims built into it. LeakReference.zip