Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-

Do you aim to get users working quickest or do you aim to teach?
Daklu replied to Mr Mike's topic in LAVA Lounge
Yes, that is what they're for. However, 1. They are expensive and time consuming, and not everyone is able to attend them. 2. The information in training classes and seminars tends to be outdated, especially with the way LV development has shifted the last 4 years. 3. Out of necessity training classes and seminars use contrived examples. Learning is far more effective when discussing code the user has written themself. I don't view it as "training," I view it as "teaching." You "train" a dog to fetch a ball. You "teach" a programmer to understand a complex situation and make appropriate decisions. You are correct forums are not an ideal platform for teaching. Ideally, a new programmer would work side-by-side with an experienced developer for years asking questions and understanding why things are done a certain way. Very few people have that luxury. Forums, while not ideal, are the best option many of us have. You are correct, and I don't mean to claim that it does. Lots of people here know more about specific functions, features, and tricks than I do. I leave it to them to provide those kinds of answers. But at the same time, if we don't point out why the problem occurred and how a different design could have avoided the problem, then they won't know there are better ways to structure their system. They will continue writing legacy code. I can certainly understand why people wouldn't return to ask him questions, but at the same time I have to admit it's a clever way to filter out interruptions from people who aren't willing to invest the time in understanding what they're doing. I do it all the time with my daughters. My younger daughter will often ask me a math question to verify something she's tried to figure out in her head, like "what's 17*9?" I could simply give her the answer and be done with it. Instead I guide her through the process: Me - "Well, what's 17*10?" Her - "170" "How many 17's do you have to subtract to get your answer?" "One." "What's 170 - 17?" "153." Yeah, it drives them nuts and sometimes they get mad at me. I do it anyway. I call foul. I think we all agree they should be given both answers. The question is what do *you* do, not what we as a group *should* do. -
Or perhaps... Option C) Someone could explain in text the algorithm the OpenG Trim Whitespace function uses and I could implement it and upload it to ni.com. To the best of my knowledge, since I've never looked at that source code there's no copyright violation, and I'd be really surprised if anyone at OpenG has applied for a patent. NI gets source code ownership and better functionality for Labview, OpenG authors retain ownership of their code. Everybody walks away happy. It would be cumbersome for large libraries, but for one-offs it seems like a reasonable way to fold user improvements into the Labview base. -------------- There's one question regarding code ownership I'm not clear on. The only thing that gives me slight pause over transferring ownership of something like LapDog to NI is that it may prevent me from continuing to develop the code independently of the direction NI chooses to take it. On the other hand, we're already creating our own copyrighted works entirely from functions and sub vis licensed to us by NI, so I don't see how giving LapDog ownership to NI would be significantly different from what I'm already doing. The only restriction I can see is that I (presumably) couldn't give LapDog to NI then turn around and sell it as a third party add-on. That's largely irrelevant imo, since I'm already giving it away for free. Comments?
-
Do you aim to get users working quickest or do you aim to teach?
Daklu replied to Mr Mike's topic in LAVA Lounge
The poll is fundamentally a question between how and why. Do you prefer to show someone how to fix their current problem or illustrate why that problem exists in the first place. I lean heavily towards answering the (often unasked) question of why and cast my vote accordingly, but both types of responses are valid and necessary. Often my response does depend on the specific question and who is doing the asking. If someone describes their overall system before explaining the specific problem they've encountered, I interpret that as an invitation to comment on it. When a persons asks for the "best" way to solve a problem, often it requires discovering and analyzing system architecture, non-functional requirements, and stuff like that, which of course also invites comments on it. Conversely, Dec/Jan is when FIRST is building their robots and we usually get a few questions from them. Given their time constraints and lack of experience, it's probably not a good idea to steer them toward the AF. One thing I worry about with respect to answering the how question without addressing the why question is the impression it will leave with readers other than the original poster. Failing to highlight why implicitly validates poor (or at the very least, ignorant) decisions. Many times the problem only exists because the architectural situation is untenable. Doctors are taught how to treat a patient with a severed arm, but they don't ignore it when someone is sticking their arm in a combine simply because they know how to deal with the results. In the same way I prefer to try and show people how to avoid losing an arm rather than emphasizing how to apply a bandaid to the bloody stump. Once somebody understands the "ideal" way to implement something--and more importantly why it is "ideal"--then they are in a better position to make decisions on when it is okay to use less-than-ideal implementations. But to get to that level of understanding requires somebody pointing out the flaws and consequences of the implementation they're using. IMO why is the most important question humanity has ever asked. All that being said, I firmly believe a big part of what makes LAVA so valuable is the variety of user backgrounds and opinions expressed here. When I first came to LAVA I was a corporate drone working in an internal test tools group. Now I'm an independent contractor with my own business. Different positions have entirely different sets of environmental non-functional requirements underlying every design decision, and it's all too easy to unintentionally project my own environment requirements onto the user's question rather than getting clarification on their environmental requirements. This is very often the limiting factor for me. I'm already a really slow writer so I tend to have to pick and choose those threads I participate in. Too bad nobody wants to pay me to write posts for LAVA. (Although that's probably good news for the rest of you. ) -
I haven't read through all the replies on this thread, but this comment jumped out at me. As an alternative, have you considered writing an instrument actor instead of using by-ref objects? Personally, I find actor-oriented programming much better than reference-based programming for multi-threaded applications. YMMV.
-
What license you choose to use depends entirely on what rights you want to give users. BSD allows users to do pretty much anything with your code. LGPL maintains the GPL's copyleft policy if the source code is modified, but allows users to link to libraries released under LGPL without requiring it to also be released under LGPL. You can also choose other licenses if you want. LapDog is released with a Rootbeerware license.
-
This morning I received an email advertising a new free-to-play fantasy multiplayer online game. Curious, I pulled up the website and read a little bit while brushing my teeth. (Smartphones FTW.) The very first magical item I looked at was... The game is still in beta so I can forgive them for misspelling his name.

-
Yep, real helicopters--unlike airplanes--are unstable by nature. Cheap RC helicopters are simpler and more stable than their full sized counterparts, but it doesn't make the project easy. I agree, and I have to admit I was totally overambitious on what I could achieve. When academic theory meets real world variability big ideas become big problems with big headaches. Fortunately for me I had an advisor who made us scale back our ambitions into something manageable.
-
No, it's not completely infeasible, but since we're in the development phase and don't know what the optimum filter values should be I'd prefer to have the flexibility of software filtering.
-
My fault for mixing units. Sample rate is 1.613 kHz. Filter is 2 Hz. I happened to run across a Butterworth Coefficients vi while reading the help files that addresses this problem. I run this vi on the host with the sample and cutoff freqs as inputs and pass the returned coefficients to the FPGA. This allows me to change all the relevant parameters from the RT code without recompiling the FPGA code.
-
Yeah, that's what I ended up doing. It wasn't as troublesome as I thought it would be. Right, but for the filter to work correctly it has to know the sampling frequency, and that can only be set using the express vi configuration dialog box. What I ended up doing was setting the filter's sampling freq to 1.613 kHz and the cutoff freq to 2 Hz. I believe the only side effect of increasing the module's sampling freq is a proportional increase in the cutoff freq. i.e. Collecting data at 10 kHz would push the cutoff freq to ~12.3 Hz. It's not ideal, but it's workable. Another option would be to decimate the input stream to a fixed sample rate prior to running it through the filter. But with the huge number of possible sample rates the module supports I didn't feel like working through the math to make sure I'm getting consistent and regular data.
-
I have a cRIO-9074 with a 9237 strain gauge module. The signals are way too noisy to be useful, so I added a Butterworth Pt-by-Pt low pass filter to the RT code. My benchmarking shows the execution time of that vi to be 0.1 ms on this platform. That gives me a theoretical maximum throughput of 10k points per second. The first problem is I'm going to have 8 channels of data and the minimum sample frequency for the 9237 is 1.613 kHz per channel, which translates to ~13k data points per second. I considered moving the filter to the FPGA, but there doesn't appear to be a way to change the sample rate without recompiling the code. At this point in the project I can't really afford to wait 20 minutes for the recompile to finish every time I make a change. Perhaps later in the project when systems and parameters are understood better I can do that. The second problem is I don't have enough signal processing experience to understand all the filtering options LV provides. The customer is leaning towards using an FFT to filter out high frequency noise. I don't know if that will be any more computationally efficient and I'd have to do a bunch of research to even figure out how to use those vis to do what I need. Does anyone know the relative cpu load of the various filtering options, and are there other filters that can give me a low pass filter at a much smaller cost?
-
You can also connect terminals with a wire using click-hold-release. That behavior still exists in 2012.
-
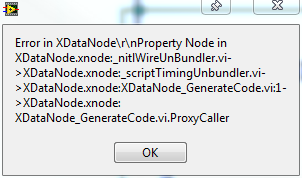
Anytime I do change the properties or expand/contract the property terminals of a timed loop I get the following error. Everything still seems to work correctly so it's not a show stopper--just a bit annoying to click OK 2-3 times every time I make a change. Has anyone else seen this problem?
-
Modifying a Labview built MSI?
Daklu replied to Daklu's topic in Application Builder, Installers and code distribution
Yeah, but I don't know if what I want to do is a good idea, nor do I know how to do it. I'm hoping there are users around here with a better understanding of the MSI technology and database who can chime in and help answer those questions, but it appears to be a pretty esoteric skill set. -
Problem: An installer for a LV api to a particular device was built several years ago. When LV 2012 was released users discovered there is no option to install the package for LV2012. LV 2009-11 will show up as options if the users has them installed, but 2012 isn't offered. Rebuilding the installer would be fairly straightforward... if the final source code, palettes, and installer configuration were available. Unfortunately, it appears they were not saved in scc. Question: Is it possible to use Orca or some other tool to easily update the MSI database so LV2012 is presented as an option? I know directly editing an MSI database is discouraged, but I'd rather not try to rebuild everything from scratch if it can be avoided.
-
Native Support for Dynamic Palettes
Daklu replied to crelf's topic in Application Builder, Installers and code distribution
This isn't quite the same, but it is a step in the direction of dynamic palettes. -
Just a quick note to let you know it will be at least another week before I'll be able to look at your stuff again. Hopefully others will be able to give you some guidance in the meantime. You are correct that you need multiple loops. How many do you think you'll need? However many tasks you want to execute in parallel is the absolute minimum number of loops you'll need. I always have additional loops handling messages and coordinating the actions of subsystems to create the high level behavior I want. My last medium-sized application had ~a dozen independent loops, and I don't think that's all that much. You need to learn how to create loops that are robust and self-deterministic. By that I mean the loop will always behave in a predictable and correct way, regardless of what message it receives from an external entity. Instead of just thinking of loops as a string of functions that execute in parallel, think of each loop as an independent entity with its own data space. Design your loops around a piece of functionality and/or data the loop provides to the rest of the application. No they won't. The sequence is contained in the string array, and the string array is emptied when the EStop notifier is processed. The message queue may still have messages waiting to be processed, but if EStop halts everything and shuts down the application those messages will never be read. If you're not planning on shutting down the app in response to an EStop, and are (rightfully) concerned messages on the queue will be processed when you don't want them to be, you need to implement some sort of message filtering in the receiver. I do that with the behavioral state machine I showed in an earlier post. There are probably other ways to implement it as well.
-
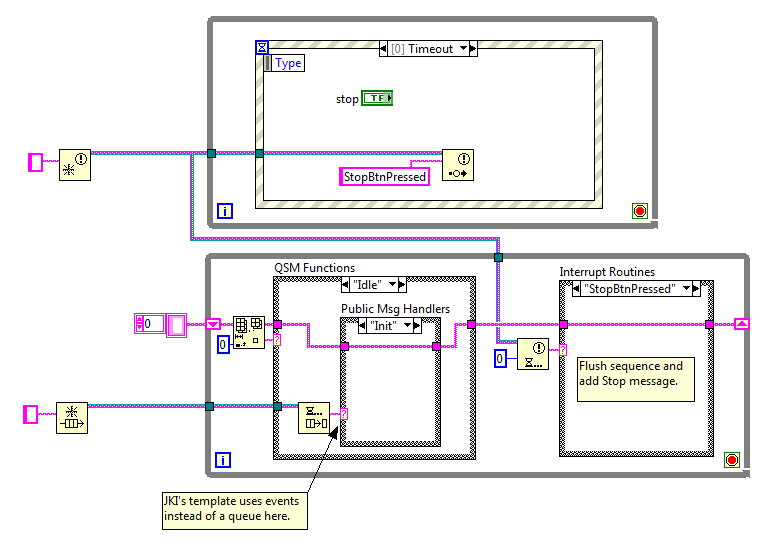
I'll help as much as I can, but to be honest I doubt it will be as much as either of us would like. I look to be pretty busy over the next week and a half. It's big, but it's actually not bad. I've seen (and helped create) far less organized QSMs. There's no way to implement a reliable STOP function with the queue manipulations you are doing. Even if you flush the queue and put a Stop message on it, your QSM loop could put other messages in front of the Stop message. A quick scan through loop 3 shows a lot of places where you are putting messages on the front of the queue. If you want to use a Stop interrupt, the only way to make sure it will be the next message processed is by putting all your other messages on the rear of the queue. Once you put any other message on the front of the queue you've lost that guarantee. Yep, the JKI template doesn't support interrupts. If you think about it for a bit you'll realize neither does dataflow programming. Public sequence QSMs pretend interrupts exist by frequently checking the queue to see if an "interrupt" occurred. Functionally it's not much different from you checking a Stop button local variable regularly. In fact, checking the local variable is probably safer, since the interrupt will only occur when the button is clicked instead of for any arbitrary message put on the front of the queue. I'd really prefer to explain how to break down your application into message handlers, state machines, continuous loops, and metronomes. I'd like to show you how to combine these different kinds of loops to build up the functionality you need. Unfortunately I haven't figured out how to explain it to beginning and intermediate level programmers yet. It's not that the ideas are too difficult to understand; I just haven't been able to figure out exactly how much information they need to understand how to get started using them. Since the goal is to get you on going on a path you're comfortable with I'm going to recommend switching back to a private sequence QSM. You can use JKI's template as long as the front panel events are not handled in the same loop as all the business logic. You can implement interrupts using something like this: [WARNING - I have never implemented this nor have I analyzed it much. There might be bad effects I haven't thought of.] I'm off to bed. But first, in the flow chart showing the desired behavior you have several "Interrupt?" decision points that feed into "Read from VNA." Are these interrupts from the UI or something else? And what happens after "Read from VNA?"
-
I didn't explain it very well. Direct connections means each component sends messages directly to the component that ultimately receives the message--there's no need to forward messages like you have to do with hierarchical messaging. With hierarchical messaging an owner needs to know specifics about its subcomponents. To explain a little more, in the context of what I read, a "pure reactive system" (or "event-based system") is one in which all messages at the abstraction level you're looking at are status messages. They are announcements that something interesting just happened with the message sender. ("I stubbed my toe.") There are no messages requesting specific actions from another component. ("Get me a bandaid.") The idea is that by being purely reactive, each component is naturally decoupled from the others--since it isn't explicitly sending messages to them--and more reusable. Hierarchical messaging requires message routing, which in turn requires owners to know specific information about their subcomponents. In the literature I've read it was implied that event-based systems are not organized in a hierarchy (at the abstraction level at which you're looking,) so there is no concept of ownership or subcomponents. Without ownership each component must send messages directly to other components. But in order to establish communication links between components without creating static dependencies, you have to dynamically register all the events at runtime in source code that is part of neither component's libraries. (I imagine this code would be implemented in the application's initialization routine.) The last bit, and the part I'm most fuzzy on, is that the semantics of the code establishing the communication links was such that it was possible to link an arbitrary event generator with an arbitrary event consumer, regardless of whether or not they had compatible interfaces. Obviously some sort of adapter code would have to be implemented to make the translation, but you didn't see evidence of that while creating the links. I don't recall if it included source code, but it could look something like this, Nurse.TreatInjury handles Me.IStubbedMyToe[/CODE] Anyway, I'm mostly just thinking out loud. It sounds like you guys are at least part of the way there. I haven't needed that kind of functionality yet, but I'm curious what it would look like in Labview. Do you use hierarchical messaging throughout your application, or do you have abstraction layers or subsets of components that use direct messaging? Publish-subscribe implies to me dynamically registering for messages at runtime. i.e. Each component sends a message to another component saying, "add me to the list of receivers when you send message [i]m[/i]." Is that how you are using it? (I know we've talked about it before, but it's so hard to keep everyone's interpretations straight.) Well, it's your thread. The rest of us are just hijacking it. Sure. In the context of a QSM, a public message (or state) is any message that external loops are allowed to put on the queue. Private messages are the "sub vi" messages that external loops should not put on the queue. One of the difficulties with public sequence (single queue) QSMs is that there is no way to prevent external loops from sending a private message. Therefore, all messages by definition are public and all message handling code should be written with the expectation that it can be called at any time. There's a lot of detail here that will take me a while to absorb, and unfortunately I've spent far too much time on this thread today. My initial reaction to your question is if you are using a public sequence QSM, no. The cost of using a public sequence QSM to allow interrupting a sequence is being very restricted in where you can put decision making logic and what that logic can do. Race conditions will breed like rabbits. If you are using a private sequence QSM, yes, but you lose interruptability. Until I understand the entire scope of your problem I can't give too many specifics, but here are a few things to get you started. 1. Create an execution flow diagram showing the how the cases transition from one to another. Don't worry about race conditions for the moment. Just map out the logic in your QSM loop. You [u]have[/u] to understand what you've implemented if you want to continue on this path. (And I have to understand it before I can give you any specific advice.) If a case is used in more than one execution sequence, create duplicates on the diagram. In the example I posted all the non-orange cases represent duplicates. 2. Create an execution flow diagram modelling how you want the application to behave. Focus on what happens when users do each action available to them. Break them down into however many steps you're comfortable with. Usually this is an Idle case with a branch for each event the QSM responds to. The branch will go through a sequence of functions before returning to the Idle case. It ends up looking a bit like a flower with each branch being a petal. 3. Post both diagrams. -------------- [i wrote the following, then was going to delete it as there are way too many details and exceptions for this to be a "good" guide. I decided to let it remain in case you wanted to give it a go... But beware, there be dragons down here.] 4. [b]Save your project and back it up. [/b]Refactoring a QSM is tricky and I haven't developed an easy list of steps to follow. The idea is to simplify your execution flow diagram by reducing the number of cases to the bare minimum. The following is my general approach, but there are lots of things that can trip you up. 5. Create a sub vi out of any duplicate cases on your execution diagram. For example, if you have a case for "IncCounter," select all the code inside the case structure and [i]Edit >> Create Sub VI[/i]. Save the sub vi as IncCounter.vi. Now you're going to try to move the IncCounter functionality from its own case to other cases so we can remove the IncCounter case. This takes some judgement and requires understanding what you have implemented. 6. Find all the places where IncCounter is put on the queue. Figure out what case immediately precedes IncCounter. Let's call it GetNextWidget. (If IncCounter is the first item put on the queue in response to a user input, skip to 8. IncCounter is a public message and the case cannot be removed.) 6a. If GetNextWidget appears multiple times in the execution flow diagram and it is not always immediately followed by IncCounter, skip to 7. There's additional branching logic that needs to be figured out. 6b. If GetNextWidget only appears once in your execution flow diagram, place IncCounter.vi in the GetNextWidget case so it is the last action before exiting the case. Remove IncCounter from the list of items placed on the queue. 6c. If GetNextWidget appears multiple times in the execution flow diagram, but it is always followed immediately by IncCounter, place IncCounter.vi in the GetNextWidget case so it is the last action before exiting the case. Remove IncCounter from the list of items placed on the queue. (If you've already created a sub vi for GetNextWidget, put IncCounter.vi in GetNextWidget.vi. 7. Repeat step 6 for every case just before IncCounter on your execution flow diagram. 8. If every iteration through 6 resulted in 6b or 6c (in other words if you are no longer enqueuing IncCounter anywhere) you can delete the IncCounter case. 9. Repeat steps 5-7 for every duplicate case in your diagram. 10. Update your execution flow diagram. ------------- To be honest, I suspect you'll get stuck on step 2. That's where I got stuck when I struggled with QSMs. QSMs are good at implementing flow charts, and flow charts are good ways to model QSMs. The problem is flow charts are useless when it comes to modelling modern event-based behavior users expect because flow charts don't have any concept of interrupts. If you can't model it using a flow chart you shouldn't implement it using a QSM.
-
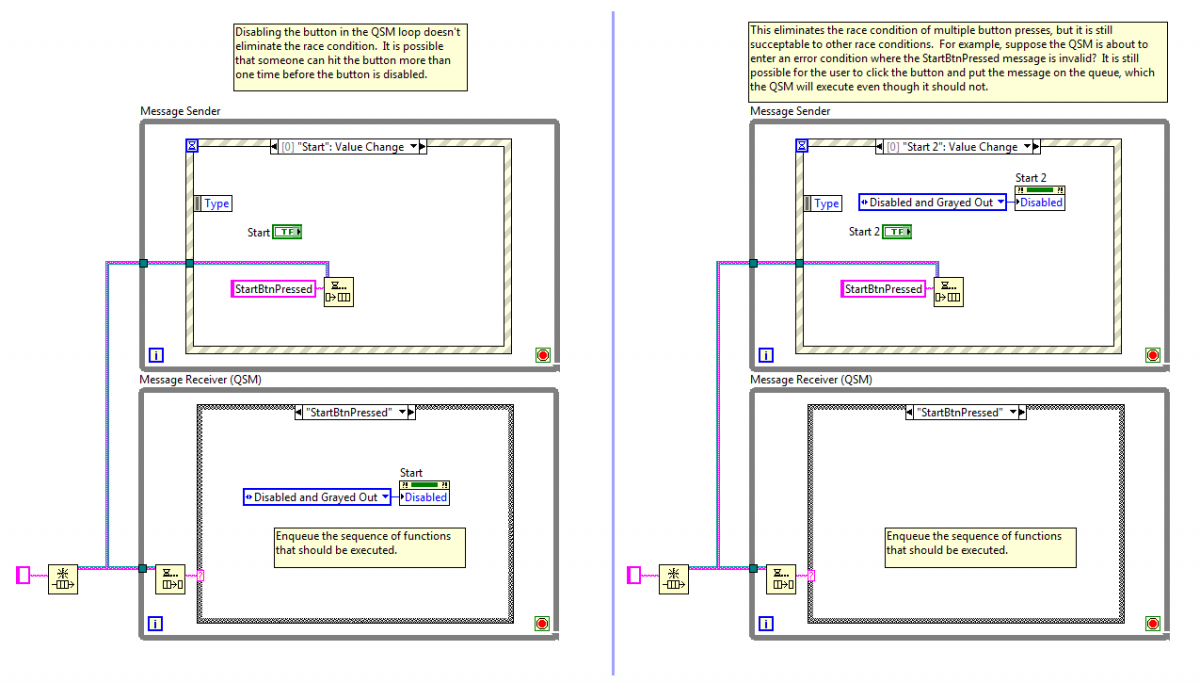
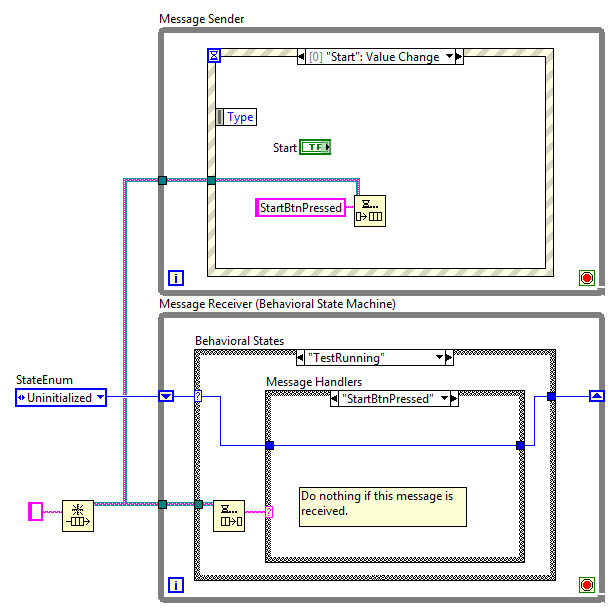
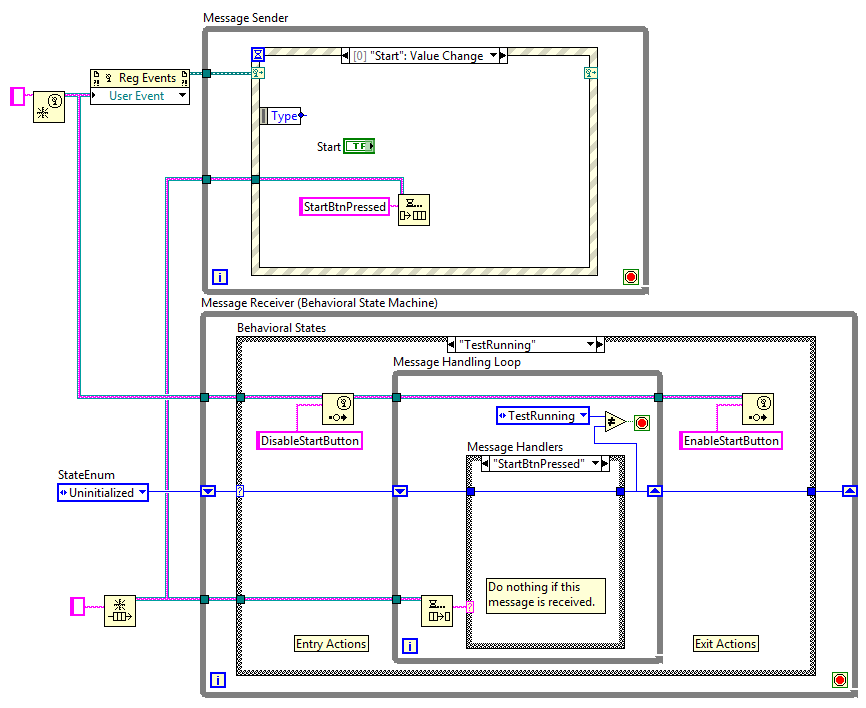
Disabling buttons is one of the things I often see people do to work around the problems with public sequence (single queue) QSMs. It can work in very limited circumstances, but it doesn't scale well and is not a good design practice. [Note: The examples use an UI event loop as the sender, but it could be any kind of process executing in parallel.] Disabling the button can be done either in the receiving loop (shown on the left) or in the sending loop (shown on the right.) In the example on the left, it is easy to see that it is possible for the sender to send multiple StartBtnPressed messages before the button is disabled. If the receiving loop is waiting for a message the user will not be able to click fast enough to generate multiple messages, but what if the receiving loop is executing a case and won't return to service the queue for another 0.5 seconds? Multiple StartBtnPressed messages. The problems with the example on the right are a little more subtle. Users cannot enqueue multiple StartBtnPressed messages, but what happens if the StartBtnPressed message is invalid for some other reason? Maybe the receiving loop has entered an error condition users need to take care of before starting the test. Preventing users from pressing the Start button while in an error condition requires the receiving loop to set the button's disabled state, which as I showed in the example on the left still exposes you to race conditions. Q: So if neither solution is safe, how do you prevent users from pressing the start button? A: You don't. The problem with both of these solution is they are attempting to implement correct behavior by preventing the message from being sent. I call this "sender side filtering." In order for a message sender to know whether or not a message should be sent, it needs to know what state the receiver will be in when it processes the message. In the examples above the event loop needs to implement this logic: if QSM.StateWhenMessageIsProcessed != (TestRunning OR Error) then send(StartBtnPressed) end [/CODE] Clearly this is impossible. When using parallel independent loops sender side filtering cannot prevent race conditions. [u]Ever.[/u] The best you can hope for is nobody will accidentally trigger them. As the application grows that gets harder and harder to justify. If you have messages that sometimes should not be processed, the only way to implement that without race conditions is to use receiver side filtering. The receiving loop is the only one that knows what state it is in when the message is read. That's where the message filtering needs to be implemented. I implement message filtering using a Behavioral State Machine (BSM.) Here is a slightly simplified version of what I usually use. In this implementation it doesn't matter how many times the StartBtnPressed message is put on the queue. As soon as the BSM enters a state where the StartBtnPressed message should not be processed it won't process them. They get ignored. If I want to disable the Start button to give visual feedback to the users, the BSM can send a "DisableStartButton" (or something along those lines) to the event loop when it enters a state where it shouldn't be used, similar to this: Here each [i]loop [/i]is a separate and distinct entity with clearly defined responsibilities. The event loop is responsible for the state of the user interface--detecting events, setting control properties, displaying data, etc. The BSM is responsible for managing the state of the underlying business logic and responding correctly to requests to do something. Again, public sequence QSMs like those in the first example [i]can[/i] be used successfully as long as certain restrictions are maintained. As the app grows and message filtering becomes necessary you can't help but introduce race conditions. (That's on top of having to trace through the maze of conditionals buried in each case to figure out the overall logic.) When people claim it "scales well" they must be using a different interpretation than what I'm used to--it's clear to me it does not scale well at all. I have no problem if people use public sequence QSMs (provided I don't have to work on it,) just as long as they understand they are painting themself into a corner. Unfortunately the limitations I've described here are not well understood by the community at large, and the full set of limitations isn't understood by [i]anybody.[/i]
-
I agree it's easier if you choose a single transport mechanism in your code, and since you already use events for your back end (NSV) I understand why you'd decide to go that route. Since NSV events are the backbone of your system, do you find your systems are heavily event-based instead of command/request-based? Not events the transport mechanism, but events in the general sense that each component is telling others something just occurred ("I just stubbed my toe.") instead of instructing another component to do something ("Go get me a bandaid.") I use about an even mix of request and status (or event) messages. For most applications request messages go down the tree and status messages go up. I've read stuff that speaks highly of pure reactive systems that only use status messages. Thinking about all those direct connections makes me shudder and I'm curious what your experience is. I don't disagree with you at all. There are some implementation decisions that can have a huge effect on how easy they are to use. When I first played around with user events my instinct was to create a unique user event for each custom message sent to the event loop. I hated it. They became much more usable once I started creating a single generic user event and sending all custom messages on that. Do you use generic user events or create one for each message? I'm also curious how you manage the interface ownership between two components. Which component gets to decide what the message looks like? In my applications a component owns and defines the request messages it will honor and the status messages it will provide. If there is an interface mismatch the other component has to implement an adapter of some sort. Events more naturally align with status messages, but if all you use is status messages and status messages are owned by the sender, I would think it would lead to dependency pollution. (Interface dependency, not static dependency.) I know you guys use abstract classes to define interfaces for components, but it's not clear to me if you do that for messaging interfaces or just for method interfaces, and if you do define abstract classes for messaging interfaces, which component owns the class?
-
Evolution? User events and queues are both just transports. Obfuscation (chaining functions instead of using sub vis) and insufficient decomposition (cramming too much stuff in a single loop) are the two main implementation issues I encounter when I work with existing QSMs. Switching from queues to user events doesn't help either of those problems. What problem does events solve that you don't like about queues? Dynamic registration and one-to-many are the main functional differences of events. How do these features help you write good code? If events are more suited to your development style than queues I don't know why you'd use queues either. I'm more curious about the development style in which events are more easier than queues. Do you use hierarchical messaging or are your designs based more on direct messaging?
-
Perfect! Thank you very much.
-
Thanks Christina. It sounds like I have to choose one or the other. Most of the time I want blank projects, but occasionally I like the dialog. Is there a way to invoke it manually? I found some files that looked relevant in \ProjectTemplates and \resource\plugins\NewDialogFiles but didn't find a way to launch it.
-
It's not that it's special, it's just different. After consultation to refine the requirements. Yes. Refine? Uh uh, that *is* the requirement (with respect to location.) I cannot believe you just wrote that. This is reductio ad absurdum argument. What is worse. Is that it is a reductio ad absurdum arguement based on an analogy Ahh... the ever-so-common fallacy of "appealling to the fallacy." (Dismissing an argument in its entirety based on identifying a logical fallacy, without regard to whether the argument relies on the fallacy. Or in the context in which it is usually employed, "I can't refute the argument so I'll claim it contains a logical fallacy and ignore it.") I absolutely agree comparing software development to building a skyscraper is absurd. Why'd you do it in the first place? I wasn't referring to running on different operating systems. I was referring to the various hardware configurations, drivers, services, and all the other stuff that is different between computers even if they are running the same operating system. Operating systems have improved a lot in the last decade in providing a consistent environment for the software, but the environmental variables are still much less constrained than the environmental variables an architect has to deal with. If beta testing were an effective alternative to having an in-house QA department, then I'd agree with you. It's not. It's not even close. I'll grant you that the overriding goal of all companies is to maximize profit (though not necessarily by reducing costs.) Releasing shoddy software isn't a good long term strategy for maximizing profits, and beta testing isn't a good way to find bugs. They'd be stupid (in business terms) to rely on beta testing for QA. May I ask what you're basing your assertion on? I can't say what most large software companies do, but those beta programs I've been able to see from the inside require a lot of time, effort, and money. Beta Coordinator was an actual position. It was somebody's job title. It may have been filled by a contractor, but it was too big of a job to just add it to someone else's list of tasks. I'm not claiming software is harder than quantum mechanics. There are some things that make it harder than structural engineering. In other ways it's probably easier. One thing that makes it harder is customer's expectations. People intuitively accept constraints to physical objects. Nobody buys a Ford Focus and expects it to be suitable for all driving conditions they may encounter. What if there's 2 feet of snow on the ground? What if I want to tow a 4,000 pound trailer. What if I want to play around on some sand dunes? Nobody considers the car defective for not allowing them to use it in these conditions. Just seeing the car gives them a pretty good idea of what it can be used for. People also expect software to be much more malleable than physical objects. Most people have a pretty good idea that modifying a car designed to use unleaded gasoline to be able to also use diesel fuel requires more than just drilling out the hole in the fuel tank so the diesel pump nozzle fits. Yet software customers ask for those kinds of changes all the time and expect them to be easy, because on the surface they look easy. Easier? Maybe. I suppose it depends on a person's particular talents. But it is a very new discipline and it is much more of a craft than a science. Engineering knowledge grows from failure. You try something new and when it fails you figure out why. Structural engineering has had thousands of years to figure out how to build things correctly. Software engineering has had about fifty. Structural engineering is heavily based on knowing the physical properties of materials and applying mathematical equations to predict what will happen when a design is subjected to different conditions. Software engineering hasn't developed to the point where we can do that consistently. It's kind of irrelevant because nobody can do or expects to do full factorial testing. Regardless, any combinatorial testing is simply a recognition that d) the software must run correctly in an environment that is not well-defined and that the developer has very little control over.