Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-

Actor-Queue Relationship in the Actor Framework
Daklu replied to mje's topic in Object-Oriented Programming
You're right, we are thinking about slightly different things. Given your launch stack, it depends on how much Nested depends on Filter for correct operation and whether Filter is constant or changable. In the specific case of DoS attacks it probably doesn't matter since a few extra messages getting through Filter are unlikely to break Nested. The filtering is geared more towards performance and responsiveness than ensuring state diagram correctness. In situations where failure to filter a message may allow state diagram violations, the presence of a race condition is almost certainly undesirable. Then filter and state knowledge need to be in the same place. -
Actor-Queue Relationship in the Actor Framework
Daklu replied to mje's topic in Object-Oriented Programming
I don't think there's anything wrong with the idea of using a filter actor. I've used them in my own code with no discernable negative effects. But sending message from an inner actor to an external actor can create unexpected race conditions if the developer isn't careful. I just posted an example on another thread (and copied below) illustrating the problem. Sending outbound messages directly to recipients and bypassing the outer actor can be done safely, but it's certainly one of those things I would encourage people to avoid until they are very comfortable with actor-oriented programming. -
Error Handling in messaging systems
Daklu replied to John Lokanis's topic in Application Design & Architecture
Sure, there are ways to implement similar functionality using synchronous query-response messaging and timeouts. My response was directed at the question of whether or not fully asynchronous actors still need a timeout on their message queue. My answer remains, "no, I believe it is possible to always create a well-designed actor without putting critical code in the message handler's timeout case." Implementing timeout behavior using synchronous query-response messages may very well be obvious (though the asynchronous solution is more obvious to me.) What's less obvious is how to solve the other problems associated with synchronous messaging the developer encounters later. If an actor has a behavior that requires some sort of event timeout, I prefer to implement that behavior in the actor using a metronome or watchdog loop--similar to the helper VI you describe above. -
Actor-Queue Relationship in the Actor Framework
Daklu replied to mje's topic in Object-Oriented Programming
Minor point: I would say it blurs the line between messages and operations (or functions, methods, etc.), not messages and processes. In my mind process = actor and I think there's a pretty clear distinction between Actors and Messages in the AF. +1. As a general rule I try to use "actor" to mean the abstract concept and "Actor" to mean an AF actor. I propose we adopt that as a matter of convention. It is *extremely* important to understand this concept if you're going to do any actor-oriented programming, whether you use the AF or not. (Important enough for me to bold and underline it. ) But it's a very subtle difference and I haven't found a really good way to get that idea across to people. One of the best explanations I've seen was in the Channel 9 video Todd linked a while back on the AF Community Forum. To (heavily) paraphrase, he said: "Pretend that the other process is a turkey. If the turkey isn't an actor, when Thanksgiving rolls around you go out and chop off its head. If the turkey is an actor, then you ask it to cut off its own head." I'll also add that a message phrased as a command may still be a request. I send "Exit" messages whenever I want another actor to quit, and that sounds suspiciously like a command. It's still a request though, because the actor may refuse to do it. To add to the confusion, even if an implemented actor always honors the Exit message--essentially making that message a command--it is also still a request. How do you tell if a message is a command or a request? It's all about responsibility. Figure out where the final responsibility for knowing whether a particular message can be honored lies. If the sender has the responsibility, it's a command. If the receiver has the responsibility, it's a request. It is closely related to other threads where I've mentioned "sender side filtering" vs "receiver side filtering." If you won't, I will. A command makes the sender responsible for knowing whether the receiver can process the message without going into some unexpected state. In the context of the entire system's operation, yes, the sender needs to know when it should send a particular message to a particular receiver, but it should never have to worry about breaking the receiver because it sent a message when it shouldn't have. (Like I said, lots of gray between actor and non-actor.) -
Help define canonical LabVIEW.gitignore template for GitHub
Daklu replied to JackDunaway's topic in Source Code Control
First, the listing is just an example of what my .hgignore looks like. I wasn't suggesting it should be part of a baseline template. That particular listing is from a repro root. My global ignore just has the .aliases and .lvlps files listed. I think the .lvbitx files are more like .viobj files. They get generated every time the fpga code compiles, sometimes with different names. I don't know how LV decides if the name needs to be changed, but in my recent struggles it wasn't uncommon for me to end up with multiple bit files generated from the same vi. What kind of baseline are you looking for, files that everyone wants to ignore all the time or files that most people want to ignore most of the time? In Hg the ignore file lists those files that will not be added automatically. You can still select and add them manually if desired. I'd put bit files in the same category as executables--if it does get added to the repository, it's probably only checked in at very stable points. Also, here's a link to instructions on how to set a global ignore file, and another link to the hgignore file help docs. -
Help define canonical LabVIEW.gitignore template for GitHub
Daklu replied to JackDunaway's topic in Source Code Control
.hgignore .aliases .lvlps .lvbitx -
Error Handling in messaging systems
Daklu replied to John Lokanis's topic in Application Design & Architecture
I think of publish/subscibe (and Observers) as subsets of the event-announcement strategy. (I'd rather just call it "event based programming," but people tend to confuse that with User Events and Event Structures in LV.) In particular, publish/subscribe implies (to me) the ability to add and remove yourself from a list of subscribers during runtime and choosing a subset of an actor's messages to subscribe to. Publish/subscribe is a form of event-announcement, but there are other ways to implement it as well. No. The AF (and any messaging framework worth its salt) doesn't restrict its users to a single paradigm, but allows them to create the kind of messaging protocol they need to solve the problem. The requirement for synchronous query-response, asynchronous query-response, or event-announcement messages is determined by how you define and implement your actor. It has nothing to do with the messaging system itself. -
Error Handling in messaging systems
Daklu replied to John Lokanis's topic in Application Design & Architecture
The traditional LV model of a top level vi that all other vis are a dependency of doesn't always translate well to actor oriented programming, especially if using the Actor Framework since it dynamically launches actors. Once the startup code has launched the actors and made the necessary connections it can exit, leaving each actor as its own top level vi. -
Help define canonical LabVIEW.gitignore template for GitHub
Daklu replied to JackDunaway's topic in Source Code Control
I haven't used Mercurial a lot, but I'm pretty sure there are places you can put an .hgignore file to apply it to the machine and/or user. Or is that only if using TortoiseHg? -
Error Handling in messaging systems
Daklu replied to John Lokanis's topic in Application Design & Architecture
I don't think you want to do that. There's value in routing all messages between helper loops, subactors, and external actors through a central point inside the actor. (Usually the message handling loop in my code.) That central point maintains all the important state data the actor needs to operate correctly. Once you allow internal loops to communicate directly with external actors, you open the door to race conditions. The component is announcing an event (an error) the brain (the message handler) doesn't know about. To illustrate the race condition, let's pretend you have two actors: Actor and OtherActor. Actor has a message handling loop and an interal helper loop. We don't know how OtherActor is implemented, but we know that if it receives an error message it will in turn send a Reset message back to the Actor. But, we don't want the Actor to always accept and process Reset messages. We only want to do that if the Actor is in an error state. When the messages are routed through the message handler the message sequence goes like this: 1. Helper loop sends error message to message handler. 2. Message handler notes error, switches to error state, and sends message to OtherActor. 3. OtherActor sends Reset message to Actor. 4. Actor receives message, confirms it is in an error state, and initiates the reset. When the helper loop bypasses the message handler this sequence is possible: 1. Helper loop sends error message to message handler and OtherActor. 2. OtherActor sends Reset message to Actor. 3. Actor receives Reset message, finds it is not in an error state, and discards the message. 4. Actor receives error message and switches to error state. Will that happen? Probably not. But the race condition exists and I'd rather *know* my app will behave as expected rather than *hope* my app will behave as expected. (In my experience by the time race condition is discovered there will be so many race conditions present it is very difficult to remove them.) Alternatives? You have overridable error handling. Why not implement overridable shutdown code? Customize each one to make the message handler waits for the helper loops to shut down before they are allowed to shut themself down. Each actor certainly has the potential to become an independent state machine. Or another way to look at it is each actor *is* its own state machine, it just starts out with only one state. That's kind of what actor-oriented programming is about. Do you think about actors differently? -
Error Handling in messaging systems
Daklu replied to John Lokanis's topic in Application Design & Architecture
Yeah, that's the kind of scheme I had in mind. It can work, but it's not as simple or clear (imo) as an event-announcement protocol. If the event-announcement messages from an actor occur so frequently there is risk of bogging down the messaging system I'll see if other load reduction strategies can be used, like: -Remove some events from the list of announced events. -Make the announcement based on a timer event instead of an OnChanged event. -Bundle multiple announcements into a single message. If these can't be applied I'll look into more complex messaging ideas like Futures or asynchronous query-response messages. Synchronous query-response messages are a solution of last resort for me. -
Error Handling in messaging systems
Daklu replied to John Lokanis's topic in Application Design & Architecture
I'm not following so let me talk this out. You tell me where I go wrong. You have a parent class that implements some sort of message handling code in a method I'll call "Execute." You have created a subclass which contains UI elements and overridden the Parent.Execute method. On the UI.Execute block diagram, you use Call Parent Method to invoke the parent's message handling code and in parallel you have a loop for catching front panel events from the user. The problem you're having is that on the UI.Execute block diagram the parent message handler is exiting before the UI loop, which leaves the UI loop stranded. Is that correct? Do all your actors inherit from that parent? What kind of message does the parent handle? Do you use a case structure or command pattern message handler? Is the UI loop an independent actor able to communicate directly with actors on other block diagrams, or is it a helper loop that works with the parent's message handler (and perhaps other helper loops) to present create an actor? -
Error Handling in messaging systems
Daklu replied to John Lokanis's topic in Application Design & Architecture
No. Yes.* You are correct that if one of the Exited messages fails to arrive then the UI loop will never shut down. That's exactly what I want to happen. Putting a timeout in the UI loop permits a resource leak--Loop 1 can continue operating after the rest of the application has been shut down. By not using a timeout any errors in my shutdown logic are immediately apparent. Fail early, fail often. The hardest bugs to fix are those I don't know about. (*"Waiting" in the sense that the UI loop will never shut itself down, not in the sense that it is blocked or prevented from processing other messages it receives.) I guess my question is why do you ask the Power Supply for its state? Why don't you just have the power supply announce any state changes? That way your caller always has the most up to date information and you don't have to block it waiting for a response. Even if you do use a query-response protocol, you can design it to be asynchronous and non-blocking. It often requires the caller keep track of more state information of the kind "I've sent the power supply a QueryState message and am waiting for a reply," but it's still usually preferable to blocking the calling thread in my opinion. -
Help define canonical LabVIEW.gitignore template for GitHub
Daklu replied to JackDunaway's topic in Source Code Control
I don't use Git, but I assume .gitignore is similar to .hgignore. How is the canonical .gitignore file used in practice? Doesn't Git have a system-wide ignore file? -
Error Handling in messaging systems
Daklu replied to John Lokanis's topic in Application Design & Architecture
Whether or not you use actors is irrelevant. I could have (and perhaps should have) said, The messaging protocol is the series of messages your loops exchange to communicate important information. The ability of messaging frameworks to incorporate those features doesn't support your claim that, For this reason your messaging system either needs a long timeout... Messaging systems don't need those features any more than a person without a car needs car insurance. The reason you need those features is because you are using a message protocol designed around synchronous query-response communication. If your protocol is designed around asynchronous event-announcements then the need for those features goes away. Yeah, me too. But I can easily envision scenarios where dynamically launching actors loops would be beneficial. The particular components involved in the sequence of messages don't matter. Synchronous messaging (blocking one thread while waiting for another thread to respond) is rarely a good idea. Okay yeah, I can see why you wouldn't want to take the time to implement it. -
Error Handling in messaging systems
Daklu replied to John Lokanis's topic in Application Design & Architecture
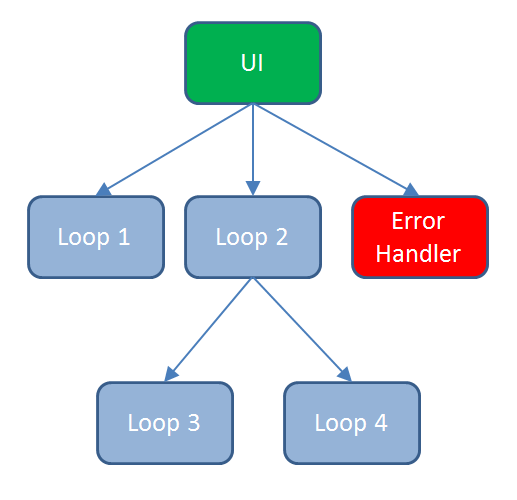
Quit interrupting. Me and hoovah are trying to have a discussion. A couple comments that may help... or may make you to decide it's not worth the effort. In my actors a message transport failure (i.e. the queue has been unexpectedly released) is a fatal error and always triggers an automatic shutdown. That could help you in the scenario you describe, but it's not a general solution. You don't say what your actor tree looks likes, so I'm guessing it's something like this. Broadcasting a shutdown message to all actors simultaneously limits your ability to control the shutdown process, even if an actor waits for all subactors to shutdown before shutting itself down. In this design the error handler doesn't have any subactors, so it shuts down immediately after receiving the message instead of waiting for all the other actors to shutdown first. You need to use targeted messaging, not broadcast messaging, and implement shutdown logic. This is how I have implemented controlled shutdowns in similar designs: The top level actor (UI) decides to shut down the app, so it sends "Exit" messages to Loops 1 and 2. Loop 1 receives the Exit message and shuts down, sending an "Exited" message to the UI. The UI notes that Loop 1 has exited. Loop 2 receives the Exit message and sends Exit messages to Loops 3 and 4. Loop 3 shuts down and sends Loop 2 an Exited message. Loop 2 records that Loop 3 has exited. Loop 4 shuts down and sends Loop 2 an Exited message. Loop 2 records that Loop 4 has exited. Loop 2 realizes that all its subactors have exited, so it exits and sends the UI an Exited message. The UI records that Loop 2 has exited, and realizing that both Loops 1 and 2 have exited and any error messages they may have created would have been received, sends an Exit message to the Error Handler. The error handler exits and sends an Exited message to the UI. The UI sees that all subactors have exited and exits itself.
-
Actor-Queue Relationship in the Actor Framework
Daklu replied to mje's topic in Object-Oriented Programming
(I'm sure you--MJE--know most of the stuff I say below, but I'm spelling it out for the benefit of other readers.) I propose implementing an actor with the expectation that its message queue is a de facto job queue violates the one of the fundamental principles of sound actor design. Message queues transports and job queues have different requirements because messages and jobs serve different purposes. Message are used to transfer important information between actors. Actors should always strive to read messages as quickly as possible since any unread messages may contain information the actor needs to know to make correct decisions. ("ReactorCoreOverheated") Whether or not they immediately act on the message is up to the actor, but at least it is aware of all the information available to it so it can make an informed decision about what action to take. Jobs aren't serviced the same way messages are. Jobs are a mechanism to keep worker loops busy. They're more of a "Hey, when you finish what you're doing can you to start on this" kind of thing rather than an "Here's some important information you should know about" kind of thing. Commingling these purposes into a single entity is part of the QSM mindset I mentioned earlier and leads to additional complications, like priority queues. So how do you implement a job processor if it isn't an actor? Make it an internal component of an actor. Create a helper loop that does nothing but dequeue and process jobs. When the actor receives an AddJobToJobQueue message in its message handling loop, it places the job on the job queue for eventual processing by the helper loop. Sound suspiciously like an actor? It's not. The job processor is directly controlled by the message handling loop. Actors are never directly controlled by other components; they control themselves. The job queue can be manipulated by the message handling loop as required, even to the point of killing the queue to trigger the job processing loop to exit. An actor's message queue is never manipulated or killed by anyone other than the actor itself. There's a lot of gray between an actor and a helper loop. The implementations can look very similar. I try to keep my helper loops very simple to avoid race conditions often found in QSMs. They are very limited in what operations they perform. They don't accept any messages and send a bare minimum of messages to the caller. ("Exited" and "Here'sYourData.") -
Error Handling in messaging systems
Daklu replied to John Lokanis's topic in Application Design & Architecture
I understand what you're saying, but I would rephrase it and say your messaging protocol needs to be designed appropriately. Messaging system implies (to me) a framework for sending messages, like LapDog.Messaging, JAMA, or the messaging aspect of the AF. The messaging protocol is the series of messages your actors exchange to communicate important information. In practice that is what I implement. If a low level actor has a fatal error and shuts down that message is sent up the chain to the top level actor, who in turn issues a shutdown command to everything else. It's pretty simple to implement and fatal errors are discovered quickly. There are, however, other valid ways of dealing with the situation. Some applications benefit from being able to dynamically invoke and destroy actors. In these cases there is no need to shut everything down just because a temporary actor is no longer needed. My apps haven't required dynamic actors so I don't bother with it, but it is a valid use case. Also, fatal errors in one actor don't necessarily require the entire app be shutdown. The owning actor could detect the unexpected shutdown and spin up another actor to replace it. I agree every actor should handle its own errors as best as it can. I've never found a scenario where I thought a centralized error handler was preferable to having each actor define its own behavior when it has an error. These scenarios might exist--lots of people seem to use centralized error handlers. Perhaps I'm just lacking in imagination. Error handling (and your entire messaging protocol, really) is simplified if you use an event-based messaging protocol. In other words, instead of the DAQ asking the logger for information the logger automatically sends information to the DAQ when an event of interest occurs. I handle these kinds of conveniences using a generic DebugMessage with a string payload. Status messages that are not critical to system operation but would be helpful during development are wrapped in a DebugMessage and sent up the chain. All DebugMessages get routed to an actor where the payload is extracted and added to a string indicator. Sometime the actor is application's UI, sometimes it is a separate debug window. In my systems the overhead to implement it is minimal. -
Error Handling in messaging systems
Daklu replied to John Lokanis's topic in Application Design & Architecture
I agree with Tim, it requires a two-part solution. To add a bit to what he said: 1. You could create an error logging system that successfully logged every error, even during shutdown. That creates an opportunity for the application never closing. If the error logger encounters an error while it is shutting down, it has to start up enough to log *that* error, followed by another shutdown which throws an error... you get the point. So the first step is figuring out what errors you care about logging. 2. Professional applications (which I loosly interpret as anything built into an executable) really should have a controlled shutdown process. In my systems the top level actor issues the shutdown command and it is propogated down the hierarchy. However, no actor actually begins shutting itself down until it all its subactors have finished shutting themself down. So while the command is issued from the top-down, the shutdown process itself operates bottom-up. Occasionally I will customize the shutdown sequence so certain components (like an error logger) will be the last to shutdown, even though it is not the top level actor. In practice I ignore most errors generated by an actor or loop once its shutdown process has started. Note that's not necessarily when it first receives the shutdown command. It's when that actor decides it's time to exit the loop. -
Actor-Queue Relationship in the Actor Framework
Daklu replied to mje's topic in Object-Oriented Programming
My apologies. I was thinking of a case structure message handler, not a command-based messaging system. I doubt it. There's no reason for me to believe an arbitrary application can't be implemented using the Actor Framework. However, while I agree that's the first real question, it's not the only real question. Once the ability to create an arbitrary application using a particular language or style has been met, the decision is based on other factors, like how productive you can be with it. Again, I think the AF does an admirable job of providing a usable framework while supporting your safety goals. An API can't be all things to all people and every design decision involves tradeoffs. Recognizing the limitations that result from those decisions isn't a criticism. -
[Ask LAVA] Must Override exists; could Must Implement?
Daklu replied to JackDunaway's topic in Object-Oriented Programming
I don't know. I haven't thought about that at all. Off the top of my head and putting no more than 2 minutes thought into it... -If the probe requires access to private data, then I suppose there's justification for making it part of the class definition, the same as any method that access private data. If the probe can provide the information to the user using the class' public method, then it doesn't need to be part of the class definition. -Which menu palettes are part of the class definition? I end up creating my own .mnu files or use the utility built into VIPM. -Precedence, imo, isn't sufficient reason to continue moving along an inferior path. Nothing is preventing that kind of white box testing as far as I know. (Though I use VI Tester for unit testing and don't have the option to make test cases members of the class under test.) There are a couple concerns I have: 1. You are proposing using unit tests to verify child classes written by other developers meet some set of functional requirements. White box testing relies on some knowledge of the implementation. You, as the parent class author, don't know how the child class author will implement the functional requirements, so writing white box test cases isn't possible. They must be black box. 2. Is it possible to implement a script smart enough to inspect an arbitrary block diagram and know if a functional requirement has been met? (Hint: No, except perhaps in trivial cases.) Automated inspection isn't capable of allowing all the implementations that meet an arbitrary functional requirement and rejecting all the implementations that do not. Version control simplicity for one. Who wants to check out lvclass file just to write another unit test for the class? More importantly to me, it allows end users more flexibility in customizing certain parameters without changing the source code. If you want to help your plugin authors write plugins that work well in your application, you distribute the manifest with the plugin interface class. Users that want to use it can. Users that have other use cases can change the manifest or otherwise ignore it. -
Actor-Queue Relationship in the Actor Framework
Daklu replied to mje's topic in Object-Oriented Programming
It doesn't matter what the value of the timeout is. If there is code that only executes after n ms of waiting to dequeue a message there is a non-zero chance the code will not execute. You must be making this statement in a context I'm not aware of. I can't figure out what you're trying to say. I don't think you're claiming it is universally true. That would be akin to saying, "Every actor must have a timeout case that executes or else it will fail." Clearly that is false. You could be claiming that's true for implementations that use the "zero or calculated timeout" technique. But then your statement boils down to, "In implementations where executing the code in the zero timeout is critical to the correct operation of the actor, if the zero timeout code never executes your actor will fail." That's true, but it's not particularly informative. Can you explain? I do think putting critical code in a timeout case is a questionable design practice, but I didn't claim using a timeout is always wrong. I said if I see a timeout attached to the actor's message handling loop it triggers a bunch of other questions that have to be answered before I'm comfortable allowing it. -
[Ask LAVA] Must Override exists; could Must Implement?
Daklu replied to JackDunaway's topic in Object-Oriented Programming
I don't think this is a good idea. The class definition (which I interpret to mean the .lvclass file) is supposed to define the class--data and methods to operate on the data. Performance guarantees to calling code, restrictions placed on child classes, and unit tests for the class certainly contain information related to the class, but they are not part of what a class is. It would be nice to be able to right-click on a class and have an option to run all unit tests associated with that class, and that does require a way to link the class to the unit test. But please don't embed that information in the .lvclass file. Previously I mentioned .lvcontract files to keep track of requirements and guarantees. I'll just generalize the idea and change the name from MyClass.lvcontract to MyClass.lvclass.manifest. The purpose of the manifest is to store any important information about the class (or vi) that isn't defined by the class. Theoretically someone could write a project provider plugin that reads the manifest file and invokes the unit tests it specifies. Eventually I think LV is going to have to support something along the lines of manifests eventually anyway in order to address the issues people are running into. Last year I was raising the alarm about the risk of running into unsolvable conflicts with the many .vip packages available. Manifests could solve that problem. -------- More to your question, black box testing cannot provide the same level of guarantees as inspection. If my Add function is required to return a value from 0-10, how many tests do I need to conduct to guarantee the function is working correctly? Assuming I'm adding two 32-bit numbers, about 18,447,000,000,000,000,000. That's a lot of goofing off waiting for the test to finish. Conversely, if I can inspect the block diagram and I see the output is coerced just prior to being passed out, I've verified correctness in less than 10 seconds. It is possible to use unit testing to verify many aspects of an interface's implementation. In my experience doing that usually leads to a lot of test code churn that isn't adding significant value to the project. YMMV. -
Actor-Queue Relationship in the Actor Framework
Daklu replied to mje's topic in Object-Oriented Programming
Just out of curiosity, giggle in an "I agree" way or giggle in an "how ironic" way? True, but your original concern was with the message queue getting backed up, not actor responsiveness in general. Designing an actor such that the message queue routinely gets backed up during normal operation creates the additional complexities you identified: -What is the correct behavior when the queue is full? -How do you enable senders to send special requirement messages like priority messages or "only do this once regardless of how many times it appears in the queue" messages? Neither of these questions have easy answers, but they must be addressed if your actor operates on the "job queue" principle. Separating an actor's implementation into a message handling loop and "everything else" makes those questions irrelevant. Not necessarily. An actor may receive messages faster than they can be processed sequentially, but if they can be processed concurrently by delegating to multiple loops then no throttling is required. Fundamentally an actor is just an abstraction of some concurrent computation. Internally the actor may implement a single loop or it may implement multiple loops. External code doesn't know or care how many loops it uses. In cases where the messages must be processed sequentially, then yes, some sort of filtering may be required. Even delegating to a single subactor has benefits. The filtering can be implemented in the actor instead of trying to encode it in the messaging system or leaving it up to the senders. I agree. I'll argue against any claim that it's the responsibility of either the sender or the receiver to make sure the queue doesn't overflow. In the general case senders won't know what messages the receiver is getting from other sources so it has no way of choosing an appropriate rate to send messages. On the receiving side, all messages take some finite amount of time to process and the receiver cannot prevent a hundred senders from flooding its message queue. Neither the sender nor receiver has the ability to prevent a queue flood; therefore, neither of them have the responsibility to prevent it. So who is responsible? At the risk of being trite, it's the responsibility of the developer who is combining the actors into a working system. As a practical matter no component is going to understand a complex system well enough to automatically throttle messages through all possible system states. I suppose it's possible to build one, but I think it would add a lot of complexity for relatively little value. In a hierarchical messaging system you can implement some throttling/filtering in any of the actors along the message chain. Common places where I've implemented it is in the sender's owner (first hop,) receiver's owner (last hop,) or in the lowest actor in the hierarchy that owns both the sender and receiver. In direct messaging systems where each actor sends messages directly to the intended receiver with no intermediate actors the options are more limited. I've avoided attempts to create a generalized message transport interface that can use any of the two dozen options available. I'm of the opinion that there are too many idiosyncracies with each transport that the sender and receiver must know about for it to be worthwhile. (i.e. An actor whose message queue is a TCP connection is written differently than an actor whose message queue is a global variable.) Furthermore, I don't see a lot of practical situations where there's a need to be able to change the transport. I'm sure there are some, but I think it's better to handle them on a case by case basis rather than trying to build a general purpose message transport interface. Sure. One of the fundamental axioms of actor-oriented programming is an actor can receive any message at any time. The actor can't control when it receives messages, so any code set to execute on a timeout runs the risk of being starved. If the timeout code is critical to the proper operation of the actor and it doesn't get executed, the actor may not behave as expected. -
[Ask LAVA] Must Override exists; could Must Implement?
Daklu replied to JackDunaway's topic in Object-Oriented Programming
Really? And these notes consist of more than, "I wish Daklu would shut up?" I'm shocked. It sounds like your straitjacket is similar to what I've had in mind; a set of restrictions that can be applied and enforced when that level of protection is wanted, but can be removed by the class user for special situations. I'm getting a mixed message here and I'm not quite sure what you're trying to say, so I'll break it down a bit. a class that chooses not to wear the straightjacket *is not a value of the parent class* I disagree with this part. A child class that chooses not to wear the parent's straitjacket is still a value (or type) of the parent class. I view straitjackets (or restrictions, guarantees, contracts, requirements, etc.) as a different language construct than classes, Interfaces, or Traits. I think it would be a mistake to build requirements into any of those features. If a parent class has a straightjacket to let it be used in an application, and the child class chooses not to wear the straightjacket, then it can still inherit all the parent class functionality, but it cannot be used in a framework that expects classes that use the straightjacket. Mmm, this is moving in the right direction but I need clarification. If the parent class is straitjacketed and a child class is not, does that prevent a child object from travelling on a parent wire altogether? Does it effectively remove the ability to dynamically dispatch to that child class? Can the child's straitjacket be changed, donned, or removed without editing the child's .lvclass file or any methods? In order to get the security you want and the flexibility I want, I think there has to be two parts to establishing a contract. The calling code or parent class publishes requirements, and the called code or child class publishes the promises it is willing to make to callers. The intersection of the requirements and promises is the contract. If the contract fulfills all the requirements published by the calling code, everyone is happy and there's no error. A very rudamentary form of this could be implemented now using manually edited .lvcontract files. All you'd need is an engine to walk the dependency tree, load the .lvcontract files, and compare the caller's requirement list against the callees promises. Something else occurred to me while typing this up. You've been advocating making requirements part of the class. I've been advocating making requirements part of the calling code. It there a valid use case for needing different sets of requirements on different objects of a single class? Neither of our positions permits that. If it is a useful addition, how is it accomplished?