Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-
Customized Toolbars Selectively Disable Auto Compiling
-
I'm not. (Apologies to Monty Python's Life of Brian.)
-
VIPM will make me smarter? Sign me up for 11 copies!
-
Or care, for that matter.
-
Not at all, I was just curious. Had I been more familiar with vipc files I likey would have clued in to the dependency right away. If the zip file had contained only the vipc file (with the package inside) I *might* have figured it out. Once I saw the package in the zip file I completely disregarded the vipc file. No need to change your distro. A better solution is to get smarter users....
-
Depends on how closely related it is to your original topic. If you wanted to ask questions on how to implement by-ref data using a DVR, I'd recommend a new post with a more accurate title for your new question. New posts tend to get a little more attention than older posts. When spawning a new thread that's an offshoot of a previous thread it's a good idea to link back to the original to give readers an easy way to get the history. On the other hand, if you still had questions about the consequences of different choices for sharing data that should be posted here. This is a pretty casual community--about the only thing that will evoke a flame from others is if you spam the same question across multiple LAVA forums. (Even then the flame is more of a smoldering matchstick than a blow torch.)
-
I was in the same boat. It took me some time to get my head around how programming concepts apply to Labview. In many cases I'm still learning... Happy to help. I'll actually be offline for the first part of July, but if you start a new thread someone will speak up and help you out.
-
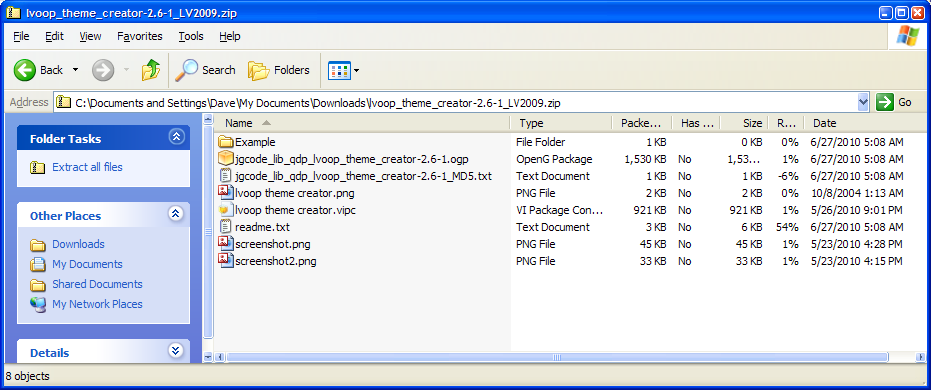
I see it now. I've evaluated VIPM configuration files and like the feature, but since I don't work with them regularly it didn't even occur to me to try applying the configuration. (Had I noticed the vipc file's size I might have figured it out.) Can't dispute your reasoning. Curious, why didn't you put the Theme Creator package in the vipc file? I noticed that in the changelist. Thanks!
-
Yep, your hierarchy will behave the same way as what I suggested. [i'm not talking down to you, simply trying to be clear.] You won't find anything in Labview's help about a "by-ref class." In general there are three kinds of data a class can have: By-value data, by-reference data, and global data. When I said "by-ref class" I meant a class in which all the user data is stored by reference instead of by value or globally. The differences between the types of data are: By-Value Data: Branching a wire creates a copy of the data. No data is shared. By-Reference Data: Branching a wire does not create a copy of the data. You can share data by simply branching the wire and using the class methods on both branches. Each class constant does create a new copy of the data. Global Data: All branches and block diagram constants refer to the same copy of the data. Data is always shared. Search the example finder for ReferenceObject.lvproj. That shows how to implement a by-ref class using a queue. DVRs are in the help file. Are you using LV 2009? Right. Build MockDevice as if it were a regular class, except instead of putting the state data (strings, booleans, etc.) directly in the class ctl, put them in a by-ref container. (Put them in a cluster and put the cluster in a DVR or on a queue as shown in ReferenceObject.lvproj.) Now in MockDevice:Initialize you'll have to dynamically launch Simulator.vi in a parallel thread. That's when you use SciWare's ActiveObject:LaunchProcess.vi as an example. I haven't needed to do that, but lots of others have. You can do that by opening Simulator.vi with option "8" wired into the Open VI Reference prim. This is my variation of SciWare's LaunchProcess implementation. (You can see I have the "8" wrapped up in a diagram disable structure.) You'll notice that the class wire branches right after the Bundle By Name prim with one branch heading to the output terminal and the other branch being sent to the class control input in my ProcessLoop.vi. (That would be your Simulator.vi.) Because the ActiveObject class ctl has by-ref data, both branches refer to the same set of data.

-
I tried... I really did... For the life of me I can't figure out how to parse that to mean, "download the zip file if you don't have the dependency." But like I said, I'm a little slow. Are you sure about that? Ahhhhh... better. Me? I don't ever have opinions...
-
We're just trying to save you the extra work.
-

How many "User Events" can LabVIEW queued?
Daklu replied to MViControl's topic in Application Design & Architecture
Since you asked, here's what I'm currently using for my messaging framework. I uploaded the source to the LapDog respository and will do any additional modifications there. MessageLibrary.zip -
Hmm... the theme creator needs the icon editor api package v2.0, but apparently I'm too stupid to find it. Can I have a hint?
-
Grrr... I spent a couple hours responding last night only to have IE eat my post when I previewed it. You don't specify how you are using the abstraction layer, so I'll throw this out there in case you are doing something different. Assuming your abstraction is an InstrumentController class, by far the easiest way to do what you want is to make an InstrumentSimulator class that is a child of the InstrumentController class. If your InstrumentController class includes a "Use Simulator" setting, back up and create a new class. Splitting up the functionality makes the code easier to understand and easier to test. InstrumentController is more reusable across different projects--if apps have different simulator requirements you're can create a project-specific InstrumentSimulator instead of modifying InstrumentController source code and potentially introducing bugs in other apps. Your main app needs almost no modifications to use the simulator. I use a conditional disable structure to switch between my real instrument drivers and my mock instrument drivers. No other changes needed. Is there some reason simulator.vi should be write only instead of read-write? The first question you need to answer is if you want your simulator data to be a global data ("static" data in other languages) available to all simulator instances or by-ref data unique for each simulator object. It's easier to get something that runs using global class data. It's not easier (imo) to get something that runs robustly using global class data. By-ref class data offers more flexibility in how you use the class. For example, using by-ref class data you can simulate n instruments (each with their own simulator vi) by simply dropping n class constants on the block diagram. You can't do that with global class data. You can also make a by-ref class behave like a global class by wrapping the by-ref object in another class as a global variable. If you start with a global class you can't make it behave like a by-ref class. It will always be a global class. My default is to use a by-ref class, especially if there's a chance you might reuse the class in other projects. If you decide you want a global class: Global variables - Easy for class users to use--no need to drag class wires around. Easy for class users to misuse if they are not aware of its global nature. Easy to implement getters and setters. Requires potentially complex semaphores if you have any read-modify-write operations. Allows concurrent access to different data elements. Named Single Element Queue - Built in protection against race conditions. No concurrent access unless you implement a separate queue for each data element. Very slight possiblity of stepping on an identically named queue. Functional Global - You can make a functional global behave more like a global variable or more like a named single element queue, depending on how you implement it. Personally I don't see a need for them in OOP. If you decide you want a by-ref class: Data Value Reference - Build in protection against race conditions. No concurrent access unless you implement a separate DVR for each data element. Unnamed Single Element Queue - Pretty much the same as the DVR, except you have to manually implement a bit more of the functionality. Since the introduction of DVRs in 2009, I find the DVR a more natural device for storing shared data than the SEQ. If you have a separate InstrumentSimulator class, what you're looking for is a class in which the methods run in the client's execution branch, *except* for Simulator.vi, which runs in a private, parallel execution branch. SciWare created an Active Object framework for by-ref classes that shows how to launch a class member vi in a parallel branch. (See LaunchProcess.vi.) You'd do that as part of InstrumentSimulator's initialization routine. Assuming Simulator.vi is just setters and getters, you can simplify his design a lot by removing the command queue and message queue. You'd also replace his Process.vi with your Simulator.vi. Making InstrumentSimulator a global class avoids all the complexities required with making sure both branches have the same DVR or unnamed queue refnum. The data sharing is built into the global variable so you just have to launch Simulator.vi when the app starts.
-
Typically the hash is posted on the author's website. Somebody changing the source code can't change the hash on the website, so by checking the hash of the download against the hash shown on the website you can make sure the binary is identical. I'm not sure there's any value in including the hash as part of the download. I don't think I've ever had a download end up corrupted.
-
How many "User Events" can LabVIEW queued?
Daklu replied to MViControl's topic in Application Design & Architecture
for the humor! (I’m working on a more complete comparison between QSMs and “real” state machines. I’ll likely post it in a new thread when it’s ready.) Continuing from earlier… Really? Scooby-Doo? Shaggy? Velma, Fred, and Daphne? You know… Mystery, Inc? (I thought the US exported our television across the galaxy…) Agreed. I’d probably take it a step further and say having a QSM manage anything other than itself is a mistake. (At least I would if I thought QSMs were a good idea.) Not in my mind. Although in principle you could queue up more than one message at a time, there is no reason to do so. Each case is an atomic operation. Any time the loop is ready to dequeue a message, any message is valid. None of the cases depend on another case being executed prior to it or following it. This application does use the command pattern, but it’s not part of my messaging system. The messaging component essentially consists of a MessageQueue class, which wraps LV’s queue prims along with error handling, and a Message base class with a single Get Name method. Rather than sending messages as strings and variants/typedefs (both of which caused me maintenance headaches) all messages are sent as objects. This makes it much easier for me to arbitrarily change data the message carries without breaking the app in a bunch of different places. In that application each message is a unique class and the message name is defined by the message class’ name. This gives me type safety; I don’t have to worry about accidentally sending the wrong data to any message handling case and the only spell checking required is to make sure the cases are spelled identically to the class names. In a sense it is “debugging by design.” I eliminated the possibility of a whole range of bugs and all the error checking code that goes along with them. The downside is that each message requires its own class even if multiple messages contain the same data. That can create a lot of duplicate code, and LV edit time performance seems to suffer badly when there are lots of classes in a project. I’ve addressed that in my latest application by creating unique message classes according to the type of data they carry. If multiple messages carry the same data (or more frequently, no data) then all those message objects are instances of the same message class, but the message name property is set when the object is created. The tradeoff? Less type safety, more spell checking inspection, simplified project window and class hierarchy. Can’t post the app and the topic itself is a 6-week thread all on its own. If you don’t have it I strongly recommend purchasing Head First Design Patterns. It’s well worth it at twice the price. I don’t universally use active objects for all my applications. There’s a lot of complexity associated with them that isn’t always beneficial, and to be honest, I’m not satisfied with the ActiveObject.lvlib template I have. I’m still trying to figure out how to appropriately separate the active object functionality from the business object functionality. I do prefer the flexibility of the MVC architecture and will use it unless there is a very compelling reason not to. When fleshing out an app’s requirements I try to be very up front about the consequences of what my customer is asking for. Often they say something like, “All I need is a quick vi to do…” My response is, “I can do that, but here are the things that will be difficult to add later.” Once they understand that they *always* want a more flexible design. I’m sure that’s partly due to the environment I work in. In product development testing our test engineers often don’t know exactly what they will need to test in the future so they want to keep their options open as long as possible. I agree. But why do you need Hector for a dialog box? (See image at the end of post for how I handle simple dialog boxes.) So far when using MVC my UI code has been almost trivially simple. The UI class is fairly dumb. Its public api is events to indicate the user performed an action and methods to allow the Controller to induce changes in the UI. It doesn’t maintain any information about what the Model is doing. Connecting the UI and the processing code (in the Model) is the Controller’s job. If the UI has to do something a little more complex like load a file, usually I’ll create a DataFile class that knows how to load and save itself. When the UI needs to load the file it just calls the appropriate DataFile method. The DataFile object is tested separately from the UI object. How do I validate my UI code? Inspection is often sufficient. If there’s some question I can easily verify it by stepping through the code. I dunno… you’re the script monkey in this conversation. Automated testing and Design For Test aren’t areas I have much experience in. I understand the principle, but haven’t implemented much. I do remember recent posts from NI about a third-party automated GUI testing toolkit. Haven’t looked at it though… MVC could help simply by removing the need to automate UI testing. Since the functional part of the application is in the Model and accessible entirely through method calls, in theory you can create enough unit tests to achieve full coverage.
-
How many "User Events" can LabVIEW queued?
Daklu replied to MViControl's topic in Application Design & Architecture
Quite possibly true. I do continue to use the term QSM because that's the name the Labview community associates that pattern. However, when I recognized my own applications based on the QSM were becoming unmanagable I started searching online for information about how to design a program using a QSM. Couldn't find much of anything. So then I started reading about state machines in general and how they apply to software. None of that info made much sense in the context of applying it to a QSM in Labview. Why? Because a QSM isn't a state machine in any common understanding of what state machines are. Yeah? Then NI is wrong too. You hear that Dr. T!? I'm calling you out! (Albeit very quietly...) I could start calling an apple an "orangutan" and those who know me well would understand my meaning, but when somebody in an online forum asks for a dessert suggestion because the the in-laws are in town and I respond with "orangutan pie," it's bound to cause all sorts of trouble. (Especially when I recommend using peeled orangutans and removing the stem. ) I know I'm unlikely to change the world and get everyone to start calling it a "function machine." I'm sure there are those reading this (if anyone is left now that we've completely derailed the original topic) who dismiss this as a minor semantics issue. I disagree--what we choose to call things often conveys information about that thing. "QSM" implies that pattern is, in fact, a type of state machine when in reality it is not. If instead of "QSM" we referred to that pattern as "Hector," I would consider that a better (if rather arbitrary) name. "QSM" is an extremely poor name for the pattern. I do believe that once you recognize that it really is a function machine (or MFVI) and start thinking about it in those terms, the questions that follow will naturally lead to a more suitable pattern. The question that started me down that path was one I asked you earlier. "How do I decide if an arbitrary piece of functionality should be in a state or a sub vi?" What heuristics and guidelines would you give to a junior developer that asked you that question? Doesn't matter if the QSM is based on strings, variants, enums, or classes. It's the architecture itself that is flawed, not the data it passes. (I suppose it wouldn't surprise you that I'm not a fan of the QMH either.) I've not heard that phrase before. "Multi Functional VI" does more accurately describe what it is and, somewhat ironically, also perfectly explains why you shouldn't use it for applications. Code is easier to maintain over the long run when it is separated, not combined. This is known as separation of concerns. (QSM code is similar to procedural code, so read the sentence about C and Pascal.) I could use my favorite procedural programming language and write a generic function similar to this... DoEverything(str funcName, var funcArgs){ Select funcName { Case = "Func1" { Cast(funcArgs, string); // do stuff }; Case = "Func2" { Cast(funcArgs, int); // do other stuff DoEverything("Func1", varData); }; Case = "Func3" { Cast(funcArgs, string); // do stuff again DoEverything("Func1", varData); DoEverything("Func2", varData); // do even more stuff }; Case Else {}; };};Main(){ funcNames[] = {"Func1", "Func3", Func2"}; funcArgs[] = {"Foo", 42, "Bar"}; For i = 0 to 2 { DoEverything(funcNames, funcArgs; };}; (I'll be the first to admit this is an imperfect textual metaphor for the QSM. For one thing the above implementation uses a function stack (permitting a kind of recursion) instead of a function queue. For another it doesn't show many of the QSM features, such as capturing events/messages. Regardless, the metaphor is attempting to illustrate the code structure of the QSM, not the actual implementation.) The question is why do this? Doesn't it make much more sense to have Func1, Func2, and Func3 be their own functions instead of wrapped in an arbitrary DoEverything() function? Even if your functions didn't directly call into other functions, does DoEverything() strike you as good programming? I suspect the QMH and QSM came about from attempts to "keep all the code on one screen" and a general reluctance to create sub vis. I understand that--I used to hate having to make a bunch of sub vis too. (Still do if its only purpose is to reduce the amount of screen space requried.) There are practical advantages to using sub vis instead of states. Earlier I mentioned it is clearly (IMO) more readable when the program flow is defined by the block diagram instead of by the queue. There are other advantages too. Using sub vis instead of states is also much safer, especially when the application gets complex. Consider three sub vis which form a cycle by calling into each other like this: SubVI1 --> SubVI2 --> SubVI3 --> SubVI1 Labview throws a compiler error if you do this--you end up with a broken run arrow. If you use states that enqueue other states instead of sub vis Labview's compiler can't check your code for cycles. Unless your application is very simply it is unreasonable to expect to be able to write test cases for all code paths. In short, the only way to make sure any given change has not introduced this error is by inspection. Dunno about you but the thought of having to manually trace through all the state machine's execution paths for any non-trivial changes is decidedly unappealling. Another nice thing the compiler does for us when using sub vis instead of states is ensure type safety. When you're converting all your data to a string so it can be passed to the next state (function) you're preventing the compiler from doing that. All those edit time broken wires that would have appeared with sub vis have just turned into run time errors that may or may not be caught by your testing. Once again, the only way you can be sure you've got it right is by inspection. Code inspection has a place in programming for sure, but expecting it to be sufficient for anything other than simple algorithms is a mistake imo. (Speaking of type safety errors, there's a bug in the pseudo code I posted above. Did you notice it while looking over the code? How long did it take you to find it? Had each function been broken out on its own the compiler would have picked it up immediately.) Hate to break it to you Scooby, but their state machine pattern appears to be woefully inadequate for implementing state machines as well. I've spent far too much time on this reply as it is... I'll try to post more later. You're a Labview instructor? Very cool. -
Understanding a sub vi's error handling at a glance?
Daklu replied to Daklu's topic in LabVIEW General
So throw him a kudo! Geez, what a Scrooge... -
Understanding a sub vi's error handling at a glance?
Daklu replied to Daklu's topic in LabVIEW General
THAT would make for some interesting block diagrams... I'll be thrilled when we finally get more than 256 colors we can use. -
Understanding a sub vi's error handling at a glance?
Daklu replied to Daklu's topic in LabVIEW General
True. I almost always have the context window open anyway but I'm probably in the minority. I use it so much I remapped F1 to toggle the context window. I do recall seeing that icon a few times but to be honest I never paid much attention to it. I don't know that I've ever used that option on property nodes. My proposal is restricted to only 2 states: recommended or optional. Your solution allows for a much more expressive way of communicating error handling by creating different colored ornaments. Thanks for the tip! -
I know LV style guidelines and conventional wisdom states that sub vis should always have error in and error out terminals as a way to enforce data flow if it is needed. I found that without some insight into the sub vi's error handling I tend to wire them all up and impose an artificial data flow on my application. Sometimes I ended up going to great lengths to reorganize a vi so the error wire was clean when in fact the sub vis I was connecting weren't significantly affected by the error in terminal and didn't generate an error on their own that needed to be caught. I started removing the error terminals if it was simply passed through the sub vi, but I didn't really like that solution either. I've played around with various combinations of settings for the error in and error out terminals and documenting error behavior ("This vi runs normally regardless of the error in condition.") in the properties dialog box but couldn't find anything that was simple/intuitive enough to use yet expressive enough to describe the most common situations. Recently I came up with this idea based on setting the terminal's connection property: error in terminal - Not all sub vis case out the error in terminal and so the input value is irrelevant. Recommended - The sub vi's output depends on the error in condition. Optional - The sub vi runs normally regardless of the error in condition. error out terminal - Not all sub vis generate errors so the error out terminal is irrelevant. Recommended - The vi (or one of its sub vis) may change the value on the error wire, either setting an error or clearing an error. Optional - The error out terminal value is always equal to the error in terminal value. Using this scheme the error terminals on most typical sub vis would be Rec/Opt. Sub vis that do I/O or generate internal errors would be Rec/Rec. Close Reference sub vis would be Opt/Rec. My class accessor vis would be Opt/Opt since I set the new value regardless of the error terminal. Thoughts? Is this a reasonably clear way to convey basic error handling information to the user?
-
I think local variables are faster than reinitializing each control through an invoke node. If you have lots of fp controls and only a few controls you want to preserve you could buffer those values on a wire and copy it back into the control after resetting all the fp controls. That would probably make your code easier to read than a bunch of local variables or invoke nodes. I don't know if there is a performance difference between reinitializing each control separately and the entire fp at once. You'd have to benchmark it.
-
How many "User Events" can LabVIEW queued?
Daklu replied to MViControl's topic in Application Design & Architecture
One good thing for me that has come out of this discussion is I have a much better understanding of state machines. I finally know the differences between "Moore," "Mealy," and "Mixed" state machines, how those different models are implemented in Labview, and have a *much* better idea of how to correctly decompose application requirements into a state machine. Unfortunately for the rest of you, I'm now more convinced than ever that the QSM is not a state machine and shouldn't be promoted as a good general purpose design pattern. I've actually started implementing all three models of the Microwave state machines from the article I linked to above. But like you, spare time is hard to come by and I'm not sure when I'll get them done. -
How many "User Events" can LabVIEW queued?
Daklu replied to MViControl's topic in Application Design & Architecture
By the way Jon, I hope my comment about your state names aren't taken as criticisms of your code. Your code is extremely clean, well documented, and the way you've organized the states helps clarify things. (Likely better than mine.) My critiques are targeting the QSM design pattern, not your implementation of it. Whew... thanks for catching that! I'll download the internet when I get home so I won't have to worry about it. (My views on the QSM may be out in left field, but at least my grammar isn't. )